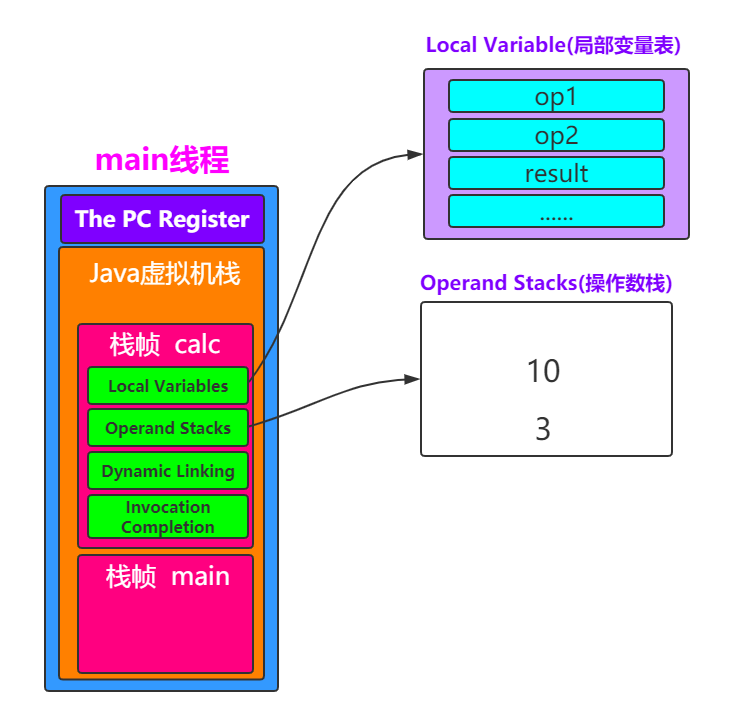
JVM进行篇

class Person{
private String name="Jack";
private int age;
private final double salary=100;
private static String address;
private final static String hobby="Programming";
public void say(){
System.out.println("person say...");
}
public static int calc(int op1,int op2){
op1=3; int result=op1+op2; return result;
}
public static void order(){ }
public static void main(String[] args){
calc(1,2); order();
}
}

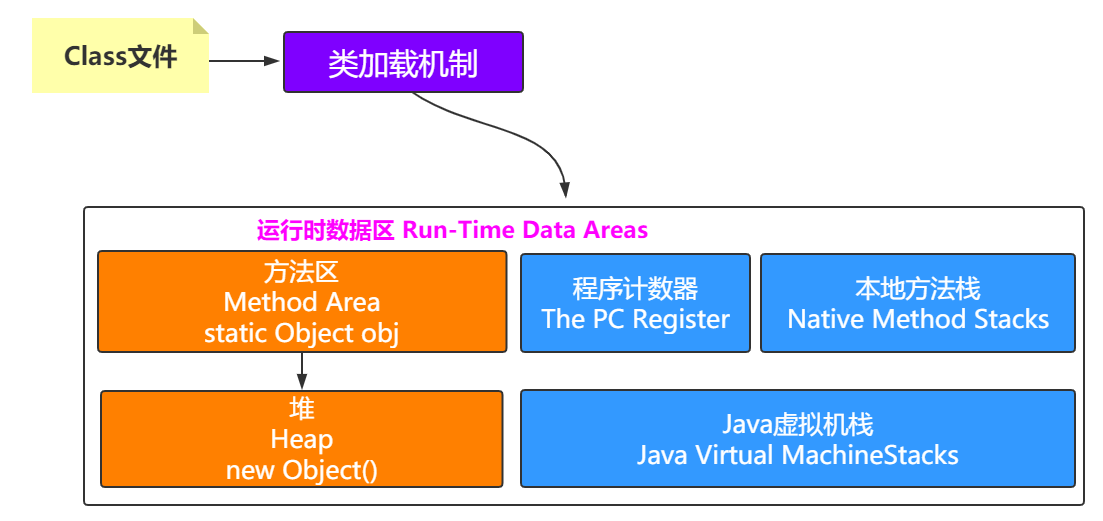
方法区指向堆
方法区会存放静态变量,常量等数据,如果下面的这种情况,就是典型的方法区中元素执行堆中的对象
private static Object obj=new Object();
堆指向方法区
方法区会包含类的信息,堆中会有对象,那怎么知道对象是哪个类创建的呢?
