Java基于POI实现excel任意多级联动下拉列表——支持从数据库查询出多级数据后直接生成【附源码】

- Excel相关知识点
(1)名称管理器——Name Manager
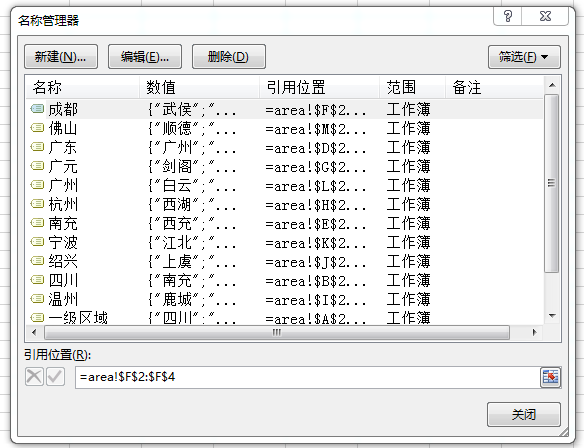
【CoderBaby】首先需要创建多个名称(包含key及value),作为下拉列表的数据源,后续通过名称引用。可通过菜单:“公式”---“名称管理器”找到,如下图:
(2)数据验证——DataValidation
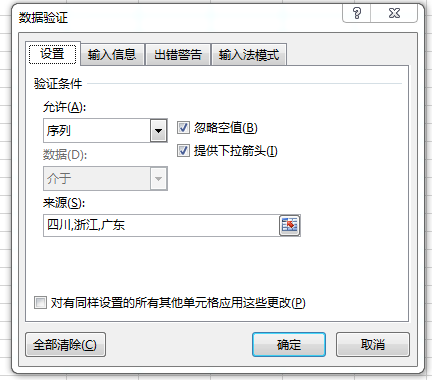
此处我们需要选List(序列),Source(来源)选项;可通过菜单:“数据”---“数据验证”找到,如下图:
(3)INDIRECT公式
通过数据验证的Source(来源)设置为Indirect公式来控制级联的效果,如下图:

- 代码实现
(1)数据准备—以省市县三级为例
- 创建数据源(多级区域)表:Area(根据实际情况,可以是部门、跨国公司、物种分类属性等)
CREATE TABLE `area` (
`area_id` int NOT NULL AUTO_INCREMENT,
`area_name` varchar(64) NOT NULL,
`area_desc` varchar(256) DEFAULT NULL,
`parent_area_id` int DEFAULT NULL,
PRIMARY KEY (`area_id`)
) ENGINE=InnoDB AUTO_INCREMENT=32 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci |
- 初始化数据
省级数据:
NSERT INTO area(area_name,area_desc) VALUES ("四川","四川省"),("浙江","浙江省"),("广东","广东省");
市级数据:
INSERT INTO area(area_name,area_desc, parent_area_id) VALUES ("南充","南充市", 1),("成都","成都市", 1), ("广元","广元市", 1),("杭州","杭州市", 2),("温州","温州市", 2),("绍兴","绍兴市", 2),("宁波","宁波市", 2),("广州","广州市", 3),("佛山","佛山市", 3);
县级数据:
INSERT INTO area(area_name,area_desc, parent_area_id) VALUES ("西充","西充县", 4),("仪陇","仪陇县", 4),("武侯","武侯区", 5),("龙泉","龙泉区", 5),("青羊","青羊区", 5),("剑阁","剑阁县", 6),("青川","青川县", 6);
INSERT INTO area(area_name,area_desc, parent_area_id) VALUES ("西湖","西湖区", 7),("江干","江干区", 7),("鹿城","鹿城区", 8),("龙湾","龙湾区", 8),("上虞","上虞区", 9),("越城","越城区", 9),("江北","江北区", 10),("镇海","镇海区", 10);
INSERT INTO area(area_name,area_desc, parent_area_id) VALUES ("白云","白云区", 11),("天河","天河区", 11),("顺德","顺德区", 12),("南海","南海区", 12);
(2)实现逻辑说明
- 递归查询数据源表(area),构建“以parent_area_id为key,子区域名称列表为value的HashMap”
(a)第一级区域查询,根据parent_area_id为空的查询出第一级区域列表
List<String> firstAreaNames = new ArrayList(); String queryArea0 = "select area_id, area_name from area where parent_area_id IS NULL";
Map<Integer, String> area0List = new LinkedHashMap<>();
int areaLevel = 1;
jdbc.query(queryArea0, rs -> {
area0List.put(rs.getInt("area_id"), rs.getString("area_name"));
firstAreaNames.add(rs.getString("area_name"));
});
areaList.put("一级区域", firstAreaNames);
以区域ID为key,子区域名称列表为value的HashMap定义如下: private Map<String, List<String>> areaList = new LinkedHashMap<>();
(b)传入parent_area_id查询子区域area_id和area_name,如此反复递归,直到没有子区域为止
Map<Integer, String> subAreas = queryAreaInfo(area0List);
while (subAreas.keySet().size() > 0) {
areaLevel++;
subAreas = queryAreaInfo(subAreas);
}
queryAreaInfo函数定义:
private Map<Integer, String> queryAreaInfo(Map<Integer, String> parentAreas) {
Map<Integer, String> subAreas = new LinkedHashMap<>();
for (Integer areaId : parentAreas.keySet()) {
