MongoDB -> kafka 高性能实时同步(采集)mongodb数据到kafka解决方案
写这篇博客的目的
让更多的人了解 阿里开源的MongoShake可以很好满足mongodb到kafka高性能高可用实时同步需求(项目地址:https://github.com/alibaba/MongoShake,下载地址:https://github.com/alibaba/MongoShake/releases)。至此博客就结束了,你可以愉快地啃这个项目了。还是一起来看一下官方的描述:
MongoShake is a universal data replication platform based on MongoDB's oplog. Redundant replication and active-active replication are two most important functions. 基于mongodb oplog的集群复制工具,可以满足迁移和同步的需求,进一步实现灾备和多活功能。
没有标题的标题
哈哈,有兴趣听我啰嗦的可以往下。最近,有个实时增量采集mongodb数据(数据量在每天10亿条左右)的需求,需要先调研一下解决方案。我分别百度、google了mongodb kafka sync 同步 采集 实时等 关键词,写这篇博客的时候排在最前面的当属kafka-connect(官方有实现https://github.com/mongodb/mongo-kafka,其实也有非官方的实现)那一套方案,我对kafka-connect相对熟悉一点(不熟悉的话估计编译部署都要花好一段时间),没测之前就感觉可能不满足我的采集性能需求,测下来果然也是不满足需求。后来,也看到了https://github.com/rwynn/route81,编译部署也较为麻烦,同样不满足采集性能需求。我搜索东西的时候一般情况下不会往下翻太多,没找到所需的,大多会尝试换关键词(包括中英文)搜搜,这次可能也提醒我下次要多往下找找,说不定有些好东西未必排在最前面几个。
之后在github上搜in:readme mongodb kafka sync,让我眼前一亮。
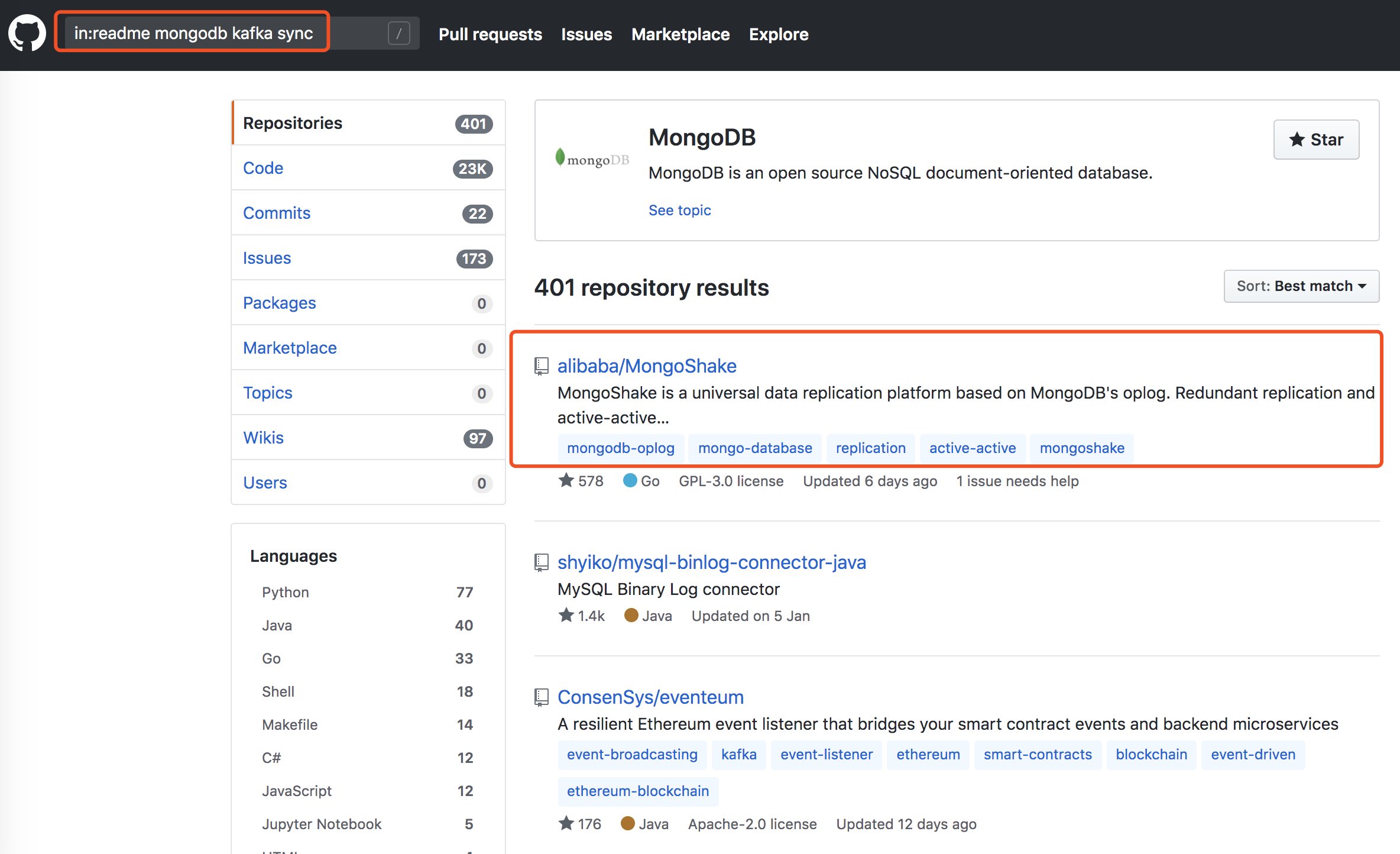
点进去快速读了一下readme,正是我想要的(后面自己实际测下来确实高性能、高可用,满足我的需求),官方也提供了MongoShake的性能测试报告。
这篇博客不讲(也很大可能是笔者技术太渣,无法参透领会(●´ω`●))MongoShake的架构、原理、实现,如何高性能的,如何高可用的等等。就一个目的,希望其他朋友在搜索实时同步mongodb数据时候,MongoShake的解决方案可以排在最前面(实力所归,谁用谁知道,独乐乐不如众乐乐,故作此博客),避免走弯路、绕路。
初次使用MongoShake值得注意的地方
数据处理流程
v2.2.1之前的MongoShake版本处理数据的流程:
MongoDB(数据源端,待同步的数据)
-->MongoShake(对应的是collector.linux进程,作用是采集)
