Python爬虫学习三------requests+BeautifulSoup爬取简单网页
第一次第一次用MarkDown来写博客,先试试效果吧!
昨天2018俄罗斯世界杯拉开了大幕,作为一个伪球迷,当然也得为世界杯做出一点贡献啦。
于是今天就编写了一个爬虫程序将腾讯新闻下世界杯专题的相关新闻和链接提取出来,同时也再复习一下
Python爬虫类库的使用。
爬取前相关库文件的安装
1.python安装,如果还没有安装可以去Python官网去下载安装相应的版本,这里我使用的是Python3.6.1。
2.requests库安装,使用cmd命令打开命令行,接着
pip install requests,等待一些时间后安装就完成啦。同时这里不在介绍requests库的详细使用,如果想查看更多的使用,可以前往http://docs.python-requests.org/zh_CN/latest/user/quickstart.html进行学习。
3.bs4安装,这次使用到的解析工具是BeautifulSoup,所以在写代码前需要安装好,还是在命令行输入
pip install bs4进行安装。BeautifulSoup的学习可以前往https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html。
网页分析
1.首先观察页面,找到我们想要提取的数据在哪。

2.接着打开F12开发者工具,点击下图所示的箭头再点击网页上的内容,查看它出现在真正网页的位置。
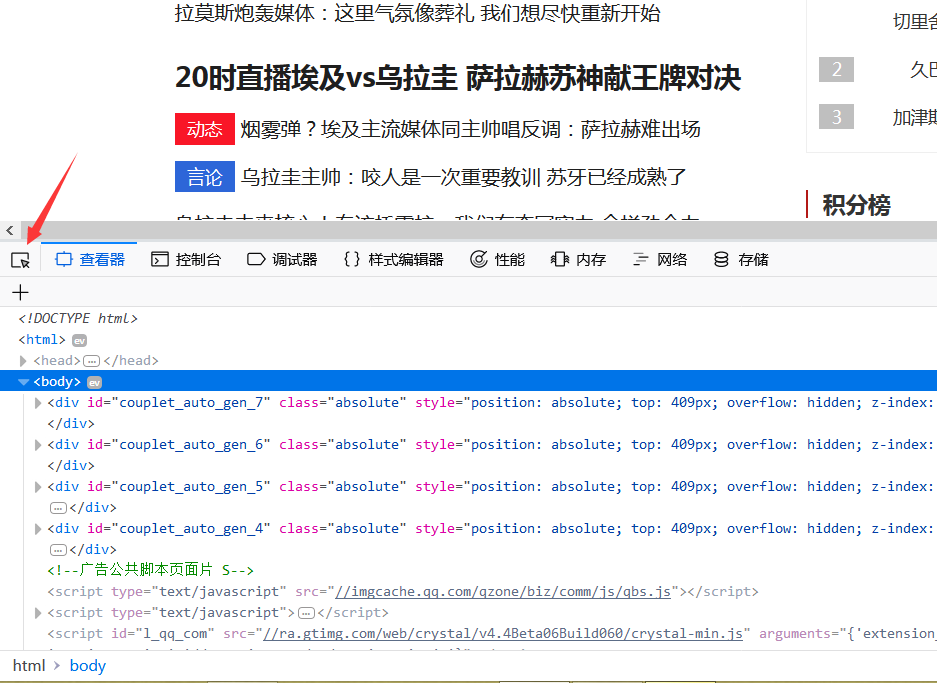

