Spark On Yarn搭建及各运行模式说明
之前记录Yarn:Hadoop2.0之YARN组件,这次使用Docker搭建Spark On Yarn
一、各运行模式
1、单机模式
该模式被称为Local[N]模式,是用单机的多个线程来模拟Spark分布式计算,通常用来验证开发出来的应用程序逻辑上没有问题。其中N代表可以使用N个线程,每个线程拥有一个core。如果不指定N,则默认是1个线程(该线程拥有1个core)
指令实例:
1)spark-shell --master local
2)spark-shell --master local[4]代表会有4个线程(每个线程一个core)来并发执行应用程序
运行该模式非常简单,只需要把Spark的安装包解压之后,改一些常用的配置即可使用,而不用启动Spark的Master 、Worker守护进程(只有集群的Standalone方式时,才需要这两个角色),也不用启动Hadoop的各服务(除非必须用到hdfs)这是和其他模式的区别。
2、伪集群模式
该模式和local[N]很像,不同的是。它会在单机启动多个进程来模拟集群下的分布式场景,而不像Local[N]这种多线程只能在一个进程下共享资源。通常也是用来验证开发出来的应用程序在逻辑上有没有问题,或想使用Spark的计算框架而没有太多资源。
指令实例:
spark-shell --master local-cluster[2,3,1024]
用法:提交应用程序时使用local-cluster[x,y,z],参数:x代表要生成executor数,y和z分别代表每个executor所拥有的core和memory数,上面这条命令表示:会使用2个executor进程,每个进程分配3个core和1G内存来运行应用程序
