scrapy爬取微信小程序社区教程(crawlspider)
爬取的目标网站是:
http://www.wxapp-union.com/portal.php?mod=list&catid=2&page=1
目的是爬取每一个教程的标题,作者,时间和详细内容
通过下面的命令可以快速创建 CrawlSpider模板 的代码:
scrapy genspider wsapp wxapp-union.com
CrawlSpider是Spider的派生类,Spider类的设计原则是只爬取start_url列表中的网页,而CrawlSpider类定义了一些规则(rule)来提供跟进link的方便的机制,从爬取的网页中获取link并继续爬取的工作更适合。
在之前爬取免费代理的爬虫里面,我们没有使用crawlspider,当我们想要爬取下一页的时候,采用的是xpath解析response,找到下一页的链接,然后再次请求

但是这样的弊端在于难以灵活爬取网站,因此这里我们使用crawlspider来让爬取任务更简单。
CrawlSpider继承自Spider, 爬取网站常用的爬虫,其定义了一些规则(rule)方便追踪或者是过滤link。 也许该spider并不完全适合您的特定网站或项目,但其对很多情况都是适用的。 因此您可以以此为基础,修改其中的方法,当然您也可以实现自己的spider。
除了从Spider继承过来的(您必须提供的)属性外,其提供了一个新的属性:
- rules
一个包含一个(或多个) Rule 对象的集合(list)。 每个 Rule 对爬取网站的动作定义了特定表现。 Rule对象在下边会介绍。 如果多个rule匹配了相同的链接,则根据他们在本属性中被定义的顺序,第一个会被使用。
该spider也提供了一个可复写(overrideable)的方法:
- parse_start_url(response)
当start_url的请求返回时,该方法被调用。 该方法分析最初的返回值并必须返回一个 Item 对象或者 一个 Request 对象或者 一个可迭代的包含二者对象。
这里我们使用rules设置规则爬取我们需要的链接。
因为我们需要爬取教程,点击下一页之后发现网页链接的变化是page,即第一页到第二页的变化是page=1变成了page=2
/portal.php?mod=list&catid=2&page=1
如果有爬虫经验的话这里应该很容易理解
可以知道页数链接是在类似于list&catid=2&page=x这种格式的链接里面
接着我们查看每一页里面的每一篇文章的链接,比如:
http://www.wxapp-union.com/article-5798-1.html
可知教程的详情是在类似于article-xxx.html这种格式的链接里面
所以我们可以在rules里面编写这两条规则
rules = (
Rule(LinkExtractor(allow=r'.+list&catid=2&page=\d+'), follow=True),
Rule(LinkExtractor(allow=r'.+article-.+\.html'), callback='parse_detail', follow=False),
)
我们需要使用LinkExtractor和Rule这两个东西来决定爬虫的具体走向
需要注意的是:
1,allow设置规则的方法:要能够限制在我们想要的url上面,不是和其他url产生相同的正则表达式即可
在我们这里设置的rules里面,使用 .+来匹配任意字符,\d+来匹配page后面的数字
