ceph 的crush算法 straw
很多年以前,Sage 在写CRUSH的原始算法的时候,写了不同的Bucket类型,可以选择不同的伪随机选择算法,大部分的模型是基于RJ Honicky写的RUSH algorithms 这个算法,这个在网上可以找到资料,这里面有一个新的特性是sage很引以为豪的,straw算法,也就是我们现在常用的一些算法,这个算法有下面的特性:
- items 可以有任意的weight
- 选择一个项目的算法复杂度是O(n)
- 如果一个item的weight调高或者调低,只会在调整了的item直接变动,而没有调整的item是不会变动的
O(n)找到一个数组里面最大的一个数,你要把n个变量都扫描一遍,操作次数为n,那么算法复杂度是O(n)
冒泡法的算法复杂度是O(n²)
这个过程的算法基本动机看起来像画画的颜料吸管,最长的一个将会获胜,每个item 基于weight有自己的随机straw长度
这些看上去都很好,但是第三个属性实际上是不成立的,这个straw 长度是基于bucket中的其他的weights来进行的一个复杂的算法的,虽然iteam的PG的计算方法是很独立的,但是一个iteam的权重变化实际上影响了其他的iteam的比例因子,这意味着一个iteam的变化可能会影响其他的iteam
这个看起来是显而易见的,但是事实上证明,8年都没有人去仔细研究底层的代码或者算法,这个影响就是用户做了一个很小的权重变化,但是看到了一个很大的数据变动过程,sage 在做的时候写过一个很好的测试,来验证了第三个属性是真的,但是当时的测试只用了几个比较少的组合,如果大量测试是会发现这个问题的
sage注意到这个问题也是很多人抱怨在迁移的数据超过了预期的数据,但是这个很难量化和验证,所以被忽视了很久
无论如何,这是个坏消息
好消息是,sage找到了如何解决分布算法来的实现这三个属性,新的算法被称为 'straw2',下面是不同的算法
straw的算法
max_x = -1
max_item = -1
for each item:
x = random value from 0..65535
x *= scaling factor
if x > max_x:
max_x = x
max_item = item
return item
这个就有问题了scaling factor(比例因子) 是其他iteam的权重所有的,这个就意味着改变A的权重,可能会影响到B和C的权重了
新的straw2的算法是这样的
max_x = -1
max_item = -1
for each item:
x = random value from 0..65535
x = ln(x / 65536) / weight
if x > max_x:
max_x = x
max_item = item
return item
可以看到这个是一个weight的简单的函数,这个意味着改变一个item的权重不会影响到其他的项目
sage发现问题的一半,然后 sam根据这个算法解决了问题
计算ln()函数有点讨厌,因为这个是一个浮点功能,CRUSH是定点运算(整数型),当前的实施方法是128KB的查找表,在做一个小的单元测试的时候比straw慢了25%,单这个可能跟一些缓存和输入也有关系
以上是2014年sage在开发者邮件列表里面提出来的,相信到现在为止straw2的算法已经改进了很多,目前默认的还是straw算法,内核在kernel4.1以后才支持的这个属性的
那么我们在0.9x中来看下这个属性,来从实际环境中看下具体有什么区别
实践过程
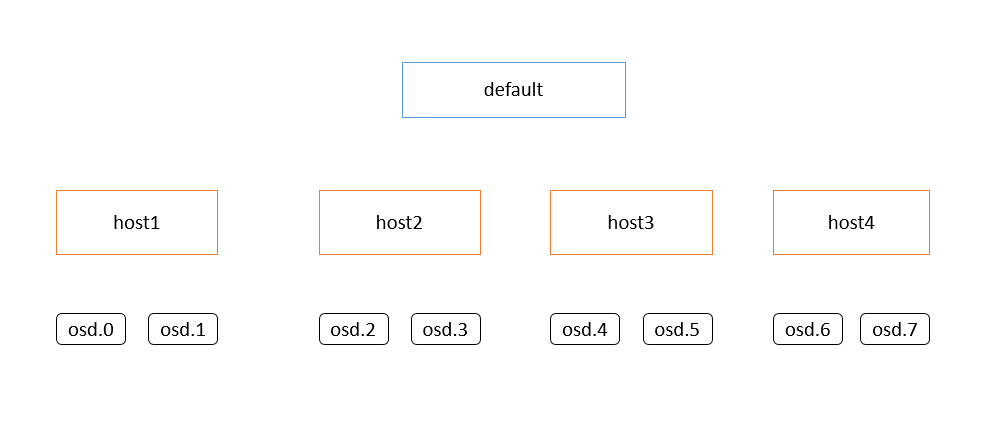
基础的环境为这个,我的机器为8个osd的单机节点,通过修改crush模拟成如上图所示的环境,设置的pg数目为800,保证每个osd上的pg为100左右,这个增加pg的数目,来扩大测试的样本
straw2和straw的区别在于,straw算法改变一个bucket的权重的时候,因为内部算法的问题,造成了其他机器的item的计算因子也会变化,就会出现其他没修改权重的bucket也会出现pg的相互间的流动,这个跟设计之初的想法是不一致的,造成的后果就是,在增加或者减少存储节点的时候,如果集群比较大,数据比较多,就会造成很大的无关数据的迁移,这个就是上面提到的问题