该模式非常简单,只需要把spark的安装包解压后,改一些常用的配置即可使用。而不用启动Spark的Master、Worker守护进程(只有集群的standalone方式时,也不用启动hadoop的各服务)。
3、集群模式1---spark自带的Cluster Manager的Standalone client模式
和单机运行模式不同,这里必须在执行应用程序前,先启动Spark的Master和Worker守护进程。不用启动Hadoop服务,除非必须用到。然后在想要作为Master的节点上用start-all.sh来启动即可。这样运行模式,可以使用spark的8080 web ui来观察资源和应用程序的执行情况
指令实例:
1)spark-shell --master spark://spark01:7077
2)spark-shell --master spark://spark01:7077 --deploy-mode client
产生的进程
①Master进程作为clust manager,用来对应用程序申请的资源进行管理。
②SparkSubmit作为client端和运行Driver程序
③CoarseGrainedExecutorBackend用来并发执行程序
4、集群模式2---spark自带的Cluster Manager的standalone cluster模式
指令实例:
spark-submit --master spark://spark01:6066 --deploy-mode cluster
与第三种模式的区别:
①客户端的SparkSubmit进程会在应用程序提交给集群后退出
②Master会在集群中选择一个Worker进程生成一个子进程DriverWrapper来启动Driver来启动程序
③该DriverWrapper进程会占用Worker进程的一个core,所以同样的资源配置下,会比第三种运行模式,少一个core来参与运算
④应用程序的结果,会在执行Driver程序的节点的sdtout中输出,而不是打印在屏幕上。
5、集群模式3---基于Yarn的ResourceManager的Client模式
现在越来越多的场景,都是Spark跑在Hadoop集群中,所以为了做到资源能够均衡调度,会使用Yarn来作为Spark的Cluster的Manager,来为Spark的应用程序分配资源。在执行Spark应用程序之前,要启动Hadoop的各个服务。由于已经有了资源管理器,所以不需要启动Spark的Master、Work守护进程。
指令实例:
①spark-shell --master yarn
②spark-shell --master yarn --deploy-mode client
提交应用程序后,各节点会启动相关JVM进程,如下:
①在ResourceManager节点上提交应用程序,会生成SparkSubmit进程,该进程会执行Driver程序。
②RM会在集群中的某个NodeManager上启动一个ExecutorLauncher进程来作为ApplicationMaster
③RM也会在多个NodeManager上生成一个CoarseGrainedExecutorBackend进程来并发执行应用程序。
