【机器学习】算法原理详细推导与实现(六):k-means算法
【机器学习】算法原理详细推导与实现(六):k-means算法
之前几个章节都是介绍有监督学习,这个章节介绍无监督学习,这是一个被称为k-means的聚类算法,也叫做k均值聚类算法。
聚类算法
在讲监督学习的时候,通常会画这样一张图:
这时候需要用logistic回归或者SVM将这些数据分成正负两类,这个过程称之为监督学习,是因为对于每一个训练样本都给出了正确的类标签。
在无监督学习中,经常会研究一些不同的问题。假如给定若干个点组成的数据集合:

所有的点都没有像监督学习那样给出类标签和所谓的学习样本,这时候需要依靠算法本身来发现数据中的结构。在上面的这张图中,可以很明显的发现这些数据被分成了两簇,所以一个无监督学习算法将会是聚类算法,算法会将这样的数据聚集成几个不同的类。
聚类算法很多应用场景,举几个最常用的:
- 在生物学应用中,经常需要对不同的东西进行聚类,假设有很多基因的数据,你希望对它们进行聚类以便更好的理解不同种类的基因对应的生物功能
- 在市场调查中,假设你有一个数据库,里面保存了不同顾客的行为,如果对这些数据进行聚类,可以将市场分为几个不同的部分从而可以对不同的部分指定相应的销售策略
- 在图片的应用中,可以将一幅照片分成若干个一致的像素子集,去尝试理解照片的内容
- 等等...
聚类的基本思想是:给定一组数据集合,聚集成若干个属性一致的类。
k-means聚类
这个算法被称之为k-means聚类算法,用于寻找数据集合中的类,算法的输入是一个无标记的数据集合\({x^{(1)},x^{(2)},...,x^{(m)}}\),因为这是无监督学习算法,所以在集合中只能看到\(x\),没有类标记\(y\)。k-means聚类算法是将样本聚类成\(k\)个簇(cluster),具体算法步骤如下:
step 1 随机选取k个聚类质心点(cluster centroids),那么就等于存在了\(k\)个簇\(c^{(k)}\):
\]
step 2 对于每一个\(x^{(i)}\),需要计算与每个质心\(\mu_j\)的距离,\(x^{(i)}\)则属于与他距离最近质心\(\mu_j\)的簇\(c^{(j)}\):
\]
step 3 对于每一个类\(c^{(j)}\),重新计算该簇质心的值:
\]
之后需要重复step 2和step 3直到算法收敛,下面图中对上述步骤进行解释,存在数据点如下所示:
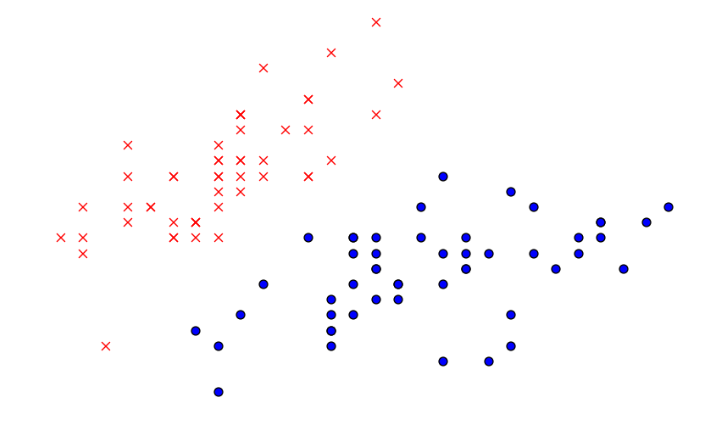
假设我们取\(k=2\),那么会在数据集合中随机选取两个点作为质心,即下图中红色的点\(\mu_1\)和蓝色的点\(\mu_2\):

