Delta Lake源码分析
Delta Lake源码分析
本文主要从代码的具体实现方面进行讲解,关于delta lake的事务日志原理,可以看这篇博客,讲解的很详细。
Delta Lake元数据
delta lake 包含Protocol、Metadata、FileAction(AddFile、RemoveFile)、CommitInfo和SetTransaction这几种元数据action。
- Protocol:这是delta lake自身的版本管理,一般只出现在第一次的commit日志里(之后版本升级应该也会有);
- Metadata:存储delta表的schema信息,第一次commit和每次修改schema时出现,以最后一次出现的为准;
- FileAction:文件的相关操作,delta lake的文件操作只有添加文件和删除文件;
- CommitInfo:保存关于本次更改的原始信息,如修改时间,操作类型,读取的数据版本等;
- SetTransaction:设置application的提交版本,一般用于流式计算的一致性控制(exactlyOnce)。
//初始的commit log会包含protocol和metaData的信息
{"commitInfo":{"timestamp":1576480709055,"operation":"WRITE","operationParameters":{"mode":"ErrorIfExists","partitionBy":"[]"},"isBlindAppend":true}}
{"protocol":{"minReaderVersion":1,"minWriterVersion":2}}
{"metaData":{"id":"fe0948b9-8253-4942-9e28-3a89321a004d","format":{"provider":"parquet","options":{}},"schemaString":"{\"type\":\"struct\",\"fields\":[{\"name\":\"azkaban_tag\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"project_name\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"flow_name\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"job_name\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"application_name\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"queue_name\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"master_name\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}}]}","partitionColumns":[],"configuration":{},"createdTime":1576480707164}}
{"add":{"path":"part-00000-dc1d1431-1e4b-4337-b111-6a447bad15fc-c000.snappy.parquet","partitionValues":{},"size":1443338,"modificationTime":1576480711000,"dataChange":true}}
//之后的commit log会记录下当前操作的信息
{"commitInfo":{"timestamp":1576481270646,"operation":"DELETE","operationParameters":{"predicate":"[\"(`master_name` = 'mob_analyse')\"]"},"readVersion":0,"isBlindAppend":false}}
{"remove":{"path":"part-00000-dc1d1431-1e4b-4337-b111-6a447bad15fc-c000.snappy.parquet","deletionTimestamp":1576481270643,"dataChange":true}}
{"add":{"path":"part-00000-d6431884-390d-4837-865c-f6e52f0e2cf5-c000.snappy.parquet","partitionValues":{},"size":1430267,"modificationTime":1576481273000,"dataChange":true}}
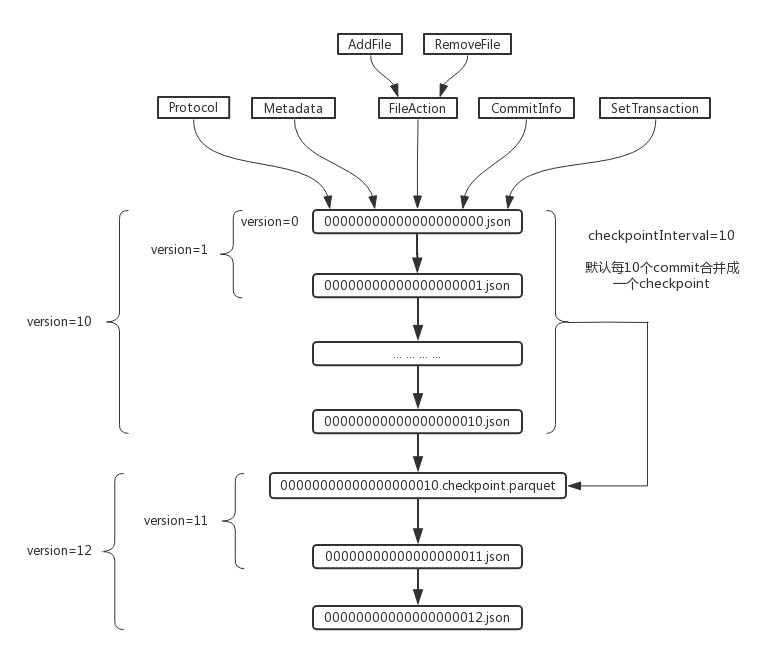
snapshot生成
当存在checkpoint文件时,DeltaLog类的currentSnapshot会根据checkpoint和之后的json日志来计算快照。
- 通过loadMetadataFromFile()方法读取_last_checkpoint文件获得最新的checkpoint路径;
- 通过LogStore.listFrom()方法获得checkpoint之后版本的delta log文件;
- 使用verifyDeltaVersions方法验证delta log的文件是否是连续的(日志版本必须是连续的,每个commit log都需要被计算);
