centos7搭建hadoop2.10高可用(HA)
本篇介绍在centos7中搭建hadoop2.10高可用集群,首先准备6台机器:2台nn(namenode);4台dn(datanode);3台jn(journalnode);3台zk(zookeeper)
| IP | hostname | 进程 |
| 192.168.30.141 | s141 | nn1(namenode),zkfc(DFSZKFailoverController),zk(QuorumPeerMain) |
| 192.168.30.142 | s142 | dn(datanode), jn(journalnode),zk(QuorumPeerMain) |
| 192.168.30.143 | s143 | dn(datanode), jn(journalnode),zk(QuorumPeerMain) |
| 192.168.30.144 | s144 | dn(datanode), jn(journalnode) |
| 192.168.30.145 | s145 | dn(datanode) |
| 192.168.30.146 | s146 | nn2(namenode),zkfc(DFSZKFailoverController) |
各个机器 jps进程:
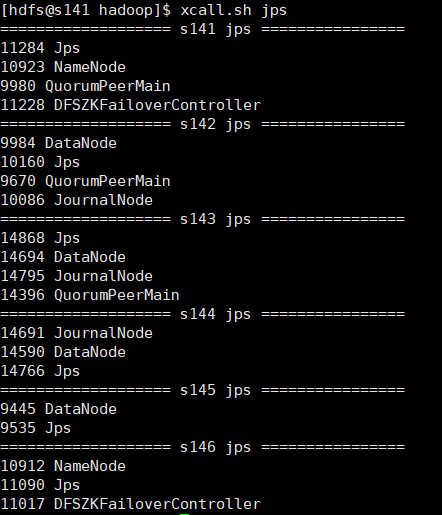
由于本人使用的是vmware虚拟机,所以在配置好一台机器后,使用克隆,克隆出剩余机器,并修改hostname和IP,这样每台机器配置就都统一了每台机器配置 添加hdfs用户及用户组,配置jdk环境,安装hadoop,本次搭建高可用集群在hdfs用户下,可以参照:centos7搭建hadoop2.10伪分布模式
下面是安装高可用集群的一些步骤和细节:
1.设置每台机器的hostname 和 hosts
修改hosts文件,hosts设置有后可以使用hostname访问机器,这样比较方便,修改如下:
127.0.0.1 locahost
192.168.30.141 s141
192.168.30.142 s142
192.168.30.143 s143
192.168.30.144 s144
192.168.30.145 s145
192.168.30.146 s146
2.设置ssh无密登录,由于s141和s146都为namenode,所以要将这两台机器无密登录到所有机器,最好hdfs用户和root用户都设置无密登录
我们将s141设置为nn1,s146设置为nn2,就需要s141、s146能够通过ssh无密登录到其他机器,这样就需要在s141和s146机器hdfs用户下生成密钥对,并将s141和s146公钥发送到其他机器放到~/.ssh/authorized_keys文件中,更确切的说要将公钥添加的所有机器上(包括自己)
在s141和s146机器上生成密钥对:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
将id_rsa.pub文件内容追加到s141-s146机器的/home/hdfs/.ssh/authorized_keys中,现在其他机器暂时没有authorized_keys文件,我们就将id_rsa.pub更名为authorized_keys即可,如果其他机器已存在authorized_keys文件可以将id_rsa.pub内容追加到该文件后,远程复制可以使用scp命令:
s141机器公钥复制到其他机器
scp id_rsa.pub hdfs@s141:/home/hdfs/.ssh/id_rsa_141.pub
scp id_rsa.pub hdfs@s142:/home/hdfs/.ssh/id_rsa_141.pub
scp id_rsa.pub hdfs@s143:/home/hdfs/.ssh/id_rsa_141.pub
scp id_rsa.pub hdfs@s144:/home/hdfs/.ssh/id_rsa_141.pub
scp id_rsa.pub hdfs@s145:/home/hdfs/.ssh/id_rsa_141.pub
scp id_rsa.pub hdfs@s146:/home/hdfs/.ssh/id_rsa_141.pub
s146机器公钥复制到其他机器
scp id_rsa.pub hdfs@s141:/home/hdfs/.ssh/id_rsa_146.pub
scp id_rsa.pub hdfs@s142:/home/hdfs/.ssh/id_rsa_146.pub
scp id_rsa.pub hdfs@s143:/home/hdfs/.ssh/id_rsa_146.pub
scp id_rsa.pub hdfs@s144:/home/hdfs/.ssh/id_rsa_146.pub
scp id_rsa.pub hdfs@s145:/home/hdfs/.ssh/id_rsa_146.pub
scp id_rsa.pub hdfs@s146:/home/hdfs/.ssh/id_rsa_146.pub
在每台机器上可以使用cat将秘钥追加到authorized_keys文件
cat id_rsa_141.pub >> authorized_keys
cat id_rsa_146.pub >> authorized_keys
此时authorized_keys文件权限需要改为644(注意,经常会因为这个权限问题导致ssh无密登录失败)
chmod 644 authorized_keys
3.配置hadoop配置文件(${hadoop_home}/etc/hadoop/)
配置细节:
注意: s141和s146具有完全一致的配置,尤其是ssh.
