Python实现DBSCAN聚类算法(简单样例测试)
发现高密度的核心样品并从中膨胀团簇。
Python代码如下:
- # -*- coding: utf-8 -*-
- """
- Demo of DBSCAN clustering algorithm
- Finds core samples of high density and expands clusters from them.
- """
- print(__doc__)
- # 引入相关包
- import numpy as np
- from sklearn.cluster import DBSCAN
- from sklearn import metrics
- from sklearn.datasets.samples_generator import make_blobs
- from sklearn.preprocessing import StandardScaler
- import matplotlib.pyplot as plt
- # 初始化样本数据
- centers = [[1, 1], [-1, -1], [1, -1]]
- X, labels_true = make_blobs(n_samples=750, centers=centers, cluster_std=0.4,
- random_state=0)
- X = StandardScaler().fit_transform(X)
- # 计算DBSCAN
- db = DBSCAN(eps=0.3, min_samples=10).fit(X)
- core_samples_mask = np.zeros_like(db.labels_, dtype=bool)
- core_samples_mask[db.core_sample_indices_] = True
- labels = db.labels_
- # 聚类的结果
- n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0)
- n_noise_ = list(labels).count(-1)
- print('Estimated number of clusters: %d' % n_clusters_)
- print('Estimated number of noise points: %d' % n_noise_)
- print("Homogeneity: %0.3f" % metrics.homogeneity_score(labels_true, labels))
- print("Completeness: %0.3f" % metrics.completeness_score(labels_true, labels))
- print("V-measure: %0.3f" % metrics.v_measure_score(labels_true, labels))
- print("Adjusted Rand Index: %0.3f"
- % metrics.adjusted_rand_score(labels_true, labels))
- print("Adjusted Mutual Information: %0.3f"
- % metrics.adjusted_mutual_info_score(labels_true, labels,
- average_method='arithmetic'))
- print("Silhouette Coefficient: %0.3f"
- % metrics.silhouette_score(X, labels))
- # 绘出结果
- unique_labels = set(labels)
- colors = [plt.cm.Spectral(each)
- for each in np.linspace(0, 1, len(unique_labels))]
- for k, col in zip(unique_labels, colors):
- if k == -1:
- col = [0, 0, 0, 1]
- class_member_mask = (labels == k)
- xy = X[class_member_mask & core_samples_mask]
- plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor=tuple(col),
- markeredgecolor='k', markersize=14)
- xy = X[class_member_mask & ~core_samples_mask]
- plt.plot(xy[:, 0], xy[:, 1], 'o', markerfacecolor=tuple(col),
- markeredgecolor='k', markersize=6)
- plt.title('Estimated number of clusters: %d' % n_clusters_)
- plt.show()
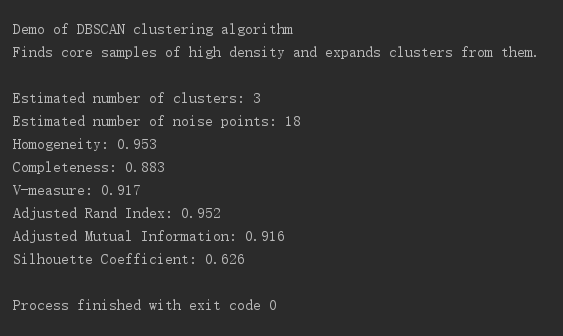
测试结果如下:
最终结果绘图:
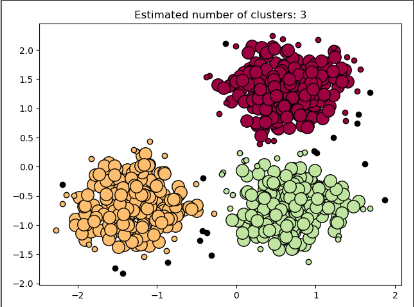
具体数据:
Python实现DBSCAN聚类算法(简单样例测试)的更多相关文章
- extern外部方法使用C#简单样例
外部方法使用C#简单样例 1.添加引用using System.Runtime.InteropServices; 2.声明和实现的连接[DllImport("kernel32", ...
- spring事务详解(二)简单样例
系列目录 spring事务详解(一)初探事务 spring事务详解(二)简单样例 spring事务详解(三)源码详解 spring事务详解(四)测试验证 spring事务详解(五)总结提高 一.引子 ...