分别计算每一个\(x^{(i)}\)和质心\(\mu_1\)、\(\mu_2\)的距离,\(x^{(i)}\)离哪个\(\mu_j\)更近,那么\(x^{(i)}\)就属于哪个\(c^{(j)}\),即哪些点离红色\(\mu_1\)近则属于\(c^{(1)}\),离蓝色近则属于\(c^{(2)}\)。第一次将\(x^{(i)}\)分类后效果如下:
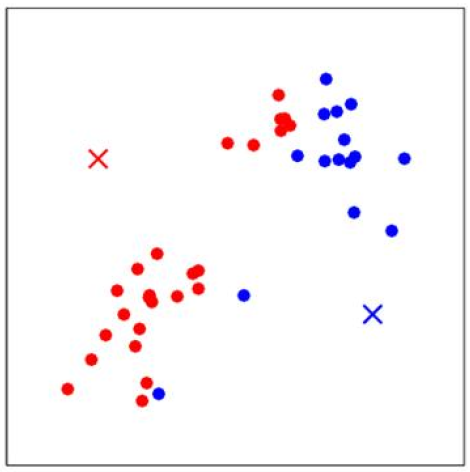
下一步是更新簇\(c^{(j)}\)的质心,计算所有红色点的平均值,得到新的质心\(\mu_{1\_new}\);计算所有蓝色点的平均值,得到新的质心\(\mu_{2\_new}\),如下图所示:

再次重复计算每一个\(x^{(i)}\)和质心的距离,更新质心的值。多次迭代收敛后,即使进行更多次的迭代,\(x^{(i)}\)的类别和质心的值都不会再改变了:
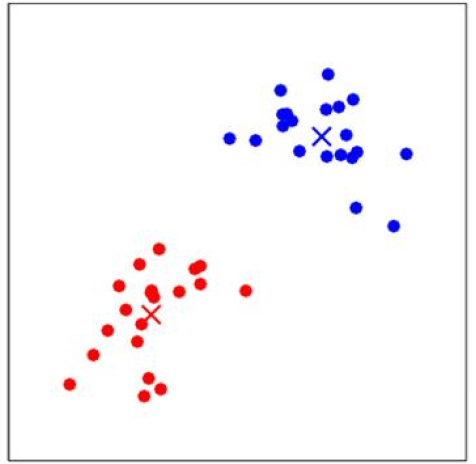
这里涉及到一个问题,如何保证k-means是收敛的?前面算法强调的是结束条件是收敛,为了保证算法完全收敛,这里引入畸变函数(distortion function):
\]
\(J(c,\mu)\)表示每个样本点\(x^{(i)}\)到其质心距离的平方和,当\(J(c,\mu)\)没有达到最小值,可以固定\(c^{(j)}\)更新每个簇的质心\(\mu_j\),质心变化后固定质心的值\(\mu_j\)重新划分簇\(c^{(j)}\)也变化,不断迭代。当\(J(c,\mu)\)达到最小值时,\(\mu_j\)和\(c^{(j)}\)也同时收敛。(这个过程和前面【机器学习】算法原理详细推导与实现(五):支持向量机(下)中的SMO优化算法算法的过程很相似,都是固定一组值或者一个值,更新另外一组或者一个值,使其函数优化到极值,这个过程叫做坐标上升,这里不作推导)。实际上可能会有多组\(\mu\)和\(c\)能够使得\(J(c,\mu)\)取得最小值,但是这种情况并不多见。
由于畸变函数\(J(c,\mu)\)是非凸函数,所以意味着不能保证取的最小值是全局最小值,也就是说k-means对随机取的质心的初始位置比较敏感。一般达到局部最优已经满足分类的需求了,如果比较介意的话,可以多跑几次k-means算法,然后取\(J(c,\mu)\)最小值的\(\mu\)和\(c\)。
k值确定
很多人不知道怎么确定数据集需要分多少个类(簇),因为数据是无监督学习算法,k值需要认为的去设定。所以这里会提供两种方法去确定k值。
第一种方法:
观察法,本文的例子可以看出,把数据集画在图中显示,就能很明显的看到应该划分2个类(簇):
并非所有的数据都像上面的数据一样,一眼可以看出来分2个类(簇),所以介绍一般比较常用的第二种方法。
第二种方法:
轮廓系数(Silhouette Coefficient),是聚类效果好坏的一种评价方式。最早由 Peter J. Rousseeuw 在 1986 提出。它结合内聚度和分离度两种因素。可以用来在相同原始数据的基础上用来评价不同算法、或者算法不同运行方式对聚类结果所产生的影响。
按照上面计算k-means算法的步骤计算完后,假设\(x^{(i)}\)属于簇\(c^{(i)}\),那么需要计算如下两个值:
- \(a(i)\),计算\(x^{(i)}\)与同一簇中其他点的平均距离,代表\(x^{(i)}\)与同一簇中其他点不相似的程度
- \(b(i)\),计算\(x^{(i)}\)与另一个与\(x^{(i)}\)最近的簇\(c\),与簇\(c\)内所有点平均距离,代表\(x^{(i)}\)与最相邻簇\(c\)的不相似程度
最终轮廓系数的计算公式为:
\]
轮廓系数的范围为\([-1, 1]\),越趋近于1代表内聚度和分离度都相对较优。
所以可以在k-means算法开始的时候,先设置k值的范围\(k \in [2, n]\),从而计算k取每一个值的轮廓系数,轮廓系数最小的那个k值就是最优的分类总数。
实例
假设存在数据集为如下样式:
import matplotlib.pyplot as plt
import numpy as np
from sklearn.cluster import KMeans
from sklearn import metrics
# figsize绘图的宽度和高度,也就是像素
plt.figure(figsize=(8, 10))
x1 = np.array([1, 2, 3, 1, 5, 6, 5, 5, 6, 7, 8, 9, 7, 9])
x2 = np.array([1, 3, 2, 2, 8, 6, 7, 6, 7, 1, 2, 1, 1, 3])
X = np.array(list(zip(x1, x2))).reshape(len(x1), 2)
# print(X)
# x,y轴的绘图范围
plt.xlim([0, 10])
plt.ylim([0, 10])
plt.title('sample')
plt.scatter(x1, x2)
# 点的颜色
colors = ['b', 'g', 'r', 'c', 'm', 'y', 'k', 'b']
# 点的形状
markers = ['o', 's', 'D', 'v', '^', 'p', '*', '+']
plt.show()

虽然观察法可以知道这个数据集合只要设置\(k=3\)就好了,但是这里还是想用轮廓系数来搜索最佳的k值。假设不知道的情况下,这里取\(k \in [2, 3, 4, 5, 8]\):
# 测试的k值
tests = [2, 3, 4, 5, 8]
subplot_counter = 1
for t in tests:
subplot_counter += 1