-->Kafka(raw格式,未解析的带有header+body的数据)
-->receiver(对应的是receiver.linux进程,作用是解析,这样下游组件就能拿到比如解析好的一条一条的json格式的数据)
-->下游组件(拿到mongodb中的数据用于自己的业务处理)
v2.2.1之前MongoShake的版本解析入kafka,需要分别启collector.linux和receiver.linux进程,而且receiver.linux需要自己根据你的业务逻辑填充完整,然后编译出来,默认只是把解析出来的数据打个log而已
src/mongoshake/receiver/replayer.go中的代码如图:
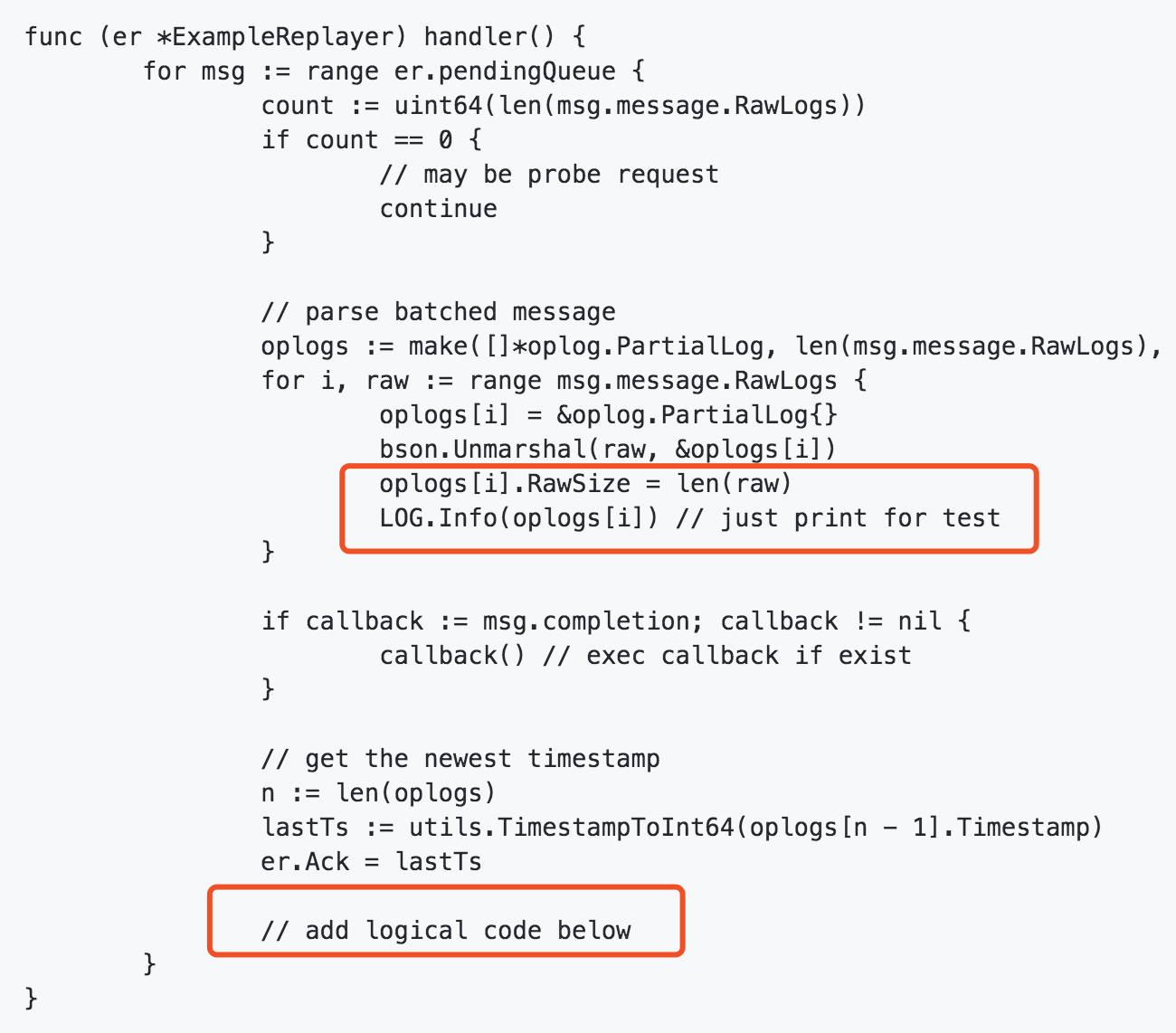
详情见:https://github.com/alibaba/MongoShake/wiki/FAQ#q-how-to-connect-to-different-tunnel-except-direct
v2.2.1版本MongoShake的collector.conf有一个配置项tunnel.message
# the message format in the tunnel, used when tunnel is kafka.
# "raw": batched raw data format which has good performance but encoded so that users
# should parse it by receiver.
# "json": single oplog format by json.
# "bson": single oplog format by bson.
# 通道数据的类型,只用于kafka和file通道类型。
# raw是默认的类型,其采用聚合的模式进行写入和
# 读取,但是由于携带了一些控制信息,所以需要专门用receiver进行解析。
# json以json的格式写入kafka,便于用户直接读取。
# bson以bson二进制的格式写入kafka。
tunnel.message = json
- 如果选择的
raw格式,那么数据处理流程和上面之前的一致(MongoDB->MongoShake->Kafka->receiver->下游组件) - 如果选择的是
json、bson,处理流程为MongoDB->MongoShake->Kafka->下游组件
v2.2.1版本设置为json处理的优点就是把以前需要由receiver对接的格式,改为直接对接,从而少了一个receiver,也不需要用户额外开发,降低开源用户的使用成本。
简单总结一下就是:
raw格式能够最大程度的提高性能,但是需要用户有额外部署receiver的成本。json和bson格式能够降低用户部署成本,直接对接kafka即可消费,相对于raw来说,带来的性能损耗对于大部分用户是能够接受的。
高可用部署方案
