Django学习路32_创建管理员及内容补充+前面内容复习
创建管理员 python manage.py createsuperuser
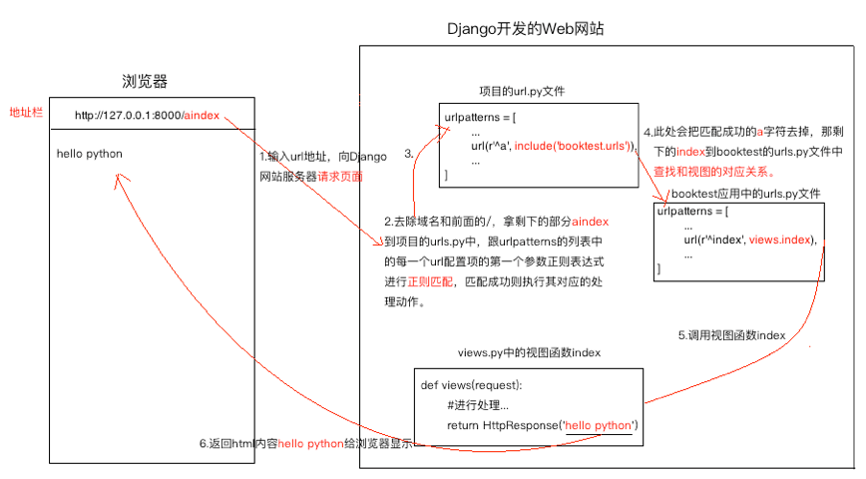
数据库属性命名限制 1.不能是python的保留关键字
2.不允许使用连续的下划线,这是由django的查询方式决定的
3.定义属性时需要指定字段类型,通过字段类型的参数指定选项
语法如下:
属性名=models.字段类型(选项)
字段类型
使用时需要引入django.db.models包,字段类型如下:
AutoField:自动增长的IntegerField,通常不用指定,不指定时Django会自动创建属性名为id的自动增长属性 BooleanField:布尔字段,值为True或False NullBooleanField:支持Null、True、False三种值 CharField(max_length=字符长度):字符串
参数max_length表示最大字符个数 TextField:大文本字段,一般超过4000个字符时使用 IntegerField:整数 DecimalField(max_digits=None, decimal_places=None):十进制浮点数 参数max_digits表示总位数 参数decimal_places表示小数位数 FloatField:浮点数 DateField:[auto_now=False, auto_now_add=False]):日期
参数auto_now表示每次保存对象时,自动设置该字段为当前时间,用于"最后一次修改"的时间戳,它总是使用当前日期,默认为false。
参数auto_now_add表示当对象第一次被创建时自动设置当前时间,用于创建的时间戳,它总是使用当前日期,默认为false 参数auto_now_add和auto_now是相互排斥的,组合将会发生错误 TimeField:时间,参数同DateField DateTimeField:日期时间,参数同DateField FileField:上传文件字段 ImageField:继承于FileField,对上传的内容进行校验,确保是有效的图片
选项: null:如果为True,表示允许为空,默认值是False blank:如果为True,则该字段允许为空白,默认值是False 对比:null是数据库范畴的概念,blank是表单验证证范畴的 db_column:字段的名称,如果未指定,则使用属性的名称 db_index:若值为True, 则在表中会为此字段创建索引,默认值是False default:默认值 primary_key:若为True,则该字段会成为模型的主键字段,默认值是False,一般作为AutoField的选项使用 unique:如果为True, 这个字段在表中必须有唯一值,默认值是False。
get() 获取数据的坑
注:之前写过 get():返回表中满足条件的一条且只能有一条数据 如果查到多条数据,则抛异常:MultipleObjectsReturned 查询不到数据,则抛异常:DoesNotExist
判断条件中的 属性列__参数 的补充 1.判等 exact 例:查询编号为1的图书
BookInfo.objects.get(id=1)
BookInfo.objects.get(id__exact=1) 2.模糊查询 contains 例:查询书名包含'传'的图书。contains BookInfo.objects.filter(btitle__contains='传')
例:查询书名以'部'结尾的图书 endswith 开头:startswith
BookInfo.objects.filter(btitle__endswith='部') 3.空查询 isnull select * from booktest_bookinfo where title is not null; 例:查询书名不为空的图书。isnull
BookInfo.objects.filter(btitle__isnull=False) 4.范围查询 in select * from booktest_bookinfo where id in (1,3,5)
例:查询编号为1或3或5的图书。
BookInfo.objects.filter(id__in = [1,3,5]) 5.比较查询
gt 大于
lt 小于
gte 大于等于
lte 小于等于 例:查询编号大于3的图书。
