假期学习【三】HDFS操作及spark的安装/使用
1.安装 Hadoop 和 Spark
进入 Linux 系统,参照本教程官网“实验指南”栏目的“Hadoop 的安装和使用”,完
成 Hadoop 伪分布式模式的安装。完成 Hadoop 的安装以后,再安装 Spark(Local 模式)。
2.HDFS 常用操作
使用 hadoop 用户名登录进入 Linux 系统,启动 Hadoop,参照相关 Hadoop 书籍或网络
资料,或者也可以参考本教程官网的“实验指南”栏目的“HDFS 操作常用 Shell 命令”,
使用 Hadoop 提供的 Shell 命令完成如下操作:
(1) 启动 Hadoop,在 HDFS 中创建用户目录“/user/hadoop”;
(2) 在 Linux 系统的本地文件系统的“/home/hadoop”目录下新建一个文本文件
test.txt,并在该文件中随便输入一些内容,然后上传到 HDFS 的“/user/hadoop”
目录下;
进入/home/hadoop目录,并创建test.txt文件

输入内容
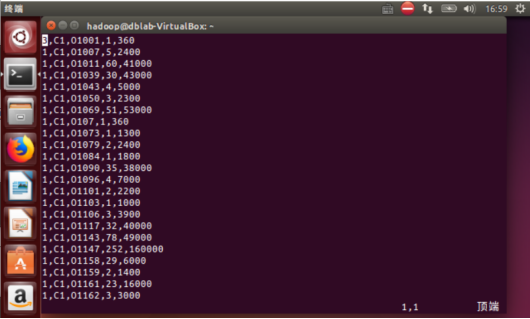
将文件上传到HDFS的/user/hadoop目录下,并查看。

可以发现已经上传成功
(3) 把 HDFS 中“/user/hadoop”目录下的 test.txt 文件,下载到 Linux 系统的本地文
件系统中的“/home/hadoop/下载”目录下;
执行如下命令。

可以查看到已经下载到本地。
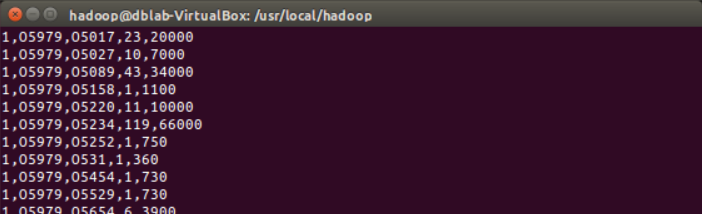
(4) 将HDFS中“/user/hadoop”目录下的test.txt文件的内容输出到终端中进行显示;
执行如下命令

可以显示
(5) 在 HDFS 中的“/user/hadoop”目录下,创建子目录 input,把 HDFS 中
“/user/hadoop”目录下的 test.txt 文件,复制到“/user/hadoop/input”目录下;

(6) 删除HDFS中“/user/hadoop”目录下的test.txt文件,删除HDFS中“/user/hadoop”
目录下的 input 子目录及其子目录下的所有内容。

3. Spark 读取文件系统的数据
Spark安装
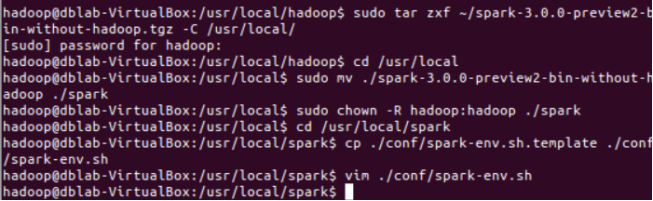
在Spark官网:http://spark.apache.org/downloads.html 下载Spark
并在修改Spark的配置文件spark-env.sh添加输入下列命令:
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
如图:

测试输入图中命令将输出大量信息
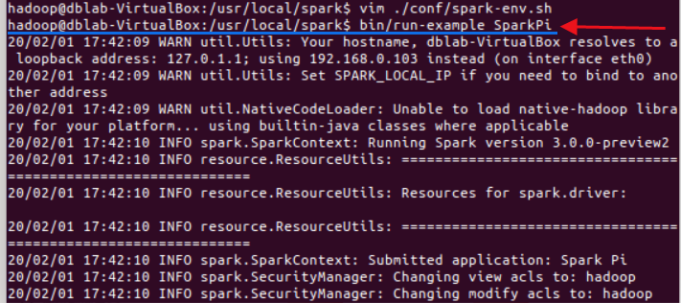

将得到一个π的近似数,说明安装成功
(1)在 spark-shell 中读取 Linux 系统本地文件“/home/hadoop/test.txt”,然后统计出文件的行数;
启动spark-shell
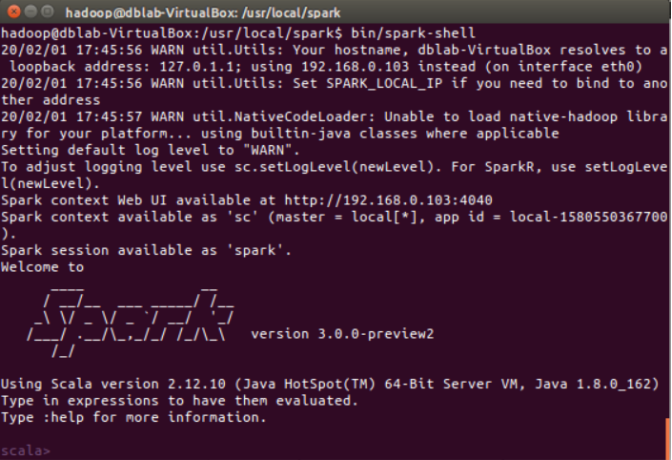
(2)在 spark-shell 中读取 HDFS 系统文件“/user/hadoop/test.txt”(如果该文件不存在,
请先创建),然后,统计出文件的行数;
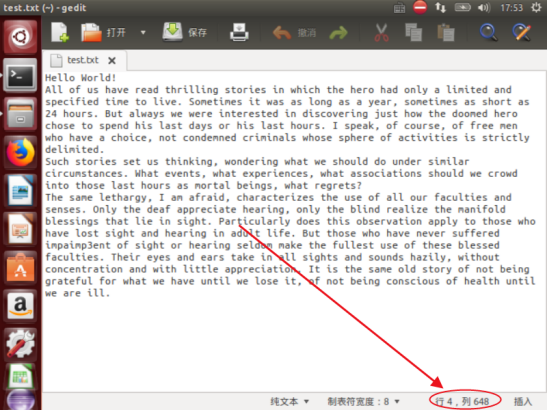
统计结果

未理解的问题:
显示4行正确,但不理解为什么界面行数大于统计的行数。
(3)编写独立应用程序,读取 HDFS 系统文件“/user/hadoop/test.txt”(如果该文件不存在,
请先创建),然后,统计出文件的行数;通过 sbt 工具将整个应用程序编译打包成 JAR 包,
并将生成的 JAR 包通过 spark-submit 提交到 Spark 中运行命令。
1.安装sbt