String queryArea = "select area_id, area_name from area where parent_area_id = '" + areaId.intValue() + "'";
List<String> areaNames = new ArrayList();
jdbc.query(queryArea, rs -> {
subAreas.put(rs.getInt("area_id"), rs.getString("area_name"));
areaNames.add(rs.getString("area_name"));
});
if (areaNames.size() > 0) {
areaList.put(parentAreas.get(areaId), areaNames);
}
}
return subAreas;
}
注:必须用LinkedHashMap,否则初始化数据会重新排序,导致后续生成下拉列表出错
(c)根据计算出的区域层级,动态构造首行标题栏
for (int i = 1; i <= areaTotalLevel; i++) {
String cellValue = convertToChineseNumber(i) + "级区域";
firstRow.createCell(columnIndex++).setCellValue(cellValue);
}
- 根据构建的“以parent_area_id为key,子区域名称列表为value的HashMap”,创建名称管理器和数据验证
/**
* 构造名称管理器和数据验证及公式
*
* @param workbook 目标工作簿
* @param file 输出的文件全路径
* @param dropDownDataSource 以父级id为key,子级名称列表为value的集合
* @param dataSourceSheetName 作为数据源的工作表名称
* @param columnStep 起始列的列号(以下表0为初始列)
* @param totalLevel 总共的层级数量
* @throws IOException
* @throws InvalidFormatException
*/
private void Cascade(Workbook workbook, File file, Map<String, List<String>> dropDownDataSource,
final String dataSourceSheetName, final int columnStep, final int totalLevel) throws IOException, InvalidFormatException { Sheet dataSourceSheet = workbook.createSheet(dataSourceSheetName);
workbook.setSheetHidden(workbook.getSheetIndex(dataSourceSheet), true); Row headerRow = dataSourceSheet.createRow(0);
String[] firstValidationArray = null;
boolean firstTime = true;
int columnIndex = 0;
// 构造名称管理器数据源
for (String key : dropDownDataSource.keySet()) {
Cell cell = headerRow.createCell(columnIndex);
cell.setCellValue(key);
if (dropDownDataSource.get(key) == null || dropDownDataSource.get(key).size() == 0) {
continue;
}
ArrayList<String> values = (ArrayList) dropDownDataSource.get(key);
if (firstTime) {
firstValidationArray = values.toArray(new String[values.size()]);
}
int dataRowIndex = 1;
for (String value : values) {
Row row = firstTime ? dataSourceSheet.createRow(dataRowIndex) : dataSourceSheet.getRow(dataRowIndex);
if (row == null) {
row = dataSourceSheet.createRow(dataRowIndex);
}
row.createCell(columnIndex).setCellValue(value);
dataRowIndex++;
} // 构造名称管理器
String range = buildRange(columnIndex, 2, values.size());
Name name = workbook.createName();
name.setNameName(key);
String formula = dataSourceSheetName + "!" + range;
name.setRefersToFormula(formula);
columnIndex++;
firstTime = false;
} Sheet assetSheet = workbook.getSheetAt(0);
// 第一级设置DataValidation
XSSFDataValidationHelper dvHelper = new XSSFDataValidationHelper((XSSFSheet) assetSheet);
