编译原理实验之SLR1文法分析
---内容开始---
这是一份编译原理实验报告,分析表是手动造的,可以作为借鉴。
基于 SLR(1) 分析法的语法制导翻译及中间代码生成程序设计原理与实现
1 、理论传授
语法制导的基本概念,目标代码结构分析的基本方法,赋值语句语法制导生成四元式的
基本原理和方法,该过程包括语法分析和语义分析过程。
2 、目标任务
[ 实验 项目] 完成以下描述赋值语句 SLR(1)文法语法制导生成中间代码四元式的过程。
G[A]:A→V=E
E→E+T∣E-T∣T
T→T*F∣T/F∣F
F→(E)∣i
V→i
[ 设计说明 ] 终结符号 i 为用户定义的简单变量,即标识符的定义。
[ 设计要求]
(1)构造文法的 SLR(1)分析表,设计语法制导翻译过程,给出每一产生式
对应的语义动作;
(2)设计中间代码四元式的结构;
(3)输入串应是词法分析的输出二元式序列,即某赋值语句“专题 1”的输出结果,输出为赋值语句的四元式序列中间文件;
(4)设计两个测试用例(尽可能完备),并给出程序执行结果四元式序列。
3、 程序功能描述
在第一次实验词法分析输出结果的基础上设计SLR1文法分析过程,并了解四元式的形成:
- 输入串为实验一的二元式序列
- 输出为对输入串的SLR(1)文法的判断结果
- 输出有针对输入串的SLR(1)文法的具体分析过程
- 有对输入串的四元式输出序列
4、 主要数据结构描述
二元组结构体,用来存储词法分析程序输出的二元组对 <类别,单词>:
int count;
struct eryuanzu
{
int a;
char temp[COUNT];
}m[COUNT];
void out(int a,char* temp){// 打印二元组
printf("< %d %s >\n",a,temp);
m[count].a=a;
strcpy(m[count].temp,temp); //
count++;
}
SLR1分析过程中所要用到的状态栈、符号栈等:
stack<int> state; //状态栈
stack<char> sign; //符号栈
char st; //规约弹出时,状态栈顶元素
int flag=0; //标志是否是SLR
stack<string> place; //变量地址栈
ACTION表,二维数组表示:
/* i ( ) + - * / = #
以1开头的百位数为s移进项,0为error,-1为accept,其余的一位两位数是r规约项*/
int ACTION[20][9]={{103,0,0,0,0,0,0,0,0},//0
{0,0,0,0,0,0,0,0,-1},
{0,0,0,0,0,0,0,104,0},
{0,0,0,0,0,0,0,10,0},
{109,108,0,0,0,0,0,0},
{0,0,0,110,111,0,0,0,1},//5 mnl;;huhyhjhjio
{0,0,4,4,4,112,113,0,4},
{0,0,7,7,7,7,7,0,7},
{109,108,0,0,0,0,0,0,0},
{0,0,9,9,9,9,9,0,9},
{109,108,0,0,0,0,0,0,0},//10
{109,108,0,0,0,0,0,0,0},
{109,108,0,0,0,0,0,0,0},
{109,108,0,0,0,0,0,0,0},
{0,0,119,110,111,0,0,0,0},
{0,0,2,2,2,112,113,0,2},//
{0,0,3,3,3,112,113,0,3},
{0,0,5,5,5,5,5,0,5},
{0,0,6,6,6,6,6,0,6},
{0,0,8,8,8,8,8,0,8}};//19
·GOTO表,二维数组表示:
//A V E T F
int GOTO[20][5]={{1,2,0,0,0},
{0,0,0,0,0},//1
{0,0,0,0,0},
{0,0,0,0,0},
{0,0,5,6,7},
{0,0,0,0,0},//5
{0,0,0,0,0},
{0,0,0,0,0},
{0,0,14,6,7},
{0,0,0,15,7},
{0,0,0,16,7},//10
{0,0,0,0,17},
{0,0,0,0,18},
{0,0,0,0,0},
{0,0,0,0,0},
{0,0,0,0,0},//15
{0,0,0,0,0},
{0,0,0,0,0},
{0,0,0,0,0},
{0,0,0,0,0}};//19
规约时所用到的函数,分别对应每一条规则:
void R1(); //A→V=E
void R2(); //E→E+T
void R3(); //E→E-T
void R4(); //E→T
void R5(); //T→T*F
void R6(); //T→T/F
void R7(); //T→F
void R8(); //F→(E)
void R9(); //F→i
void R10(); //V→i
void R1() {
sign.pop(); sign.pop(); sign.pop(); //弹出符号栈
state.pop(); state.pop(); state.pop(); //弹出状态栈
sign.push('A'); //符号'A'入栈
st=state.top();