假期学习【三】HDFS操作及spark的安装/使用的更多相关文章
- git学习——<三>git操作
一.创建仓库 创建一个目录 mkdir repository cd到该目录下,初始化该版本库 git init 至此,版本库创建成功,可以在该文件夹下看到.git文件夹,ls -ah可以看到该文件夹. ...
- Redis基础学习(三)—Key操作
一.key的相关操作 1.删除 del key1 key2 ... Keyn 作用: 删除1个或多个键. 返回值: 不存在的key忽略掉,返回真正删除的key的数量. 2.重命名 rename k ...
- jquery 学习(三) - 遍历操作
HTML代码 <p>1111</p> <p>1111</p> <p>1111</p> <p>1111</p&g ...
- Python基础学习三 文件操作(一)
文件读写 r,只读模式(默认). w,只写模式.[不可读:不存在则创建:存在则删除内容:] a,追加模式.[不可读: 不存在则创建:存在则只追加内容:] r+,[可读.可写:可追加,如果打开的文件不存 ...
- deno学习三 官方提供的方便deno 安装方式
早起deno 使用了golang 开发,同时需要protobuf 进行数据的序列化以及反序列化处理 当前的deno 已经使用rust 进行了开发,同时官方提供的安装方式也很方便了,不需要 那么复杂的编 ...
- hadoop学习(五)----HDFS的java操作
前面我们基本学习了HDFS的原理,hadoop环境的搭建,下面开始正式的实践,语言以java为主.这一节来看一下HDFS的java操作. 1 环境准备 上一篇说了windows下搭建hadoop环境, ...
- 大数据技术之_19_Spark学习_05_Spark GraphX 应用解析 + Spark GraphX 概述、解析 + 计算模式 + Pregel API + 图算法参考代码 + PageRank 实例
第1章 Spark GraphX 概述1.1 什么是 Spark GraphX1.2 弹性分布式属性图1.3 运行图计算程序第2章 Spark GraphX 解析2.1 存储模式2.1.1 图存储模式 ...
- Spark学习笔记1——第一个Spark程序:单词数统计
Spark学习笔记1--第一个Spark程序:单词数统计 笔记摘抄自 [美] Holden Karau 等著的<Spark快速大数据分析> 添加依赖 通过 Maven 添加 Spark-c ...
- Spark-读写HBase,SparkStreaming操作,Spark的HBase相关操作
Spark-读写HBase,SparkStreaming操作,Spark的HBase相关操作 1.sparkstreaming实时写入Hbase(saveAsNewAPIHadoopDataset方法 ...
随机推荐
- JS求1到100的累计值
sum=0 for(i=1;i<=100;i++) { sum+=i } alert(sum) 作者:kerwin-chyl 文章链接:https:////www.cnblogs.com/k ...
- js循环小练习
function fn(){ //打印三角形 for(var i = 1 ; i <= 30 ; i++){ for(var x = 1; x <= i; x++ ){ document. ...
- Sublime Text3添加到右键菜单,"用 SublimeText3 打开"
在Sublime Text3安装目录下新建一个文件 sublime_addright.inf 文件内容: [Version] Signature="$Windows NT$" [D ...
- cesium1.65api版本贴地贴模型标绘工具效果(附源码下载)
前言 cesium 官网的api文档介绍地址cesium官网api,里面详细的介绍 cesium 各个类的介绍,还有就是在线例子:cesium 官网在线例子,这个也是学习 cesium 的好素材. 内 ...
- wordpress 配置坑详解
首先 经过我测试,php74模块没有支持apache的.所以升级到php74 之后,php无法使用. 最基本的函数phpinfo 调用不出来,没有相关的模块. 安装mariadb 10.4 之后发现, ...
- pycharm中新建Vue项目时没有vue.js的解决办法
可能很多小伙伴在使用pycharm 1,新建vue项目的时候并没有发现vue.js的名字, 2,新建.vue文件(即单文件组件)的时候没有 下面就来帮助大家一下,仅供参考 如图: 1.首先我们打开设置 ...
- day19 几个模块的学习
# 模块本质上就是一个 .py 文件# 数据类型# 列表.元组# 字典# 集合.frozenset# 字符串# 堆栈:特点:先进后出# 队列:先进先出 FIFO # from collections ...
- 剑指offer-面试题58_1-翻转单词顺序-字符串
/* 题目: 输入一个英文句子,翻转单词顺序,但单词内部顺序不变. */ /* 思路: 先翻转整个句子,再将每个单词分别翻转一次. */ #include<iostream> #inclu ...
- Anaconda切换工作目录盘符
先回到C盘符的根目录再切换到其他盘符
- [TJOI2014] 匹配
注:此题无序,也无嵬 正文 我们这题求得事实上是一个最大费用最大流,最后的对每条边进行枚举,额然后,如果最大费用小了,就计入答案.. 算是,比较水吧 还有,一开始WA了两次是因为,dis应初始化为负无 ...