使用Selenium爬取京东电商数据(以手机商品为例)
进入京东(https://www.jd.com)后,我如果搜索特定的手机产品,如oppo find x2,会先出现如下的商品列表页:
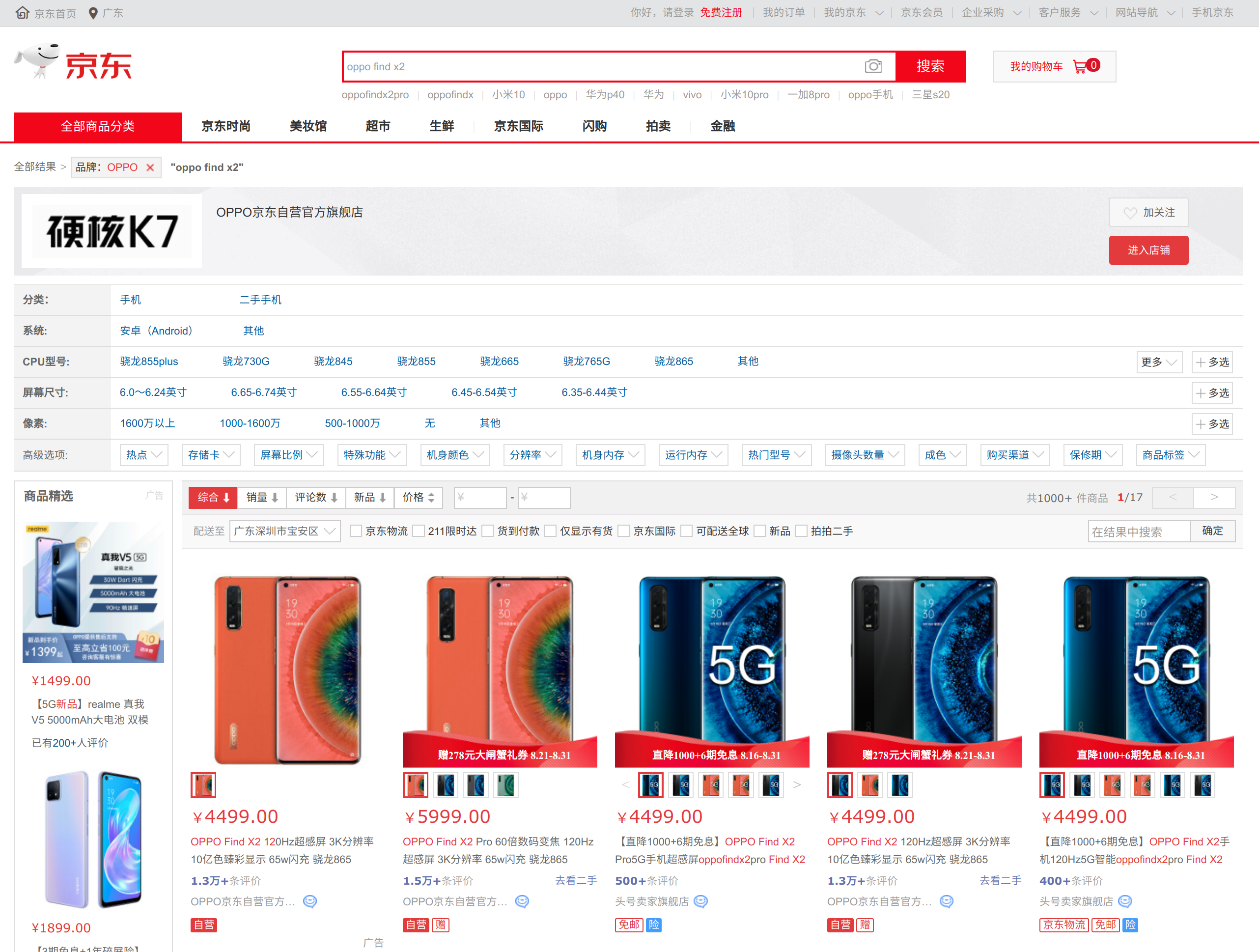
如果点击进入其中一个商品会进入到如下图所示的商品详情页,可以看到用户对该商品的评论:
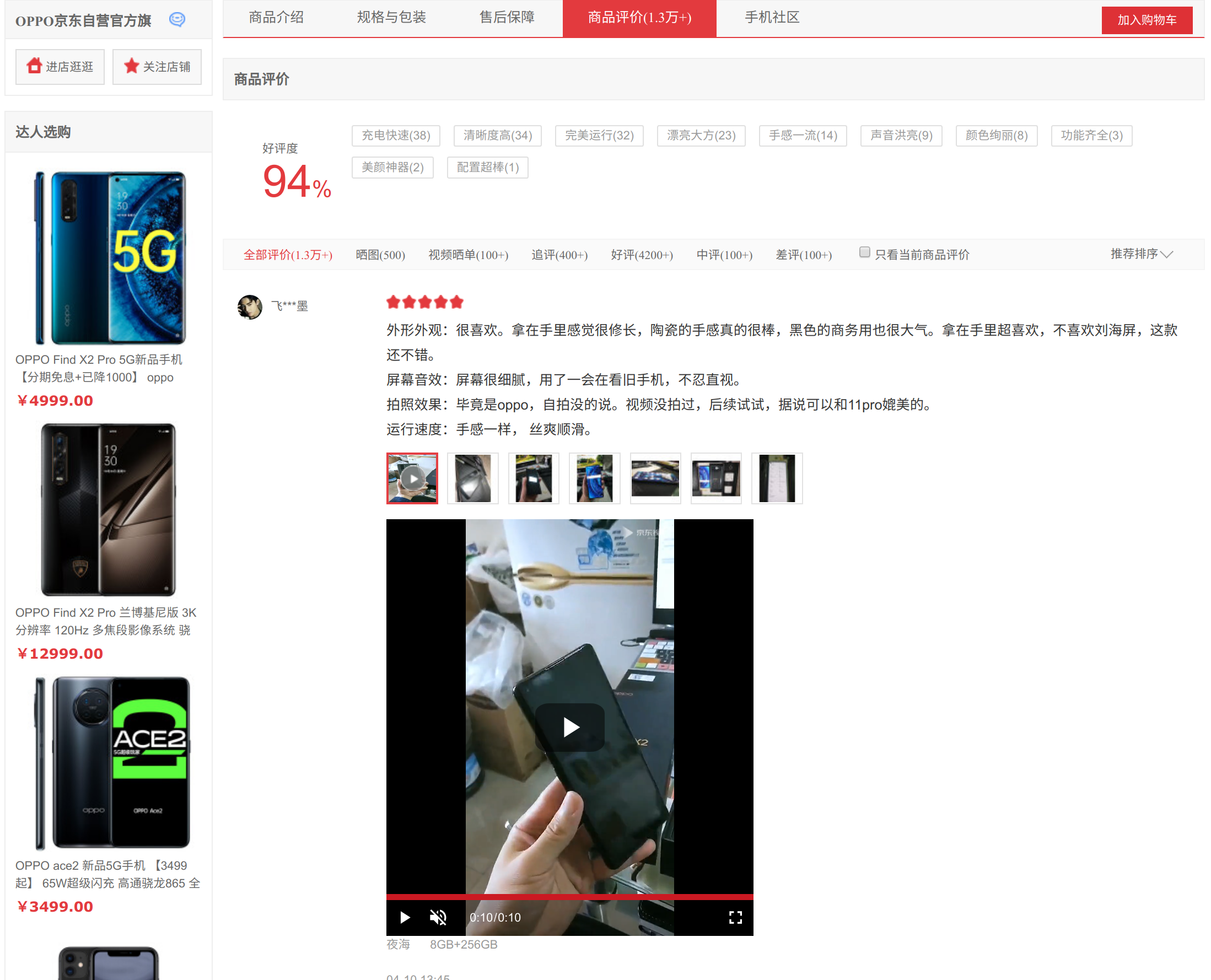
这篇博客主要是记录我怎么爬取商品列表页和详情页,我使用Selenium,模拟浏览器实现自动化的用户浏览操作,能在一定程度上规避反爬虫(爬取平台对你进行屏蔽操作)的风险。总体来说,列表页和详情页的爬取数据过程中用户模拟行为如下所示:

一、商品列表页数据爬取
首先,先介绍爬取列表页所需要的实现的功能:
- 设置模拟浏览器(open_browser)
- 初始化参数(init_variable)
- 解析并爬取列表单页内容(parse_JDpage)
- 翻页(turn_JDpage)
- 自动化爬取多页(JDcrawl)
1. 设置模拟浏览器
def open_browser(self):
# 若下列命令报错,请进入下面链接下载chromedriver然后放置在/user/bin/下即可
# https://chromedriver.storage.googleapis.com/index.html?path=2.35/
self.options = webdriver.ChromeOptions()
self.options.add_argument(self.user_agent)
self.browser = webdriver.Chrome(options = self.options)
# 隐式等待:等待页面全部元素加载完成(即页面加载圆圈不再转后),才会执行下一句,如果超过设置时间则抛出异常
try:
self.browser.implicitly_wait(10)
except:
print("页面无法加载完成,无法开启爬虫操作!")