printf("r1\t");
}
void R2() {
sign.pop(); sign.pop(); sign.pop(); //弹出符号栈
state.pop(); state.pop(); state.pop(); //弹出状态栈
sign.push('E'); st=state.top(); //符号'E'入栈
printf("r2\t\t");
}
void R3() {
sign.pop(); sign.pop(); sign.pop();
state.pop(); state.pop(); state.pop();
sign.push('E');st=state.top();
printf("r3\t\t");
}
void R4() {
sign.pop();
state.pop();
sign.push('E');st=state.top();
printf("r4\t\t");
}
void R5() {
sign.pop(); sign.pop(); sign.pop();
state.pop(); state.pop(); state.pop();
sign.push('T');st=state.top();
printf("r5\t\t");
}
void R6() {
sign.pop(); sign.pop(); sign.pop();
state.pop(); state.pop(); state.pop();
sign.push('T');st=state.top();
printf("r6\t\t");
}
void R7() {
sign.pop();
state.pop();
sign.push('T');st=state.top();
printf("r7\t\t");
}
void R8() {
sign.pop(); sign.pop(); sign.pop();
state.pop(); state.pop(); state.pop();
sign.push('F');st=state.top();
printf("r8\t\t");
}
void R9() {
sign.pop();
state.pop();
sign.push('F');st=state.top();
printf("r9\t\t");
}
void R10() {
sign.pop();
state.pop();
sign.push('V');st=state.top();
printf("r10\t\t");
}
SLR1分析处理函数:
void SLR()
{
printf("输入串\t\t状态栈\t\t符号栈\t\tACTION\t\tGOTO ");
int i,j,k=1;
state.push(0); //初始化
sign.push('#');
int which; //对应表项内容
char c; //输入符号串首
int a; //坐标
int b;
do{
printf("\n");
c=m[k-1].temp[0]; //输入符号串首
cout<<c<<' ';
for(int j=k;j<=count;j++)
printf("%s",m[j].temp);
printf("\t\t");
displayStack(state);
displayStack1(sign);
a=state.top(); //坐标
b=isVt(c);
/*if(isOp(c)!=-1)
temp1=c;
place.push(temp1);*/
if(b!=-1) //输入串首c是终结符
{
which=ACTION[a][b];
if(which==-1)
{
printf(" acc,分析成功!\n");
flag=1;
break;
}
else if(which==0)
{ printf("error项1\n ");break; }
else if(which>=100) //移进
{
which=s_r(which);
printf("s%d\t\t",which);
sign.push(c);
state.push(which);
k++;
}
else
{
switch(which) //which整型,case不要加''
{
case 1:R1();break;
case 2:R2();break;
case 3:R3();break;
case 4:R4();break;
case 5:R5();break;
case 6:R6();break;
case 7:R7();break;
case 8:R8();break;
case 9:R9();break;
case 10:R10();break;
default:printf("which=%derror项2\n ");break;
}
//状态转移 Vn
int e=isVn(sign.top());
if(e!=-1)
{
int convert=GOTO[st][e];
state.push(convert);
printf("GOTO[%d,%c]=%d",st,sign.top(),convert);
}
}
}
else
{ printf("error_b ");break; }
}while(which!=-1);//while
}