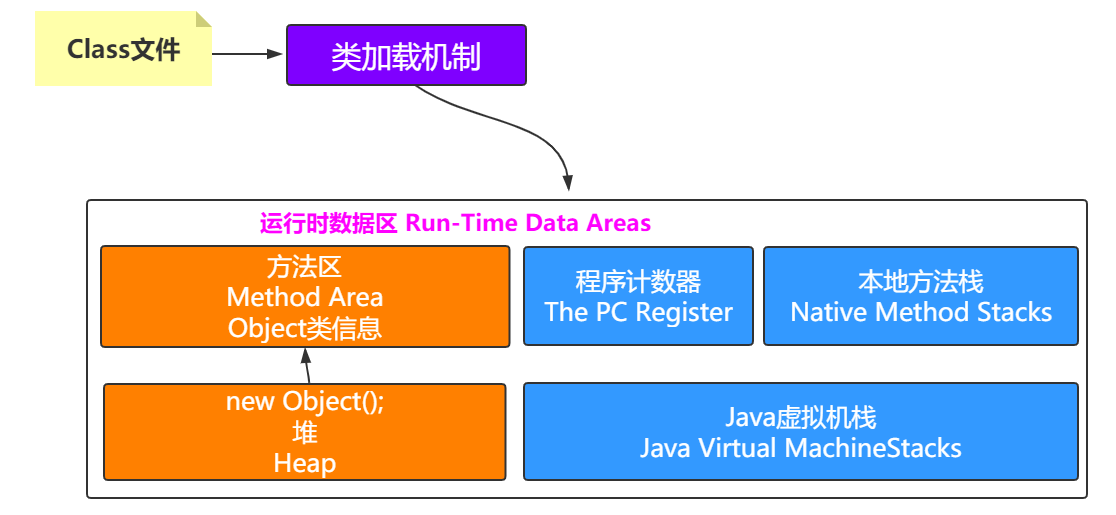
思考:一个对象怎么知道它是由哪个类创建出来的呢? 怎么记录呢? 这就需要了解一个Java对象的具体信息了
Java对象内存布局
一个对象在内存中包括3个部分: 对象头,实例数据和对齐填充

内存模型:
一块是非堆区,一块是堆区。
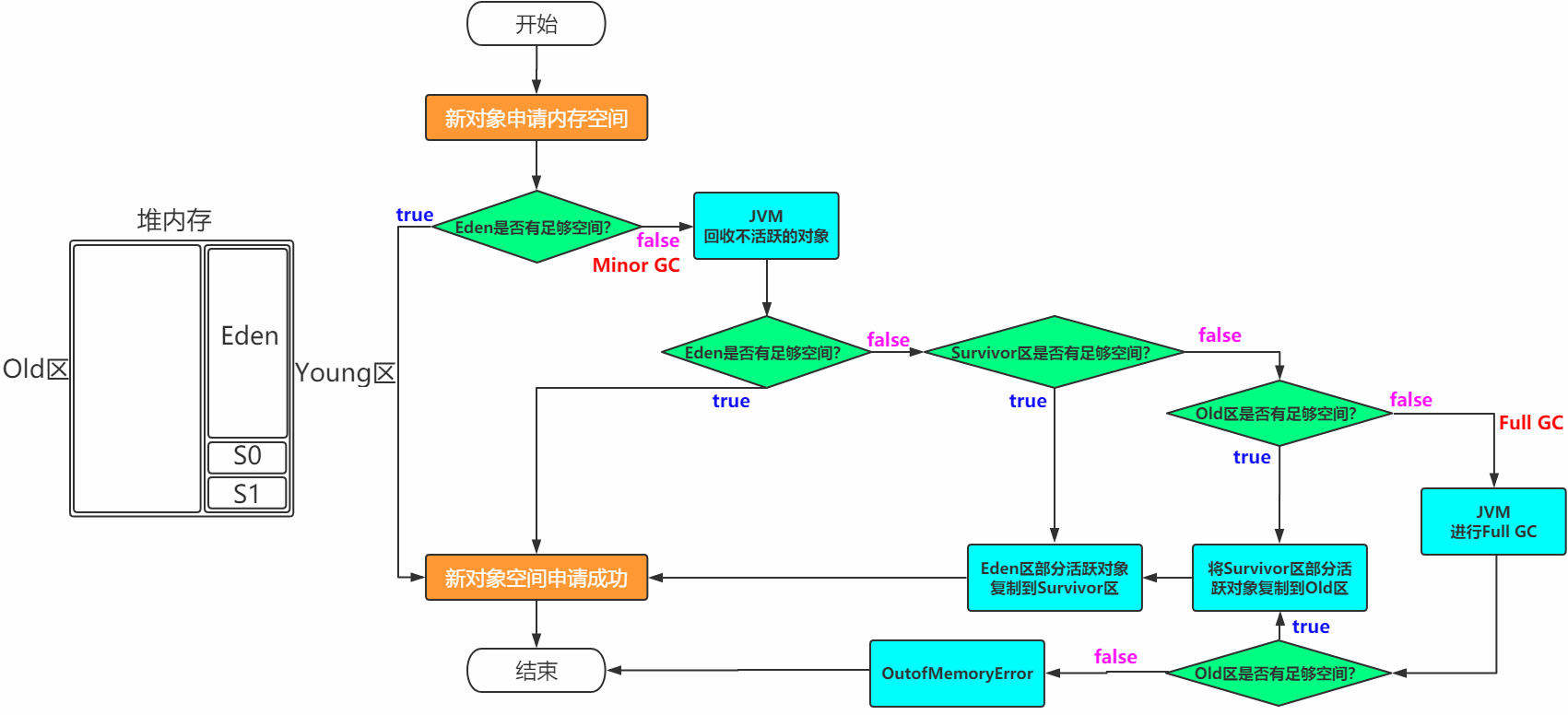
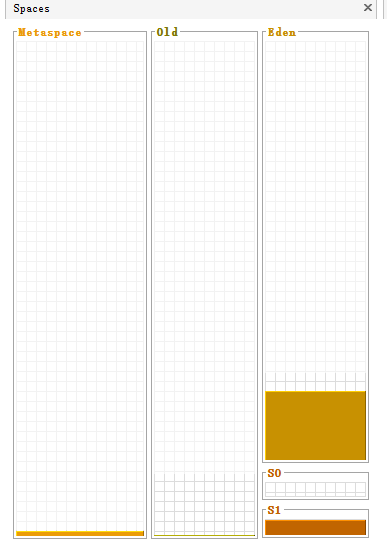