1) 配置nameservice
[hdfs-site.xml]
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
2) dfs.ha.namenodes.[nameservice ID]
[hdfs-site.xml]
<!-- myucluster下的名称节点两个id -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
3) dfs.namenode.rpc-address.[nameservice ID].[name node ID]
[hdfs-site.xml]
配置每个nn的rpc地址。
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>s141:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>s146:8020</value>
</property>
4) dfs.namenode.http-address.[nameservice ID].[name node ID]
配置webui端口
[hdfs-site.xml]
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>s141:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>s146:50070</value>
</property>
5) dfs.namenode.shared.edits.dir
名称节点共享编辑目录.选择三台journalnode节点,这里选择s142、s143、s144三台机器
[hdfs-site.xml]
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://s142:8485;s143:8485;s144:8485/mycluster</value>
</property>
6) dfs.client.failover.proxy.provider.[nameservice ID]
配置一个HA失败转移的java类(改配置是固定的),client使用它判断哪个节点是激活态。
[hdfs-site.xml]
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
7) dfs.ha.fencing.methods
脚本列表或者java类,在容灾保护激活态的nn.
[hdfs-site.xml]
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property> <property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hdfs/.ssh/id_rsa</value>
</property>
8) fs.defaultFS
配置hdfs文件系统名称服务。这里的mycluster为上面配置的dfs.nameservices
[core-site.xml]
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
9) dfs.journalnode.edits.dir
配置JN存放edit的本地路径。
[hdfs-site.xml]
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hdfs/hadoop/journal</value>
</property>
完整配置文件:
core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster/</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hdfs/hadoop</value>
</property>
</configuration>
hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration>
<property>
<name>dfs.replication</name>
<value></value>
</property>
<property>
<name>dfs.hosts</name>
<value>/opt/soft/hadoop/etc/dfs.include.txt</value>
</property>
<property>
<name>dfs.hosts.exclude</name>
<value>/opt/soft/hadoop/etc/dfs.hosts.exclude.txt</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>s141:</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>s146:</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>s141:</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>s146:</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://s142:8485;s143:8485;s144:8485/mycluster</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property> <property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hdfs/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hdfs/hadoop/journal</value>
</property>
</configuration>
mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml
<?xml version="1.0"?> <configuration> <!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>s141</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
4. 部署细节
1)在jn节点分别启动jn进程(s142,s143,s144)
hadoop-daemon.sh start journalnode
2)启动jn之后,在两个NN之间进行disk元数据同步
a)如果是全新集群,先format文件系统,只需要在一个nn上执行。
[s141|s146]
hadoop namenode -format
b)如果将非HA集群转换成HA集群,复制原NN的metadata到另一个NN上.