5、实验测试
1.测试用例:i=(i-i*i)#,输入file.txt直接从文件读取输入串,得到结果如下:
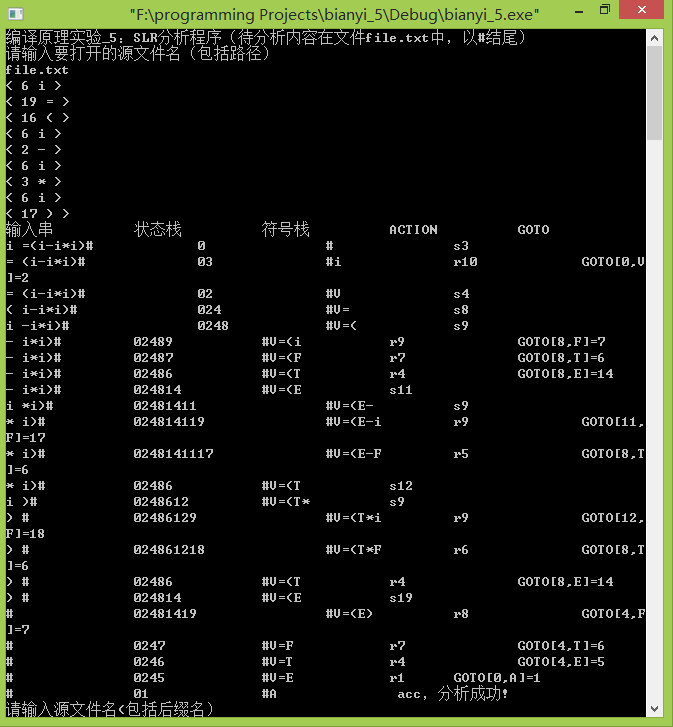
四元式结果输出:
由于图片无法上传便罢
6、 实验总结
本次实验是对理论课上所学知识的应用,重点是理解分析栈和符号栈,这里我采用自行造ACTION和GOTO表,这样SLR分析表就出来了,自动造表还是比较复杂。而且在造表的过程中经常出错,最后在大家的讨论中解决了。造完表后的分析过程并不复杂,按部就班分情况来处理。
本次实验加深了我对SLR1的分析过程的理解,也加深了对四元式的认识。
7、源代码
分为两个CPP
Siyuanshi.cpp
#include "stdafx.h"
#include<stdlib.h>
#include<fstream>
#include<iostream>
#include<stdio.h>
using namespace std; #define MAX 100
int mm=,sum=;//sum用于计算运算符的个数
//mm用于标输入表达式中字符的个数
char JG='A';
char str[MAX];//用于存输入表达式
int token=;//左括号的标志 /***********用于更改计算后数组中的值**************/
void change(int e)
{
int f=e+;
char ch=str[f];
if(ch>='A'&&ch<='Z')
{
for(int l=;l<mm+;l++)
{
if(str[l]==ch)
str[l]=JG;
}
} if(str[e]>='A'&&str[e]<='Z')
{
for(int i=;i<mm;i++)
{
if(str[i]==str[e])
str[i]=JG;
}
}
} void chengchuchuli(int i,int mm)
{ i++;
for( ;i<=mm-;i++)//处理乘除运算
{
if(str[i]=='*'||str[i]=='/')
{ cout<<"("<<str[i]<<" "<<str[i-]<<" "<<str[i+]<<" "<<JG<<")"<<endl;
change(i-);
str[i-]=str[i]=str[i+]=JG;
sum--;
JG=(char)(int)JG++;
}
}
} void jiajianchuli(int j,int mm)
{
j++;
for( ;j<=mm-;j++)//处理加减运算
{
if(str[j]=='+'||str[j]=='-')
{
cout<<"("<<str[j]<<" "<<str[j-]<<" "<<str[j+]<<" "<<JG<<")"<<endl;
change(j-);
str[j-]=str[j]=str[j+]=JG;
sum--;
JG=(char)(int)JG++;
}
}
} /*扫描遍从文件中读入表达式*/
void scan(FILE *fin)
{
int p[MAX];
char ch='a';
int c=-,q=;
while(ch!=EOF)
{
ch=getc(fin); while(ch==' '||ch=='\n'||ch=='\t')
ch=getc(fin);//消除空格和换行符 str[mm++]=ch;
if(ch=='='||ch=='+'||ch=='-'||ch=='*'||ch=='/')
sum++;
else if(ch=='(')
{
p[++c]=mm-;
}
else if(ch==')')
{
q=mm-;
chengchuchuli(p[c],q);//从左括号处理到又括号
jiajianchuli(p[c],q);
JG=(char)(int)JG--;
str[p[c]]=str[mm-]=JG;
c--;
JG=(char)(int)JG++;
}
}
} void siyuanshi()
{ for(int i=;i<=mm-;i++)//处理乘除运算
{
if(str[i]=='*'||str[i]=='/')
{ cout<<"("<<str[i]<<" "<<str[i-]<<" "<<str[i+]<<" "<<JG<<")"<<endl;
change(i-);
str[i-]=str[i]=str[i+]=JG;
sum--;
JG=(char)(int)JG++;
} } for(int j=;j<=mm-;j++)//处理加减运算
{
if(str[j]=='+'||str[j]=='-')
{ cout<<"("<<str[j]<<" "<<str[j-]<<" "<<str[j+]<<" "<<JG<<")"<<endl;
change(j-);
str[j-]=str[j]=str[j+]=JG;
sum--;
JG=(char)(int)JG++;
} } for(int k=;k<=mm-;k++)//处理赋值运算
{
if(str[k]=='=')
{ JG=(char)(int)--JG;
cout<<"("<<str[k]<<" "<<str[k+]<<" "<<" "<<" "<<str[k-]<<")"<<endl;