# 显式等待:设置浏览器最长允许超时的时间
self.wait = WebDriverWait(self.browser, 10)
上述代码解释:
- webdriver.ChromeOptions() :如果运行后报错,请下载chomedriver至/user/bin/下即可解决问题。
- self.user_agent :用户代理(user-agent)用于帮助网站识别请求用户的浏览器类别,以便于网站发送相应的网页数据。有人建议不加可以anti反爬虫,但这里我是加上了(可右击网页‘检查’里找到header后,从里面获取user_agent,例如 "Mozilla/** (X11; Linux x**) AppleWebKit/*** (KHTML, like Gecko) Chrome/7*** Safari/**" )。
- 关于Selenium中的等待有三种:强制等待,隐式等待和显式等待。 (1) 强制等待就是 time.sleep() ,就等待完指定时间后便进行后续操作; (2) 隐式等待是 implicitly_wait() ,括号内设置的是页面加载最长等待时间,如果页面在规定时间内加载完成就直接进行下一步。如果页面在规定时间都没加载完,就会超时报错。注意:隐式等待是作用在整个浏览器周期中,不需要像强制等待那样需要多次设置。(3) 显式等待是 WebDriverWait() ,它是让程序每隔几秒(默认poll_frequency=0.5, 0.5秒)看下,如果出现了所需元素就执行下一步,但如果间隔检查一直没检测到所需元素且检查总时长达到给的最长超时时间(即参数timeout,单位是秒),就会报无元素错误。如果隐式和显式等待一起用,等待的最长的时间取两者最大的时长。一般推荐在定位元素前检查元素存在使用显式等待。
2. 初始化参数
def init_variable(self, url_link, search_key, user_agent):
# url_link为电商平台首页,search_key为商品搜索词
self.url = url_link
self.keyword = search_key
self.isLastPage = False
self.user_agent = user_agent
上述参数分别是:
- url :京东首页链接。
- keyword :商品搜索词,这里我用的是‘oppo find x2’。
- isLastPage :布尔值,当前页面是否为页末。
- user_agent :用户代理。
3. 解析并爬取列表单页内容
def parse_JDpage(self):
try:
# 定位元素并获取元素下的字段值(商品标题,价格,评论数,商品链接)
names = self.wait.until(EC.presence_of_all_elements_located((By.XPATH, '//div[@class="gl-i-wrap"]/div[@class="p-name p-name-type-2"]/a/em')))
prices = self.wait.until(EC.presence_of_all_elements_located((By.XPATH, '//div[@class="gl-i-wrap"]/div[@class="p-price"]/strong/i')))
comment_nums = self.wait.until(EC.presence_of_all_elements_located((By.XPATH, '//div[@class="gl-i-wrap"]/div[@class="p-commit"]/strong')))
links = self.wait.until(EC.presence_of_all_elements_located((By.XPATH, '//li[@class="gl-item"]')))
page_num = self.wait.until(EC.presence_of_element_located((By.XPATH, '//div[@class="page clearfix"]//input[@class="input-txt"]')))
names = [item.text for item in names]
prices = [price.text for price in prices]
comment_nums = [comment_num.text for comment_num in comment_nums]
links = ["https://item.jd.com/{sku}.html".format(sku = link.get_attribute("data-sku")) for link in links]
page_num = page_num.get_attribute('value')
except selenium.common.exceptions.TimeoutException:
print('parse_page: TimeoutException 网页超时')
self.parse_JDpage()
except selenium.common.exceptions.StaleElementReferenceException:
print('turn_page: StaleElementReferenceException 某元素因JS刷新已过时没出现在页面中')
print('刷新并重新解析网页...')
self.browser.refresh()
self.parse_JDpage()
print('解析成功')
return names, prices, comment_nums, links, page_num
上述代码解释如下:
- 用 try...except... 是因为爬虫不是每次都能爬取顺利的,有时候会因为各种原因而报错,详情可见selenium的常见异常,例如:网络慢或京东反爬虫给你空白信息,导致网页超时。而某元素因为更新不及时,导致报错 StaleElementReferenceException 。在不同情况使用不同的手段,我在爬取京东列表页时,只要给够等待时间,一般来说是不会报网页超时的,而且京东对列表页的爬虫相对宽松些,不会像后面要爬的详情页那样时不时反爬虫给你空白信息,导致网页超时。此外,对待元素没出现在Dom(Document Object Model, 文档对象模型,它将HTML文档以树结构表达)中,只要重新刷新再重爬就好了。
- EC.presence_of_all_elements_located 和 EC.presence_of_element_located ,这两方法是判断是否至少有一个元素或某个元素存在与Dom树中,直白来说,就是检查你要爬的元素字段在不在当前页面上。
- By.XPATH :Selenium有很多元素定位方法,详情请见Selenium八种元素定位方法。个人偏好用Xpath,易学且Chrome在检查元素里还能直接右击复制出Xpath。具体使用方法可参考python+selenium基础之XPATH定位。
- wait.until() :until是当定位的元素出现则说明该显示等待检查间隔内检查成功,可以进行下面的代码了。与之相反的是 wait.until_not() ,当定位元素消失则进行后续代码,而不再等待。
- 建议读者结合真实场景内容去看代码会更快理解以上内容。
4. 翻页
def turn_JDpage(self):
# 移到页面末端并点击‘下一页’
try:
self.browser.find_element_by_xpath('//a[@class="pn-next" and @onclick]').click()
time.sleep(1) # 点击完等1s
self.browser.execute_script("window.scrollTo(0, document.body.scrollHeight)")
time.sleep(2) # 下拉后等2s
# 如果找不到元素,说明已到最后一页
except selenium.common.exceptions.NoSuchElementException:
self.isLastPage = True
# 如果页面超时,跳过此页
except selenium.common.exceptions.TimeoutException:
print('turn_page: TimeoutException 网页超时')
self.turn_JDpage()
# 如果因为JS刷新找不到元素,重新刷新
except selenium.common.exceptions.StaleElementReferenceException:
print('turn_page: StaleElementReferenceException 某元素因JS刷新已过时没出现在页面中')
print('刷新并重新翻页网页...')