1.步骤一
在s141机器上,将hadoop数据复制到s146对应的目录下
scp -r /home/hdfs/hadoop/dfs hdfs@s146:/home/hdfs/hadoop/
2.步骤二
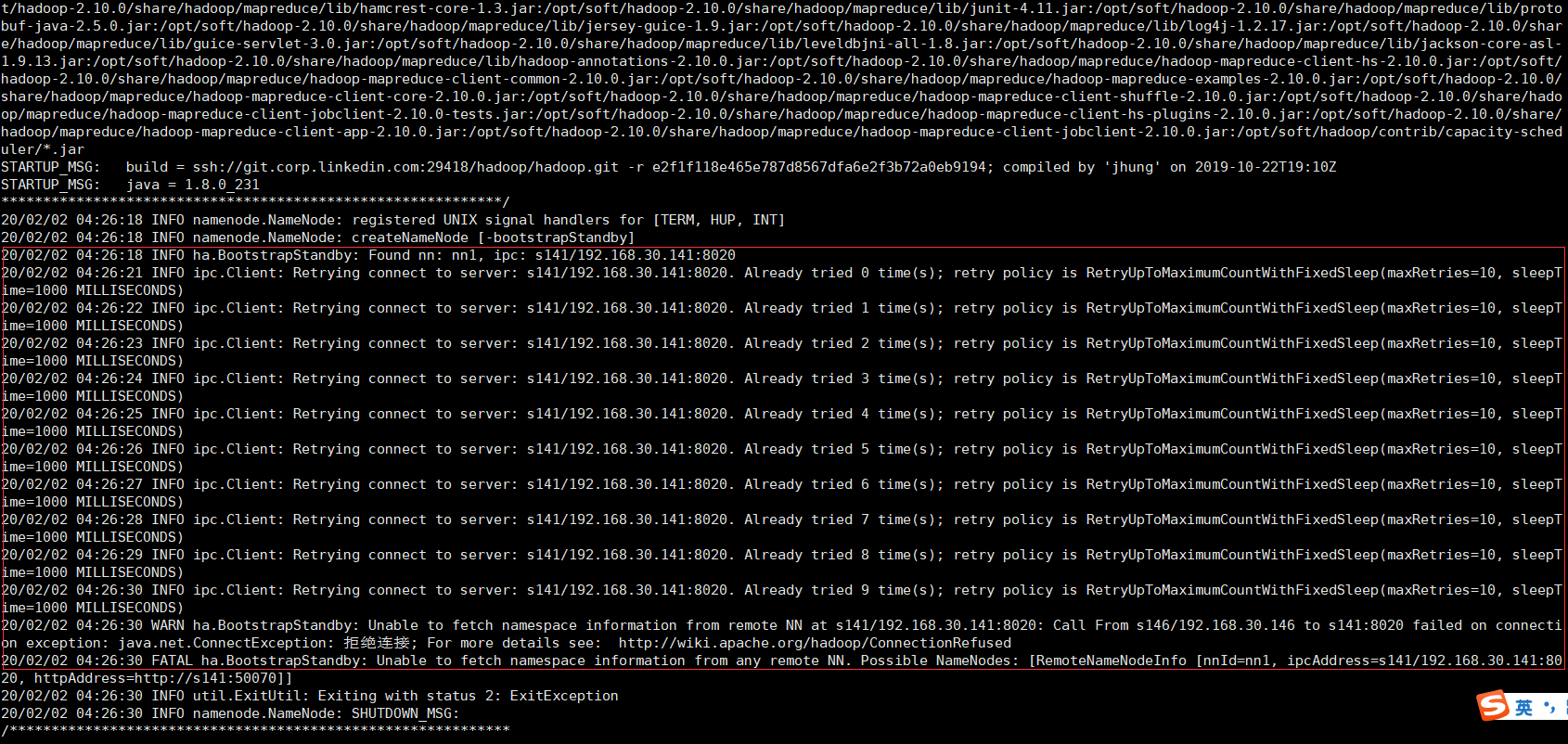
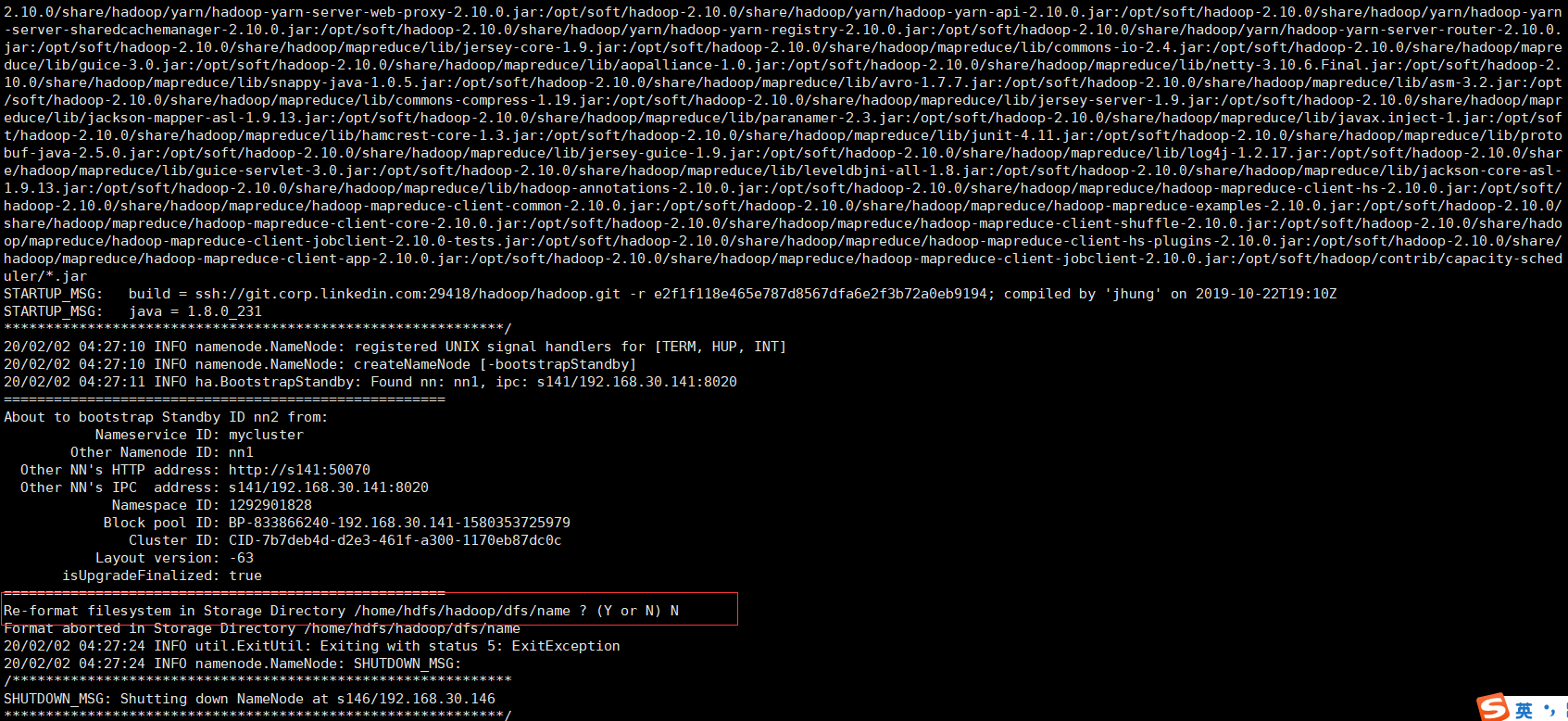
在新的nn(未格式化的nn,我这里是s146)上运行以下命令,实现待命状态引导。注意:需要s141namenode为启动状态(可以执行:hadoop-daemon.sh start namenode )。
hdfs namenode -bootstrapStandby
如果没有启动s141名称节点,就会失败,因为引导standby节点需要连接原nn节点,如图:
启动s141名称节点后,在s141上执行命令
hadoop-daemon.sh start namenode
然后在执行待命引导命令,注意:提示是否格式化,选择N,如图:
3. 步骤三
在其中一个NN上执行以下命令,完成edit日志到jn节点的传输。
hdfs namenode -initializeSharedEdits
如果执行过程中报:java.nio.channels.OverlappingFileLockException 错误:
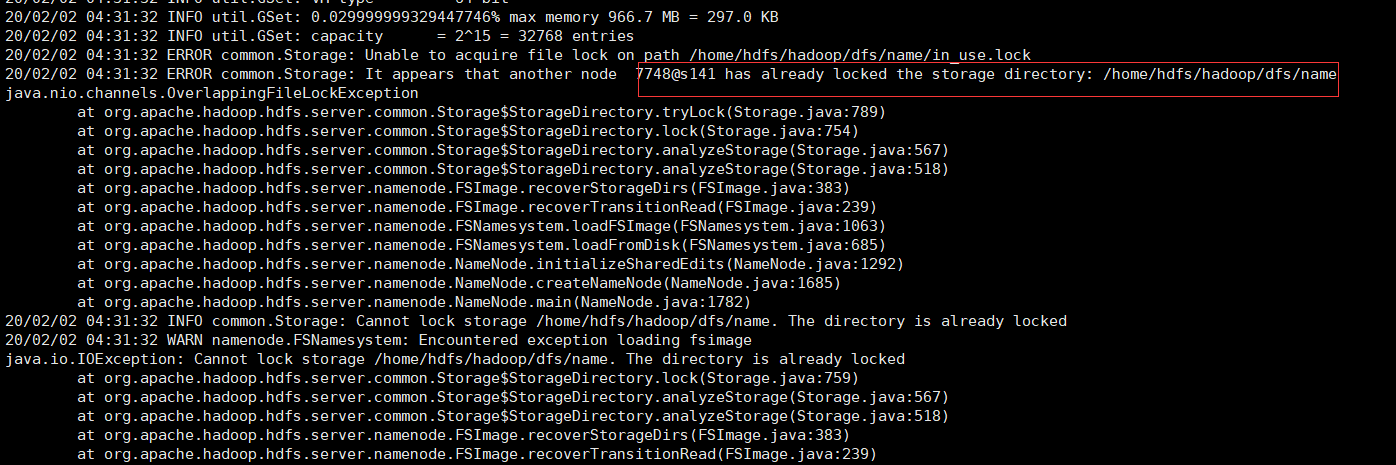
说明namenode在启动中,需要停掉namenode节点(hadoop-daemon.sh stop namenode)
执行完后查看s142,s143,s144是否有edit数据,这里查看生产了mycluster目录,里面有编辑日志数据,如下:
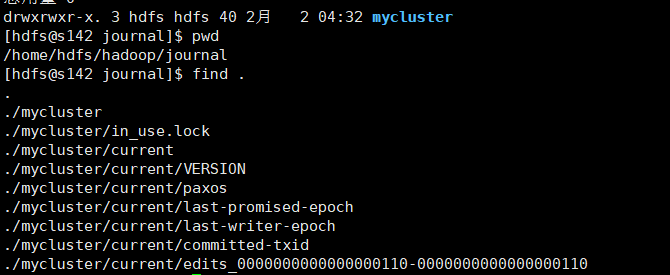
4.步骤四
启动所有节点.
在s141上启动名称节点和所有数据节点:
hadoop-daemon.sh start namenode
hadoop-daemons.sh start datanode
在s146上启动名称节点
hadoop-daemon.sh start namenode
此时在浏览器中访问 http://192.168.30.141:50070/ 和 http://192.168.30.146:50070/ 你会发现两个namenode都为standby
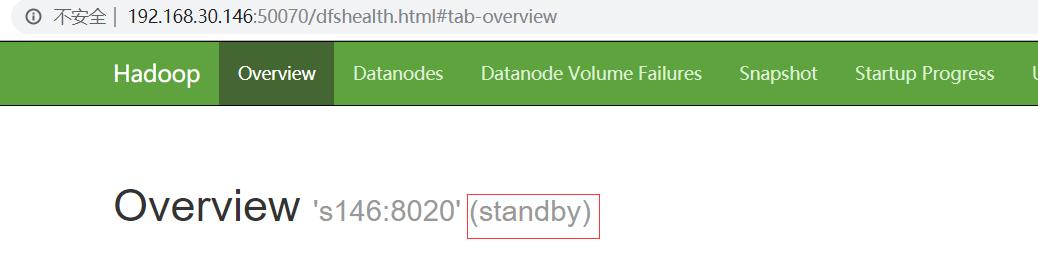
这时需要手动使用命令将其中一个切换为激活态,这里将s141(nn1)设置为active
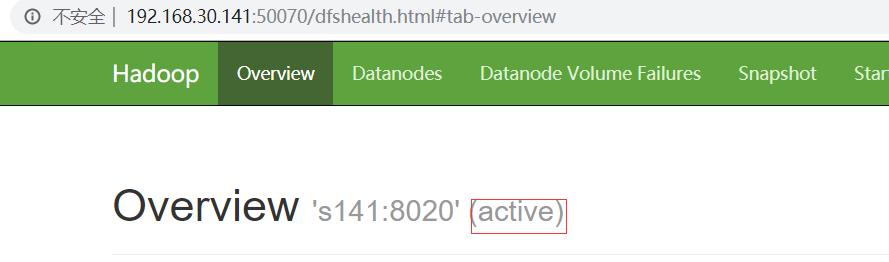
hdfs haadmin -transitionToActive nn1
此时s141就为active
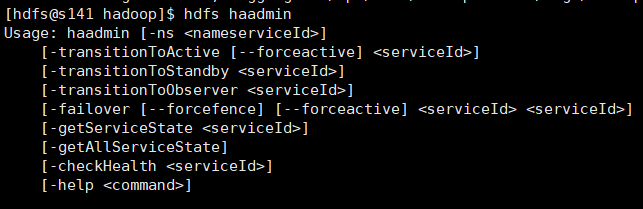
hdfs haadmin常用命令:
至此手动容灾高可用配置完成,但是这种方式不智能,不能够自动感知容灾,所以下面介绍自动容灾配置
5.自动容灾配置
需要引入zookeeper quarum 和 zk 容灾控制器(ZKFC)两个组件
搭建zookeeper集群,选择s141,s142,s143三台机器,下载 zookeeper:http://mirror.bit.edu.cn/apache/zookeeper/zookeeper-3.5.6
1) 解压zookeeper,并创建zk软链接:
#解压zk