sum--;
change(k+);
str[k-]=JG;
}
} } extern void MAIN(){
char in[MAX]; //用于接收输入输出文件名
FILE *fin;
cout<<"请输入源文件名(包括后缀名)"<<endl;
cin>>in;;
if ((fin=fopen(in,"r"))==NULL)
{
cout<<"error"<<endl;
}
cout<<"*********四元式如下*********"<<endl;
scan(fin);//调用函数从文件中读入表达式
siyuanshi();
if(sum==) printf("成功?");
else printf("有错误");
//关闭文件
fclose(fin);
system("pause");
}
Bianyi_5.cpp
// bianyi_5.cpp : Defines the entry point for the console application.
// #include "stdafx.h"
#include <iostream>
#include <string>
#include <stack>
#include <map>
#include <string>
#include <cstring>
#include <iomanip> using namespace std;
extern void MAIN();
#define ADD 1
#define SUB 2
#define MUL 3
#define FH 4
#define SG 5
#define ID 6
#define INT 7
#define LT 8
#define LE 9
#define EQ 10
#define NE 11
#define GT 12
#define GE 13
#define MHEQ 14
#define XGMUL 15
#define ZKH 16
#define YKH 17
#define DIV 18
#define EQ 19//=
#define blz 00 #define COUNT 40
char* keyword[]={"begin","end","if","then","else","for","do","and","or","not"};//保留字 int count;
struct eryuanzu
{
int a;
char temp[COUNT];
}m[COUNT]; void out(int a,char* temp){// 打印二元组 printf("< %d %s >\n",a,temp);
m[count].a=a;
strcpy(m[count].temp,temp); //
count++;
} stack<int> state; //状态栈
stack<char> sign; //符号栈
char st; //规约弹出时,状态栈顶元素
int flag=; //标志是否是SLR
stack<string> place; //变量地址栈 /* i ( ) + - * / = #
以1开头的百位数为s移进项,0为error,-1为accept,其余的一位或两位数是r规约项*/
int ACTION[][]={{,,,,,,,,},//
{,,,,,,,,-},
{,,,,,,,,},
{,,,,,,,,},
{,,,,,,,},
{,,,,,,,,},//5
{,,,,,,,,},
{,,,,,,,,},
{,,,,,,,,},
{,,,,,,,,},
{,,,,,,,,},//
{,,,,,,,,},
{,,,,,,,,},
{,,,,,,,,},
{,,,,,,,,},
{,,,,,,,,},//
{,,,,,,,,},
{,,,,,,,,},
{,,,,,,,,},
{,,,,,,,,}};//19
//A V E T F
int GOTO[][]={{,,,,},
{,,,,},//
{,,,,},
{,,,,},
{,,,,},
{,,,,},//
{,,,,},
{,,,,},
{,,,,},
{,,,,},
{,,,,},//
{,,,,},
{,,,,},
{,,,,},
{,,,,},
{,,,,},//
{,,,,},
{,,,,},
{,,,,},
{,,,,}};// void R1(); //A→V=E
void R2(); //E→E+T
void R3(); //E→E-T
void R4(); //E→T
void R5(); //T→T*F
void R6(); //T→T/F
void R7(); //T→F
void R8(); //F→(E)
void R9(); //F→i
void R10(); //V→i int isOp(char a) //判断二元运算符及二元运算符的优先级
{
int i;
switch(a)
{
case '=':i=;break;
case '+':i=;break;
case '-':i=;break;
case '*':i=;break;
case '/':i=;break;
default:i=-;break;
}
return i;
}
int isVt(char a)
{
int i;
switch(a)
