Kaggle-pandas(6)
Renaming-and-combining
教程
通常,数据会以列名,索引名或我们不满意的其他命名约定提供给我们。 在这种情况下,您将学习如何使用pandas函数将有问题的条目的名称更改为更好的名称。
Renaming
我们将在这里介绍的第一个函数是rename(),它使您可以更改索引名和/或列名。 例如,要将数据集中的点列更改为得分,我们可以
- reviews.rename(columns={'points': 'score'})
通过rename(),可以分别通过指定索引或列关键字参数来重命名索引或列值。 它支持多种输入格式,但是通常最方便的是Python字典。 这是一个使用它重命名索引的某些元素的示例。
- reviews.rename(index={0: 'firstEntry', 1: 'secondEntry'})
您可能会经常重命名列,但是很少重命名索引值。 为此,通常使用set_index()更方便。
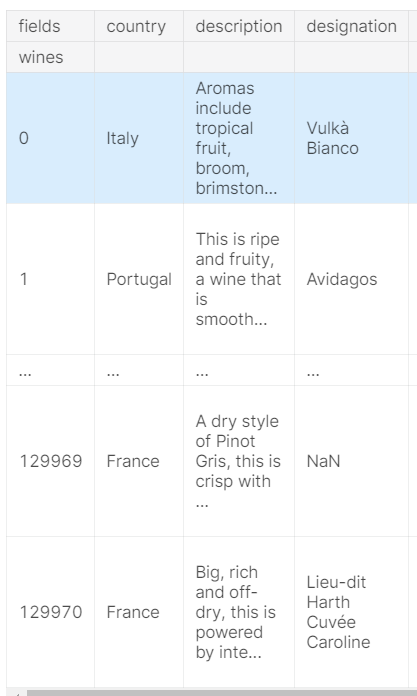
行索引和列索引都可以具有自己的名称属性。 互补的rename_axis()方法可用于更改这些名称。 例如:
- reviews.rename_axis("wines", axis='rows').rename_axis("fields", axis='columns')
原来的表:
现在的表:
Combining
在数据集上执行操作时,有时我们需要以不平常的方式组合不同的DataFrame和/或Series。 pandas有三种核心方法可以做到这一点。 按照从简单到复杂的顺序,分别是concat(),join()和merge()。 merge()可以执行的大多数操作也可以通过join()来更简单地完成,因此我们将省略它,而只关注前两个函数。
最简单的组合方法是concat()。 给定一个元素列表,此函数会将这些元素沿轴拖在一起。
当我们在不同的DataFrame或Series对象中具有数据但具有相同的字段(列)时,这很有用。 一个示例:YouTube视频数据集,该数据集可根据来源国家/地区(例如本例中的加拿大和英国)对数据进行拆分。 如果我们想同时研究多个国家,可以使用concat()将它们混在一起:
- canadian_youtube = pd.read_csv("../input/youtube-new/CAvideos.csv")
- british_youtube = pd.read_csv("../input/youtube-new/GBvideos.csv")
- pd.concat([canadian_youtube, british_youtube])
相当于两个表拼接到了一起。
就复杂性而言,最中间的组合器是join()。 join()使您可以组合具有共同索引的不同DataFrame对象。 例如,要提取加拿大和英国在同一天流行的视频,我们可以执行以下操作:
- left = canadian_youtube.set_index(['title', 'trending_date'])
- right = british_youtube.set_index(['title', 'trending_date'])
- left.join(right, lsuffix='_CAN', rsuffix='_UK')
这里必须使用lsuffix和rsuffix参数,因为在英国和加拿大数据集中,数据具有相同的列名。 如果这不是真的(例如,因为我们事先将其重命名),则不需要它们。
join就是数据库之中的连接操作,主键与外键需要一样。
练习
1.
region_1 and region_2 are pretty uninformative names for locale columns in the dataset. Create a copy of reviews with these columns renamed to region and locale, respectively.
- # Your code here
- renamed = reviews.rename(columns={'region_1': 'region','region_2':'locale'})
- # Check your answer
- q1.check()
2.
Set the index name in the dataset to wines.
- reindexed = reviews.rename_axis("wines", axis='rows')
- print(reindexed)
- # Check your answer
- q2.check()
3.
The Things on Reddit dataset includes product links from a selection of top-ranked forums ("subreddits") on reddit.com. Run the cell below to load a dataframe of products mentioned on the /r/gaming subreddit and another dataframe for products mentioned on the r//movies subreddit.
- gaming_products = pd.read_csv("../input/things-on-reddit/top-things/top-things/reddits/g/gaming.csv")
- gaming_products['subreddit'] = "r/gaming"
- movie_products = pd.read_csv("../input/things-on-reddit/top-things/top-things/reddits/m/movies.csv")
- movie_products['subreddit'] = "r/movies"
Create a DataFrame of products mentioned on either subreddit.
- combined_products = pd.concat([gaming_products, movie_products])
- # Check your answer
- q3.check()
4.
The Powerlifting Database dataset on Kaggle includes one CSV table for powerlifting meets and a separate one for powerlifting competitors. Run the cell below to load these datasets into dataframes:
- powerlifting_meets = pd.read_csv("../input/powerlifting-database/meets.csv")
- powerlifting_competitors = pd.read_csv("../input/powerlifting-database/openpowerlifting.csv")
Both tables include references to a MeetID, a unique key for each meet (competition) included in the database. Using this, generate a dataset combining the two tables into one.