DataValidationConstraint firstConstraint = dvHelper.createExplicitListConstraint(firstValidationArray);
CellRangeAddressList firstRangeAddressList = new CellRangeAddressList(1, MAX_ROWS, 0 + columnStep, 0 + columnStep);
DataValidation firstDataValidation = dvHelper.createValidation(firstConstraint, firstRangeAddressList);
firstDataValidation.setSuppressDropDownArrow(true);
assetSheet.addValidationData(firstDataValidation); // 剩下的层级设置DataValidation
for (int i = 1; i < totalLevel; i++) {
char[] offset = new char[1];
offset[0] = (char) ('A' + columnStep + i - 1);
String formulaString = buildFormulaString(new String(offset), 2);
XSSFDataValidationConstraint dvConstraint = (XSSFDataValidationConstraint) dvHelper.createFormulaListConstraint(formulaString);
CellRangeAddressList regions = new CellRangeAddressList(1, MAX_ROWS, 0 + columnStep + i, 0 + columnStep + i);
XSSFDataValidation dataValidationList = (XSSFDataValidation) dvHelper.createValidation(dvConstraint, regions);
dataValidationList.setSuppressDropDownArrow(true);
assetSheet.addValidationData(dataValidationList);
}
// 将结果输出到excel
FileOutputStream os = null;
try {
os = new FileOutputStream(file);
workbook.write(os);
} catch (Exception e) {
e.printStackTrace();
} finally {
IOUtils.closeQuietly(os);
}
}
说明:
构造名称引用的数据源区域:
private String buildRange(int offset, int startRow, int rowCount) {
char start = (char) ('A' + offset);
return "$" + start + "$" + startRow + ":$" + start + "$" + (startRow + rowCount - 1);
}
构造indirect公式:
private String buildFormulaString(String offset, int rowNum) {
return "INDIRECT($" + offset + (rowNum) + ")";
}
- 最终实现效果
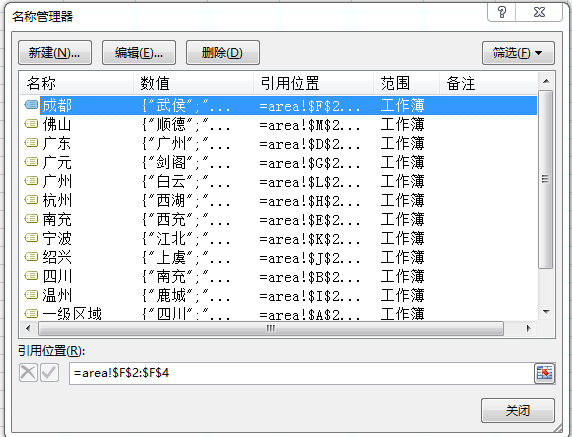
名称管理器的数据源工作表:

名称管理器:
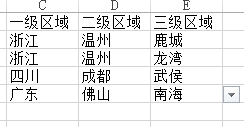
生成的模板:
附:
1) Excel 多级联动下拉列表: https://blog.csdn.net/zhan107876/article/details/95341684
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
*******************************************************************************************
精力有限,想法太多,专注做好一件事就行
- 我只是一个程序猿。5年内把代码写好,技术博客字字推敲,坚持零拷贝和原创
- 写博客的意义在于锻炼逻辑条理性,加深对知识的系统性理解,锻炼文笔,如果恰好又对别人有点帮助,那真是一件令人开心的事
*******************************************************************************************
Java基于POI实现excel任意多级联动下拉列表——支持从数据库查询出多级数据后直接生成【附源码】的更多相关文章
- POI导出大量数据的简单解决方案(附源码)-Java-POI导出大量数据,导出Excel文件,压缩ZIP(转载自iteye.com)
说明:我的电脑 2.0CPU 2G内存 能够十秒钟导出 20W 条数据 ,12.8M的excel内容压缩后2.68M 我们知道在POI导出Excel时,数据量大了,很容易导致内存溢出.由于Excel ...
- 利用Java针对MySql封装的jdbc框架类 JdbcUtils 完整实现(包含增删改查、JavaBean反射原理,附源码)
最近看老罗的视频,跟着完成了利用Java操作MySql数据库的一个框架类JdbcUtils.java,完成对数据库的增删改查.其中查询这块,包括普通的查询和利用反射完成的查询,主要包括以下几个函数接口 ...