{
case 'i':i=;break;
case '(':i=;break;
case ')':i=;break;
case '+':i=;break;
case '-':i=;break;
case '*':i=;break;
case '/':i=;break;
case '=':i=;break;
case '#':i=;break;
default:i=-;break;
}
return i;
}
int isVn(char a)
{
int i;
switch(a)
{
case 'A':i=;break;
case 'V':i=;break;
case 'E':i=;break;
case 'T':i=;break;
case 'F':i=;break;
default:i=-;break;
}
return i;
}
int s_r(int i) //移进或者其他
{
int result;
if(i/==) //移进
result=i-;
else
result=i;
return result;
} bool invertStack(stack<int> &one_stack)
{
if (one_stack.empty())//if the stack is null,then don't invert it
{
return false;
}
else
{
//init a stack to save the inverted stack
stack<int> invert;
while (!one_stack.empty())
{
invert.push(one_stack.top());
one_stack.pop();
}
//this moment the stack's inverted state is the stack invert ,so get it back
one_stack = invert;
return true;
}
} void displayStack(stack<int> one_stack) //打印输出
{
invertStack(one_stack);
while (!one_stack.empty())
{
cout << one_stack.top();
one_stack.pop();
}
cout << '\t' << '\t' ;
} bool invertStack1(stack<char> &one_stack)
{
if (one_stack.empty())//if the stack is null,then don't invert it
{
return false;
}
else
{
//init a stack to save the inverted stack
stack<char> invert;
while (!one_stack.empty())
{
invert.push(one_stack.top());
one_stack.pop();
}
//this moment the stack's inverted state is the stack invert ,so get it back
one_stack = invert;
return true;
}
} void displayStack1(stack<char> one_stack)
{
invertStack1(one_stack);
while (!one_stack.empty())
{
cout << one_stack.top();
one_stack.pop();
}
cout << '\t' << '\t';
} void SLR()
{
printf("输入串\t\t状态栈\t\t符号栈\t\tACTION\t\tGOTO ");
int i,j,k=;
state.push(); //初始化
sign.push('#');
int which; //对应表项内容
char c; //输入符号串首
int a; //坐标
int b;
do{
printf("\n");
c=m[k-].temp[]; //输入符号串首
cout<<c<<' ';
for(int j=k;j<=count;j++)
printf("%s",m[j].temp);
printf("\t\t");
displayStack(state); displayStack1(sign);
a=state.top(); //坐标
b=isVt(c);
/*if(isOp(c)!=-1)
temp1=c;
place.push(temp1);*/
if(b!=-) //输入串首c是终结符
{ which=ACTION[a][b];
if(which==-)
{
printf(" acc,分析成功!\n");
flag=;
break;
}
else if(which==)
{ printf("error项1\n ");break; }
else if(which>=) //移进
{
which=s_r(which);
printf("s%d\t\t",which);
sign.push(c);
state.push(which);
k++;
}
else
{
