AI初探1
一个典型的机器学习的过程,首先给出一个输入数据,我们的算法会通过一系列的过
程得到一个估计的函数,这个函数有能力对没有见过的新数据给出一个新的估计,也被称为
构建一个模型。就如同上面的线性回归函数。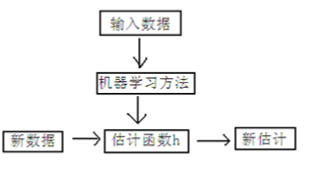
在机器学习(Machine learning)领域,主要有三类不同的学习方法:
监督学习(Supervised learning)、
非监督学习(Unsupervised learning)、
半监督学习(Semi-supervised learning),
监督学习:通过已有的一部分输入数据与输出数据之间的对应关系,生成一个函数,将输入映射到合适的输出,例如分类。
非监督学习:直接对输入数据集进行建模,例如聚类。
半监督学习:综合利用有类标的数据和没有类标的数据,来生成合适的分类函数。
一、监督学习
1、监督式学习(Supervised learning),是一个机器学习中的方法,可以由训练资料中学到或建立一个模式( learning model),并依此模式推测新的实例。训练资料是由输入物件(通常是向量)和预期输出所组成。函数的输出可以是一个连续的值(称为回归分析),或是预测一个分类标签(称作分类)。
2、一个监督式学习者的任务在观察完一些训练范例(输入和预期输出)后,去预测这个函数对任何可能出现的输入的值的输出。要达到此目的,学习者必须以"合理"(见归纳偏向)的方式从现有的资料中一般化到非观察到的情况。在人类和动物感知中,则通常被称为概念学习(concept learning)。
3、监督式学习有两种形态的模型。最一般的,监督式学习产生一个全域模型,会将输入物件对应到预期输出。而另一种,则是将这种对应实作在一个区域模型。(如案例推论及最近邻居法)。为了解决一个给定的监督式学习的问题(手写辨识),必须考虑以下步骤:
1)决定训练资料的范例的形态。在做其它事前,工程师应决定要使用哪种资料为范例。譬如,可能是一个手写字符,或一整个手写的词汇,或一行手写文字。
2)搜集训练资料。这资料须要具有真实世界的特征。所以,可以由人类专家或(机器或传感器的)测量中得到输入物件和其相对应输出。
3)决定学习函数的输入特征的表示法。学习函数的准确度与输入的物件如何表示是有很大的关联度。传统上,输入的物件会被转成一个特征向量,包含了许多关于描述物件的特征。因为维数灾难的关系,特征的个数不宜太多,但也要足够大,才能准确的预测输出。
4)决定要学习的函数和其对应的学习算法所使用的数据结构。譬如,工程师可能选择人工神经网络和决策树。
5)完成设计。工程师接着在搜集到的资料上跑学习算法。可以借由将资料跑在资料的子集(称为验证集)或交叉验证(cross-validation)上来调整学习算法的参数。参数调整后,算法可以运行在不同于训练集的测试集上
另外对于监督式学习所使用的词汇则是分类。现著有著各式的分类器,各自都有强项或弱项。分类器的表现很大程度上地跟要被分类的资料特性有关。并没有某一单一分类器可以在所有给定的问题上都表现最好,这被称为‘天下没有白吃的午餐理论’。各式的经验法则被用来比较分类器的表现及寻找会决定分类器表现的资料特性。决定适合某一问题的分类器仍旧是一项艺术,而非科学。
目前最广泛被使用的分类器有人工神经网络、支持向量机、最近邻居法、高斯混合模型、朴素贝叶斯方法、决策树和径向基函数分类。
二、无监督式学习
1、无监督式学习(Unsupervised Learning )是人工智能网络的一种算法(algorithm),其目的是去对原始资料进行分类,以便了解资料内部结构。有别于监督式学习网络,无监督式学习网络在学习时并不知道其分类结果是否正确,亦即没有受到监督式增强(告诉它何种学习是正确的)。其特点是仅对此种网络提供输入范例,而它会自动从这些范例中找出其潜在类别规则。当学习完毕并经测试后,也可以将之应用到新的案例上。
2、无监督学习里典型的例子就是聚类了。聚类的目的在于把相似的东西聚在一起,而我们并不关心这一类是什么。因此,一个聚类算法通常只需要知道如何计算相似度就可以开始工作了。
三、半监督学习
1、半监督学习的基本思想是利用数据分布上的模型假设, 建立学习器对未标签样本进行标签。
形式化描述为:
给定一个来自某未知分布的样本集S=L∪U, 其中L 是已标签样本集L={(x1,y1),(x2,y2), … ,(x |L|,y|L|)}, U是一个未标签样本集U={x’1,x’2,…,x’|U|},希望得到函数f:X → Y可以准确地对样本x预测其标签y,这个函数可能是参数的,如最大似然法;可能是非参数的,如最邻近法、神经网络法、支持向量机法等;也可能是非数值的,如决策树分类。其中, x与x’ 均为d 维向量, yi∈Y 为样本x i 的标签, |L| 和|U| 分别为L 和U 的大小, 即所包含的样本数。半监督学习就是在样本集S 上寻找最优的学习器。如何综合利用已标签样例和未标签样例,是半监督学习需要解决的问题。
2、半监督学习问题从样本的角度而言是利用少量标注样本和大量未标注样本进行机器学习,从概率学习角度可理解为研究如何利用训练样本的输入边缘概率 P( x )和条件输出概率P ( y | x )的联系设计具有良好性能的分类器。这种联系的存在是建立在某些假设的基础上的,即聚类假设(cluster assumption)和流形假设(maniford assumption)
AI初探1的更多相关文章
- AI初探
看东西应该记笔记,不然如过眼云烟,如只逛商场,不买东西,不留下带走什么,就是浪费时间,没有收获,仅此开始,定期梳理看过的东西. 人工智能的目的是什么呢? 答:让机器表现得更像人类,甚至在某些技能上超越 ...