6、集群模式4----基于Yarn的ResourceManager的Cluster模式
指令实例:
①spark-shell --master yarn --deploy-mode client
和第5种的区别如下:
①在ResourceManager端提交应用程序,会生成SparkSubmit进程,该进程只用来做Client端,应用程序提交给集群后,就会删除该进程
②ResourceManager在集群中的某个NodeManager中运行ApplicationMaster,该AM同时会执行Driver程序,紧接着,各NodeManager上运行CoarseGrainedExecutorBackend来并发执行应用程序
③应用程序的结果,会在执行Driver应用程序的节点的sdtout输出,而不是打印在屏幕上。
7、Spark On Mesos模式
http://ifeve.com/spark-mesos-spark/
二、Spark On Yarn
官方说明:http://spark.apache.org/docs/latest/running-on-yarn.html、http://spark.apache.org/docs/latest/submitting-applications.html
1、图解说明
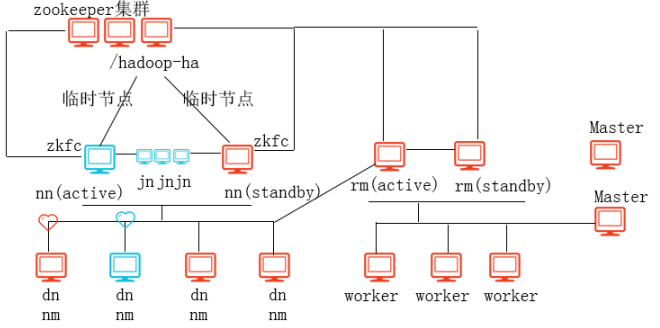
Spark On Yarn模式:Spark集群的资源管理器不是由Master(Cluster Manager)来管理,而是由Yarn的ResourceManager来管理,而Spark的任务调度依然是由SparkContext来调度。