self.browser.refresh()
self.turn_JDpage()
print('翻页成功')
上述代码解释:
- self.browser.execute_script("window.scrollTo(0, document.body.scrollHeight)") 是模拟浏览器向下滑动网页,避免由于页面展示不全而报错。
- self.browser.refresh() :页面刷新。
- time.sleep() :强制等待下,过快会被京东反爬虫。
5. 自动化爬取多页
def JDcrawl(self, url_link, search_key, user_agent, save_path):
# 初始化参数
self.init_variable(url_link, search_key, user_agent)
df_names = []
df_prices = []
df_comment_nums = []
df_links = [] # 打开模拟浏览器
self.open_browser()
# 进入目标JD网站
self.browser.get(self.url)
# 在浏览器输入目标商品名,然后搜索
self.browser.find_element_by_id('key').send_keys(self.keyword)
self.browser.find_element_by_class_name('button').click() # 开始爬取
self.browser.execute_script("window.scrollTo(0, document.body.scrollHeight)")
print("################\n##开启数据爬虫##\n################\n")
while self.isLastPage != True:
page_num = 0
names, prices, comment_nums, links, page_num = self.parse_JDpage()
print("已爬取完第%s页" % page_num)
df_names.extend(names)
df_prices.extend(prices)
df_comment_nums.extend(comment_nums)
df_links.extend(links)
self.turn_JDpage() # 退出浏览器
self.browser.quit() # 保存结果
results = pd.DataFrame({'title':df_names,
'price':df_prices,
'comment_num':df_comment_nums,
'url':df_links})
results.to_csv(save_path, index = False)
print("爬虫全部结束,共%d条数据,最终结果保存至%s" % (len(results),save_path))
以上代码就是将之前模块组合在一起,这里不过多进行过多解释。
二、商品详情页数据爬取
当我们爬取完列表页数据后,可以通过依次进入各个商品详情页爬取用户评论内容。虽然大体流程跟列表页爬取流程差不多,但具体爬取过程的细节上还是有些不同的处理方法。
- 清洗列表页数据(clean_overview)
- 设置模拟浏览器(open_browser)
- 初始化参数(init_variable)
- 解析并爬取详情单页内容(parse_JDpage)
- 翻页(turn_JDpage)
- 自动化爬取多页(JDcrawl_detail)
1. 清洗列表页数据
因为爬取商品列表中的商品很多不是我们真正想要的爬取的内容,比如:我们不想看二手拍拍的商品,只想看oppo find x2而不适它的pro版本,另外也不想看oppo find x2的相关配件商品。所以,我们要对列表页数据执行清洗过程:(1) 不要评论少的商品;(2) 不要商品名称带‘拍拍’标签的商品;(3) 不要部分匹配搜索词的商品;(4) 不要价格过低的商品。清洗代码如下:
def clean_overview(self, csv_path, search_keyword):
'''
清洗数据
1. 清洗掉少于11条评论的数据
2. 清洗掉含‘拍拍’关键词的数据
3. 清洗掉不含搜索关键词的数据
4. 清洗掉价格过低的数据 输入:
1. csv_path (str): 爬取的overview商品展示页下的结果文件路径。
2. search_keyword (str): 爬取的overview商品展示页下搜索关键词。
输出:
1. overview_df (pd.DataFrame): 清洗好的overview数据
'''
overview_path = csv_path
overview_df = pd.read_csv(overview_path)
search_key = search_keyword # 1. 清洗掉少于11条评论的数据
print("原始数据量:%s" % len(overview_df))
drop_idxs = []
comment_nums = overview_df['comment_num']
for i, comment_num in enumerate(comment_nums):
try:
if int(comment_num[:-3]) in list(range(11)):
drop_idxs.append(i)
except:
pass
print("清洗掉少于11条评论的数据后的数据量:%s(%s-%s)" % (len(overview_df) - len(drop_idxs), len(overview_df), len(drop_idxs)))
overview_df.drop(drop_idxs, axis = 0, inplace = True)
overview_df = overview_df.reset_index(drop = True) # 2. 清洗掉含‘拍拍’关键词的数据
drop_idxs = []
comment_titles = overview_df['title']
for i, title in enumerate(comment_titles):
try:
if title.startswith('拍拍'):
drop_idxs.append(i)
except:
pass
print("清洗掉含‘拍拍’关键词的数据后的数据量:%s(%s-%s)" % (len(overview_df) - len(drop_idxs), len(overview_df), len(drop_idxs)))
overview_df.drop(drop_idxs, axis = 0, inplace = True)
overview_df = overview_df.reset_index(drop = True) # 3. 清洗掉不含搜索关键词的数据
drop_idxs = []
comment_titles = overview_df['title']
for i, title in enumerate(comment_titles):
if search_key.replace(" ","") not in title.lower().replace(" ",""):
drop_idxs.append(i)
print("清洗掉不含搜索关键词的数据后的数据量:%s(%s-%s)" % (len(overview_df) - len(drop_idxs), len(overview_df), len(drop_idxs)))
overview_df.drop(drop_idxs, axis = 0, inplace = True)
overview_df = overview_df.reset_index(drop = True) # 4. 清洗掉价格过低/过高的数据
drop_idxs = []
comment_prices = overview_df['price']
prices_df = {}
for p in comment_prices:
if p not in list(prices_df.keys()):
prices_df[p] = 1
else:
prices_df[p] += 1
# print("各价格下的商品数:", prices_df)
# {4499: 89, 5999: 5, 6099: 1, 12999: 2, 6999: 1, 89: 1, 29: 1}
# 通过上述结果,我们只要价位为4499的商品结果即可了
for i, p in enumerate(comment_prices):
if p != 4499.0:
drop_idxs.append(i)
print("清洗掉价格过低/过高的数据后的数据量:%s(%s-%s)" % (len(overview_df) - len(drop_idxs), len(overview_df), len(drop_idxs)))
overview_df.drop(drop_idxs, axis = 0, inplace = True)
overview_df = overview_df.reset_index(drop = True)
return overview_df
2. 设置模拟浏览器
同样地,我们先进行浏览器设置。注意:在这里我们的隐式等待和显式等待都增加了,这里的原因是因为京东对详情页的爬取加重防守了,所以我们得给页面加载和元素定位更多的等待和尝试时间,不然会什么都爬不到。
def open_browser(self):
'''设置浏览器'''
# 若下列命令报错,请进入下面链接下载chromedriver然后放置在/user/bin/下即可
# https://chromedriver.storage.googleapis.com/index.html?path=2.35/
self.options = webdriver.ChromeOptions()
self.browser = webdriver.Chrome(options = self.options)
# 隐式等待:等待页面全部元素加载完成(即页面加载圆圈不再转后),才会执行下一句,如果超过设置时间则抛出异常
try:
self.browser.implicitly_wait(50)
except:
print("页面无法加载完成,无法开启爬虫操作!")