为了解决这个问题就新加入了算法straw2,这个算法保证在bucket的crush权重发生变化的时候,只会在变化的bucket有数据流入或者流出,不会出现其他bucket间的数据流动,减少数据的迁移量,下面的测试将会直观的看到这种变化
环境配置
调整tunables 为 hammer,这个里面才支持crush v4(straw2)属性
root@lab8107:~/ceph/crush# ceph osd crush tunables hammer
adjusted tunables profile to hammer
root@lab8107:~/ceph/crush# ceph osd crush set-tunable straw_calc_version 1
adjusted tunable straw_calc_version to 1
设置完了检查这两个个属性,如果是straw_calc_version 0的时候profile会显示unknow
root@lab8107:~/ceph/crush# ceph osd crush dump|egrep "allowed_bucket_algs|profile"
"allowed_bucket_algs": 54,
"profile": "hammer",
root@lab8107:~/ceph/crush# ceph osd crush dump|grep alg
"alg": "straw",
"alg": "straw",
"alg": "straw",
"alg": "straw",
"alg": "straw",
"alg": "straw",
设置完了后并不能马上生效的,这个是为了防止集群大的变动,可以用这个触发,或者等待下次crush发生变动的时候会自动触发
ceph osd crush reweight-all
先来测试straw
开始第一步测试,将osd.7从集群中crush改为0,那么变动的就是host4的crush,那么我们来看下数据的变化
首先需要记录原始的pg分布
root@lab8107:~ ceph pg dump pgs|awk '{print $1,$15}' > oringin
root@lab8107:~/ceph/crush# ceph osd crush reweight osd.7 0
reweighted item id 7 name 'osd.7' to 0 in crush map
root@lab8107:~ceph pg dump pgs|awk '{print $1,$15}' > rewei70
现在比较oringin 和rewei70 的变化
diff oringin rewei70 -y -W 30 --suppress-common-lines
查看非调整节点的数据流动
0.3d [2] | 0.3d [5]
0.316 [2] | 0.316 [5]
0.26c [5] | 0.26c [1]
0.241 [2] | 0.241 [0]
0.235 [5] | 0.235 [2]
0.128 [0] | 0.128 [3]
再来一次将osd.6的crush weight弄成0
ceph osd crush reweight osd.6 0
再次查看变化
0.cb [4] | 0.cb [2]
0.30b [4] | 0.30b [2]
0.2e9 [1] | 0.2e9 [4]
0.2d8 [3] | 0.2d8 [1]
0.28e [3] | 0.28e [4]
0.286 [1] | 0.286 [4]
0.1f7 [3] | 0.1f7 [1]
0.1b6 [1] | 0.1b6 [4]
0.163 [0] | 0.163 [3]
0.14f [2] | 0.14f [4]
0.10a [0] | 0.10a [3]
上面的两组就是在一个bucket的里面的出现单点和整个bucket的crush weight减少的时候触发的其他节点的数据变动
现在把环境恢复后再来测试straw2
修改crush map 里面的bucket的alg
root@lab8107:~/ceph/crush# ceph osd getcrushmap -o crushmap.txt
got crush map from osdmap epoch 390
