导出mysql内数据 python建倒排索引
根据mysql内数据,python建倒排索引,再导回mysql内。
先把mysql内的数据导出,先导出为csv文件,因为有中文,直接打开csv文件会乱码,再直接改文件的后缀为txt,这样打开时不会是乱码,在第一行输入列名

保存时选另存为,将编码格式改为utf-8
这是建倒排索引时的代码(sort列没有空格和逗号) 运行是会报一个warning,但是结果没问题,代码结合了网络搜索结果,和我自己的修改,引用自:
https://blog.csdn.net/luoganttcc/article/details/89843699
https://github.com/luogantt/recommend_sys/blob/master/Inverted_index/invert_indexx.py 多谢分享!
from pprint import pprint
import pandas as pd
df = pd.read_csv("C:/Users/caiweiwen/Desktop/index_poem_dynasty.txt")
df['id'] = ' '
df['dynasty'] = ' '
all_dynasty = dict()
for i in range(len(df['poemid'])):
df['id'][i] = str(df['poemid'][i])
df['dynasty'][i] = "".join(str(df['dyn'][i]).split("朝代:"))
all_dynasty[df['dynasty'][i]] = 1
for dyn in all_dynasty.keys():
temp = []
for i in range(len(df['id'])):
if dyn == df['dynasty'][i]:
temp.append(df['id'][i])
all_dynasty[dyn] = temp
pprint(all_dynasty)
for sort in all_dynasty.keys():
with open('index_poem_dynasty.csv', 'a+', encoding='utf-8-sig') as f:
f.write(sort + ':'+','.join(all_dynasty[sort])+'\n')
还有更复杂一点的诗歌标签的倒排索引:
from pprint import pprint
import pandas as pd
docu_set = dict()
df = pd.read_csv("C:/Users/caiweiwen/Desktop/index_poem_sort.txt")
key = ""
value = ""
for i in range(42440): #数据问题,之后的数据id和sort之间会换行
key = str(df['poemid'][i])
value = str(df['sort'][i]).split( ) #去掉每个sort里的空格,返回列表
