python爬虫——urllib使用代理
收到粉丝私信说urllib库的教程还没写,好吧,urllib是python自带的库,没requests用着方便。本来嘛,python之禅(import this自己看)就说过,精简,效率,方便也是大家的追求。不过大家有要求,那就写一篇关于urllib的基础教程。
本文中的知识点:
- get请求
- 使用代理
- post请求
安装
urllib是python自带的,不用安装,直接import进来即可
代码样例
注意这里需要先定义opener,在打开我们要发送的request请求。返回的字符串编码用utf-8处理
import urllib.request
from urllib.parse import urlencode
opener = urllib.request.build_opener()
# 发送request请求
req = urllib.request.Request('https://www.baidu.com/')
res = opener.open(req)
# 打印response code
print(res.status)
# urllib字符串默认是bytes类型,需要转换到utf-8
print(res.read().decode('utf-8'))
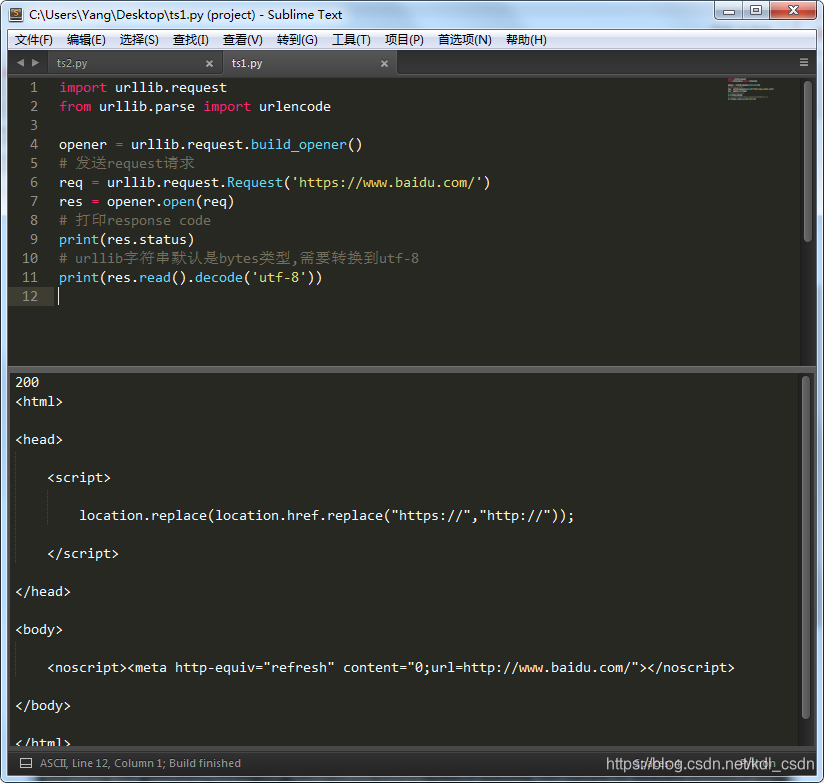
运行下,结果如下图
使用代理
注意还是要模拟用户请求,加上header参数
import urllib.request
from urllib.parse import urlencode
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}
# 代理IP,由快代理提供
proxy = '124.94.203.122:20993'
proxy_values = "%(ip)s" % {'ip': proxy}
proxies = {"http": proxy_values, "https": proxy_values}
# 设置代理
handler = urllib.request.ProxyHandler(proxies)
opener = urllib.request.build_opener(handler)
# 发送request请求
req = urllib.request.Request('https://www.baidu.com/s?ie=UTF-8&wd=ip', headers=headers)
res = opener.open(req)
# 打印response code
print(res.status)