tar -xzvf apache-zookeeper-3.5.-bin.tar.gz -C /opt/soft/zookeeper-3.5.6
#进入/opt/soft下
cd /opt/soft
#创建zk软链接
ln -s zookeeper-3.5.6 zk
2) 配置环境变量,在/etc/profile中添加zk环境变量,并重新编译/etc/profile文件
source /etc/profile
3) 配置zk配置文件,复制${ZK_HOME}/conf/zoo_simple.cfg 为同目录下 zoo.cfg,三台机器配置文件统一
# The number of milliseconds of each tick
tickTime=
# The number of ticks that the initial
# synchronization phase can take
initLimit=
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/home/hdfs/zookeeper
# the port at which the clients will connect
clientPort=
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=
# Purge task interval in hours
# Set to "" to disable auto purge feature
#autopurge.purgeInterval=
server.=s141::
server.=s142::
server.=s143::
4)分别
在s141的/home/hdfs/zookeeper(在zoo.cfg配置文件中配置的dataDir路径)目录下创建myid文件,值为1(对应zoo.cfg配置文件中的server.1)
在s142的/home/hdfs/zookeeper(在zoo.cfg配置文件中配置的dataDir路径)目录下创建myid文件,值为2(对应zoo.cfg配置文件中的server.2)
在s143的/home/hdfs/zookeeper(在zoo.cfg配置文件中配置的dataDir路径)目录下创建myid文件,值为3(对应zoo.cfg配置文件中的server.3)
5) 分别在每台机器上启动zk
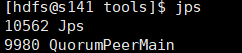
zkServer.sh start
启动成功会出现zk进程:QuorumPeerMain
配置hdfs相关信息:
1)停止hdfs所有进程
stop-all.sh
2) 配置hdfs-site.xml,启用自动容灾.
[hdfs-site.xml]
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
3) 配置core-site.xml,指定zk的连接地址.
<property>
<name>ha.zookeeper.quorum</name>
<value>s141:,s142:,s143:</value>
</property>
4) 分发以上两个文件到所有节点。
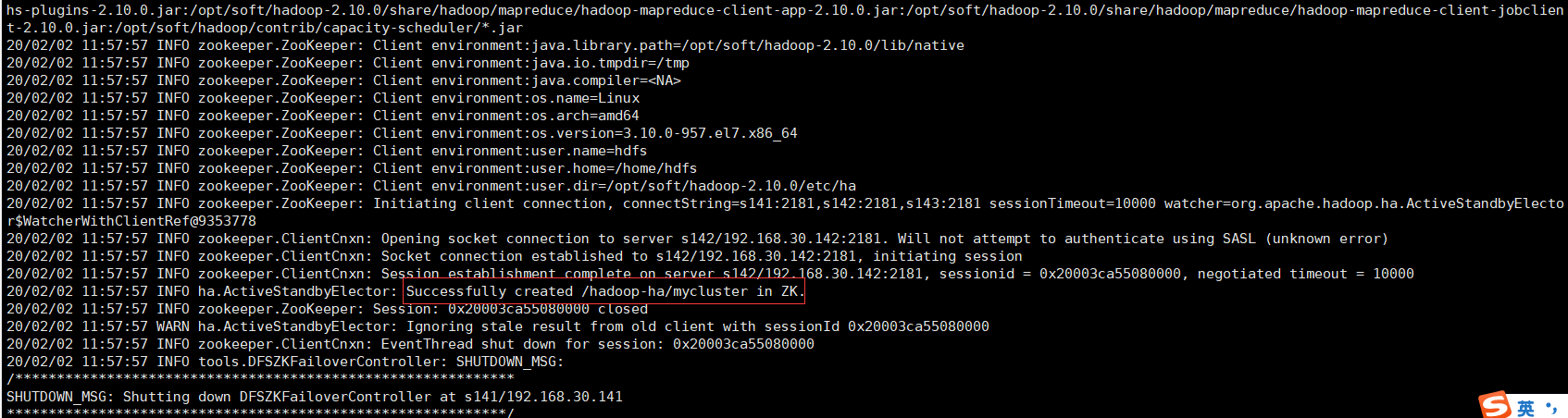
5) 在其中的一台NN(s141|s146),使用以下命令在ZK中初始化HA状态
hdfs zkfc -formatZK
出现如下结果说明成功:
也可去zk中查看:

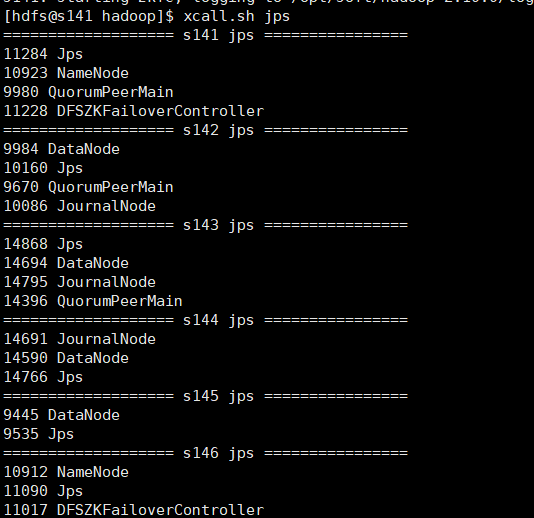
6) 启动hdfs集群
start-dfs.sh
查看各个机器进程:
启动成功,再看一下webui
s146为激活态

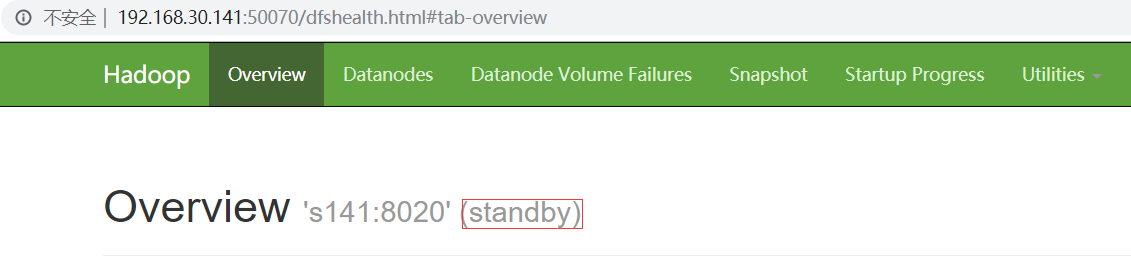
s141为待命态
至此hadoop 自动容灾HA搭建完成,希望对你有所帮助
centos7搭建hadoop2.10高可用(HA)的更多相关文章
- centos7搭建hadoop2.10完全分布式
本篇介绍在centos7中大家hadoop2.10完全分布式,首先准备4台机器:1台nn(namenode);3台dn(datanode) IP hostname 进程 192.168.30.141 ...
- centos7搭建hadoop2.10伪分布模式
1.准备一台Vmware虚拟机,添加hdfs用户及用户组,配置网络见 https://www.cnblogs.com/qixing/p/11396835.html 在root用户下 添加hdfs用户, ...
- hadoop学习笔记(七):hadoop2.x的高可用HA(high avaliable)和联邦F(Federation)
Hadoop介绍——HA与联邦 0.1682019.06.04 13:30:55字数 820阅读 138 Hadoop 1.0中HDFS和MapReduce在高可用.扩展性等方面存在问题: –HDFS ...
- 搭建 RabbitMQ Server 高可用集群
阅读目录: 准备工作 搭建 RabbitMQ Server 单机版 RabbitMQ Server 高可用集群相关概念 搭建 RabbitMQ Server 高可用集群 搭建 HAProxy 负载均衡 ...