switch(which) //which整型,case不要加''
{
case :R1();break;
case :R2();break;
case :R3();break;
case :R4();break;
case :R5();break;
case :R6();break;
case :R7();break;
case :R8();break;
case :R9();break;
case :R10();break;
default:printf("which=%derror项2\n ");break;
}
//状态转移 Vn
int e=isVn(sign.top());
if(e!=-)
{
int convert=GOTO[st][e];
state.push(convert);
printf("GOTO[%d,%c]=%d",st,sign.top(),convert);
}
}
}
else
{ printf("error_b ");break; } }while(which!=-);//while
} void R1() { sign.pop(); sign.pop(); sign.pop(); //弹出符号栈
state.pop(); state.pop(); state.pop(); //弹出状态栈
sign.push('A'); //符号'A'入栈
st=state.top();
printf("r1\t");
}
void R2() { sign.pop(); sign.pop(); sign.pop(); //弹出符号栈
state.pop(); state.pop(); state.pop(); //弹出状态栈
sign.push('E'); st=state.top(); //符号'E'入栈
printf("r2\t\t");
}
void R3() { sign.pop(); sign.pop(); sign.pop();
state.pop(); state.pop(); state.pop();
sign.push('E');st=state.top();
printf("r3\t\t");
}
void R4() {
sign.pop();
state.pop();
sign.push('E');st=state.top();
printf("r4\t\t");
}
void R5() { sign.pop(); sign.pop(); sign.pop();
state.pop(); state.pop(); state.pop();
sign.push('T');st=state.top();
printf("r5\t\t");
}
void R6() { sign.pop(); sign.pop(); sign.pop();
state.pop(); state.pop(); state.pop();
sign.push('T');st=state.top();
printf("r6\t\t");
}
void R7() {
sign.pop();
state.pop();
sign.push('T');st=state.top();
printf("r7\t\t");
}
void R8() {
sign.pop(); sign.pop(); sign.pop();
state.pop(); state.pop(); state.pop();
sign.push('F');st=state.top();
printf("r8\t\t");
}
void R9() {
sign.pop();
state.pop();
sign.push('F');st=state.top();
printf("r9\t\t");
}
void R10() {
sign.pop();
state.pop();
sign.push('V');st=state.top();
printf("r10\t\t");
} ///////////////////////////////////////////////
void scanner(FILE *p)
{
char filein[],fileout[]; //文件名
printf("请输入要打开的源文件名(包括路径)\n");
scanf("%s",filein);
//printf("请输入要输出的目标文件名(包括路径)\n");
//scanf("%s",fileout);
if((p=fopen(filein,"r"))==NULL) {printf("输入文件打开有错!\n");return;}
// if((q=fopen("fileout","rw"))==NULL) {printf("输出文件打开有错!\n");return;} char token[COUNT]; //输出数组
int r=,i=;
char ch;
ch=fgetc(p);
while(!feof(p)) //没有读到文件末尾
{
if(isdigit(ch))
{
i=;
token[i]=ch;
while(isdigit(ch=fgetc(p)))
{
i++;
token[i]=ch;
}
token[i+]='\0'; //整数结束。不要忘结束标志!
fseek(p,-,); //重定向到当前位置的前一个!