- 解析并聚合checkpoint和delta log为Seq[DeltaLogFileIndex],然后new Snapshot();
- Snapshot里的stateReconstruction会使用InMemoryLogReplay来计算日志中的各种action,获得最终的状态信息。
当没有checkpoint文件时,通过DeltaLog类的update方法来计算快照。
- 当不存在_last_checkpoint文件时,new一个版本号为-1的Snapshot;
- 检测到currentSnapshot的版本为-1,调用update方法,实际工作的是updateInternal方法,它会把当前的快照更新到最新版本;
- updateInternal会遍历出版本号小于等于 max(当前版本,0)的checkpoint文件和delta log,并通过new Snapshot将这些更新添加到当前快照中。
@volatile private var currentSnapshot: Snapshot = lastCheckpoint.map { c =>
val checkpointFiles = c.parts
.map(p => checkpointFileWithParts(logPath, c.version, p)) //目前版本没用到parts,疑似商业版功能
.getOrElse(Seq(checkpointFileSingular(logPath, c.version))) //返回最新checkpoint文件路径
val deltas = store.listFrom(deltaFile(logPath, c.version + 1)) //返回checkpoint之后版本的json文件
.filter(f => isDeltaFile(f.getPath))
.toArray
val deltaVersions = deltas.map(f => deltaVersion(f.getPath))
verifyDeltaVersions(deltaVersions) //验证版本日志是否连续
val newVersion = deltaVersions.lastOption.getOrElse(c.version)
logInfo(s"Loading version $newVersion starting from checkpoint ${c.version}")
try {
val deltaIndex = DeltaLogFileIndex(DeltaLog.COMMIT_FILE_FORMAT, deltas)
val checkpointIndex = DeltaLogFileIndex(DeltaLog.CHECKPOINT_FILE_FORMAT, fs, checkpointFiles)
val snapshot = new Snapshot( //创建快照
logPath,
newVersion,
None,
checkpointIndex :: deltaIndex :: Nil,
minFileRetentionTimestamp,
this,
// we don't want to make an additional RPC here to get commit timestamps when "deltas" is
// empty. The next "update" call will take care of that if there are delta files.
deltas.lastOption.map(_.getModificationTime).getOrElse(-1L))
validateChecksum(snapshot) //通过crc文件校验版本,但是目前delta版本并没有生成crc文件,后续会更新或者又是商业版的坑?
lastUpdateTimestamp = clock.getTimeMillis()
snapshot
} catch {
case e: FileNotFoundException
if Option(e.getMessage).exists(_.contains("parquet does not exist")) =>
recordDeltaEvent(this, "delta.checkpoint.error.partial")
throw DeltaErrors.missingPartFilesException(c, e)
case e: AnalysisException if Option(e.getMessage).exists(_.contains("Path does not exist")) =>
recordDeltaEvent(this, "delta.checkpoint.error.partial")
throw DeltaErrors.missingPartFilesException(c, e)
}
}.getOrElse {
new Snapshot(logPath, -1, None, Nil, minFileRetentionTimestamp, this, -1L) //没有checkpoint文件时,从头开始读delta log计算
}
// Reconstruct the state by applying deltas in order to the checkpoint.
// We partition by path as it is likely the bulk of the data is add/remove.