堆区分为两大块:一个是old区,一个是Young区,
Young区分为两个大块,一个是Survivor区(s0+s1),一块是Eden区,Eden:s0:s1=8:1:1
s0和s1一样大,也可以叫From和to
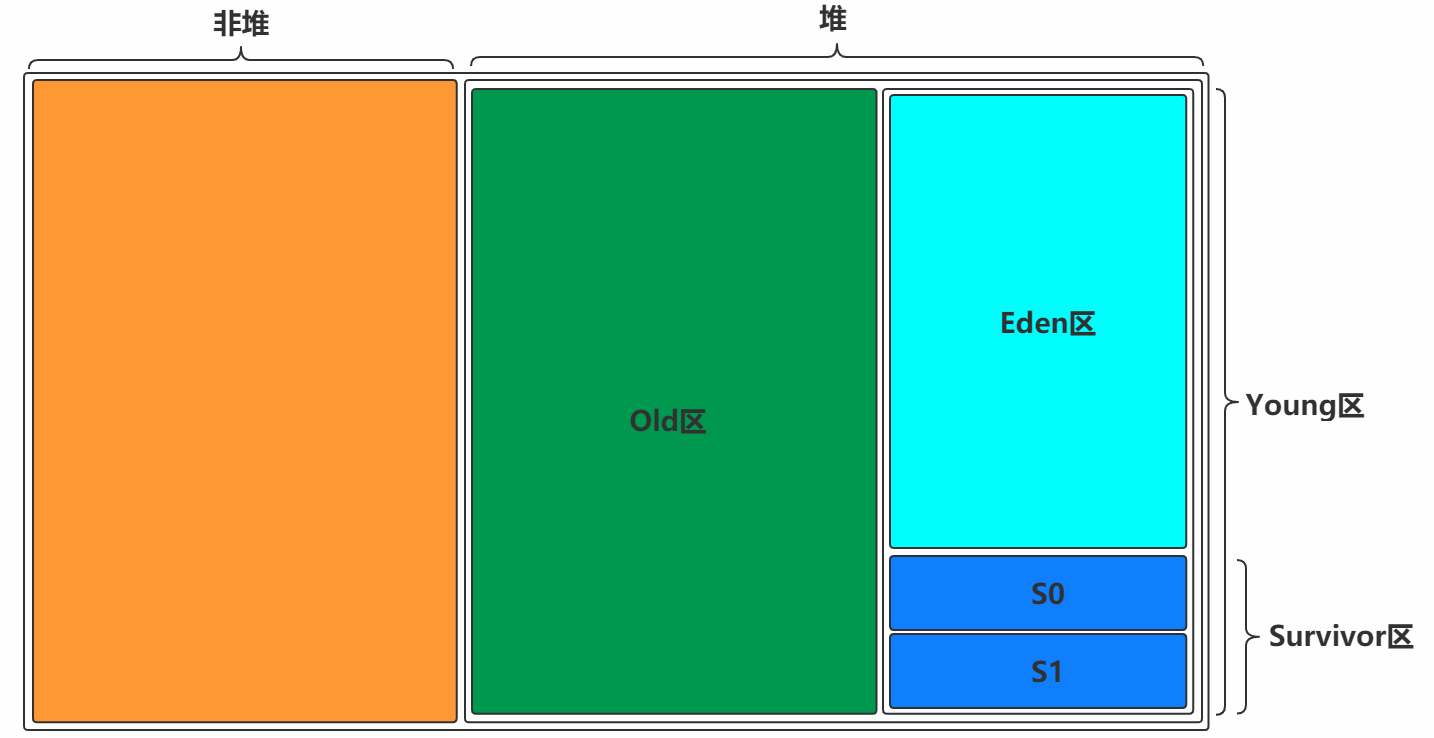
根据之前的对于Heap的介绍可以知道,一般对象和数组的创建会在堆中分配内存空间,关键是堆中有那么多区域,那一个对象的创建到底在哪个区域呢?