out(INT,token);
//fprintf(q,"%d %s\n",INT,token);
}
else if(isalpha(ch))
{
i=;
int flag=; //标志是否是保留字,默认不是
token[i]=tolower(ch);
while(isalpha(ch=fgetc(p)))
{
i++;
token[i]=tolower(ch);
}
token[i+]='\0';
fseek(p,-,);
for(r=;r<;r++)
{
if(!strcmp(token,keyword[r]))
{
printf("<blz %s>\n",token);
// fprintf(q,"%d %s\n","保留字",token);
flag=;
break;
}
}
if(!flag)
{ out(ID,token);
// fprintf(q,"%d %s\n",ID,token);
}
}
else
{
i=;
switch(ch)
{
case '+':{ token[i]=ch;
token[i+]='\0';
out(ADD,token);
}break;
case '-':{ token[i]=ch;
token[i+]='\0';
out(SUB,token);}break;
case '*':{ token[i]=ch;
token[i+]='\0';
out(MUL,token);}break;
case ';':{ token[i]=ch;
token[i+]='\0';
out(FH,token);}break;
case '|':{ token[i]=ch;
token[i+]='\0';
out(SG,token);}break;
case '(':{ token[i]=ch;
token[i+]='\0';
out(ZKH,token);}break;
case ')':{ token[i]=ch;
token[i+]='\0';
out(YKH,token);}break;
case '=':{ token[i]=ch;
token[i+]='\0';
out(EQ,token);}break;
case ' ':{ break;} //空格直接跳
case '#':{ break;} //井号用作结尾
case '<':{token[i]=ch;
ch=fgetc(p);
if(ch=='='){
token[i+]='=';
token[i+]='\0';
out(LE,token);
}
else if(ch=='>'){
token[i+]='>';
token[i+]='\0';
out(NE,token);
}
else
{ printf(" error \n");
fseek(p,-,); //多读的要回退一个字符
}
}break; case '>':{token[i]=ch;
ch=fgetc(p);
if(ch=='=')
{
token[i+]='=';
token[i+]='\0';
out(GE,token);
}
else
{ printf(" error \n");
fseek(p,-,); //多读的要回退一个字符
}
}break;
case ':':{token[i]=ch;
ch=fgetc(p);
if(ch=='='){
token[i+]='=';
token[i+]='\0';
out(MHEQ,token);
}
else
{ printf(" error \n");
fseek(p,-,); //多读的要回退一个字符
}
}break;
case '/':{token[i]=ch;
ch=fgetc(p);
if(ch=='*')
{
token[i+]='*';
token[i+]='\0';
out(XGMUL,token);
while() //注释部分的处理!
{
ch=fgetc(p);
if(ch=='*')
{
if((ch=fgetc(p))=='/')
break;
}
}
}
else // 除号,修改第一次程序部分
{ /*printf(" error \n");
fseek(p,-1,1); */
out(DIV,token);
fseek(p,-,);//多读的要回退一个字符
}
}break;
default:{
printf(" error\n ");
}break; }
}
ch=fgetc(p);
}
fclose(p);
}
int main(int argc, char* argv[])
{
printf("编译原理实验_5:SLR分析程序(待分析内容在文件file.txt中,以#结尾)\n");
FILE *fin,*q;
scanner(fin);
strcpy(m[count].temp,"#");//!
count=count+;
//scanner(p,q);
SLR();
MAIN();
return ;
}
---内容结束---
编译原理实验之SLR1文法分析的更多相关文章
- 《编译原理》构造 LL(1) 分析表的步骤 - 例题解析
<编译原理>构造 LL(1) 分析表的步骤 - 例题解析 易错点及扩展: 1.求每个产生式的 SELECT 集 2.注意区分是对谁 FIRST 集 FOLLOW 集 3.开始符号的 FOL ...
- 【编译原理】语法分析LL(1)分析法的FIRST和FOLLOW集
近来复习编译原理,语法分析中的自上而下LL(1)分析法,需要构造求出一个文法的FIRST和FOLLOW集,然后构造分析表,利用分析表+一个栈来做自上而下的语法分析(递归下降/预测分析),可是这个FIR ...
- 编译原理(六)自底向上分析之LR分析法
自底向上分析之LR分析法 说明:以老师PPT为标准,借鉴部分教材内容,AlvinZH学习笔记. 基本概念 1. LR分析:从左到右扫描(L)自底向上进行规约(R),是规范规约,也即最右推导(规范推导) ...