plt.subplot(3, 2, subplot_counter)
kmeans_model = KMeans(n_clusters=t).fit(X)
for i, l in enumerate(kmeans_model.labels_):
plt.plot(x1[i], x2[i], color=colors[l], marker=markers[l], ls='None')
# 每个点对应的标签值
# print(kmeans_model.labels_)
plt.xlim([0, 10])
plt.ylim([0, 10])
plt.title('K = %s, Silhouette Coefficient = %.03f' % (t, metrics.silhouette_score(X, kmeans_model.labels_, metric='euclidean')))
得到的结果为:
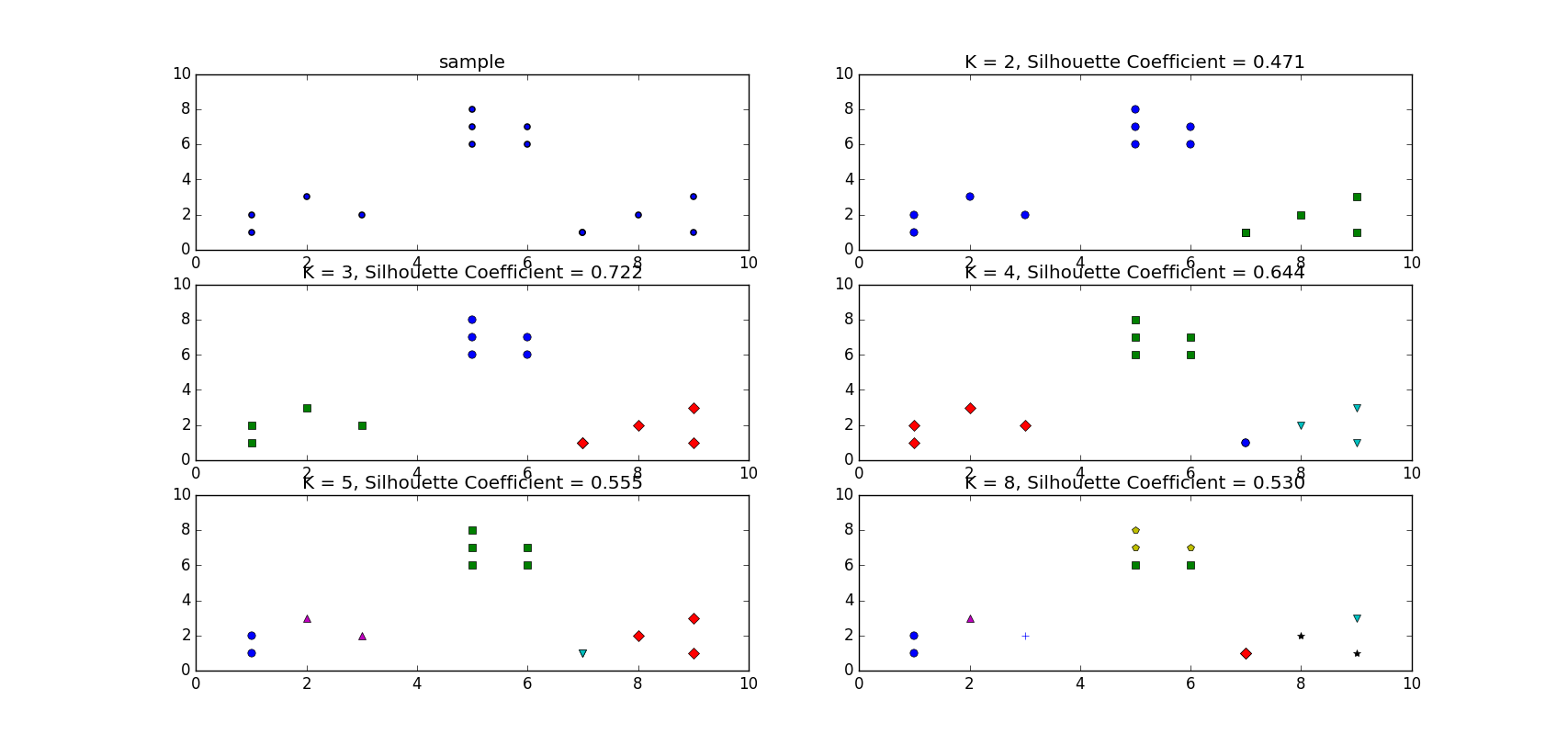
可以看到当\(k=3\)时轮廓系数最大为0.722
数据和代码下载请关注公众号【 机器学习和大数据挖掘 】,后台回复【 机器学习 】即可获取
【机器学习】算法原理详细推导与实现(六):k-means算法的更多相关文章
- 经典算法题每日演练——第十六题 Kruskal算法
原文:经典算法题每日演练--第十六题 Kruskal算法 这篇我们看看第二种生成树的Kruskal算法,这个算法的魅力在于我们可以打一下算法和数据结构的组合拳,很有意思的. 一:思想 若存在M={0, ...
- 分布式系列文章——Paxos算法原理与推导
Paxos算法在分布式领域具有非常重要的地位.但是Paxos算法有两个比较明显的缺点:1.难以理解 2.工程实现更难. 网上有很多讲解Paxos算法的文章,但是质量参差不齐.看了很多关于Paxos的资 ...
- 【转载】分布式系列文章——Paxos算法原理与推导
转载:http://linbingdong.com/2017/04/17/%E5%88%86%E5%B8%83%E5%BC%8F%E7%B3%BB%E5%88%97%E6%96%87%E7%AB%A0 ...
- 强化学习-学习笔记7 | Sarsa算法原理与推导
Sarsa算法 是 TD算法的一种,之前没有严谨推导过 TD 算法,这一篇就来从数学的角度推导一下 Sarsa 算法.注意,这部分属于 TD算法的延申. 7. Sarsa算法 7.1 推导 TD ta ...
- 机器学习实战 - python3 学习笔记(一) - k近邻算法
一. 使用k近邻算法改进约会网站的配对效果 k-近邻算法的一般流程: 收集数据:可以使用爬虫进行数据的收集,也可以使用第三方提供的免费或收费的数据.一般来讲,数据放在txt文本文件中,按照一定的格式进 ...