docu_set[key]=value
print(key)
print(value)
tmp = []
for i in range(42439,len(df['poemid'])):
if(df['poemid'][i].isdigit()): #判断是否为数字,是则为id
key = df['poemid'][i]
docu_set[key] = tmp
else:
tmp.append("".join(str(df['poemid'][i]).split())) #先去掉sort里的空格,因为返回的列表项是列表,列表项应为string,所以又转为string
if(df['poemid'][i+1].isdigit()): #判断下一行是否为数字
docu_set[key] = tmp
print("key:" + key)
print("value:" + str(tmp))
tmp = []
pprint(docu_set) #输出字典
all_words = dict()
for i in docu_set.values():
for j in i:
all_words[j] = 1
print(all_words.keys())
invert_index = dict()
for b in all_words.keys():
temp = []
for j in docu_set.keys():
if b in docu_set[j]:
temp.append(j)
invert_index[str(b)] = temp
pprint(invert_index)
for sort in invert_index.keys():
with open('index_poem_sort.csv', 'a+', encoding='utf-8-sig') as f:
f.write(sort + ':'+','.join(invert_index[sort])+'\n')
倒排结果:
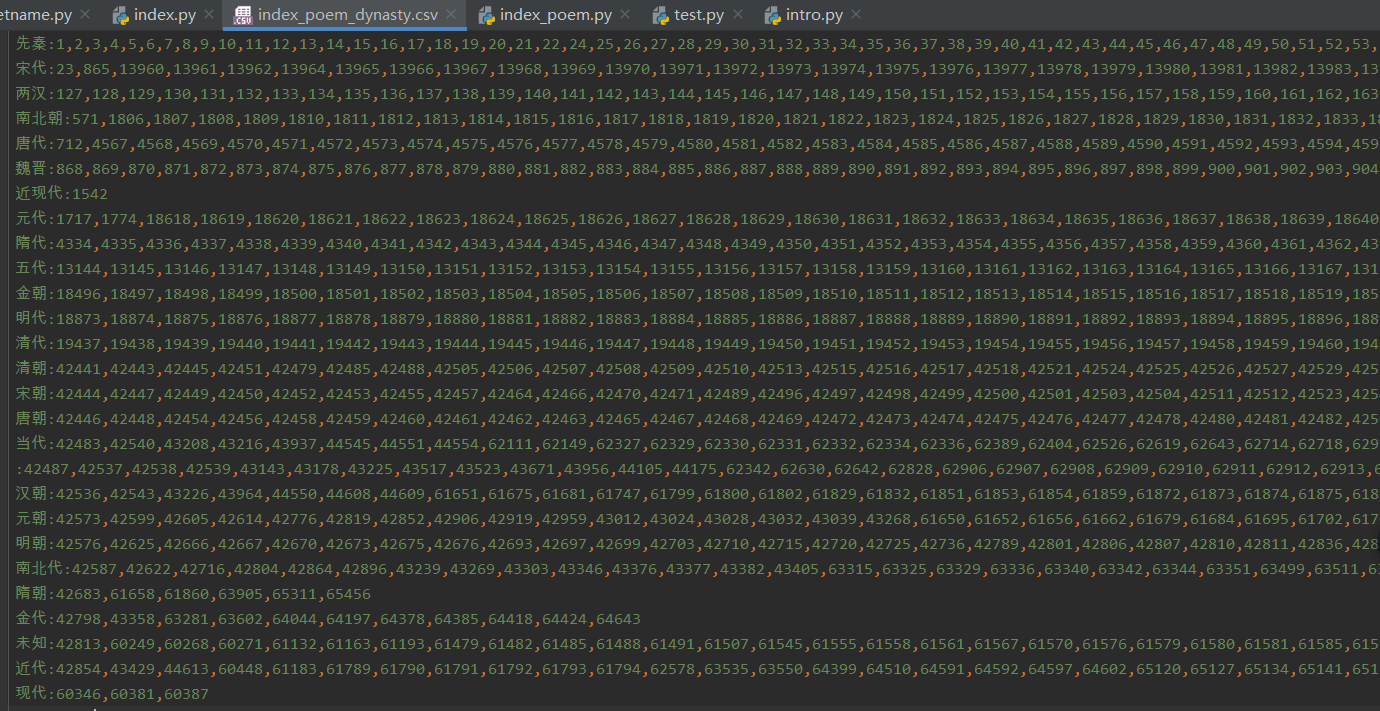
导入时选择txt文件的形式
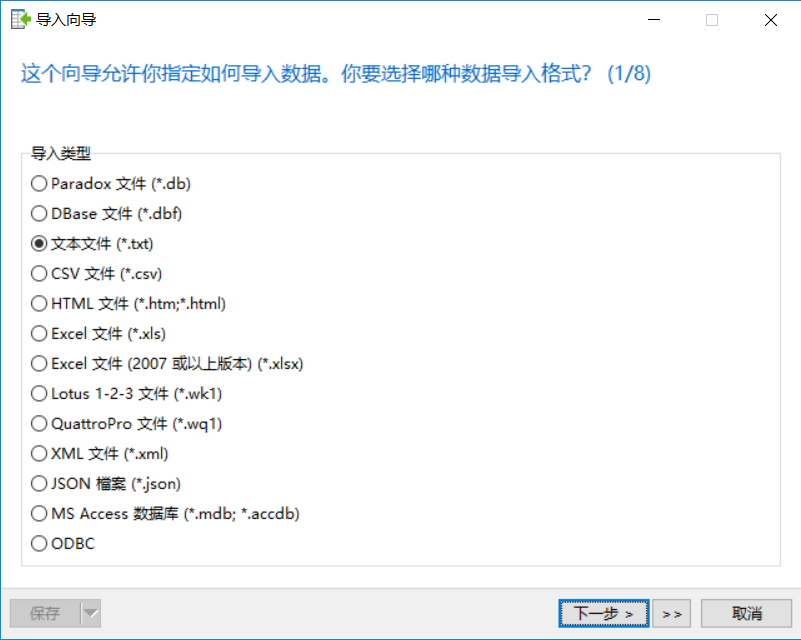
栏位分隔符我选择其他符号,我用冒号“ :”,视自己的具体情况而定,这样选源栏位和目标栏位时就很清晰了

最后的成果:
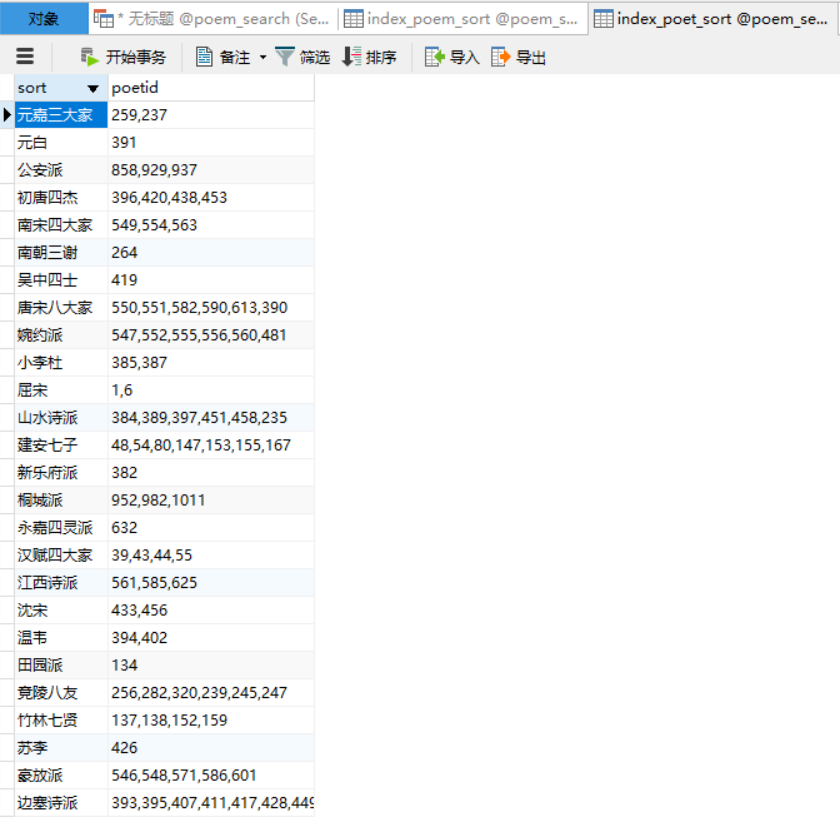
总结:
刚开始还是走了很多弯路,用dataframe和它自带的建索引,结果不知道怎么用,还是上网搜了倒排索引的python代码后才知道该用什么数据类型,幸好看到的第一个就是对的哈哈哈,
以前第一次做android的时候就花了很多时间查百度都没对,问了大佬才知道要先系统地学习一遍。以后不知道怎么写的时候还是直接搜要做的内容吧,按自己的想法搜数据结构或者算法要
花很多时间。
导出mysql内数据 python建倒排索引的更多相关文章
- 使用Python3导出MySQL查询数据