// Non-path based actions will be collocated to a single partition.
private val stateReconstruction = {
val implicits = spark.implicits
import implicits._
val numPartitions = spark.sessionState.conf.getConf(DeltaSQLConf.DELTA_SNAPSHOT_PARTITIONS)
val checkpointData = previousSnapshot.getOrElse(emptyActions)
val deltaData = load(files)
val allActions = checkpointData.union(deltaData)
val time = minFileRetentionTimestamp
val hadoopConf = new SerializableConfiguration(spark.sessionState.newHadoopConf())
val logPath = path.toUri // for serializability
allActions.as[SingleAction]
.mapPartitions { actions =>
val hdpConf = hadoopConf.value
actions.flatMap {
_.unwrap match {
case add: AddFile => Some(add.copy(path = canonicalizePath(add.path, hdpConf)).wrap)
case rm: RemoveFile => Some(rm.copy(path = canonicalizePath(rm.path, hdpConf)).wrap)
case other if other == null => None
case other => Some(other.wrap)
}
}
}
.withColumn("file", assertLogBelongsToTable(logPath)(input_file_name()))
.repartition(numPartitions, coalesce($"add.path", $"remove.path"))
.sortWithinPartitions("file")
.as[SingleAction]
.mapPartitions { iter =>
val state = new InMemoryLogReplay(time)
state.append(0, iter.map(_.unwrap))
state.checkpoint.map(_.wrap)
}
}
日志提交
日志的提交是在OptimisticTransactionImpl的commit()中实现的。
- 调用prepareCommit方法做各种检查,如字段是否重复、是否第一次提交等;
- 判断本次commit的隔离等级,目前只检查是否修改了数据,若修改了数据则使用Serializable级别,否则用SnapshotIsolation,因为不修改数据的情况下,它可以提供和Serializable一样的保证,且能在之后的冲突检测中更容易通过(writeIsolation还没有使用,后期会更新吧);
- 使用doCommit方法提交action日志,生成当前version+1的log文件,如果同名文件已存在,则提交失败;
- doCommit失败后会调用checkAndRetry进行重试,遍历读version后的所有commit log,进行冲突检测,检测通过后再次提交doCommit;
- 完成doCommit后,postCommit方法会检查是否满足checkpointInterval,如果满足条件则调用deltaLog.checkpoint()方法生成新的checkpoint文件,并更新_last_checkpoint文件。
/**
* Modifies the state of the log by adding a new commit that is based on a read at
* the given `lastVersion`. In the case of a conflict with a concurrent writer this
* method will throw an exception.
*
* @param actions Set of actions to commit
* @param op Details of operation that is performing this transactional commit
*/
@throws(classOf[ConcurrentModificationException])
def commit(actions: Seq[Action], op: DeltaOperations.Operation): Long = recordDeltaOperation(
deltaLog,
"delta.commit") {
val version = try {
// Try to commit at the next version.
var finalActions = prepareCommit(actions, op) //各种检查
// Find the isolation level to use for this commit
val noDataChanged = actions.collect { case f: FileAction => f.dataChange }.forall(_ == false)
val isolationLevelToUse = if (noDataChanged) { //0.5版本新特性,很简单的隔离等级判定,writeIsolation还没有使用,等后续更新吧
// If no data has changed (i.e. its is only being rearranged), then SnapshotIsolation
// provides Serializable guarantee. Hence, allow reduced conflict detection by using
// SnapshotIsolation of what the table isolation level is.