2,什么情况下使用follow:如果在爬取页面的时候,需要将满足当前条件的url在进行跟进,那么就设置为Ture,否则设置为False
在我们的这个例子里面,对于这个界面,我们选择了跟进:
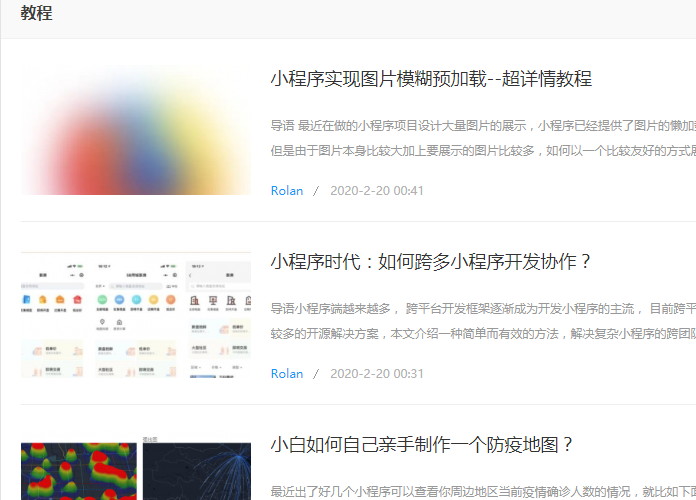
因为我们在这个页面里再爬取教程的详情页面,所以需要跟进
而在这个页面我们没有跟进:
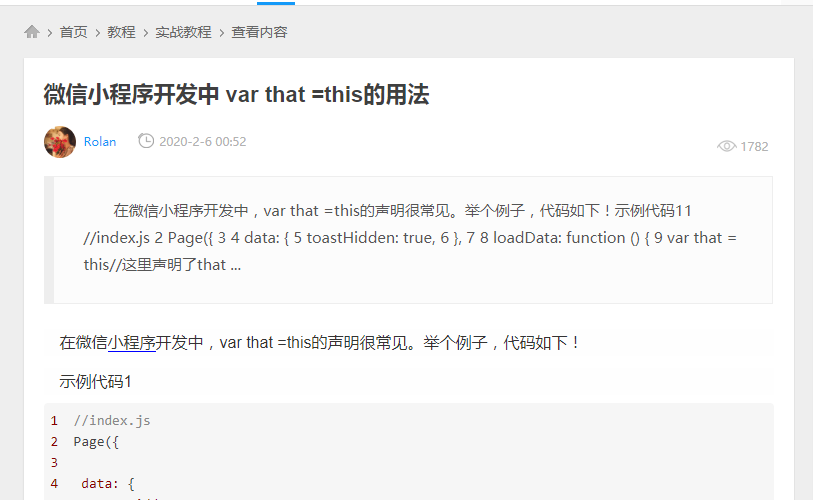
因为我们到了这个页面并且获取了教程详细信息之后,这个页面对于我们来说就已经无用了,虽然在这个页面的旁边可能还有其他的教程详情链接等待我们去点击,但是这些详情链接我们会在其他的地方爬取到的,虽然scrapy里面自动会去重,但我们为了省事,得到我们需要的东西之后就终止爬虫对于这个页面的探索,这样爬虫脉络更清晰一点
3,什么情况下该指定callback:如果这个url对应的页面,只是为了获取更多的url,并不需要里面的数据,那么可以不指定callback,如果想要获取url对应页面中的数据,那么就需要指定一个callback
callback里面的函数是我们对于页面进行详细解析的回调函数。我们需要对详细教程页的教程内容进行分析,所以需要callback,而在portal.php?mod=list&catid=2&page=1这一类页面里,我们仅仅是想要获取更多的详细教程的链接,也不需要更多的处理,所以不使用callback
除了这些之外,其他的地方跟原来的spider大致相同,爬取到的详细内容保存在了json文件里面

代码放在了github上面,欢迎Star
https://github.com/Cl0udG0d/scrapy_demo
参考链接:
https://geek-docs.com/scrapy/scrapy-tutorials/scrapy-crawlspider.html
https://www.kancloud.cn/ju7ran/scrapy/1364596
https://www.cnblogs.com/derek1184405959/p/8451798.html
https://www.bilibili.com/video/av57909837?p=8
scrapy爬取微信小程序社区教程(crawlspider)的更多相关文章
- python爬取微信小程序(实战篇)
python爬取微信小程序(实战篇) 本文链接:https://blog.csdn.net/HeyShHeyou/article/details/90452656 展开 一.背景介绍 近期有需求需要抓 ...
- Python爬取微信小程序(Charles)
Python爬取微信小程序(Charles) 本文链接:https://blog.csdn.net/HeyShHeyou/article/details/90045204 一.前言 最近需要获取微信小 ...
- 爬虫_微信小程序社区教程(crawlspider)
照着敲了一遍,,, 需要使用"LinkExtrator"和"Rule",这两个东西决定爬虫的走向. 1.allow设置规则的方法:要能够限制在我们想要的url上 ...
- scarpy crawl 爬取微信小程序文章(将数据通过异步的方式保存的数据库中)
import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider ...