- 多层神经网络BP算法 原理及推导
首先什么是人工神经网络?简单来说就是将单个感知器作为一个神经网络节点,然后用此类节点组成一个层次网络结构,我们称此网络即为人工神经网络(本人自己的理解).当网络的层次大于等于3层(输入层+隐藏层(大于 ...
- AdaBoost 算法原理及推导
AdaBoost(Adaptive Boosting):自适应提升方法. 1.AdaBoost算法介绍 AdaBoost是Boosting方法中最优代表性的提升算法.该方法通过在每轮降低分对样例的权重 ...
- 《机器学习实战》中的程序清单2-1 k近邻算法(kNN)classify0都做了什么
from numpy import * import operator import matplotlib import matplotlib.pyplot as plt from imp impor ...
- KNN 与 K - Means 算法比较
KNN K-Means 1.分类算法 聚类算法 2.监督学习 非监督学习 3.数据类型:喂给它的数据集是带label的数据,已经是完全正确的数据 喂给它的数据集是无label的数据,是杂乱无章的,经过 ...
随机推荐
- DSN
用户DSN注册信息记录在本机的注册表上 文件DSN保存在本地磁盘上 系统DSN注册在服务器的注册表上,所以客户端连接服务器,只要一台在服务器建立了DSN,其他客户端登录时都会看到该DSN
- 重拾c++第二天(4):复合类型
1.定义:种类 数组名[元素个数] = {元素1,...,元素n} ,或者直接赋值:数组名[元素位置] = 值; 2.部分初始化,其他全为0,可以就定义一个0,这样得到0数组(或者就一个{},别的啥也 ...
- APICloud开发者进阶之路 |纯手工编写日程表功能
本文出自APICloud官方论坛, 感谢论坛版主 赵永亮 的分享. 最近看论坛内关于极光推送的问题有很多, 本想写一个关于极光的详细教程的,无奈已经有很多大牛分享过了,所以只得纯手工写了一个日程表,可 ...
- Python思维导图(一)—— 基础
前言 思维导图并不能涵盖所有知识点,只是梳理某个知识点下我们需要重点关注的分支:根据自己的情况可以进行拓展学习 计算机基础 博主认为需要重点掌握的有 编译型语言和解释型语言的区别?分别有什么编程语言? ...
- 死磕面试 - Dubbo基础知识37问(必须掌握)
作为一个JAVA工程师,出去项目拿20k薪资以上,dubbo绝对是面试必问的,即使你对dubbo在项目架构上的作用不了解,但dubbo的基础知识也必须掌握. 整理分享一些面试中常会被问到的dubbo基 ...
- 异数OS谈发展国产操作系统的问题
异数OS谈发展国产操作系统的问题 为什么写本文 最近中兴被美制裁的问题以及红芯使用开源技术宣称国产自主技术引发了舆论不少对国产CPU以及国产操作系统自主技术的讨论,为什么我们国家有BAT,有原子弹,能 ...
- Java并发关键字Volatile 详解
Java并发关键字Volatile 详解 问题引出: 1.Volatile是什么? 2.Volatile有哪些特性? 3.Volatile每个特性的底层实现原理是什么? 相关内容补充: 缓存一致性协议 ...
- ssm项目中中文字符乱码
昨天给同学改一个错,在SSM项目中,表单输入的String类型中,中文字符值,总是乱码,在控制器层获取的数据就开始乱码,先后进行了如下排查: web.xml中配置设置字符编码的监听器(过滤器), js ...
- 「 从0到1学习微服务SpringCloud 」06 统一配置中心Spring Cloud Config
系列文章(更新ing): 「 从0到1学习微服务SpringCloud 」01 一起来学呀! 「 从0到1学习微服务SpringCloud 」02 Eureka服务注册与发现 「 从0到1学习微服务S ...
- Potplay视频播放画面扭曲
Potplayer是一款非常好用的视频播放器,解码快,功耗低同时相对较好支持保真加速,但是,在使用过程中出现了如下的所谓“Bug” 经过摸索发现是播放器自动检测到此视频是360视频(不明觉厉,貌似需要 ...