SnapshotIsolation
} else {
Serializable
}
val isBlindAppend = { //判断是否不读取delta数据且所有的文件操作都是AddFile
val dependsOnFiles = readPredicates.nonEmpty || readFiles.nonEmpty
val onlyAddFiles =
finalActions.collect { case f: FileAction => f }.forall(_.isInstanceOf[AddFile])
onlyAddFiles && !dependsOnFiles
}
if (spark.sessionState.conf.getConf(DeltaSQLConf.DELTA_COMMIT_INFO_ENABLED)) { //默认会将commitInfo记录到commit log里
commitInfo = CommitInfo(
clock.getTimeMillis(),
op.name,
op.jsonEncodedValues,
Map.empty,
Some(readVersion).filter(_ >= 0),
None,
Some(isBlindAppend))
finalActions = commitInfo +: finalActions
}
// Register post-commit hooks if any
lazy val hasFileActions = finalActions.collect { case f: FileAction => f }.nonEmpty
if (DeltaConfigs.SYMLINK_FORMAT_MANIFEST_ENABLED.fromMetaData(metadata) && hasFileActions) {
registerPostCommitHook(GenerateSymlinkManifest) //生成manifest支持Presto和Athena
}
val commitVersion = doCommit(snapshot.version + 1, finalActions, 0, isolationLevelToUse) //提交action日志
logInfo(s"Committed delta #$commitVersion to ${deltaLog.logPath}")
postCommit(commitVersion, finalActions) //检测是否合并checkpoint
commitVersion
} catch {
case e: DeltaConcurrentModificationException =>
recordDeltaEvent(deltaLog, "delta.commit.conflict." + e.conflictType)
throw e
case NonFatal(e) =>
recordDeltaEvent(
deltaLog, "delta.commit.failure", data = Map("exception" -> Utils.exceptionString(e)))
throw e
}
runPostCommitHooks(version, actions) //0.5版本新特性,用来支持Presto和Amazon Athena
version
}
冲突检测(并发控制)
- 如果后续commit升级了protocol版本,则不通过;
- 如果后续commit更改了metadata,则不通过;
- 如果后续commit更改了文件:
- 在0.5之前的版本,只要读了delta表的文件,且后续其他commit log有FileAction操作,就不能通过检测(除非是完全不依赖delta表,单纯的灌数据才行,怪不得并发低);
- 0.5版本增加了Serializable,WriteSerializable,SnapshotIsolation三个隔离等级;(以下仅考虑源码的具体实现,根据isolationLevels里的文档注释,它们应该具有更多的功能,尤其是WriteSerializable级别,目前的代码并没有使用,推测应该会在后续版本进行更新,或者在商业版里才有)
- Serializable最严格的,要求绝对的串行化,设置了这个级别,只要出现并发冲突,且后续commit log存在AddFile操作,就会报错;
- WriteSerializable允许其他commit isBlindAppend时通过冲突检测(即后续的commit仅AddFile,不RemoveFile),此种情况下最终结果和串行的结果可能不同;
- SnapshotIsolation最宽松,基本都可以通过这部分的冲突检测,但是可能无法通过其他模块的检测。
- 如果后续commit删除了本次读取的文件,则不通过;
- 如果后续commit和本次commit删除了同一个文件,则不通过;
- 如果幂等的事务发生了冲突(SetTransaction部分有相同的appId),则不通过。
(具体代码在OptimisticTransaction.scala的checkAndRetry方法里,有兴趣的可以看一下)
delete
调用DeltaTable里的delete方法可以删除满足指定条件的数据。
- DeltaTableOperations的executeDelete将任务解析成DeleteCommand,然后run;
- DeleteCommand.run会检查目标delta表是否为appendOnly,若是,则禁止更新和删除数据,否则performDelete;
- 在performDelete方法中,首先解析给定的删除数据的条件,划分为只使用元数据就能计算的谓词和其它谓词两类;(具体实现是检查谓词是否仅包含分区列和条件是否涉及子查询表达式)
- 使用OptimisticTransaction里的filterFiles方法找出需要删除的文件列表,
- 如果只有上述第一种情况,则不需要扫描文件数据,直接删除文件就行,删除调用的是removeWithTimestamp方法,返回RemoveFile action;
- 如果包含上述第二种情况,则需要扫描文件数据,找出文件列表中不需要被删除的数据,使用TransactionalWrite.writeFiles方法写到新的文件中,此时deleteActions包括AddFile和RemoveFile。
- 最后用commit方法提交deleteActions,并使用recordDeltaEvent记录本次删除操作的详细信息。
(文件并没有被物理删除)
private def performDelete(