- scarpy crawl 爬取微信小程序文章
import scrapy from scrapy.linkextractors import LinkExtractor from scrapy.spiders import CrawlSpider ...
- 微信小程序实例教程(一)
序言 开始开发应用号之前,先看看官方公布的「小程序」教程吧!(以下内容来自微信官方公布的「小程序」开发指南) 本文档将带你一步步创建完成一个微信小程序,并可以在手机上体验该小程序的实际效果.这个小程序 ...
- 微信小程序实例教程(四)
第八章:微信小程序分组开发与左滑功能实现 先来看看今天的整体思路: 进入分组管理页面 --> 点击新建分组新建 进入到未分组页面基本操作 进入到已建分组里面底部菜单栏操作 --> 从名 ...
- 微信小程序实例教程(三)
第七章:微信小程序编辑名片页面开发 编辑名片有两条路径,分为新增名片流程与修改名片流程. 用户手填新增名片流程: 首先跳转到我们的新增名片页面 1 需要传递用户的当前 userId,wx.na ...
- 微信小程序实例教程(二)
第五章:微信小程序名片夹详情页开发 今天加了新干货!除了开发日志本身,还回答了一些朋友的问题. 闲话不多说,先看下「名片盒」详情页的效果图: 备注下大致需求:顶部背后是轮播图,二维码按钮弹出模态框信息 ...
随机推荐
- sqlserver with(NOLOCK) 或 with(READPAST)
https://blog.csdn.net/shuicaohui5/article/details/6758868
- Java—多线程
一.多线程 原理: 一个cpu内核有"一个指针",由于cpu的频率过高,所以感觉不到卡顿.(伪线程) 二.进程&线程 进程:进程指正在运行的程序.确切的来说,当一个程序进入 ...
- intelx86为何从0xFFFF0处执行
第一条指令的地址 在用户按下计算机电源开关之后,CPU会自动的将其CS寄存器设定为0xFFFF,将其IP寄存器设定为0x0000.由于CS:IP指出了下一条指令的地址[1],因此CPU会跳到0xFFF ...
- JsonPath在接口自动化中的应用
我理解jsonpath于json而言,就像是xpath在XML中的作用.用来确定json中某部分数据的语言.我更喜欢叫jsonpath表达式,因为这样好像是数学问题. 以前和小伙伴一起写接口自动化的时 ...
- ubuntu服务器启动过程中重启卡死的问题解决
在grub默认参数当中添加 GRUB_RECORDFAIL_TIMEOUT=0 写于: 2014年07月23日 更新于: 2015年03月24日
- (7)ASP.NET Core3.1 Ocelot Swagger
1.前言 前端与后端的联系更多是通过API接口对接,API文档变成了前后端开发人员联系的纽带,开始变得越来越重要,而Swagger就是一款让你更好的书写规范API文档的框架.在Ocelot Swagg ...
- SQL Server 批量生成数据库内多个表的表结构
在遇到大型数据库的时候,一个数据库内存在大量的数据表,如果要生成多个表的表结构,一个表的检索,然后右键Create出来,太麻烦了. 下面我介绍下批量选择并生成多个表的表结构快捷方式,仅供参考. 第一步 ...
- Camtasia对录制视频字幕编辑的教程
我们小时候会有这样的疑问,电视剧上的字幕是怎么做成的呢.字幕又是怎么不会从一幕到下一幕而产生不对应的呢.这就是影视的后期处理的结果了,利用视频的编辑软件,工作者们可以在特定的时间内加上相对应的台词,然 ...
- 日常踩坑-------新手使用idea
mybatis在idea的maven项目中的坑 今天遇到mybatis的报错,搞了好久才搞懂,在网上找了好久的相似案例,也没有搞定,先来看下网上常见的解决办法吧,相信也能解决大部分人的报错. 1.ma ...
- linux命令模式配置安装mysql
系统环境: centos 7.1 使用模式:命令模式 使用工具:xshell5 . xftp5 安装mysql前必须删除干净旧的安装包和残留文件,否则安装会失败 查看旧的安装包 rpm -qa | g ...