- powerlifting_combined = powerlifting_meets.set_index("MeetID").join(powerlifting_competitors.set_index("MeetID"))
- # Check your answer
- q4.check()
Kaggle-pandas(6)的更多相关文章
- 由Kaggle竞赛wiki文章流量预测引发的pandas内存优化过程分享
pandas内存优化分享 缘由 最近在做Kaggle上的wiki文章流量预测项目,这里由于个人电脑配置问题,我一直都是用的Kaggle的kernel,但是我们知道kernel的内存限制是16G,如下: ...
- kaggle入门2——改进特征
1:改进我们的特征 在上一个任务中,我们完成了我们在Kaggle上一个机器学习比赛的第一个比赛提交泰坦尼克号:灾难中的机器学习. 可是我们提交的分数并不是非常高.有三种主要的方法可以让我们能够提高他: ...
- Kaggle入门教程
此为中文翻译版 1:竞赛 我们将学习如何为Kaggle竞赛生成一个提交答案(submisson).Kaggle是一个你通过完成算法和全世界机器学习从业者进行竞赛的网站.如果你的算法精度是给出数据集中最 ...
- 如何使用Python在Kaggle竞赛中成为Top15
如何使用Python在Kaggle竞赛中成为Top15 Kaggle比赛是一个学习数据科学和投资时间的非常的方式,我自己通过Kaggle学习到了很多数据科学的概念和思想,在我学习编程之后的几个月就开始 ...
- kaggle数据挖掘竞赛初步--Titanic<原始数据分析&缺失值处理>
Titanic是kaggle上的一道just for fun的题,没有奖金,但是数据整洁,拿来练手最好不过啦. 这道题给的数据是泰坦尼克号上的乘客的信息,预测乘客是否幸存.这是个二元分类的机器学习问题 ...
- kaggle& titanic代码
这两天报名参加了阿里天池的’公交线路客流预测‘赛,就顺便先把以前看的kaggle的titanic的训练赛代码在熟悉下数据的一些处理.题目根据titanic乘客的信息来预测乘客的生还情况.给了titan ...
- 初窥Kaggle竞赛
初窥Kaggle竞赛 原文地址: https://www.dataquest.io/mission/74/getting-started-with-kaggle 1: Kaggle竞赛 我们接下来将要 ...
- 逻辑回归应用之Kaggle泰坦尼克之灾(转)
正文:14pt 代码:15px 1 初探数据 先看看我们的数据,长什么样吧.在Data下我们train.csv和test.csv两个文件,分别存着官方给的训练和测试数据. import pandas ...
- kaggle之Grupo Bimbo Inventory Demand
Grupo Bimbo Inventory Demand kaggle比赛解决方案集合 Grupo Bimbo Inventory Demand 在这个比赛中,我们需要预测某个产品在某个销售点每周的需 ...
- kaggle之人脸特征识别
Facial_Keypoints_Detection github code facial-keypoints-detection, 这是一个人脸识别任务,任务是识别人脸图片中的眼睛.鼻子.嘴的位置. ...
随机推荐
- 数据可视化之powerBI技巧(十四)采悟:PowerBI中自制中文单位万和亿
使用PowerBI的时候,一个很不爽之处就是数据单位的设置,只能用千.百万等英美的习惯来显示,而没有我们中文所习惯的万亿等单位,虽然要求添加"万"的呼声很高,但迟迟未见到改进动作, ...
- POJ 1047 Round and Round We Go 最详细的解题报告
题目链接:Round and Round We Go 解题思路:用程序实现一个乘法功能,将给定的字符串依次做旋转,然后进行比较.由于题目比较简单,所以不做过多的详解. 具体算法(java版,可以直接A ...
- Quartz.Net系列(十五):Quartz.Net四种修改配置的方式
案例:修改默认线程个数 1.NameValueCollection System.Collections.Specialized.NameValueCollection collection = ne ...
- Lua-源码-字符串的resize函数-luaS_resize
// 这里需要问一下:upval和一般的对象有什么区别?为什么要单独一个函数来处理? void luaC_linkupval (lua_State *L, UpVal *uv) { global_St ...
- 一张PDF了解JDK10 GC调优秘籍-附PDF下载
目录 简介 Java参数类型 Large Pages JIT调优 总结 简介 今天我们讲讲JDK10中的JVM GC调优参数,JDK10中JVM的参数总共有1957个,其中正式的参数有658个. 其实 ...
- day8 python 列表,元组,集合,字典的操作及方法 和 深浅拷贝
2.2 list的方法 # 增 list.append() # 追加 list.insert() # 指定索引前增加 list.extend() # 迭代追加(可迭代对象,打散追加) # 删 list ...
- [CISCN2019 华东南赛区]Double Secret
0x01 进入页面如下 提示我们寻找secret,再加上题目的提示,猜测这里有secret页面,我们尝试访问,结果如下 根据它这个话的意思,是让我们传参,然后它会给你加密,我们试一下 发现输入的1变成 ...
- CUDA中关于C++特性的限制
CUDA中关于C++特性的限制 CUDA官方文档中对C++语言的支持和限制,懒得每次看英文文档,自己尝试翻译一下(没有放lambda表达式的相关内容,太过于复杂,我选择不用).官方文档https:// ...
- maven&nexus_repository 私库搭建与使用
一.nexus仓库安装 1,http://www.sonatype.org/nexus/ 下载sso版本,免费2,tar -zxvf nexus-2.11.1-01-bundle.tar.gz3 ...
- cmd : 代理设置/检验代理设置成功
设置代理很简单,一句话的事儿. set HTTP_PROXY=http://user:password@proxy.domain.com:port 比如说,我用ssr,默认地址是127.0.0.1:1 ...