sparkSession: SparkSession, deltaLog: DeltaLog, txn: OptimisticTransaction) = {
import sparkSession.implicits._
var numTouchedFiles: Long = 0
var numRewrittenFiles: Long = 0
var scanTimeMs: Long = 0
var rewriteTimeMs: Long = 0
val startTime = System.nanoTime()
val numFilesTotal = deltaLog.snapshot.numOfFiles
val deleteActions: Seq[Action] = condition match {
case None => //没有限定条件,需删除整张表,此时遍历所有文件,然后删除就行
// Case 1: Delete the whole table if the condition is true
val allFiles = txn.filterFiles(Nil)
numTouchedFiles = allFiles.size
scanTimeMs = (System.nanoTime() - startTime) / 1000 / 1000
val operationTimestamp = System.currentTimeMillis()
allFiles.map(_.removeWithTimestamp(operationTimestamp)) //逻辑删除数据文件
case Some(cond) => //有条件就需要区分不同情况了
val (metadataPredicates, otherPredicates) =
DeltaTableUtils.splitMetadataAndDataPredicates( //将条件解析成能用元数据定位的和其他
cond, txn.metadata.partitionColumns, sparkSession)
if (otherPredicates.isEmpty) { //第一种情况,只使用元数据就能定位所有数据
// Case 2: The condition can be evaluated using metadata only.
// Delete a set of files without the need of scanning any data files.
val operationTimestamp = System.currentTimeMillis()
val candidateFiles = txn.filterFiles(metadataPredicates) //返回涉及到的文件
scanTimeMs = (System.nanoTime() - startTime) / 1000 / 1000
numTouchedFiles = candidateFiles.size
candidateFiles.map(_.removeWithTimestamp(operationTimestamp)) //删除
} else { //第二种情况,需要把文件中不需要删除的数据重写一份
// Case 3: Delete the rows based on the condition.
val candidateFiles = txn.filterFiles(metadataPredicates ++ otherPredicates)
numTouchedFiles = candidateFiles.size
val nameToAddFileMap = generateCandidateFileMap(deltaLog.dataPath, candidateFiles) //生成重写后的文件名和对应的AddFile action
val fileIndex = new TahoeBatchFileIndex(
sparkSession, "delete", candidateFiles, deltaLog, tahoeFileIndex.path, txn.snapshot)
// Keep everything from the resolved target except a new TahoeFileIndex
// that only involves the affected files instead of all files.
val newTarget = DeltaTableUtils.replaceFileIndex(target, fileIndex) //替换文件索引,更新LogicalPlan
val data = Dataset.ofRows(sparkSession, newTarget)
val filesToRewrite =
withStatusCode("DELTA", s"Finding files to rewrite for DELETE operation") {
if (numTouchedFiles == 0) {
Array.empty[String]
} else {
data.filter(new Column(cond)).select(new Column(InputFileName())).distinct()
.as[String].collect()
}
}
scanTimeMs = (System.nanoTime() - startTime) / 1000 / 1000
if (filesToRewrite.isEmpty) {
// Case 3.1: no row matches and no delete will be triggered
Nil
} else {
// Case 3.2: some files need an update to remove the deleted files
// Do the second pass and just read the affected files
val baseRelation = buildBaseRelation(
sparkSession, txn, "delete", tahoeFileIndex.path, filesToRewrite, nameToAddFileMap)
// Keep everything from the resolved target except a new TahoeFileIndex
// that only involves the affected files instead of all files.