# 显式等待:设置浏览器最长允许超时的时间
self.wait = WebDriverWait(self.browser, 30)
3. 初始化参数
这里增加了两个变量 isLastPage 和 ignore_page ,因为京东会自动折叠掉用户默认评价(即忽略评价),如果点击查看忽略评价会蹦出新的评论窗口,所以后续代码需要这两个变量帮助爬虫正常进行。
def init_variable(self, csv_path, search_key, user_agent):
'''初始化变量'''
self.csv_path = csv_path # 商品总览页爬取结果文件路径
self.keyword = search_key # 商品搜索关键词
self.isLastPage = False # 是否为页末
self.ignore_page = False # 是否进入到忽略评论页面
self.user_agent = user_agent # 用户代理,这里暂不用它
4. 解析并爬取详情单页内容
def parse_JDpage(self):
try:
time.sleep(10) # 下拉后等10s
# 定位元素(用户名,用户等级,用户评分,用户评论,评论创建时间,购买选择,页码)
user_names = self.wait.until(EC.presence_of_all_elements_located((By.XPATH, '//div[@class="user-info"]')))
user_levels = self.wait.until(EC.presence_of_all_elements_located((By.XPATH, '//div[@class="user-level"]')))
user_stars = self.wait.until(EC.presence_of_all_elements_located((By.XPATH, '//div[@class="comment-column J-comment-column"]/div[starts-with(@class, "comment-star")]')))
comments = self.wait.until(EC.presence_of_all_elements_located((By.XPATH, '//div[@class="comment-column J-comment-column"]/p[@class="comment-con"]')))
order_infos = self.wait.until(EC.presence_of_all_elements_located((By.XPATH, '//div[@class="comment-item"]//div[@class="order-info"]')))
if self.ignore_page == False:
# 如果没进入忽略页
page_num = self.wait.until(EC.presence_of_element_located((By.XPATH, '//a[@class="ui-page-curr"]')))
else:
# 如果进入忽略页
page_num = self.wait.until(EC.presence_of_element_located((By.XPATH, '//div[@class="ui-dialog-content"]//a[@class="ui-page-curr"]')))
# 获取元素下的字段值
user_names = [user_name.text for user_name in user_names]
user_levels = [user_level.text for user_level in user_levels]
user_stars = [user_star.get_attribute('class')[-1] for user_star in user_stars]
create_times = [" ".join(order_infos[0].text.split(" ")[-2:]) for order_info in order_infos]
order_infos = [" ".join(order_infos[0].text.split(" ")[:-2]) for order_info in order_infos]
comments = [comment.text for comment in comments]
page_num = page_num.text
except selenium.common.exceptions.TimeoutException:
print('parse_page: TimeoutException 网页超时')
self.browser.refresh()
self.browser.find_element_by_xpath('//li[@data-tab="trigger" and @data-anchor="#comment"]').click()
time.sleep(30)
user_names, user_levels, user_stars, comments, create_times, order_infos, page_num = self.parse_JDpage()
except selenium.common.exceptions.StaleElementReferenceException:
print('turn_page: StaleElementReferenceException 某元素因JS刷新已过时没出现在页面中')