root@lab8107:~/ceph/crush# crushtool -d crushmap.txt -o crushmap-decompile
root@lab8107:~/ceph/crush# vim crushmap-decompile
将文件里面的所有straw修改成straw2
root@lab8107:~/ceph/crush# crushtool -c crushmap-decompile -o crushmap-compile
root@lab8107:~/ceph/crush# ceph osd setcrushmap -i crushmap-compile
如果出现报错就把crushmap里面的straw2_calc_version改成straw_calc_version
并且设置算法(最关键的一步,否则即使设置straw2也不生效)(这里之前版本有version 2 现在已经没那个字段了)
ceph osd crush set-tunable straw_calc_version 1
查询当前的crush算法
root@lab8107:~/ceph/crush# ceph osd crush dump|grep alg
"alg": "straw2",
"alg": "straw2",
"alg": "straw2",
"alg": "straw2",
"alg": "straw2",
"alg": "straw2",
"allowed_bucket_algs": 54,
做一次重新内部算法
ceph osd crush reweight-all
可以重复上面的测试了
获取当前的pg分布
[root@lab8106 pgf]# ceph pg dump pgs|awk '{print $1,$15}' > oringin
root@lab8107:~/ceph/crush# ceph osd crush reweight osd.7 0
[root@lab8106 pgf]# ceph pg dump pgs|awk '{print $1,$15}' > rewei70
比较调整前后
diff oringin rewei70 -y -W 30 --suppress-common-lines|less
再次调整osd.6
ceph osd crush reweight osd.6 0
ceph pg dump pgs|awk '{print $1,$15}' > rewei60
已经没有非调整bucket的pg在节点间的变化了
简短的做个总结就是
straw算法里面添加节点或者减少节点,其他服务器上的osd之间会有pg的流动
straw2算法里面添加节点或者减少节点,只会pg从变化的节点移出或者从其他点移入,其他节点间没有数据流动
设置方法
ceph osd crush tunables hammer
ceph osd crush set-tunable straw_calc_version 1
开始设置好了 新创建的默认就是会straw2就会省去修改crushmap的操作
注意librados是服务端支持,客户端就支持,涉及到内核客户端的,就需要内核版本的支持,内核从4.1开始支持,也就是cephfs和rbd的块设备方式需要内核4.1及以上支持,openstack对接的是librados可以默认支持,其他的也都默认可以支持的
相关链接
ceph 的crush算法 straw的更多相关文章
- Ceph剖析:数据分布之CRUSH算法与一致性Hash
作者:吴香伟 发表于 2014/09/05 版权声明:可以任意转载,转载时务必以超链接形式标明文章原始出处和作者信息以及版权声明 数据分布是分布式存储系统的一个重要部分,数据分布算法至少要考虑以下三个 ...
- Ceph之数据分布:CRUSH算法与一致性Hash
转自于:http://www.cnblogs.com/shanno/p/3958298.html?utm_source=tuicool 数据分布是分布式存储系统的一个重要部分,数据分布算法至少要考虑以 ...
- Ceph源码解析:CRUSH算法
1.简介 随着大规模分布式存储系统(PB级的数据和成百上千台存储设备)的出现.这些系统必须平衡的分布数据和负载(提高资源利用率),最大化系统的性能,并要处理系统的扩展和硬件失效.ceph设计了CRUS ...