val newTarget = DeltaTableUtils.replaceFileIndex(target, baseRelation.location)
val targetDF = Dataset.ofRows(sparkSession, newTarget)
val filterCond = Not(EqualNullSafe(cond, Literal(true, BooleanType)))
val updatedDF = targetDF.filter(new Column(filterCond))
val rewrittenFiles = withStatusCode(
"DELTA", s"Rewriting ${filesToRewrite.size} files for DELETE operation") {
txn.writeFiles(updatedDF) //写文件
}
numRewrittenFiles = rewrittenFiles.size
rewriteTimeMs = (System.nanoTime() - startTime) / 1000 / 1000 - scanTimeMs
val operationTimestamp = System.currentTimeMillis()
removeFilesFromPaths(deltaLog, nameToAddFileMap, filesToRewrite, operationTimestamp) ++ //删文件
rewrittenFiles //写文件
}
}
}
if (deleteActions.nonEmpty) {
txn.commit(deleteActions, DeltaOperations.Delete(condition.map(_.sql).toSeq)) //提交commit日志
}
recordDeltaEvent( //记录本次操作的详细信息
deltaLog,
"delta.dml.delete.stats",
data = DeleteMetric(
condition = condition.map(_.sql).getOrElse("true"),
numFilesTotal,
numTouchedFiles,
numRewrittenFiles,
scanTimeMs,
rewriteTimeMs)
)
}
update
调用DeltaTable里的update()方法可以更新满足指定条件的数据。(和delete有些相似)
- DeltaTableOperations的executeUpdate将任务解析成UpdateCommand,然后run;
- UpdateCommand.run检查目标delta表是否为appendOnly,若是,则禁止更新和删除数据,否则performUpdate;
- 解析给定条件,划分为只使用元数据就能计算的谓词和其它谓词两类;
- 使用OptimisticTransaction里的filterFiles方法找出需要删除的文件列表,
- 如果只有上述第一种情况,removeWithTimestamp直接删除文件,然后调用rewriteFiles方法,使用buildUpdatedColumns更新受影响的列,最后writeFiles;
- 如果包含上述第二种情况,扫描数据,找出需要更新的数据,(逻辑)删除原文件,更新受影响的数据,然后rewriteFiles。
- 最后用commit方法提交deleteActions,并使用recordDeltaEvent记录本次删除操作的详细信息。
(关键代码详见UpdateCommand.scala的performUpdate方法,和delete相似)
merge
DeltaTable里merge直接调用DeltaMergeBuilder方法,后续的whenMatched和whenNotMatched都是向mergeBuilder里面添加从句,最后使用execute()启动执行;
whenMatched时可以执行update操作。
- update调用addUpdateClause方法,它使用MergeIntoClause.toActions将解析后的列名和update的表达式转化为MergeAction,MergeIntoUpdateClause将它与whenMatched的条件结合,通过withClause()添加到mergeBuilder里;
- updateAll也是同样的流程,只是MergeIntoClause.toActions(Nil, Nil)参数为空(类似于update set * ),后续execute时resolveClause方法会予以解析。
private def addUpdateClause(set: Map[String, Column]): DeltaMergeBuilder = {
if (set.isEmpty && matchCondition.isEmpty) {
// Nothing to update = no need to add an update clause
mergeBuilder
} else {
val setActions = set.toSeq
val updateActions = MergeIntoClause.toActions( //转化为MergeAction
colNames = setActions.map(x => UnresolvedAttribute.quotedString(x._1)),
exprs = setActions.map(x => x._2.expr),
isEmptySeqEqualToStar = false)
val updateClause = MergeIntoUpdateClause(matchCondition.map(_.expr), updateActions) //和条件一起打包
mergeBuilder.withClause(updateClause) //加到mergeBuilder里
}
}
whenMatched时可以执行delete操作,直接用MergeIntoDeleteClause封装一下matchCondition,然后withClause添加进mergeBuilder;
/** Delete a matched row from the table */
def delete(): DeltaMergeBuilder = {