3.复制这则新闻的链接,查看网页源代码并Ctrl+F搜索该链接是否在网页源码中。
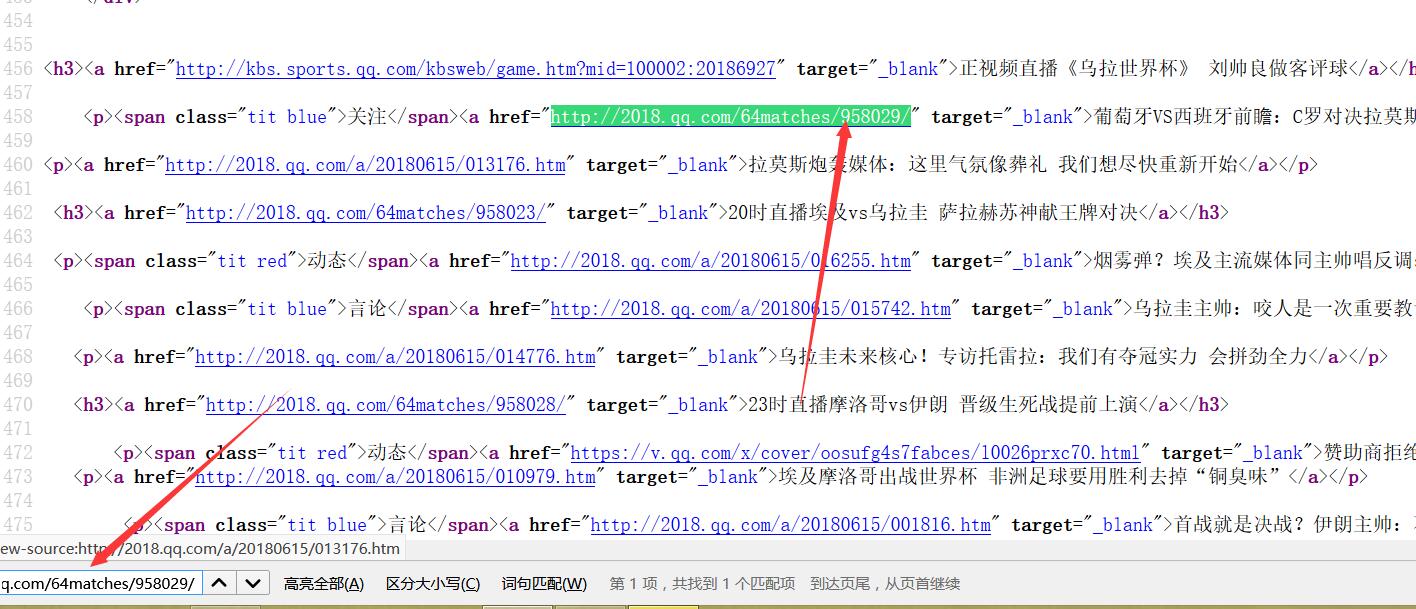
4.可以看到这个网页的新闻信息并没有通过其它方式来加载,而是处在网页的源代码中,这就为我们的提取省了不少时间。
5.返回到页面,查看网页代码结构可以发现所有的新闻都处于一个class为yaowen的div下的p标签内,我们只要能够提取出这些p标签,再从中得到a标签就可以得到我们想要的这个页面的新闻标题以及链接。
代码的编写
import requests
from bs4 import BeautifulSoup
import json
# 构造headers
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 6.3; WOW64; rv:60.0) Gecko/20100101 Firefox/60.0",
}
def get_html(url):
# 使用requests构造get请求
response = requests.get(url=url, headers=headers)
# 根据返回的状态来判断是否请求成功
if response.status_code == 200:
# 通过text属性来获取网页的源代码
html = response.text
print(html)
else:
print(response.status_code)
def main():
url = "http://2018.qq.com/"
html = get_html(url)
if __name__ == '__main__':
main()
这里首先用一个get_html()函数来得到网页的源代码,执行后结果如下:

接下来使用parse_html()来对得到的源代码进行解析
def parse_html(html):
# 使用字典来保存
infos = {}
# 创建BeautifulSoup对象
soup = BeautifulSoup(html, 'lxml')
# 使用css选择器来选择出所有的a标签,返回一个列表
news = soup.select("div.yaowen a[href^='http://2018.qq.com/a/']")
# 遍历列表存入信息到字典
for new in news:
infos[new.get_text()] = new.get("href")
return infos
执行结果如下,可以看到我们想要的该页面新闻标题以及新闻链接都提取下来了。

最后将得到的数据存入到文件中
def save_to_file(news):
# 将字典转化为字符串格式再存入文件中
news = json.dumps(news, ensure_ascii=False)
with open("news.txt", "w", encoding="utf-8") as f:
f.write(news)
print("保存至文件成功")
打开news.txt文件,查看内容