- AI安全初探——利用深度学习检测DNS隐蔽通道
AI安全初探——利用深度学习检测DNS隐蔽通道 目录 AI安全初探——利用深度学习检测DNS隐蔽通道 1.DNS 隐蔽通道简介 2. 算法前的准备工作——数据采集 3. 利用深度学习进行DNS隐蔽通道 ...
- 初探机器学习之使用百度AI服务实现图片识别与相似图片
一.百度云AI服务 最近在调研一些云服务平台的AI(人工智能)服务,了解了一下阿里云.腾讯云和百度云.其中,百度云提供了图像识别及图像搜索,而且还细分地提供了相似图片这项服务,比较符合我的需求,且百度 ...
- AI人工智能系列随笔:syntaxnet 初探(1)
人工智能是 最近的一个比较火的名词,相信大家对于阿尔法狗都不陌生吧?其实我对人工智能以前也是非常抵触的,因为我认为机器人会取代人类,成为地球乃至宇宙的霸主,但是人工智能带给我的这种冲击,我个人感觉是欲 ...
- 游戏中的人工智能——初探AI
一.游戏中的人工智能 让游戏具有挑战性: 让游戏好玩的关键因素是为之找到合适的难度等级: 人工智能在游戏中的作用是通过提供富有挑战性的竞争对象来让游戏更好玩,而在游戏中行动逼真的非玩家角色(NPC), ...
- AI人工智能系列随笔
初探 AI人工智能系列随笔:syntaxnet 初探(1)
- 初探VIM编辑器
初探VIM 引言---什么是Vim? 接触Linux这么久,想必对于一切皆文件的哲学思想已经不陌生了.因此,学习并掌握用一款Linux文本编辑器,对于玩转LInux来说,是很有必要的. vi编辑器是U ...
- A*寻路初探 GameDev.net
A*寻路初探 GameDev.net MulinB按:经典的智能寻路算法,一个老外写的很透彻很清晰,很容易让人理解神秘的A*算法.以下是一个中文翻译版. A*寻路初探 GameDev.net 作者: ...
- A*寻路初探 GameDev.net 转载
A*寻路初探 GameDev.net 译者序:很久以前就知道了A*算法,但是从未认真读过相关的文章,也没有看过代码,只是脑子里有个模糊的概念.这次决定从头开始,研究一下这个被人推崇备至的简单方法,作为 ...
随机推荐
- 【一起学源码-微服务】Nexflix Eureka 源码九:服务续约源码分析
前言 前情回顾 上一讲 我们讲解了服务发现的相关逻辑,所谓服务发现 其实就是注册表抓取,服务实例默认每隔30s去注册中心抓取一下注册表增量数据,然后合并本地注册表数据,最后有个hash对比的操作. 本 ...
- kotlin + springboot整合mybatis操作mysql数据库及单元测试
项目mybatis操作数据库参考: http://how2j.cn/k/springboot/springboot-mybatis/1649.html?p=78908 junit对controller ...
- Qt5 http/HTTPS访问 以及JSON解析的实用
实用QT5访问HTTP/以及HTTPS协议访问 并且调用Json解析 #include "mywidget.h" #include "ui_mywidget.h" ...
- 洛谷$P2150\ [NOI2015]$寿司晚宴 $dp$
正解:$dp$ 解题报告: 传送门$QwQ$. 遇事不决写$dp$($bushi$.讲道理这题一看就感觉除了$dp$也没啥很好的算法能做了,于是考虑$dp$呗 先看部分分?$30pts$发现质因数个数 ...
- win服务器管理工具,服务器vps管理
win系列服务器,vps桌面如何管理?用这个工具: IIS7远程桌面批量管理,同时管理上千台vps,服务器,3389远程端口.
- Markdown破解及汉化
首先,附上用到的资源链接: 链接:https://pan.baidu.com/s/1ULvvCPcCv_P3KyD9ajXUjQ 提取码:5fkb 第一步 直接解压就可以,解压后运行该程序,会出现下图 ...
- 程序员初学者参考 ---懂得基础语法后如何做一个自己的case?
对于很多人来说,我懂java语法,甚至面向对象的特性啦这些都是有了解的,但我就是不会做项目,其实项目真有那么难吗? 对于基础不牢固的人来说,我还不会这个基础点,那个还没学呢,你让我做个项目,我保证做不 ...
- 洛谷P1082 同余方程 题解
题目链接:https://www.luogu.com.cn/problem/P1082 题目大意: 求关于 \(x\) 的同余方程 ax≡1(mod b) 的最小正整数解. 告诉你 \(a,b\) 求 ...
- 小小知识点(二十一)如何修改PPT母版上无法直接点击修改的文字
1. 进入PPT后,选择下图右上角红色圈出的“视图”,接着选择下方红色圈出的“幻灯片母版”: 2.点击进入母版,如下图所示,最上面一栏第一个选项变成了“幻灯片母版”,在下面一栏最右边变成了“关闭母版视 ...
- getopt命令
最近学习了一下getopt(不是getopts)命令来处理执行shell脚本传入的参数,在此记录一下,包括长选项.短选项.以及选项的值出现的空格问题,最后写了个小的脚本来处理输入的参数 首先新建一个t ...