- ceph之crush map
编辑crush map: 1.获取crush map: 2.反编译crush map: 3.至少编辑一个设备,桶, 规则: 4.重新编译crush map: 5.重新注入crush map: 获取cr ...
- Ceph 调整crush map
目录 Ceph 调整crush map 1.前言 2.示例 1.创建新的replicated 2.修改当前pool的rule Ceph 调整crush map 1.前言 本文章适用于ceph n版 2 ...
- 一致性hash与CRUSH算法总结
相同之处:都解决了数据缓存系统中数据如何存储与路由. 不同之处:区别在于虚拟节点和物理节点的映射办法不同 由于一般的哈希函数返回一个int(32bit)型的hashCode.因此,可以将该哈希函数能够 ...
- Ceph根据Crush位置读取数据
前言 在ceph研发群里面看到一个cepher在问关于怎么读取ceph的副本的问题,这个功能应该在2012年的时候,我们公司的研发就修改了代码去实现这个功能,只是当时的硬件条件所限,以及本身的稳定性问 ...
- Crush 算法以及PG和PGP调整经验
PG和PGP调整经验调整前准备为了降低对业务的影响,需要调整以下参数ceph tell osd.* injectargs ‘–osd-max-backfills 1’ceph tell osd.* i ...
- Ceph相关
Ceph基础知识和基础架构简介 http://www.xuxiaopang.com/2020/10/09/list/#more大话Ceph http://www.xuxiaopang.com/2016 ...
随机推荐
- std::hash
std::hash 由于C++11引入了哈希表数据结构std::unordered_map和std::unordered_set,所以对于基本类型也实现了标准的哈希函数std::hash,标准并没有规 ...
- centos8平台:举例讲解redis6的ACL功能(redis6.0.1)
一,为什么redis6要增加acl功能模块? 什么是acl? 访问控制列表(ACL)是一种基于包过滤的访问控制技术, 它可以根据设定的条件对接口上的数据包进行过滤,允许其通过或丢弃 redis6增加了 ...
- docker-docker-compose 安装
1.安装docker-compose(官网:https://github.com/docker/compose/releases) 安装: curl -L https://github.com/doc ...
- 第七章 HTTP协议原理
一.HTTP协议概述 1.什么是HTTP? HTTP 全称:Hyper Text Transfer Protocol 中文名:超文本传输协议 http就是将用户的请求发送到服务器,将服务器请求到的内容 ...
- Linux入门到放弃之三《常用命令(帮助命令,文件压缩和解压,关机、重启,加载光盘...)》
1.获得命令帮助: man命令的用法: 命令:man find ( 获取find命令的帮助文档 ) 2.复制/root/install.log 到/tmp: ( 确认root目录下是否存在instal ...
- buuctf-misc [BJDCTF2020]认真你就输了
下载压缩包,打开发现有一个10.xls打开一乱码,发现不了头绪,但是发现了pk开头 那我们能不能将这个.xls改成.zip 说干就干,于是我们改成zip解压 打开xl,然后再打开 在chars中发现f ...
- Vue基础(1)
Vue简介 1.JavaScript框架 2.简化Dom操作 3.响应式数据驱动 Vue基础 通过下面代码引用vue: <script src="https://cdn.jsdeliv ...
- 02 HTML 常见标记 选择器 样式
no.02今天主要学习了在web中的HTML CSS,并在其中制作了明信片,在制作明信片途中有几个知识点需要总结:1.HTML 全称hyper text markup language 超文本标记语言 ...
- Redis学习五(Redis 阻塞的原因及其排查方向).
一.慢查询 因为 Redis 是单线程的,大量的慢查询可能会导致 redis-server 阻塞,可以通过 slowlog get n 获取慢日志,查看详情情况. 二.bigkey 大对象 bigke ...
- Android网络性能监控方案
阿里云 云原生应用研发平台EMAS 刘宝文(木睿) 背景 移动互联网时代,移动端极大部分业务都需要通过App和Server之间的数据交互来实现,所以大部分App提供的业务功能都需要使用网络请求.如果因 ...