val deleteClause = MergeIntoDeleteClause(matchCondition.map(_.expr))
mergeBuilder.withClause(deleteClause)
}
whenNotMatched时可以执行insert操作,流程类似update,MergeIntoClause.toActions转化,MergeIntoInsertClause封装,然后添加到mergeBuilder里;
private def addInsertClause(setValues: Map[String, Column]): DeltaMergeBuilder = {
val values = setValues.toSeq
val insertActions = MergeIntoClause.toActions(
colNames = values.map(x => UnresolvedAttribute.quotedString(x._1)),
exprs = values.map(x => x._2.expr),
isEmptySeqEqualToStar = false)
val insertClause = MergeIntoInsertClause(notMatchCondition.map(_.expr), insertActions)
mergeBuilder.withClause(insertClause)
}
调用execute来执行。
- 使用MergeInto.resolveReferences解析mergeClause。首先会检查merge的语法规则;
- 一个merge中至少存在一个whenClauses;
- 如果存在两个whenMatched,则第一个必须有条件;
- whenMatched最多有两个;
- update、delete和insert都只能出现一次。
- 具体的解析工作是由resolveClause和resolveOrFail来完成的(resolveOrFail提供了一个递归的调用)。
- 使用PreprocessTableMerge进行预处理,将MergeIntoInsertClause(notMatch)和MergeIntoMatchedClause(match:MergeIntoUpdateClause和MergeIntoDeleteClause都继承自它)封装成MergeIntoCommand;
- 调用MergeIntoCommand.run。
- 如果只有whenNotMatched,则只需要insert数据,调用writeInsertsOnlyWhenNoMatchedClauses方法,此时只需要left anti join 找到需要插入的数据,然后写就行了,相关方法是OptimisticTransaction.filterFiles和TransactionalWrite.writeFiles;
- 如果包含whenMatched,
- 调用findTouchedFiles找到所有需要更改的文件(用withColumn把列编号和文件名加到数据上,然后inner join找到match的数据);
- 然后调用writeAllChanges方法处理需要改变的数据,具体流程是对sourceDF(merge的目标df)和targetDF(上一步找出来的delta文件DF)做full join,然后使用JoinedRowProcessor.processPartition处理相应的逻辑,最后writeFiles写数据,然后remove找出的delta文件。
- 提交commit,然后recordDeltaEvent记录本次的MergeStats。
- 使用MergeInto.resolveReferences解析mergeClause。首先会检查merge的语法规则;
def execute(): Unit = {
val sparkSession = targetTable.toDF.sparkSession
val resolvedMergeInto =
MergeInto.resolveReferences(mergePlan)(tryResolveReferences(sparkSession) _) //解析
if (!resolvedMergeInto.resolved) {
throw DeltaErrors.analysisException("Failed to resolve\n", plan = Some(resolvedMergeInto))
}
// Preprocess the actions and verify
val mergeIntoCommand = PreprocessTableMerge(sparkSession.sessionState.conf)(resolvedMergeInto) //封装
sparkSession.sessionState.analyzer.checkAnalysis(mergeIntoCommand) //检查LogicalPlan
mergeIntoCommand.run(sparkSession) //执行
}
Delta Lake源码分析的更多相关文章
- 最新版ffmpeg源码分析
最新版ffmpeg源码分析一:框架 (ffmpeg v0.9) 框架 最新版的ffmpeg中发现了一个新的东西:avconv,而且ffmpeg.c与avconv.c一个模样,一研究才发现是libav下 ...
- Solr4.8.0源码分析(12)之Lucene的索引文件(5)
Solr4.8.0源码分析(12)之Lucene的索引文件(5) 1. 存储域数据文件(.fdt和.fdx) Solr4.8.0里面使用的fdt和fdx的格式是lucene4.1的.为了提升压缩比,S ...
- Solr4.8.0源码分析(8)之Lucene的索引文件(1)
Solr4.8.0源码分析(8)之Lucene的索引文件(1) 题记:最近有幸看到觉先大神的Lucene的博客,感觉自己之前学习的以及工作的太为肤浅,所以决定先跟随觉先大神的博客学习下Lucene的原 ...
- JDK源码分析-AtomicInteger
AtomicInteger可以看做Integer类的原子操作工具类.在java.util.concurrent.atomic包下,在一些使用场合下可以取代加锁操作提高并发性.接下来就从几个方面来介绍: ...