对象创建所在的区域
一般情况下,新创建的对象都会分配到Eden区,一些特殊的大的对象会直接分配到old区
比如 有对象A,B,C等创建Eden区,但是Eden区的内存空间肯定有限,比如有100M,假如已经使用了100M 或者到达一个设定的临界值,这时候就需要对Eden内存空间进行清理,即垃圾收集,这样的GC我们称之为Minor GC ,Minor GC指得是Young区的GC
经过GC之后,有些对象就会被清理掉,有些对象可能还在存活着,对于存活的对象需要将其复制到Survivor区,然后再清空Eden区中的这些对象
1) 堆内存溢出
@RestController
public class HeapController {
List<Person> list=new ArrayList<Person>();
@GetMapping("/heap")
public String heap() throws Exception{
while(true){
list.add(new Person());
Thread.sleep(1);
}
}
}
public class MyMetaspace extends ClassLoader {
public static List<Class<?>> createClasses() {
List<Class<?>> classes = new ArrayList<Class<?>>();
for (int i = 0; i < 10000000; ++i) {
ClassWriter cw = new ClassWriter(0);
cw.visit(Opcodes.V1_1, Opcodes.ACC_PUBLIC, "Class" + i, null, "java/lang/Object", null);
MethodVisitor mw = cw.visitMethod(Opcodes.ACC_PUBLIC, "<init>", "()V", null, null);
mw.visitVarInsn(Opcodes.ALOAD, 0);
mw.visitMethodInsn(Opcodes.INVOKESPECIAL, "java/lang/Object", "<init>", "()V");
mw.visitInsn(Opcodes.RETURN);
mw.visitMaxs(1, 1);
mw.visitEnd();
Metaspace test = new Metaspace();
byte[] code = cw.toByteArray();
Class<?> exampleClass = test.defineClass("Class" + i, code, 0, code.length);
classes.add(exampleClass);
}
return classes;
}
}
@RestController public class NonHeapController {
List<Class<?>> list=new ArrayList<Class<?>>();
@GetMapping("/nonheap") public String nonheap() throws Exception{
while(true){
list.addAll(MyMetaspace.createClasses());
Thread.sleep(5); } } }
public class StackDemo {
public static long count=0;
public static void method(long i){
System.out.println(count++);
method(i); }
public static void main(String[] args) { method(1); } }

理解和说明:
JVM进行篇的更多相关文章
- 初步了解JVM第二篇
在一篇<初步了解JVM第一篇>中,我们已经了解了: 类加载器:负责加载*.class文件,将字节码内容加载到内存中.其中类加载器的类型有如下: 启动类加载器(Bootstrap) 扩展类加 ...
- JVM学习篇-第一篇
JVM学习篇-第一篇 JDK( Java Development Kit): Java程序设计语言.Java虚拟机.Java类库三部分统称为JDK,JDK是用于支持Java程序开发的最小环境** ...
- JVM执行篇:使用HSDIS插件分析JVM代码执行细节--转
http://www.kuqin.com/java/20111031/314144.html 在<Java虚拟机规范>之中,详细描述了虚拟机指令集中每条指令的执行过程.执行前后对操作数栈. ...
- JVM前奏篇(大局观)
话不多说直接上干货,先来看oracle官网中是怎么描述JDK的:https://docs.oracle.com/javase/8/docs/index.html 这是官网中JDK.JRE.JVM的一个 ...
- 初步了解JVM第一篇
大家都知道,Java中JVM的重要性,学习了JVM你对Java的运行机制.编译过程和如何对Java程序进行调优相信都会有一个很好的认知. 废话不多说,直接带大家来初步认识一下JVM. 什么是JVM? ...