- 编译原理:LL(1)文法的判断,递归下降分析程序
1. 文法 G(S): (1)S -> AB (2)A ->Da|ε (3)B -> cC (4)C -> aADC |ε (5)D -> b|ε 验证文法 G(S)是不 ...
- 编译原理之LL(1)文法的判断,递归下降分析程序
1. 文法 G(S): (1)S -> AB (2)A ->Da|ε (3)B -> cC (4)C -> aADC |ε (5)D -> b|ε 验证文法 G(S)是不 ...
- 编译原理 算法3.8 LR分析 c++11实现
LR分析简介 LR分析是应用最广泛的一类分析方法,它是实用的编译器功能中最强的分析器,其特点是: 1,采用最一般的无回溯移进-规约方法. 2,可分析的文法是LL文法的真超集. 3,能够及时发现错误,及 ...
- 编译原理 #02# 简易递归下降分析程序(js实现)
// 实验存档 截图: 代码: <!DOCTYPE html> <html> <head> <meta charset="UTF-8"&g ...
- 编译原理实习(应用预测分析法LL(1)实现语法分析)
#include<iostream> #include<fstream> #include<iomanip> #include<cstdio> #inc ...
- 编译原理实验 NFA子集法构造DFA,DFA的识别 c++11实现
实验内容 将非确定性有限状态自动机通过子集法构造确定性有限状态自动机. 实验步骤 1,读入NFA状态.注意最后需要设置终止状态. 2,初始态取空,构造DFA的l0状态,将l0加入未标记状态队列que ...
随机推荐
- TensorFlow——常见张量操作的API函数
1.张量 张量可以说是TensorFlow的标志,因为整个框架的名称TensorFlow就是张量流的意思,全面的认识一下张量.在TensorFlow程序使用tensor数据结构来代表所有的数据,在计算 ...
- C++Primer第五版 6.1节练习
练习6.1:实参和形参的区别是什么? 通俗解释: 实参是形参的初始值.编译器能以任意可行的顺序对实参求值.实参的类型必须与对应的形参类型匹配. 详解1) 形参变量只有在函数被调用时才会分配内存,调用结 ...
- 【LC_Lesson5】---求最长的公共前缀
编写一个函数来查找字符串数组中的最长公共前缀. 如果不存在公共前缀,返回空字符串 "". 示例 1: 输入: ["flower","flow" ...
- JMeter——聚合报告
AggregateReport 是 JMeter 常用的一个 Listener,中文被翻译为“聚合报告”. 对于每个请求,它统计响应信息并提供请求数,平均值,最大,最小值,错误率,大约吞吐量(以请 ...
- 指定表单使用的路由 Specifying the Route Used by a Form
- Linux系统实时数据同步inotify+rsync
一.inotify简介 inotify是Linux内核的一个功能,它能监控文件系统的变化,比如删除.读.写和卸载等操作.它监控到这些事件的发生后会默认往标准输出打印事件信息.要使用inotify,Li ...
- Day9-Python3基础-多线程、多进程
1.进程.与线程区别 2.python GIL全局解释器锁 3.线程 语法 join 线程锁之Lock\Rlock\信号量 将线程变为守护进程 Event事件 queue队列 生产者消费者模型 Que ...
- ReactNative---setState与性能的平衡
setState用来更新RN的视图层显示,每一次setState操作都会更新整个 视图,于是对应的是性能消耗,在某些特殊情况下就会造成卡顿 app假死等问题: 因此个人使用setState中总结的原则 ...
- Map梳理
Map梳理 类型介绍 通用Map:用于在应用程序中管理映射,通常在 java.util 程序包中实现 HashMap.Hashtable.Properties.LinkedHashMap.Identi ...
- PKU-3580 SuperMemo(Splay模板题)
SuperMemo 题目链接 Your friend, Jackson is invited to a TV show called SuperMemo in which the participan ...