2、环境搭建
本地搭建还是基于之前的环境:使用Docker搭建Spark集群(用于实现网站流量实时分析模块),基于以上6个容器的Zookeeper集群、hadoop集群等环境来搭建。
Spark on YARN运行模式,只需要在Hadoop分布式集群中任选一个节点安装配置Spark即可,不要集群安装。因为Spark应用程序提交到YARN后,YARN会负责集群资源的调度,任选一个hadoop容器来安装spark即可。
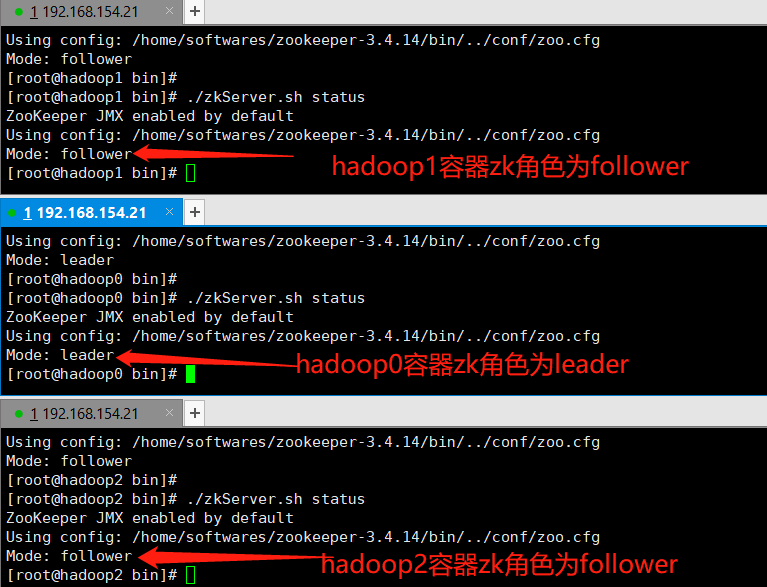
1、启动Zookeeper集群
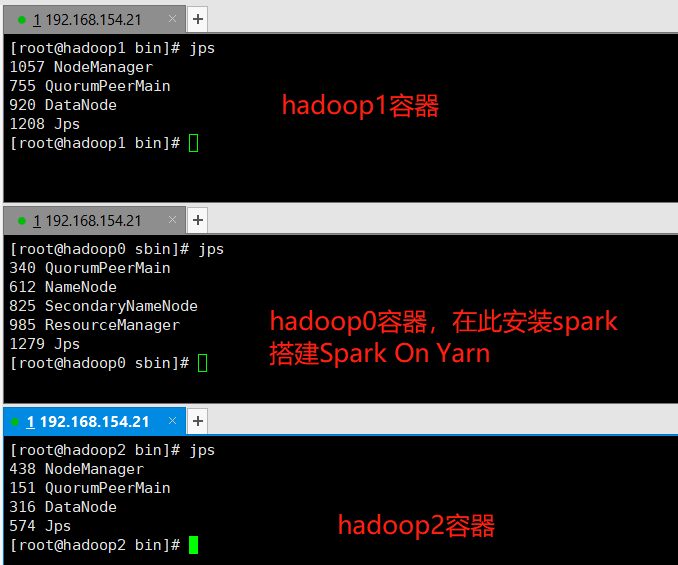
2、启动hadoop集群
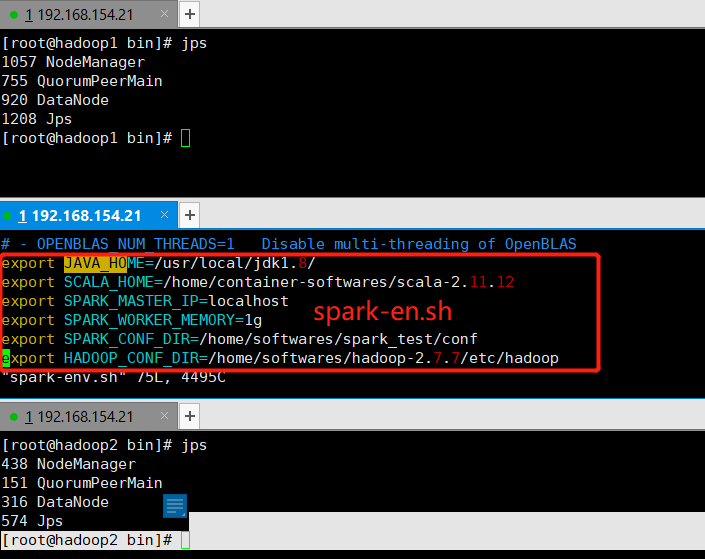
3、hadoop0容器安装配置spark,拷贝编辑spark-env.sh
4、启动测试
spark的bin目录执行命令:./spark-shell --master yarn --deploy-mode client
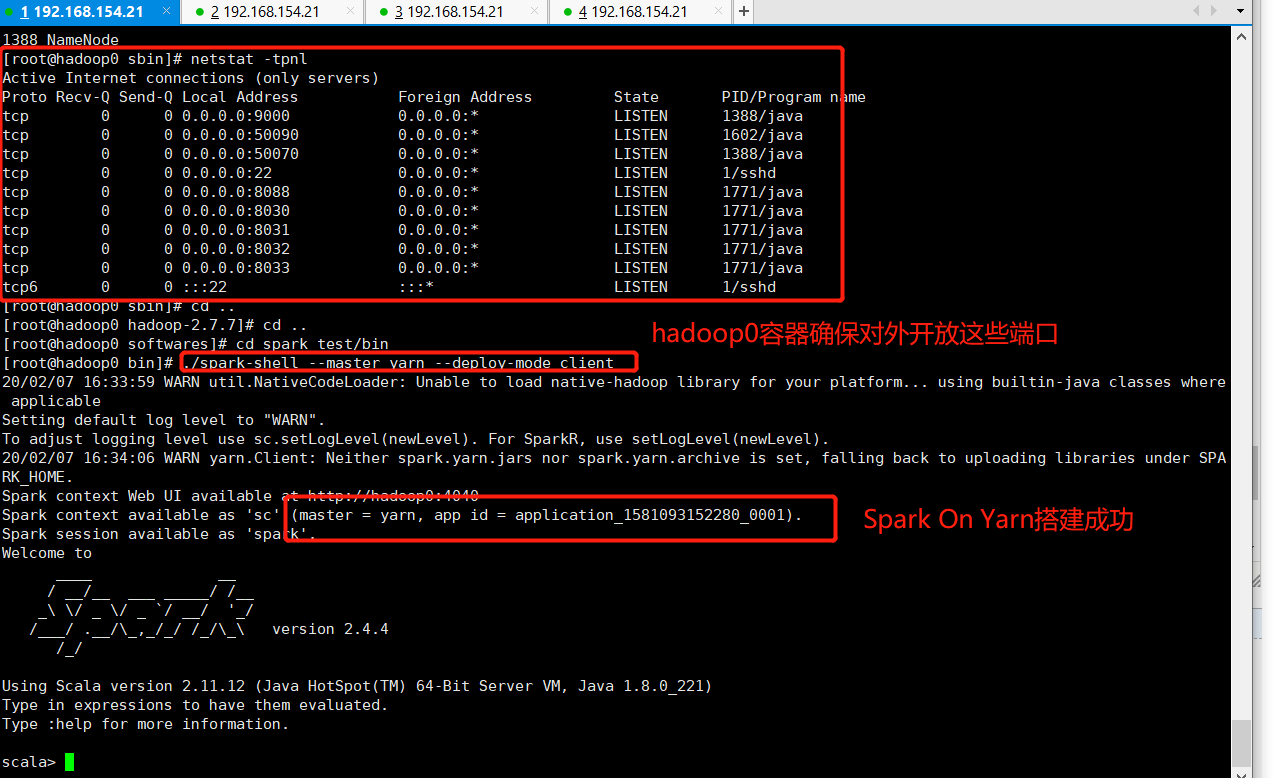
5、Yarn Web界面
可以看到Spark shell应用程序正在运行,单击ID号链接,可以看到该应用程序的详细信息。
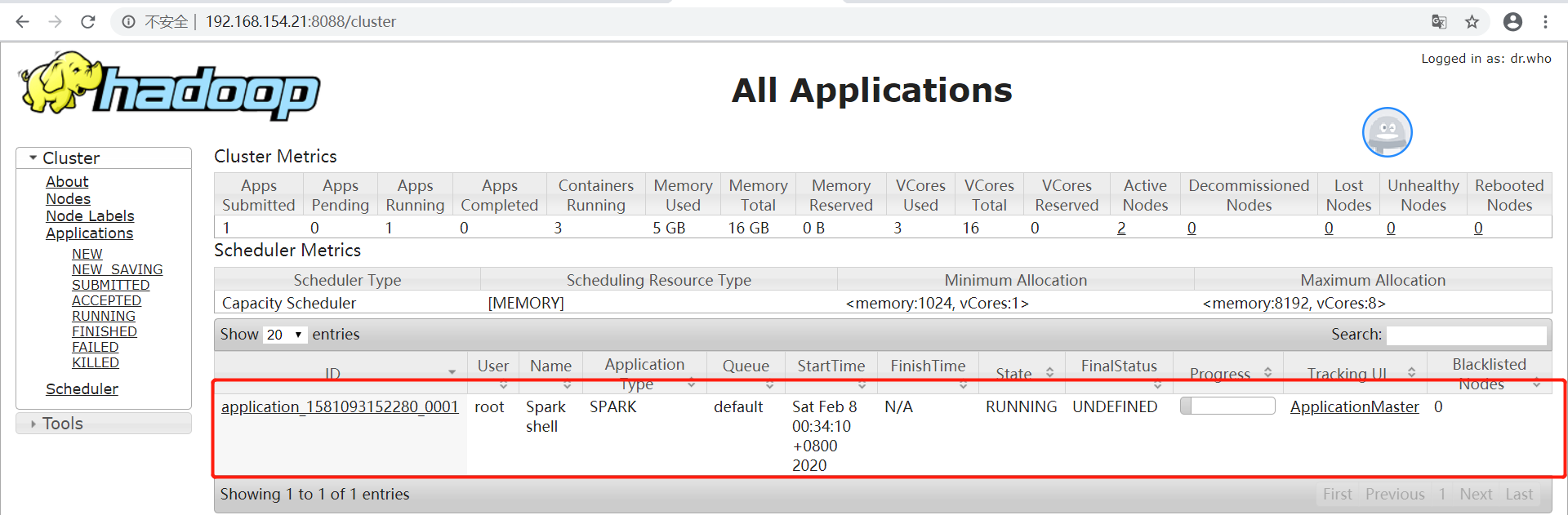
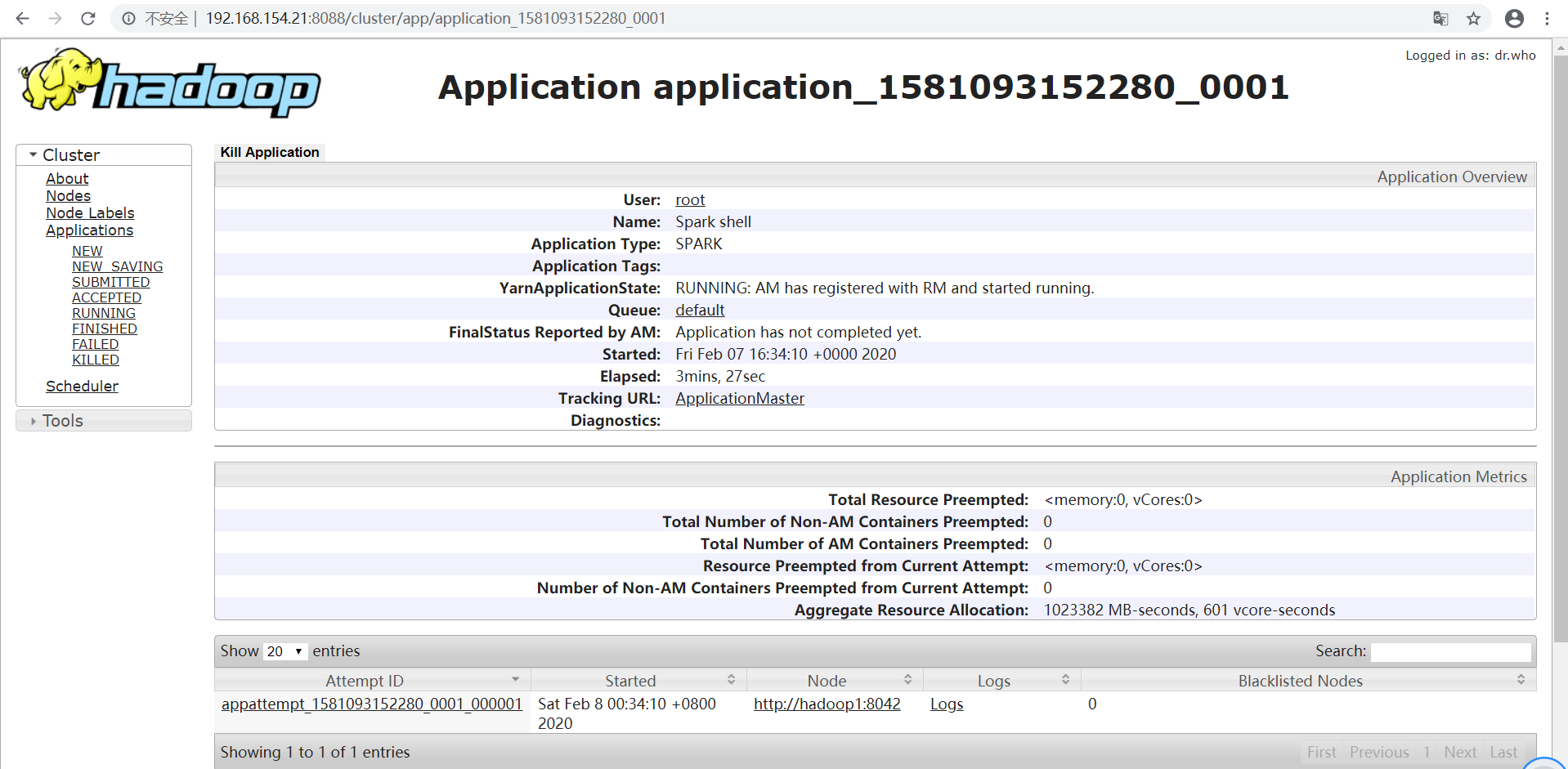
3、问题解决