BookInfo.objects.filter(id__gt = 3) 6.日期查询 year 例:查询1980年发表的图书。
BookInfo.objects.filter(bpub_date__year=1980) 例:查询1980年1月1日后发表的图书。
from datetime import date
BookInfo.objects.filter(bpub_date__gt = date(1980,1,1)) 7.返回不满足条件的数据 exclude 例:查询id不为3的图书信息。
BookInfo.objects.exclude(id=3)
F对象
作用:用于类属性之间的比较条件 使用之前需要先导入:
from django.db.models import F 例:查询图书阅读量大于评论量图书信息。
BookInfo.objects.filter(bread__gt = F('bcomment')) 例:查询图书阅读量大于2倍评论量图书信息。
BookInfo.objects.filter(bread__gt = F('bcomment')*2) Q对象
作用:用于查询时的逻辑条件
not and or,可以对Q对象进行&|~操作 使用之前需要先导入:
from django.db.models import Q 例:查询id大于3且阅读量大于30的图书的信息。
BookInfo.objects.filter(id__gt=3, bread__gt=30) BookInfo.objects.filter(Q(id__gt=3)&Q(bread__gt=30)) 例:查询id大于3或者阅读量大于30的图书的信息。
BookInfo.objects.filter(Q(id__gt=3)|Q(bread__gt=30)) 例:查询id不等于3图书的信息。
BookInfo.objects.filter(~Q(id=3))
order_by
QuerySet对象.order_by('属性') 作用:进行查询结果进行排序 例:查询所有图书的信息,按照id从小到大进行排序
BookInfo.objects.all().order_by('id')
BookInfo.objects.order_by('id') 例:查询所有图书的信息,按照id从大到小进行排序。
BookInfo.objects.all().order_by('-id') 例:把id大于3的图书信息按阅读量从大到小排序显示;
BookInfo.objects.filter(id__gt=3).order_by('-bread') 注:
属性上写上 - 号,表示从大到小进行排序
聚合函数
Sum Count Max Min Avg aggregate(聚合函数('属性'))
返回一个字典对象 使用前需先导入聚合类:
from django.db.models import Sum,Count,Max,Min,Avg 例:查询所有图书的数目 Count
BookInfo.objects.aggregate(Count('id'))
返回值类型:
{'id__count': 5} 例:查询所有图书阅读量的总和。
BookInfo.objects.aggregate(Sum('bread'))
{'bread__sum': 126} count函数 返回值是一个数字
作用:统计满足条件数据的数目 例:统计所有图书的数目。
BookInfo.objects.count()
例:统计id大于3的所有图书的数目
BookInfo.objects.filter(id__gt=3).count() 查询相关函数返回值总结:
get:返回一个对象
all:QuerySet 返回所有数据
filter:QuerySet 返回满足条件的数据
exclude:QuerySet 返回不满条件的数据
order_by:QuerySet 对查询结果进行排序
aggregate:字典 进行聚合操作
count:数字 返回查询集中数据的数目
get,filter,exclude参数中可以写查询条件。
查询集特性:
1.惰性查询:
只有在实际使用查询集中的数据的时候才会发生对数据库的真正查询 2.缓存:
当使用的是同一个查询集时,第一次的时候会发生实际数据库的查询,然后把结果缓存起来,之后再使用这个查询集时,使用的是缓存中的结果 限制查询集:
可以对一个查询集进行取下标或者切片操作来限制查询集的结果