user_names, user_levels, user_stars, comments, create_times, order_infos, page_num = self.parse_JDpage()
return user_names, user_levels, user_stars, comments, create_times, order_infos, page_num
上述代码解释:
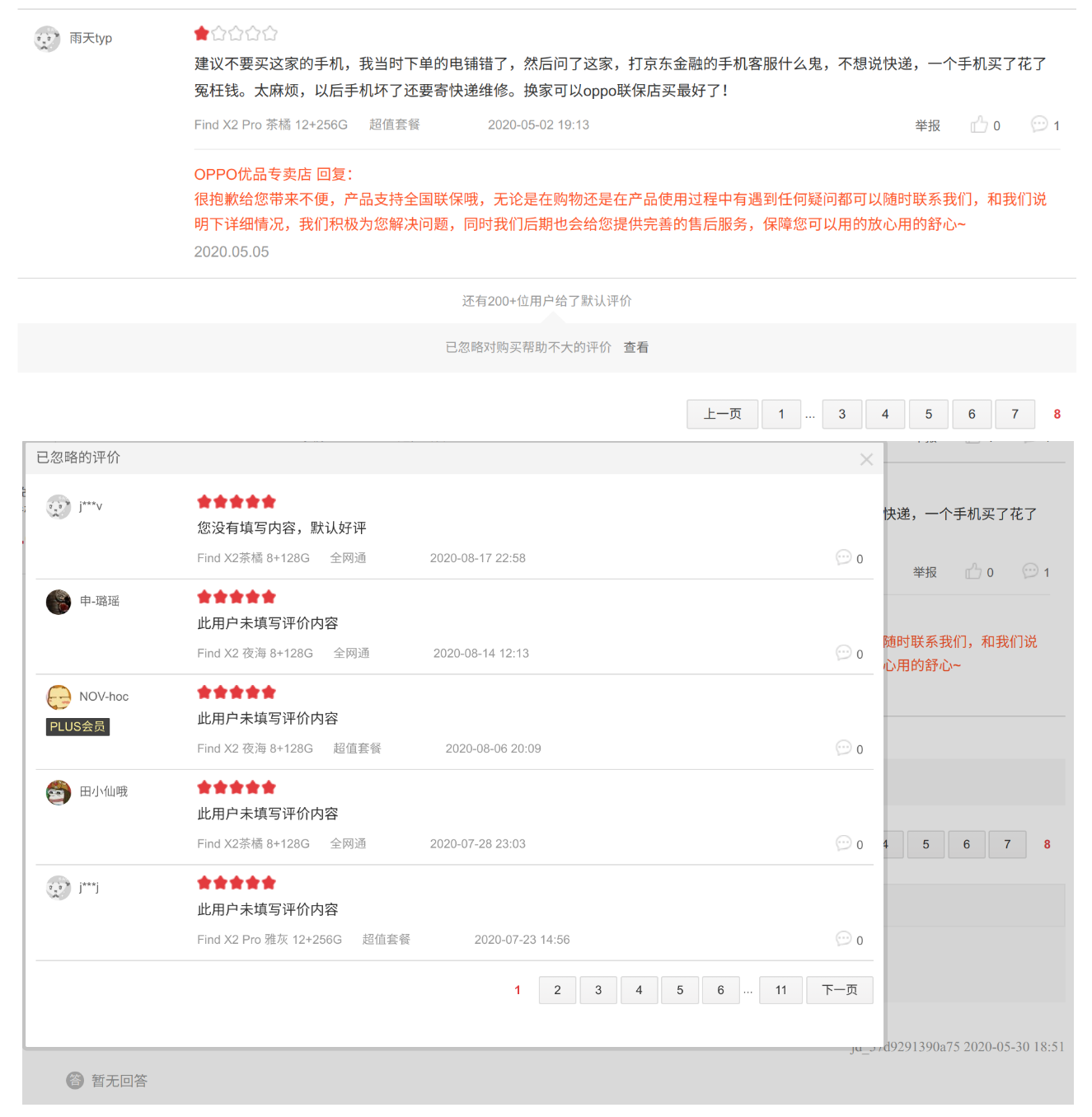
- 注意:如果进入查看忽略页,需要在弹出的忽略评论窗口进行‘下一页’的点击操作,这个大家可以自己去网站看看。
- 另外一个很重要的一点就是在报错‘网页超时’的处理方式,我在爬虫的时候遇到一个问题,就是京东的反爬虫引起的,有时候当我进入某个商品详情页后,点击进入评论区(存在评论),但是评论区会显示 暂无评价 ,即使我加大了点击评论区前的等待时间也没用,但是后面我刷新浏览器再进入评论区就有了,所以我在Timeout报错下采用了如下的解决方法:刷新页面 -> 重点击进入评论区 -> 等待30秒 -> 再爬虫 -> 还报错就继续重复以上步骤。
5. 翻页
def turn_JDpage(self):
# 移到页面末端并点击‘下一页’
try:
if self.ignore_page == False:
self.browser.find_element_by_xpath('//a[@class="ui-pager-next" and @clstag]').send_keys(Keys.ENTER)
else:
self.browser.find_element_by_xpath('//a[@class="ui-pager-next" and @href="#none"]').send_keys(Keys.ENTER)
time.sleep(3) # 点击完等3s
self.browser.execute_script("window.scrollTo(0, document.body.scrollHeight)")
time.sleep(5) # 下拉后等5s
# 如果找不到元素
except selenium.common.exceptions.NoSuchElementException:
if self.ignore_page == False:
try:
# 如果有忽略评论的页面但没进入,则进入继续翻页
self.browser.find_element_by_xpath('//div[@class="comment-more J-fold-comment hide"]/a').send_keys(Keys.ENTER)
self.ignore_page = True
print("有忽略评论的页面")
except:
# 如果没有忽略评论的页面且最后一页
print("没有忽略评论的页面")
self.ignore_page = True
self.isLastPage = True
else:
# 如果有忽略评论的页面且到了最后一页
print("没有忽略评论的页面")
self.isLastPage = True
except selenium.common.exceptions.TimeoutException:
print('turn_page: TimeoutException 网页超时')
time.sleep(30)
self.turn_JDpage()
# 如果因为JS刷新找不到元素,重新刷新
except selenium.common.exceptions.StaleElementReferenceException:
print('turn_page: StaleElementReferenceException 某元素因JS刷新已过时没出现在页面中')
self.turn_JDpage()
需要注意的是:
- 翻页要慢,太快容易被反爬虫,所以等待时间一定要增加。
- 当报错是 NoSuchElementException ,即找不到‘下一页’按钮,可能会三种情况:(1) 正常展示的评论页已到翻到页末了;(2) 忽略评论的页面已翻到页末了;(3) 京东反爬虫,不显示‘下一页’按钮给你点击。对于情况1,就是查看有没有忽略评论,如果有就点击查看并爬取它们,如果没有就结束当前商品的爬取。对于情况2,直接结束爬取。对于情况3,这个我是抱着‘给我反爬虫,那我就不爬这商品’的态度去做的,因为确实没有好的手段,但抱着‘不爬完不罢休’心态的朋友可以把这种爬虫失败的商品先记录下来,现阶段爬完再重爬它们也行。
6. 自动化爬取多页
def JDcrawl_detail(self, csv_path, search_key, user_agent):
# 初始化参数
self.init_variable(csv_path, search_key, user_agent)
unfinish_crawls = 0 # 记录因反爬虫而没有完全爬取的商品数
# 清洗数据
self.overview_df = self.clean_overview(self.csv_path, self.keyword) # 依次进入到单独的商品链接里去
for url in tqdm(list(self.overview_df['url'][3:])):
df_user_names = []
df_user_levels = []
df_user_stars = []
df_comments = []
df_create_times = []
df_order_infos = [] # 打开模拟浏览器
self.open_browser()
# 进入目标网站
self.browser.get(url)