我用的是v2.2.1版本,高可用部署非常简单。collector.conf开启master的选举即可:
# high availability option.
# enable master election if set true. only one mongoshake can become master
# and do sync, the others will wait and at most one of them become master once
# previous master die. The master information stores in the `mongoshake` db in the source
# database by default.
# 如果开启主备mongoshake拉取同一个源端,此参数需要开启。
master_quorum = true
# checkpoint存储的地址,database表示存储到MongoDB中,api表示提供http的接口写入checkpoint。
context.storage = database
同时我checkpoint的存储地址默认用的是database,会默认存储在mongoshake这个db中。我们可以查询到checkpoint记录的一些信息。
rs0:PRIMARY> use mongoshake
switched to db mongoshake
rs0:PRIMARY> show collections;
ckpt_default
ckpt_default_oplog
election
rs0:PRIMARY> db.election.find()
{ "_id" : ObjectId("5204af979955496907000001"), "pid" : 6545, "host" : "192.168.31.175", "heartbeat" : NumberLong(1582045562) }
我在192.168.31.174,192.168.31.175,192.168.31.176上总共启了3个MongoShake实例,可以看到现在工作的是192.168.31.175机器上进程。自测过程,高速往mongodb写入数据,手动kill掉192.168.31.175上的collector进程,等192.168.31.174成为master之后,我又手动kill掉它,最终只保留192.168.31.176上的进程工作,最后统计数据发现,有重采数据现象,猜测有实例还没来得及checkpoint就被kill掉了。
MongoDB -> kafka 高性能实时同步(采集)mongodb数据到kafka解决方案的更多相关文章
- MongoDB -> kafka 高性能实时同步(sync 采集)mongodb数据到kafka解决方案
写这篇博客的目的 让更多的人了解 阿里开源的MongoShake可以很好满足mongodb到kafka高性能高可用实时同步需求(项目地址:https://github.com/alibaba/Mong ...