b[0]就是取出查询集的第一条数据
b[0:1].get()也可取出查询集的第一条数据 如果b[0]不存在,会抛出IndexError异常 如果b[0:1].get()不存在,会抛出DoesNotExist异常。多条时抛MultiObjectsReturned
对一个查询集进行切片操作会产生一个新的查询集,下标不允许为负数 exists:判断一个查询集中是否有数据 True False
模型类关系
1.一对多关系
例:图书类-英雄类
models.ForeignKey() 定义在多的类中 2.多对多关系
例:新闻类-新闻类型类 体育新闻 国际
models.ManyToManyField() 定义在哪个类中都可以 3.一对一关系
例:员工基本信息类-员工详细信息类. 员工工号
models.OneToOneField定义在哪个类中都可以 关联查询(一对多)
在一对多关系中,一对应的类我们把它叫做一类,多对应的那个类我们把它叫做多类,我们把多类中定义的建立关联的类属性叫做关联属性 例:查询图书id为1的所有英雄的信息。
book = BookInfo.objects.get(id=1)
book.heroinfo_set.all() 通过模型类查询:
HeroInfo.objects.filter(hbook_id=1)
例:查询id为1的英雄所属图书信息。
hero =HeroInfo.objects.get(id=1)
hero.hbook 通过模型类查询:
BookInfo.objects.filter(heroinfo__id=1)
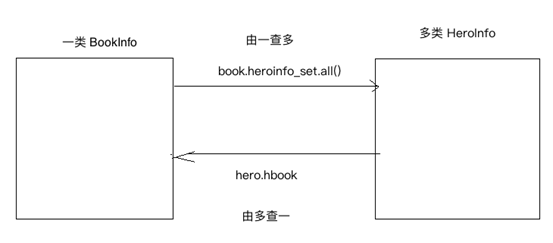
由一类的对象查询多类的时候:
一类的对象.多类名小写_set.all() #查询所用数据
由多类的对象查询一类的时候:
多类的对象.关联属性 #查询多类的对象对应的一类的对象
由多类的对象查询一类对象的id时候:
多类的对象. 关联属性_id
通过模型类实现关联查询: 例:查询图书信息,要求图书中英雄的描述包含'八'
BookInfo.objects.filter(heroinfo__hcomment__contains='八') 例:查询图书信息,要求图书中的英雄的id大于3
BookInfo.objects.filter(heroinfo__id__gt=3) 例:查询书名为“天龙八部”的所有英雄
HeroInfo.objects.filter(hbook__btitle='天龙八部') 通过多类的条件查询一类的数据:
一类名.objects.filter(多类名小写__多类属性名__条件名) 通过一类的条件查询多类的数据:
多类名.objects.filter(关联属性__一类属性名__条件名)
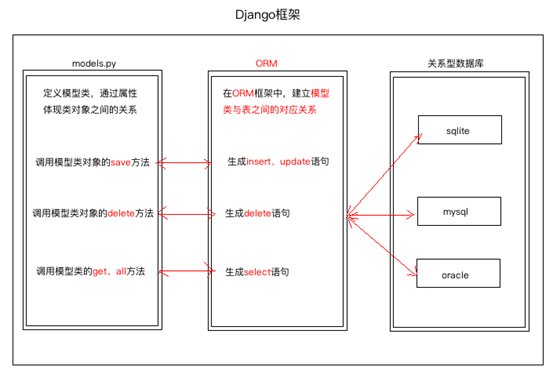
插入、更新和删除 调用模型类对象的save方法实现对模型类对应数据表的插入和更新
调用模型类对象的delete方法实现对模型类对应数据表数据的删除
自关联是一种特殊的一对多关系
管理器
objects
BookInfo.objects.all()
答:objects是Django帮我自动生成的管理器对象
通过这个管理器可以实现对数据的查询
objects是models.Manger类的一个对象
自定义管理器后 Django不再帮我们生成默认的objects管理器 1.自定义一个管理器类,这个类继承models.Manger类
2.再在具体的模型类里定义一个自定义管理器类的对象 自定义管理器类的应用场景:
1.改变查询的结果集
比如调用BookInfo.books.all()返回的是没有删除的图书的数据
2.添加额外的方法
管理器类中定义一个方法帮我们创建对应的模型类对象
使用self.model()就可以创建一个跟自定义管理器对应的模型类对象
元选项 Django默认生成的表名:
应用名小写_模型类名小写。
元选项:
需要在模型类中定义一个元类Meta
在里面定义一个类属性db_table就可以指定表名
2020-05-18
Django学习路32_创建管理员及内容补充+前面内容复习的更多相关文章
- Django学习路15_创建一个订单信息,并查询2020年\9月的信息都有哪些
在 app5.models.py 中添加一个 Order 表 class Order(models.Model): o_num = models.CharField(max_length= 16 ,u ...