至此,我们想要的信息已经抓取下来了,虽然数据不是很多,就当做是对基本爬虫操作的复习吧!
Python爬虫学习三------requests+BeautifulSoup爬取简单网页的更多相关文章
- Python爬虫学习之使用beautifulsoup爬取招聘网站信息
菜鸟一只,也是在尝试并学习和摸索爬虫相关知识. 1.首先分析要爬取页面结构.可以看到一列搜索的结果,现在需要得到每一个链接,然后才能爬取对应页面. 关键代码思路如下: html = getHtml(& ...
- python 爬虫(一) requests+BeautifulSoup 爬取简单网页代码示例
以前搞偷偷摸摸的事,不对,是搞爬虫都是用urllib,不过真的是很麻烦,下面就使用requests + BeautifulSoup 爬爬简单的网页. 详细介绍都在代码中注释了,大家可以参阅. # -* ...
- Python爬虫学习(6): 爬取MM图片
为了有趣我们今天就主要去爬取以下MM的图片,并将其按名保存在本地.要爬取的网站为: 大秀台模特网 1. 分析网站 进入官网后我们发现有很多分类: 而我们要爬取的模特中的女模内容,点进入之后其网址为:h ...
- Python爬虫实战之Requests+正则表达式爬取猫眼电影Top100
import requests from requests.exceptions import RequestException import re import json # from multip ...
- 爬虫学习(二)--爬取360应用市场app信息
欢迎加入python学习交流群 667279387 爬虫学习 爬虫学习(一)-爬取电影天堂下载链接 爬虫学习(二)–爬取360应用市场app信息 代码环境:windows10, python 3.5 ...
- Python网络爬虫第三弹《爬取get请求的页面数据》
一.urllib库 urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在Python3中的为urllib.request和urllib. ...
- python爬虫实践(二)——爬取张艺谋导演的电影《影》的豆瓣影评并进行简单分析
学了爬虫之后,都只是爬取一些简单的小页面,觉得没意思,所以我现在准备爬取一下豆瓣上张艺谋导演的“影”的短评,存入数据库,并进行简单的分析和数据可视化,因为用到的只是比较多,所以写一篇博客当做笔记. 第 ...
- python爬虫学习(三):使用re库爬取"淘宝商品",并把结果写进txt文件
第二个例子是使用requests库+re库爬取淘宝搜索商品页面的商品信息 (1)分析网页源码 打开淘宝,输入关键字“python”,然后搜索,显示如下搜索结果 从url连接中可以得到搜索商品的关键字是 ...
- python爬虫学习之使用BeautifulSoup库爬取开奖网站信息-模块化
实例需求:运用python语言爬取http://kaijiang.zhcw.com/zhcw/html/ssq/list_1.html这个开奖网站所有的信息,并且保存为txt文件和excel文件. 实 ...
随机推荐
- C#枚举(一)使用总结以及扩展类分享
0.介绍 枚举是一组命名常量,其基础类型为任意整型. 如果没有显式声明基础类型, 则为Int32 在实际开发过程中,枚举的使用可以让代码更加清晰且优雅. 最近在对枚举的使用进行了一些总结与整理,也发现 ...
- k8s二进制部署 - dashboard安装
配置资源清单rbac.yaml apiVersion: v1 kind: ServiceAccount metadata: labels: k8s-app: kubernetes-dashboard ...
- Cron表达式在 定时执行专家 5.0 中的使用方式
在<定时执行专家 V5.0>程序内部使用了包含 6 位的 Cron表达式,第一个字段(second)没有使用.程序内部一直 second 位是 0.在 Cron表达式的界面上可以设置 5位 ...
- leetcode 39 dfs leetcode 40 dfs
leetcode 39 先排序,然后dfs 注意先整全局变量可以减少空间利用 class Solution { vector<vector<int>>ret; vector&l ...
- C# 类 (7) - 抽象 Abstract
Abstract 抽象类,关键字Abstract ,最典型的应用就是在 继承机制里 作为base类,抽象类是不能被实例化的(前面说的static 类也不能被实例化)它必须作为 基类,被别人继承,然后必 ...
- js jsonParse
mdn const rx_one = /^[\],:{}\s]*$/; const rx_two = /\\(?:["\\\/bfnrt]|u[0-9a-fA-F]{4})/g; // 匹配 ...
- Flutter 真机调试
先把手机开启开发者模式,并打开USB调试功能(每种机型开启方法可能不一样) flutter devices 查看是否连接 flutter run
- RT-Thread学习笔记3-线程间通信 & 定时器
目录 1. 事件集的使用 1.1 事件集控制块 1.2 事件集操作 2. 邮箱的使用 2.1 邮箱控制块 2.2 邮箱的操作 3. 消息队列 3.1 消息队列控制块 3.2 消息队列的操作 4. 软件 ...
- 稳定币USDN的算法调控
在NGK公链的稳定币系统中,USDN的价格有时会出现一定幅度的波动.正如我们会看到USDT有时会是0.99美元,有时是1.01美元一样.那么,要保障USDN在二级市场的价格基本稳定,要如何调节供需呢? ...
- java数据类型(进阶篇)
public class note03 { public static void main(String[] args) { //数据类型拓展 //1.整数拓展 //进制: 二进制0b 十进制 八进制 ...