如果是用虚拟机搭建,可能会由于虚拟机内存过小而导致启动失败,比如内存资源过小,yarn会直接kill掉进程导致rpc连接失败。所以,我们还需要配置Hadoop的yarn-site.xml文件,加入如下两项配置:
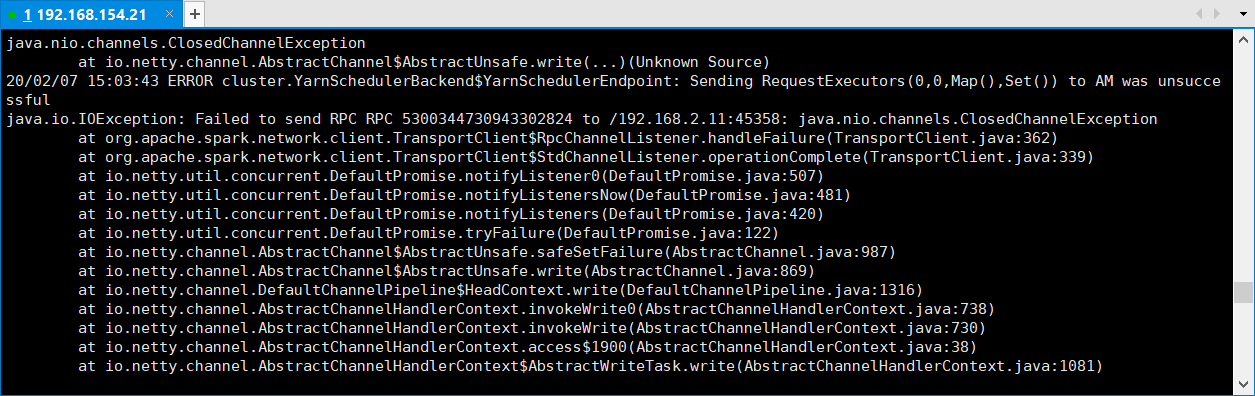
编辑yarn-site.xml添加如下内容即可
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property> <property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
如有问题,欢迎指正交流~~~~
Spark On Yarn搭建及各运行模式说明的更多相关文章
- Spark on YARN的两种运行模式
Spark on YARN有两种运行模式,如下 1.yarn-cluster:适合于生产环境. Spark的Driver运行在ApplicationMaster中,它负责向YARN Re ...
- spark基于yarn的两种提交模式
一.spark的三种提交模式 1.第一种,Spark内核架构,即standalone模式,基于Spark自己的Master-Worker集群. 2.第二种,基于YARN的yarn-cluster模式. ...
- 019 spark on yarn(Job的运行流程,可以对比mapreduce的yarn运行)
1.大纲 spark应用构成:Driver(资源申请.job调度) + Executors(Task具体执行) Yarn上应用运行构成:ApplicationMaster(资源申请.job调度) + ...