- Django学习路13_创建用户登录,判断数据库中账号名密码是否正确
在 models.py 中设置数据库表的信息 from django.db import models # Create your models here. class User(models.Mod ...
- Django学习路10_创建一个新的数据库,指定列名并修改表名
在 models.py 中添加 from django.db import models # Create your models here. class Person(models.Model): ...
- [python][django学习篇][3]创建django web的数据库模型
推荐学习博客:http://pythonzh.cn/post/8/ 博客或者web界面向用户展示内容,它需要从某个地方获取博客内容或者web界面内容,才能够展示出来.通常来说:某个地方指的就是数据库 ...
- Django学习路23_if else 语句,if elif else 语句 forloop.first第一个元素 .last最后一个元素,注释
if else 格式 {% if 条件 %} <标签>语句</标签> {%else%} <标签>语句</标签> {%endif} 标签都可以添加样式 { ...
- Django学习路6_修改数据库为 mysql ,创建mysql及进行迁徙
在项目的 settings 中修改 DATABASES = { 'default': { # 'ENGINE': 'django.db.backends.sqlite3', # 'NAME': os. ...
- django学习-数据库配置-创建模型
数据库配置 在mysite/settings.py中,包含了django项目设置的python模块 通常,这个配置文件使用SQLite作为默认数据库.如果你不熟悉数据库,或者只是想尝试下django, ...
- django学习-安装、创建应用、编写视图
快速安装指南 py -3 -m pip install django >>> import django >>> django.get_version() '2.2 ...
- Django学习路21_views函数中定义字典及html中使用类实例对象的属性及方法
创建 app6 在项目的 settings 中进行注册 INSTALLED_APPS 里面添加 'app6.apps.App6Config' 在 app6 的models.py 中创建数据表 clas ...
随机推荐
- 三.接收并处理请求参数与QueryDict对象
一.get与post请求:重点看传参与接收参数 GET请求与传参 ---->url后面跟上?k1=v1&&k2=v2 POST请求与数据提交 (1)get请求:如直接在浏览 ...
- 小白写了一堆if-else,大神实在看不下去了,竟然用策略模式直接摆平了
这里涉及到一个关键词:策略模式,那么到底什么是策略模式呢?本文就来好好给大家讲讲策略模式,大家可以带着如下几个问题来阅读本文: 1. 如何通过策略模式优化业务逻辑代码(可以根据自己从事的工作思考) ...
- js的几个小问题
1.存一个有效期为7天的cookie,key = nickname, val = Ace 代码: function setCookie(key,val,expires){ let now=new Da ...
- python数据结构(一)
collections --容器数据类型,collections模块包含了除内置类型list,dict和tuple以外的其他容器数据类型. Counter 作为一个容器可以追踪相同的值增加了多少次 # ...
- Spring中AOP相关的API及源码解析
Spring中AOP相关的API及源码解析 本系列文章: 读源码,我们可以从第一行读起 你知道Spring是怎么解析配置类的吗? 配置类为什么要添加@Configuration注解? 谈谈Spring ...
- (私人收藏)java实例、知识点、面试题、SHH、Spring、算法、图书管理系统、综合参考
https://pan.baidu.com/s/1hkmgJU6pf2sBjNV1NlOaNgr6l2 Java趣味编程100例java经典选择题100例及答案java面试题大全java排序算法大全j ...
- spring和springmvc包扫描问题
写这篇博客之前,橘子松必须感慨下!!找了我一下午加一晚上(md),问了几个朋友也没找到.凉了啊 在搭建ssm之前,我把controller service mapper包扫描用基本包扫描 都写在a ...
- SpringBoot2.x入门:引入web模块
前提 这篇文章是<SpringBoot2.x入门>专辑的第3篇文章,使用的SpringBoot版本为2.3.1.RELEASE,JDK版本为1.8. 主要介绍SpringBoot的web模 ...
- docker容器化python服务部署(supervisor-gunicorn-flask)
docker容器化python服务部署(supervisor-gunicorn-flask) 本文系作者原创,转载请注明出处: https://www.cnblogs.com/further-furt ...
- bootstrap悬停下拉菜单显示
使用Bootstrap导航条组件时,如果你的导航条带有下拉菜单,那么这个带下拉菜单的导航在点击时只会浮出下拉菜单,它本身的href属性会失效,也就是失去了超链接功能,这并不是我想要的,我希望导航条的链 ...