- 搭建 RabbitMQ Server 高可用集群【转】
阅读目录: 准备工作 搭建 RabbitMQ Server 单机版 RabbitMQ Server 高可用集群相关概念 搭建 RabbitMQ Server 高可用集群 搭建 HAProxy 负载均衡 ...
- (转)基于keepalived搭建MySQL的高可用集群
基于keepalived搭建MySQL的高可用集群 原文:http://www.cnblogs.com/ivictor/p/5522383.html MySQL的高可用方案一般有如下几种: keep ...
- Oracle Compute云快速搭建MySQL Keepalived高可用架构
最近有个客户在测试Oracle Compute云,他们的应用需要使用MySQL数据库,由于是企业级应用一定要考虑高可用架构,因此有需求要在Oracle Compute云上搭建MySQL高可用集群.客户 ...
- Corosync+Pacemaker+DRBD+MySQL 实现高可用(HA)的MySQL集群
大纲一.前言二.环境准备三.Corosync 安装与配置四.Pacemaker 安装与配置五.DRBD 安装与配置六.MySQL 安装与配置七.crmsh 资源管理 推荐阅读: Linux 高可用(H ...
- 浅谈web应用的负载均衡、集群、高可用(HA)解决方案(转)
1.熟悉几个组件 1.1.apache —— 它是Apache软件基金会的一个开放源代码的跨平台的网页服务器,属于老牌的web服务器了,支持基于Ip或者域名的虚拟主机,支持代理服务器,支持安 ...
随机推荐
- POJ 1166 The Clocks [BFS] [位运算]
1.题意:有一组3*3的只有时针的挂钟阵列,每个时钟只有0,3,6,9三种状态:对时针阵列有9种操作,每种操作只对特点的几个时钟拨一次针,即将时针顺时针波动90度,现在试求从初试状态到阵列全部指向0的 ...
- 【Linux】查看系统资源及相关信息
查看系统信息: uname -a # 查看Linux内核版本信息 cat /proc/version # 查看内核版本 cat /etc/issue # 查看系统版本 lsb_release -a # ...
- EasyUI清空combotree下拉框图标
代码: //清空combotree下拉框图标 $(".tree-icon,.tree-file").removeClass("tree-icon tree-file&qu ...
- 0009 CSS基础选择器( 标签、类、id、通配符)
typora-copy-images-to: media 第01阶段.前端基础.CSS基础选择器 CSS选择器(重点) 学习目标: 理解 能说出选择器的作用 id选择器和类选择器的区别 应用 能够使用 ...
- 20191121-8 Scrum立会报告+燃尽图 04
此作业要求参见https://edu.cnblogs.com/campus/nenu/2019fall/homework/10068 一: 组名:组长组 组长:杨天宇 组员:魏新 罗杨美慧 王歆瑶 ...
- $POJ1015\ Jury\ Compromise\ Dp$/背包
洛谷传送门 $Sol$ 这是一道具有多个“体积维度”的$0/1$背包问题. 把$N$个候选人看做$N$个物品,那么每个物品有如下三种体积: 1.“人数”,每个候选人的“人数”都是$1$,最终要填满容积 ...
- 洛谷P1776 宝物筛选 题解 多重背包
题目链接:https://www.luogu.com.cn/problem/P1776 题目大意: 这道题目是一道 多重背包 的模板题. 首先告诉你 n 件物品和背包的容量 V ,然后分别告诉你 n ...
- U盘中了蠕虫病毒,文件夹都变成exe了,怎么办?
昨天做实验,用U盘拷了实验室的文件,然后就中了病毒了(无奈),U盘里的文件全都变成了exe.有点慌张,我的U盘里存了很多课程资料.然而,我懒得下载杀毒软件.参考这位博主的做法,我成功的找回了我隐藏的文 ...
- Redis-NoSQL入门和概述(一)
NoSQL简史及定义 NoSQL 这个术语最早是在 1998 年被Carlo Strozzi命名在他的轻量的,开源的关系型数据库上的,但是该数据库没有提供标准的SQL接口:在2009 年再次被Eric ...
- Fastadmin 如何引入 layui 模块
FastAdmin基于RequireJS进行前端JS模块的管理,因此如果我们需要再引入第三方JS插件,则必按照RequireJS的规则进行载入.如果你还不了解什么是RequireJS,可以先简单了解下 ...