- spark之scala程序开发(本地运行模式):单词出现次数统计
准备工作: 将运行Scala-Eclipse的机器节点(CloudDeskTop)内存调整至4G,因为需要在该节点上跑本地(local)Spark程序,本地Spark程序会启动Worker进程耗用大量 ...
- Spark Client和Cluster两种运行模式的工作流程
1.client mode: In client mode, the driver is launched in the same process as the client that submits ...
- Hadoop之搭建完全分布式运行模式
一.过程分析 1.准备3台客户机(关闭防火墙.修改静态ip.主机名称) 2.安装JDK 3.配置环境变量 4.安装Hadoop 5.配置集群 6.单点启动 7.配置ssh免密登录 8.群起并测试集群 ...
- 大话Spark(2)-Spark on Yarn运行模式
Spark On Yarn 有两种运行模式: Yarn - Cluster Yarn - Client 他们的主要区别是: Cluster: Spark的Driver在App Master主进程内运行 ...
- Spark on Yarn 集群运行要点
实验版本:spark-1.6.0-bin-hadoop2.6 本次实验主要是想在已有的Hadoop集群上使用Spark,无需过多配置 1.下载&解压到一台使用spark的机器上即可 2.修改配 ...
- Spark on YARN简介与运行wordcount(master、slave1和slave2)(博主推荐)
前期博客 Spark on YARN模式的安装(spark-1.6.1-bin-hadoop2.6.tgz +hadoop-2.6.0.tar.gz)(master.slave1和slave2)(博主 ...
随机推荐
- mybatis一级缓存和二级缓存(三)
缓存详细介绍,结果集展示 https://blog.csdn.net/u013036274/article/details/55815104 配置信息 http://www.pianshen.co ...
- es报错org.frameworkset.elasticsearch.ElasticSearchException: {"error":{"root_cause":[{"type":"cluster_block_exception","reason":"blocked by: [FORBIDDEN/12/index read-only / allow delete (api)];"}],
今天es在保存数据的时候报错 org.frameworkset.elasticsearch.ElasticSearchException: {"error":{"root ...
- 理解 nodeJS 中的 buffer,stream
在Node.js开发中,当遇到 buffer,stream,和二进制数据处理时,你是否像我一样,总是感到困惑?这种感觉是否会让你认为不了解它们,以为它们不适合你,认为而这些是Node.js作者们的事情 ...
- python 多版本环境
参考 https://www.cnblogs.com/---JoyceLiuHome/articles/7852871.html 安装 Anaconda集成化环境 https://www.anacon ...
- npm 配置国内源
淘宝镜像 npm config set registry http://registry.npm.taobao.org
- 《NVM-Express-1_4-2019.06.10-Ratified》学习笔记(8.21)-- Host Operation with Asymmetric Namespace Access Reporting
8.21 使用ANA报告的主机操作 8.21.1 主机ANA普通操作 主机通过在Identify Controller数据结构中CMIC域的第3位来判断是否支持ANA.NSID或标识(参考第7.10章 ...
- 2019牛客多校第七场E Find the median 离散化+线段树维护区间段
Find the median 题意 刚开始集合为空,有n次操作,每次操作往集合里面插入[L[i],R[i]]的值,问每次操作后中位数是多少 分析 由于n比较大,并且数可以达到1e9,我们无法通过权值 ...
- windows下pycharm输入法跟随设置
参考网址:http://www.itdaan.com/blog/2018/05/20/90e64dae077f8ad7fa70bc9c3c8ab422.html
- Centos7添加软链接
1.pycharm添加软连接: 命令行模式中输入命令: ln -s /root/pycharm-2018.1/bin/pycharm.sh /usr/bin/pycharm ps:代码中/root/p ...
- c#数据筛选和排序
一.TreeView SelectedNode 选中的节点 Level 节点的深度(从0开始) AfterSelect 节点选中后 ...