time.sleep(35)
# 进入评论区
self.browser.find_element_by_xpath('//li[@data-tab="trigger" and @data-anchor="#comment"]').click()
time.sleep(15)
# 开始爬取
self.browser.execute_script("window.scrollTo(0, document.body.scrollHeight)")
self.isLastPage = False
self.ignore_page = False
self.lastpage = 0
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) + " 开启数据爬虫url:",url)
while self.isLastPage != True:
page_num = 0
user_names, user_levels, user_stars, comments, create_times, order_infos, page_num = self.parse_JDpage()
# 如果某页因为反爬虫无法定位到‘下一页’元素,导致重复爬取同一页,则保留之前的爬取内容,然后就不继续爬这个商品了
if self.lastpage != page_num:
self.lastpage = page_num
print("已爬取完第%s页" % page_num)
df_user_names.extend(user_names)
df_user_levels.extend(user_levels)
df_user_stars.extend(user_stars)
df_comments.extend(comments)
df_create_times.extend(create_times)
df_order_infos.extend(order_infos)
self.turn_JDpage()
else:
unfinish_crawls += 1
self.browser.quit()
break
# 退出浏览器
self.browser.quit() # 保存结果
results = pd.DataFrame({'user_names':df_user_names,
'user_levels':df_user_levels,
'user_stars':df_user_stars,
'omments':df_comments,
'create_times':df_create_times,
'order_infos':df_order_infos})
url_id = url.split('/')[-1].split('.')[0]
save_path = r'/media/alvinai/Documents/comment_crawler/JD_results/Detail/' + str(url_id) + '.csv'
results.to_csv(save_path, index = False)
print("爬虫结束,共%d条数据,结果保存至%s" % (len(results),save_path))
与列表页爬取不同在于,这里是爬完一个商品详情就保存它的结果文件,避免‘一损具损’的局面出现。另外等待时间也给多了(避免京东反爬虫)。
给大家展示下爬取界面:
我的部分爬取结果如下:


三、总结
1. 京东对列表页的爬虫的防守没有详情页严格,所以在对详情页的时候要增加等待时间并且增加一些针对反爬虫的操作。
2. 在我爬虫详情页的过程中,京东的反爬虫有以下两个体现:(1) 点击进入评论区后,不给我显示评论(解决办法:刷新浏览器重新进入评论区);(2) 评论区不给我显示‘下一页’按钮,这样我就没法定位并点击它实现翻页(暂无完美解决方法,减少这种情况发生的手段是增加进入评论区和爬去内容过程中强制等待的时间,后期可以考虑记录下这些网页并重新爬取)。
3. 在我上面的代码中,我增加了对忽略评论的爬取,原因是:尽管评论主体的文本内容没有价值,但是用户们的购买选择是具有价值的,通过这些购买选择,我们后面能进行用户对于机型、颜色、内存搭配、套餐选择的偏好分析。
4. 这是个人下班之余做的自我学习项目,与工作内容无关。
5. 我的代码落地性不强,原因是爬虫速度慢,这也为了考虑到是个人项目,如果要速度上去,不仅可能要考虑多线程,还有购买代理ip等操作,那样的话,就等于完全深入到爬虫里面了,我不是我的目的,因为我只想要它的数据。而且真要落地那种爬虫,代码再优雅而离不开行为的‘野蛮’,对爬虫平台造成大的服务器负担反而不好。从爬虫平台去考虑,他们要区分你是爬虫还是正常浏览,一个常见的思路就是你的浏览行为是否符合真实用户的浏览行为,这也是我为什么我的爬虫等待时间比较长,因为只要你不增加平台服务器负担,他们还是会‘让‘着点你的。
6. 这些数据有什么用?有用,比如说(1)如上面第3点所说,可以进行自身或竞品分析,从出售的机型版本、颜色、内存、套装选择、价格等进行统计性分析和对比; (2) 文本数据的观点抽取,标签生成,情感分析等,用以进行痛点和卖点的挖掘。这也是我接下来会想继续尝试的方向。
7. 完整代码已开源至:https://github.com/AlvinAi96/COI
使用Selenium爬取京东电商数据(以手机商品为例)的更多相关文章
- 利用selenium爬取京东商品信息存放到mongodb
利用selenium爬取京东商城的商品信息思路: 1.首先进入京东的搜索页面,分析搜索页面信息可以得到路由结构 2.根据页面信息可以看到京东在搜索页面使用了懒加载,所以为了解决这个问题,使用递归.等待 ...