# urllib字符串默认是bytes类型,需要转换到utf-8
print(res.read().decode('utf-8'))
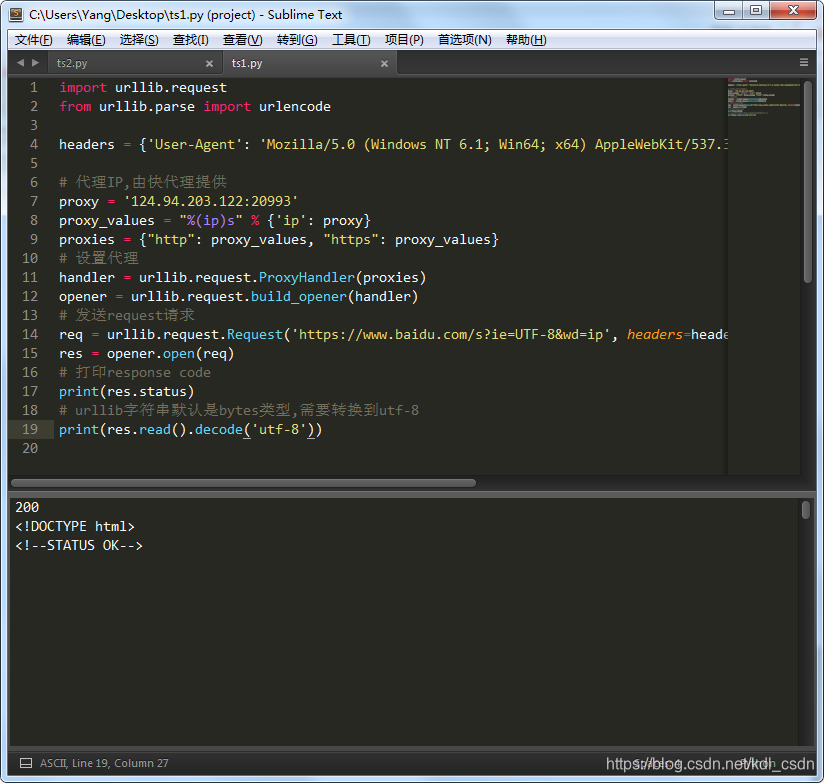
运行下,结果如下。正常打开了这个网页
 ***
***
POST请求
上述的默认使用的是get请求,那要使用post加一个method参数即可。
注意method参数POST是大写,因为我的urllib源码提示得大写。不过有的同学小写也可以,大家可以自己试下。
import urllib.request
from urllib.parse import urlencode
page_url = 'https://dev.kdlapi.com/testproxy/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}
# 代理IP,由快代理提供
proxy = '115.203.13.59:21216'
proxy_values = "%(ip)s" % {'ip': proxy}
proxies = {"http": proxy_values, "https": proxy_values}
# 设置代理
handler = urllib.request.ProxyHandler(proxies)
opener = urllib.request.build_opener(handler)
# 发送request post请求
data = bytes(urlencode({"info": "send post request"}), encoding="utf-8")
req = urllib.request.Request(url=page_url, headers=headers, data=data, method="POST")
res = opener.open(req)
# 打印response code
print(res.status)
# urllib字符串默认是bytes类型,需要转换到utf-8
print(res.read().decode('utf-8'))
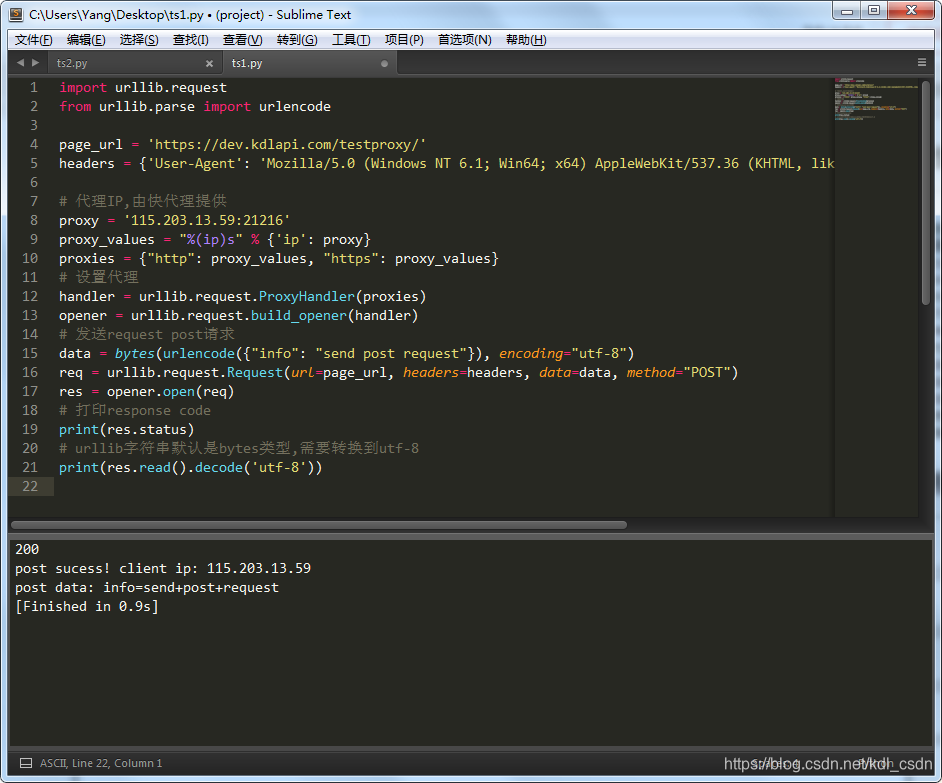
运行下试试,post成功,如图
进阶学习:
- urllib库,自己看下帮助文档或者源码吧。。。(滑稽)
- 代理IP的使用
python爬虫——urllib使用代理的更多相关文章
- Python爬虫Urllib库的高级用法
Python爬虫Urllib库的高级用法 设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Head ...