- 1.JVM前奏篇(看官网怎么说)
JVM(Java Virtual Machine) 前奏篇(看官网规范怎么说) 1.The relation of JDK/JRE/JVM 在下图中,我们所接触的,最熟悉,也是经常打交道的 最顶层 J ...
- JVM 第二篇:垃圾收集器以及算法
本文内容过于硬核,建议有 Java 相关经验人士阅读. 0. 引言 一说到 JVM ,大多数人第一个想到的可能就是 GC ,今天我们就来聊一聊和 GC 关系最大的垃圾收集器以及垃圾收集算法,希望能通过 ...
- 【JVM第二篇--类加载机制】类加载器与双亲委派模型
写在前面的话:本文是在观看尚硅谷JVM教程后,整理的学习笔记.其观看地址如下:尚硅谷2020最新版宋红康JVM教程 一.什么是类加载器 在类加载过程中,加载阶段有一个动作是"通过一个类的全限 ...
- 深入理解JAVA虚拟机之JVM性能篇---垃圾回收
一.基本垃圾回收算法 1. 判断对象是否需要回收的方法(如何判断垃圾): 1) 引用计数(Reference Counting) 对象增加一个引用,即增加一个计数,删除一个引用则减少一个计数.垃圾回 ...
- JVM基础篇(一)
JVM简介 JVM(Java虚拟机)是一个虚拟的机器,在实际的计算机上通过软件模拟来实现.JVM有自己的硬件,如处理器.堆栈.寄存器等,还具有相应的指令系统. JVM包括一套字节码指令集.一组寄存器. ...
随机推荐
- java 面向对象(十四):面向对象的特征二:继承性 (三) 关键字:super以及子类对象实例化全过程
关键字:super 1.super 关键字可以理解为:父类的2.可以用来调用的结构:属性.方法.构造器3.super调用属性.方法:3.1 我们可以在子类的方法或构造器中.通过使用"supe ...
- EM算法的收敛性
https://blog.csdn.net/kevinoop/article/details/80522477
- 前端08 /jQuery标签操作、事件
前端08 /jQuery标签操作.事件 目录 前端08 /jQuery标签操作.事件 1.标签内文本操作 1.1 html标签元素中的所有内容 1.2 text 标签元素的文本内容 2.文档标签操作 ...
- typeError:The value of a feed cannot be a tf.Tensor object.Acceptable feed values include Python scalars,strings,lists.numpy ndarrays,or TensorHandles.For reference.the tensor object was Tensor...
如上贴出了:错误信息和错误代码. 这个问题困扰了自己两天,报错大概是说输入的数据和接受的格式不一样,不能作为tensor. 后来问了大神,原因出在tf.reshape(),因为网络训练时用placeh ...
- TCP 和 UDP,哪个更胜一筹
作为 TCP/IP 中两个最具有代表性的传输层协议,TCP 和 UDP 经常被拿出来相互比较.这些协议具体有什么区别,又是什么作用呢? 在 IT 圈混迹多年的小伙伴们,对 TCP 和 UDP 肯定再熟 ...
- C++ 线性筛素数
今天要写一篇亲民的博客了,尽力帮助一下那些不会线性筛素数或者突然忘记线性筛素数的大佬. 众所周知,一个素数的倍数肯定不是素数(废话).所以我们可以找到一个方法,普通的筛法(其实不算筛,普通的是判断一个 ...
- Newbe.Claptrap 框架入门,第二步 —— 简单业务,清空购物车
接上一篇 Newbe.Claptrap 框架入门,第一步 —— 创建项目,实现简易购物车 ,我们继续要了解一下如何使用 Newbe.Claptrap 框架开发业务.通过本篇阅读,您便可以开始尝试使用 ...
- Linux文件搜索
一.whereis及which命令 这两个命令用来搜索命令的路径(也遵循/etc/updatedb.conf配置文件的筛选规则) whereis 命令名 ...
- Java集合框架1-- HashMap
HashMap的知识点可以说在面试中经常被问到,是Java中比较常见的一种数据结构.所以这一篇就通过源码来深入理解下HashMap. 1 HashMap的底层是如何实现的?(基于JDK8) 1.1 H ...
- 回文树(回文自动机)(PAM)
第一个能看懂的论文:国家集训队2017论文集 这是我第一个自己理解的自动机(AC自动机不懂KMP硬背,SAM看不懂一堆引理定理硬背) 参考文献:2017国家集训队论文集 回文树及其应用 翁文涛 参考博 ...