- Java使用POI操作Excel文件
1.简介 Apache POI是Apache软件基金会的开放源码函式库,POI提供API给Java程序对Microsoft Office格式文件读和写的功能. 2.依赖的jar包 <!-- ex ...
- Java Struts2 POI创建Excel文件并实现文件下载
Java Struts2 POI创建Excel文件并实现文件下载2013-09-04 18:53 6059人阅读 评论(1) 收藏 举报 分类: Java EE(49) Struts(6) 版权声明: ...
- JAVA使用POI读取EXCEL文件的简单model
一.JAVA使用POI读取EXCEL文件的简单model 1.所需要的jar commons-codec-1.10.jarcommons-logging-1.2.jarjunit-4.12.jarlo ...
- JAVA使用POI获取Excel的列数与行数
Apache POI 是用Java编写的免费开源的跨平台的 Java API,Apache POI提供API给Java程式对Microsoft Office格式档案读和写的功能. 下面这篇文章给大家介 ...
- java通过poi编写excel文件
public String writeExcel(List<MedicalWhiteList> MedicalWhiteList) { if(MedicalWhiteList == nul ...
- java使用POI实现excel文件的读取,兼容后缀名xls和xlsx
需要用的jar包如下: 如果是maven管理的项目,添加依赖如下: <!-- https://mvnrepository.com/artifact/org.apache.poi/poi --&g ...
- Java之POI读取Excel的Package should contain a content type part [M1.13]] with root cause异常问题解决
Java之POI读取Excel的Package should contain a content type part [M1.13]] with root cause异常问题解决 引言: 在Java中 ...
随机推荐
- Java 接口 抽象类 抽象方法
abstract class elehousekeeping { //抽象家用电器类 abstract void opermode(); //抽象方法} class TV extends elehou ...
- Gradle Wrapper
Gradle Wrapper 当把本地一个项目放入到远程版本库的时候,如果这个项目是以gradle构建的,那么其他人从远程仓库拉取代码之后如果本地没有安装过gradle会无法编译运行,如果对gradl ...
- CodeForces - 505B-Mr. Kitayuta's Colorful Graph(暴力)
Mr. Kitayuta has just bought an undirected graph consisting of n vertices and medges. The vertices o ...
- WinMTR 网络测试工具-九五小庞
WinMTR(建议优先使用) 百度下载工具 链接:https://pan.baidu.com/s/19ArKSTA2amsa4p6vHegDIQ 提取码:cy4y WinMTR是mtr工具在Windo ...
- Spring-代理模式
代理模式 目录 代理模式 1. 代理模式的分类 2. 静态代理 1. 角色分析 2. 代码步骤 3. 代理的好处 4. 进一步理解 3. 动态代理 1. 角色分析 2. 对动态代理的两个关键类的理解 ...
- transition实现图片轮播
<!DOCTYPE html> <html> <head> <meta charset="utf-8" /> <title&g ...
- Require.js中的路径在IDEA中的最佳实践
本文主要讲述require.js在IDEA中路径智能感知的办法和探索中遇到的问题. 测试使用的目录结构:一种典型的thinkphp 6的目录结构,如下图. 现在我通过在 vue-a.js 中运用不同的 ...
- 单元测试unittest(基于数据驱动的框架:unittest+HTMLTestRunner/BeautifulReport+yaml+ddt)
一.定义 unittest单元测试框架不仅可以适用于单元测试,还可以适用WEB自动化测试用例的开发与执行,该测试框架可组织执行测试用例,并且提供了丰富的断言方法,判断测试用例是否通过,最终生成测试结果 ...
- Python 字符串去除相邻重复的元素
1 def quchong(S): 2 str1=[""] 3 for i in S: 4 if i == str1[-1]: 5 str1.pop() 6 else: 7 str ...
- 10.深入k8s:调度的优先级及抢占机制源码分析
转载请声明出处哦~,本篇文章发布于luozhiyun的博客:https://www.luozhiyun.com 源码版本是1.19 上一篇我们将了获取node成功的情况,如果是一个优先pod获取nod ...