- Python爬虫教程-11-proxy代理IP,隐藏地址(猫眼电影)
Python爬虫教程-11-proxy代理IP,隐藏地址(猫眼电影) ProxyHandler处理(代理服务器),使用代理IP,是爬虫的常用手段,通常使用UserAgent 伪装浏览器爬取仍然可能被网 ...
- Python爬虫Urllib库的基本使用
Python爬虫Urllib库的基本使用 深入理解urllib.urllib2及requests 请访问: http://www.mamicode.com/info-detail-1224080.h ...
- python爬虫 urllib模块url编码处理
案例:爬取使用搜狗根据指定词条搜索到的页面数据(例如爬取词条为‘周杰伦'的页面数据) import urllib.request # 1.指定url url = 'https://www.sogou. ...
- python 爬虫 urllib模块 目录
python 爬虫 urllib模块介绍 python 爬虫 urllib模块 url编码处理 python 爬虫 urllib模块 反爬虫机制UA python 爬虫 urllib模块 发起post ...
- python爬虫 - Urllib库及cookie的使用
http://blog.csdn.net/pipisorry/article/details/47905781 lz提示一点,python3中urllib包括了py2中的urllib+urllib2. ...
- Python 爬虫 --- urllib
对于互联网数据,Python 有很多处理网络协议的工具,urllib 是很常用的一种. 一.urllib.request,request 可以很方便的抓取 URL 内容. urllib.request ...
- Python爬虫urllib模块
Python爬虫练习(urllib模块) 关注公众号"轻松学编程"了解更多. 1.获取百度首页数据 流程:a.设置请求地址 b.设置请求时间 c.获取响应(对响应进行解码) ''' ...
- python爬虫-urllib模块
urllib 模块是一个高级的 web 交流库,其核心功能就是模仿web浏览器等客户端,去请求相应的资源,并返回一个类文件对象.urllib 支持各种 web 协议,例如:HTTP.FTP.Gophe ...
随机推荐
- java用普通类如何实现枚举功能
用普通类如何实现枚举功能,定义一个Weekday的类来模拟枚举功能. 1.私有的构造方法. 2.每个元素分别用一个公有的静态成员变量表示. 可以有若干公有方法或抽象方法.采用 ...
- linux测试 scullpipe 驱动
我们已经见到了 scullpipe 驱动如何实现阻塞 I/O. 如果你想试一试, 这个驱动的源码 可在剩下的本书例子中找到. 阻塞 I/O 的动作可通过打开 2 个窗口见到. 第一个可运行 一个命令诸 ...
- jQuery 工具类函数-使用$.extend()扩展工具函数
调用名为$. extend的工具函数,可以对原有的工具函数进行扩展,自定义类级别的jQuery插件,调用格式为: $. extend ({options}); 参数options表示自定义插件的函数内 ...
- Hbase概念原理扫盲
一.Hbase简介 1.什么是Hbase Hbase的原型是google的BigTable论文,收到了该论文思想的启发,目前作为hadoop的子项目来开发维护,用于支持结构化的数据存储. Hbase是 ...
- Hibernate映射文件详解(News***.hbm.xml)二
转自 http://blog.csdn.net/a9529lty/article/details/6454924 一.hibernate映射文件的作用: Hibernate映射文件是Hibernate ...
- DRF框架中的异常处理程序
目录 DRF框架中自定义异常处理 一.自定义异常的原因 二.如何设置处理异常的程序 DRF框架中自定义异常处理 一.自定义异常的原因 在Django和DRF框架中都封装了很多的处理异常的程序,可以处理 ...
- 【一起学源码-微服务】Nexflix Eureka 源码十一:EurekaServer自我保护机制竟然有这么多Bug?
前言 前情回顾 上一讲主要讲了服务下线,已经注册中心自动感知宕机的服务. 其实上一讲已经包含了很多EurekaServer自我保护的代码,其中还发现了1.7.x(1.9.x)包含的一些bug,但这些问 ...
- 修改kubelet启动参数
我是用kubeadm安装的k8s,现在通过Aqua扫描出相关配置问题,需要修改kubelet的启动参数: 默认配置文件名为:10-kubeadm.conf #vim /usr/lib/systemd/ ...
- Python学习3月10号【python编程 从入门到实践】---》笔记
第11章 测试代码 11.1.2 可通过的测试 name_function.py ###创建一个简单的函数,他接受名和性并返回整洁的姓名 def get_formatted_name(first,la ...
- 20191031-4 beta week 1/2 Scrum立会报告+燃尽图 02
此作业要求参见 https://edu.cnblogs.com/campus/nenu/2019fall/homework/9912 git地址:https://e.coding.net/Eustia ...