- Scrapy实战篇(八)之Scrapy对接selenium爬取京东商城商品数据
本篇目标:我们以爬取京东商城商品数据为例,展示Scrapy框架对接selenium爬取京东商城商品数据. 背景: 京东商城页面为js动态加载页面,直接使用request请求,无法得到我们想要的商品数据 ...
- 爬虫系列(十三) 用selenium爬取京东商品
这篇文章,我们将通过 selenium 模拟用户使用浏览器的行为,爬取京东商品信息,还是先放上最终的效果图: 1.网页分析 (1)初步分析 原本博主打算写一个能够爬取所有商品信息的爬虫,可是在分析过程 ...
- selenium模块使用详解、打码平台使用、xpath使用、使用selenium爬取京东商品信息、scrapy框架介绍与安装
今日内容概要 selenium的使用 打码平台使用 xpath使用 爬取京东商品信息 scrapy 介绍和安装 内容详细 1.selenium模块的使用 # 之前咱们学requests,可以发送htt ...
- Scrapy实战篇(七)之Scrapy配合Selenium爬取京东商城信息(下)
之前我们使用了selenium加Firefox作为下载中间件来实现爬取京东的商品信息.但是在大规模的爬取的时候,Firefox消耗资源比较多,因此我们希望换一种资源消耗更小的方法来爬取相关的信息. 下 ...
- Scrapy实战篇(六)之Scrapy配合Selenium爬取京东信息(上)
在之前的一篇实战之中,我们已经爬取过京东商城的文胸数据,但是前面的那一篇其实是有一个缺陷的,不知道你看出来没有,下面就来详细的说明和解决这个缺陷. 我们在京东搜索页面输入关键字进行搜索的时候,页面的返 ...
- 爬虫(十七):Scrapy框架(四) 对接selenium爬取京东商品数据
1. Scrapy对接Selenium Scrapy抓取页面的方式和requests库类似,都是直接模拟HTTP请求,而Scrapy也不能抓取JavaScript动态谊染的页面.在前面的博客中抓取Ja ...
- python爬虫——用selenium爬取京东商品信息
1.先附上效果图(我偷懒只爬了4页) 2.京东的网址https://www.jd.com/ 3.我这里是不加载图片,加快爬取速度,也可以用Headless无弹窗模式 options = webdri ...
- 基于selenium爬取京东
爬取iphone 注意:browser对象会发生变化,当对当前网页做任意操作时 import time from selenium import webdriver from selenium.web ...
随机推荐
- 【Jenkins】active choices reactive parameter & Groovy Postbuild插件使用!
注:以上俩插件安装下载直接去jenkins官网或者百度下载即可 一.active choices reactive parameter 插件的使用 1.被关联的参数不做改动 2.添加active ch ...
- 洛谷 P4819 [中山市选]杀人游戏(tarjan缩点)
P4819 [中山市选]杀人游戏 思路分析 题意最开始理解错了(我太菜了) 把题意简化一下,就是找到可以确定杀手身份的最小的危险查看数 (就是不知道该村名的身份,查看他的身份具有危险的查看数量),用 ...
- day20 Pyhton学习 面向对象-类与类之间的关系
一.类与类之间的依赖关系 class Elphant: def __init__(self, name): self.name = name def open(self, ref): print(&q ...
- 【应用服务 App Service】在Azure App Service中使用WebSocket - PHP的问题 - 如何使用和调用
问题描述 在Azure App Service中,有对.Net,Java的WebSocket支持的示例代码,但是没有成功的PHP代码. 以下的步骤则是如何基于Azure App Service实现PH ...
- Linux文件系统和管理-2文件操作命令(上)
文件操作命令 文件 文件也包括目录 目录是一种特殊的文件 目录 一个目录名分成两部分 所在目录 dirname 父目录的路径 文件名 basename 本身就是两个命令 [root@C8-1 misc ...
- Compareto方法
很多时候我们写Compareto方法是用于排序,那么排序就涉及到数据位置交换. 所以要注意compareto返回值的含义,通过一个例子来看一下: 假设对象的num属性作为比较标准,对象为testVO ...
- origin添加两个Y轴
1. 选中X和两个Y 2. 点击Double Y 3. 关掉gap to Symbol,否则Line+Symbol这种显示方式可能显示不出线条
- F2. Same Sum Blocks (Hard) 解析(思維、前綴和、貪心)
Codeforce 1141 F2. Same Sum Blocks (Hard) 解析(思維.前綴和.貪心) 今天我們來看看CF1141F2(Hard) 題目連結 題目 給你一個數列\(a\),要你 ...
- 云计算管理平台之OpenStack计算服务nova
一.nova简介 nova是openstack中的计算服务,其主要作用是帮助我们在计算节点上管理虚拟机的核心服务:这里的计算节点就是指用于提供运行虚拟机实例的主机,通常像这种计算节点有很多台,那么虚拟 ...
- Python爬虫之多线程
详情点我跳转 关注公众号"轻松学编程"了解更多. 多线程 在介绍Python中的线程之前,先明确一个问题,Python中的多线程是假的多线程! 为什么这么说,我们先明确一个概念,全 ...