- flume实时采集mysql数据到kafka中并输出
环境说明 centos7(运行于vbox虚拟机) flume1.9.0(flume-ng-sql-source插件版本1.5.3) jdk1.8 kafka(版本忘了后续更新) zookeeper(版 ...
- Mongodb 和 Solr 实时同步
一.安装前准备 1.mongo-connector(基于python)中间件 2.python-3.4.3.msi 3.Mongodb 4.Solr 二.配置Mongodb集群 1).配置replic ...
- spark-streaming集成Kafka处理实时数据
在这篇文章里,我们模拟了一个场景,实时分析订单数据,统计实时收益. 场景模拟 我试图覆盖工程上最为常用的一个场景: 1)首先,向Kafka里实时的写入订单数据,JSON格式,包含订单ID-订单类型-订 ...
- canal整合springboot实现mysql数据实时同步到redis
业务场景: 项目里需要频繁的查询mysql导致mysql的压力太大,此时考虑从内存型数据库redis里查询,但是管理平台里会较为频繁的修改增加mysql里的数据 问题来了: 如何才能保证mysql的数 ...
- flink-cdc同步mysql数据到kafka
本文首发于我的个人博客网站 等待下一个秋-Flink 什么是CDC? CDC是(Change Data Capture 变更数据获取)的简称.核心思想是,监测并捕获数据库的变动(包括数据 或 数据表的 ...
- sersync实时同步实战
第1章 实时同步 1.1 什么是实时同步 实时同步是一种只要当前目录触发事件,就马上同步到远程的目录.rsync 1.2 为什么要实时同步web->nfs->backup 保证数据的连续性 ...
- C++操作Kafka使用Protobuf进行跨语言数据交互
C++操作Kafka使用Protobuf进行跨语言数据交互 Kafka 是一种分布式的,基于发布 / 订阅的消息系统.主要设计目标如下: 以时间复杂度为 O(1) 的方式提供消息持久化能力,即使对 T ...
- 基于netcore实现mongodb和ElasticSearch之间的数据实时同步的工具(Mongo2Es)
基于netcore实现mongodb和ElasticSearch之间的数据实时同步的工具 支持一对一,一对多,多对一和多对多的数据传输方式. 一对一 - 一个mongodb的collection对应一 ...
随机推荐
- POJ 1269 Intersecting Lines(判断两直线位置关系)
题目传送门:POJ 1269 Intersecting Lines Description We all know that a pair of distinct points on a plane ...
- 【转】[ppurl]从”皮皮书屋”下载电子书的姿势
转:http://blog.csdn.net/hcbbt/article/details/42072545 写在前面的扯皮 为什么标题的”皮皮书屋”加上了引号,因为皮皮书屋(http://www.pp ...
- curl使用post方式访问Spring Cloud gateway报time out错误
公司老的项目使用是php,要进行重构.其他团队使用php curl函数使用post方式调用Spring Cloud gateway 报time out错误. 但是使用postman测试是没有任何问题, ...
- 谈谈Java的Collection接口
目录 谈谈Collection 前言 Collection 方法 1.boolean add(E) 2.void clear() 3.boolean contains(Object o) 4.bool ...
- ThreadLocal终极篇
前言 在面试环节中,考察"ThreadLocal"也是面试官的家常便饭,所以对它理解透彻,是非常有必要的. 有些面试官会开门见山的提问: “知道ThreadLocal吗?” “讲讲 ...
- minikube 设置CPU和内存
安装minikube之后,第一次sudo minikube start 时,设置参数--cpus int --memory int . 如果需要更改设置,需要将缓存文件$HOME/.minikube ...
- Ubuntu 设置中文输入法
环境:新安装的Ubuntu 16.04 LTS 本来打算使用sogou拼音,但是在输入后的提示框中内容为乱码,因此尝试重新安装. 1.sudo apt-get remove sogoupinyin & ...
- Dijkstra求解单源最短路径
Dijkstra(迪杰斯特拉)单源最短路径算法 Dijkstra思想 Dijkstra是一种求单源最短路径的算法. Dijkstra仅仅适用于非负权图,但是时间复杂度十分优秀. Dijkstra算法主 ...
- .net core 连接数据库(通过数据库生成Modell)
创建数据库 (扫盲贴还劳烦大神们勿喷,谢谢) 打开数据库 输入如下代码 创建数据库 CREATE DATABASE [Blogging]; GO USE [Blogging]; GO CREATE T ...
- 「 Android开发 」开启第一个App应用
每天进步一丢丢,连接梦与想 无论什么时候,永远不要以为自己知道一切 -巴普洛夫 最近玩了下Android,但遇到了一些坑,浪费了很多的时间,在此记录一下,你若是遇到了就知道怎么解决了 PS:建议使 ...