- ConcurrentHashMap 源码分析
ConcurrentHashMap 源码分析 1. 前言 终于到这个类了,其实在前面很过很多次这个类,因为这个类代码量比较大,并且涉及到并发的问题,还有一点就是这个代码有些真的晦涩,不好懂.前前 ...
- Java高并发之无锁与Atomic源码分析
目录 CAS原理 AtomicInteger Unsafe AtomicReference AtomicStampedReference AtomicIntegerArray AtomicIntege ...
- 《k8s 源码分析》- Custom Controller 之 Informer
Custom Controller 之 Informer 概述 架构概览 reflector - List & Watch API Server Reflector 对象 ListAndWat ...
- ElasticSearch Index操作源码分析
ElasticSearch Index操作源码分析 本文记录ElasticSearch创建索引执行源码流程.从执行流程角度看一下创建索引会涉及到哪些服务(比如AllocationService.Mas ...
- linux调度器源码分析 - 运行(四)
本文为原创,转载请注明:http://www.cnblogs.com/tolimit/ 引言 之前的文章已经将调度器的数据结构.初始化.加入进程都进行了分析,这篇文章将主要说明调度器是如何在程序稳定运 ...
随机推荐
- 2019-8-30-C#-从零开始写-SharpDx-应用-笔刷
title author date CreateTime categories C# 从零开始写 SharpDx 应用 笔刷 lindexi 2019-8-30 8:50:0 +0800 2019-6 ...
- hdu 3466 01背包变形【背包dp】
http://acm.hdu.edu.cn/showproblem.php?pid=3466 有两个物品P,Q,V分别为 3 5 6, 5 10 5,如果先dp第一个再dp第二个,背包容量至少要为3+ ...
- poj1087&&hdu1526 最大流
多源多汇. 比较明显的建图.对于电器,可以从源点与各个电器相连,容量为1,表示这个电器有1个,然后对于各种接头,那可以各个接头与汇点相连,容量为1,表示每个接头只能用一次. 然后对于能够相互转换的接头 ...
- 在Swift中检查API的可用性
http://www.cocoachina.com/swift/20150901/13283.html 本文由CocoaChina译者ALEX吴浩文翻译自Use Your Loaf博客 原文:Chec ...
- 字体图标font-awesome
其实有一些常见的图标使用字体图标比使用img来得好 Font Awesome 官网:http://fortawesome.github.io/Font-Awesome/ 字体代码:http://for ...
- CAD安装失败怎样卸载重新安装CAD,解决CAD安装失败的方法总结
技术帖:CAD没有按照正确方式卸载,导致CAD安装失败.楼主也查过网上关于如何解决CAD安装失败的一些文章,是说删除几个CAD文件和CAD软件注册表就可以解决CAD安装失败的问题,实际的情况并没有这么 ...
- SecureCRT 7.1.1和SecureFx key 亲测可用
CRT:Name: ygeRCompany: TEAM ZWTSerialNumber: 03-77-119256License Key: ABH2MJ 9YVAC5 Z17QF7 4ZAS7Z AB ...
- Redis源码解析:02链表
链表提供了高效的节点重排能力,以及顺序性的节点访问方式,因为Redis使用的C语言并没有内置这种数据结构,所以Redis自己实现了链表. 链表在Redis中的应用非常广泛,比如列表的底层实现之一就是链 ...
- 深入理解iptables防火墙
0x00 Linux 安全性和 netfilter/iptables Linux 因其健壮性.可靠性.灵活性以及好象无限范围的可定制性而在 IT 业界变得非常受欢迎.Linux 具有许多内置的能力, ...
- uniapp点击底部tabbar不跳转页面
一个项目,其设想是这样的,当我进入页面,发现有新版本,提示用户之后,用户点击确定跳转到下载页面. 弹出框要用自己封装的,因为uniapp的弹出框不同的手机上展示的样子不一样,领导的是华为(在这里悄悄吐 ...