- 机器学习入门-DBSCAN聚类算法
DBSCAN 聚类算法又称为密度聚类,是一种不断发张下线而不断扩张的算法,主要的参数是半径r和k值 DBSCAN的几个概念: 核心对象:某个点的密度达到算法设定的阈值则其为核心点,核心点的意思就是一个 ...
- Python实现 K_Means聚类算法
使用 Python实现 K_Means聚类算法: 问题定义 聚类问题是数据挖掘的基本问题,它的本质是将n个数据对象划分为 k个聚类,以便使得所获得的聚类满足以下条件: 同一聚类中的数据对象相似度较高 ...
- velocity简单样例
velocity简单样例整体实现须要三个步骤,详细例如以下: 1.创建一个Javaproject 2.导入须要的jar包 3.创建须要的文件 ============================= ...
- 自己定义隐式转换和显式转换c#简单样例
自己定义隐式转换和显式转换c#简单样例 (出自朱朱家园http://blog.csdn.net/zhgl7688) 样例:对用户user中,usernamefirst name和last name进行 ...
- Kafka在Linux上安装部署及样例测试
Kafka是一个分布式的.可分区的.可复制的消息系统.它提供了普通消息系统的功能,但具有自己独特的设计.这个独特的设计是什么样的呢 介绍 Kafka是一个分布式的.可分区的.可复制的消息系统.它提供了 ...
- gtk+3.0的环境配置及基于gtk+3.0的python简单样例
/********************************************************************* * Author : Samson * Date ...
- 5.无监督学习-DBSCAN聚类算法及应用
DBSCAN方法及应用 1.DBSCAN密度聚类简介 DBSCAN 算法是一种基于密度的聚类算法: 1.聚类的时候不需要预先指定簇的个数 2.最终的簇的个数不确定DBSCAN算法将数据点分为三类: 1 ...
随机推荐
- 容器监控工具WeaveScope
最近一段时间整了一些docker容器,弄了一些基于docker的微服务通信,弄好一套服务系统之后,对于服务的性能,基础数据的监控就显的很重要, 不然就是两眼一抹黑了,要不就是维护成本很高,这些都不符合 ...
- 多线程共享变量和 AsyncLocal
>>返回<C# 并发编程> 1. 简介 2. 异步下的共享变量 3. 解析 AsyncLocal 3.1. IAsyncLocalValueMap 的实现 3.2. 结论 1. ...
- c# 匿名方法(函数) 匿名委托 内置泛型委托 lamada
匿名方法:通过匿名委托 .lamada表达式定义的函数具体操作并复制给委托类型: 匿名委托:委托的一种简单化声明方式通过delegate关键字声明: 内置泛型委托:系统已经内置的委托类型主要是不带返回 ...
- java工作流系统jflow表单引擎字段扩展组件介绍
关键词:工作流快速开发平台 工作流流设计 业务流程管理 asp.net 开源工作流 bpm工作流系统 java工作流主流框架 自定义工作流引擎 表单设计器 流程设计器 装饰类图片 用于 ...
- Lucene之索引库的维护:添加,删除,修改
索引添加 Field域属性分类 添加文档的时候,我们文档当中包含多个域,那么域的类型是我们自定义的,上个案例使用的TextField域,那么这个域他会自动分词,然后存储 我们要根据数据类型和数据的用途 ...
- 在简单的JDBC程序中使用ORM工具
本文来自[优锐课]——抽丝剥茧,细说架构那些事. ORM(对象关系映射)是用于数据库编程的出色工具.只需一点经验和Java注释的强大功能,我们就可以相对轻松地构建复杂的数据库系统并利用生产力.关系数据 ...
- MySql学习-5.查询2
1.聚合: 1.1 5个聚合函数: count(*):括号中写列名,或者 *: max(列):此列的最大值: min(列):此列的最小值: sum(列):此列的和: avg(列):此列的平均值: 1. ...
- 【redisson】分布式锁与数据库事务
场景: 用户消耗积分兑换商品. user_point(用户积分): id point 1 2000 point_item(积分商品): id point num 101 200 10 传统的contr ...
- Zabbix3.4使用详解
zabbix-基础 第1章 关于zabbix 1.1 为什么要使用监控 1.对系统不间断实时监控2.实时反馈系统当前状态3.保证服务可靠性安全性4.保证业务持续稳定运行 1.2 如何进行监控 比如我们 ...
- 利用 serviceStack 搭建web服务器
1,资料地址 参考资料 https://docs.servicestack.net/ https://docs.servicestack.net/create-your-first-webservic ...