整理个Python3导出MySQL查询数据d的脚本. Python依赖包: pymysql xlwt Python脚本: #!/usr/bin/env python # -*- coding: utf ...
- Python导出MySQL数据库中表的建表语句到文件
为了做数据对象的版本控制,需要将MySQL数据库中的表结构导出成文件进行版本化管理,试写了一下,可以完整导出数据库中的表结构信息 # -*- coding: utf-8 -*- import os i ...
- linux下用命令导出mysql表数据
由于数据库服务器是内网环境,只能通过linux跳板机连接,所以navicat工具暂时用不上. 1.用Xshell工具连接跳板机 2.再通过跳板机连接数据库服务器 >ssh -p port ip ...
- 导出mysql数据库数据
1.phpmyadmin导出 ) AS `a` LEFT JOIN ( SELECT * FROM `newerp_jifen_order_log` WHERE `content` = '客户确认收货 ...
- shell导出mysql部分数据
#!/bin/shSYSTEM=`uname -s` echo "echo"$SYSTEM if [[ $SYSTEM = "Linux" ]]; then ...
- 使用MySQL的SELECT INTO OUTFILE ,Load data file,Mysql 大量数据快速导入导出
使用MySQL的SELECT INTO OUTFILE .Load data file LOAD DATA INFILE语句从一个文本文件中以很高的速度读入一个表中.当用户一前一后地使用SELECT ...
- linux下导入、导出mysql数据库命令 下载文件到本地
一.下载到本地 yum install lrzsz sz filename 下载 rz filename 上传 linux下导入.导出mysql数据库命令 一.导出数据库用mysqldump命 ...
- PHPExcel使用-使用PHPExcel导出文件-导出MySQL数据
现在数据库里面有一组数据,我们将它按照不同的难度进行分sheet. 首先我们需要写一个mysql的配置文件- db.config.php(utf-8编码) : <?php $dbconfig= ...
- mysql的数据导出方法
mysql的数据导出几种方法 从网上找到一些问题是关于如何从MySQL中导出数据,以便用在本地或其它的数据库系统之上:以及 将现有数据导入MySQL数据库中. 数据导出 数据导出主要有以下几种方法 ...
随机推荐
- scrapy和scrapy-redis 详解一 入门demo及内容解析
架构及简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛. Scrapy 使用了 Twisted(其主要对手是Tornado)异步网络框架来处理 ...
- 2020年Android开发最新整理阿里巴巴、字节跳动、小米面经,你不看看吗?
前言 2020年是转折的一年,上半年疫情原因,很多学android开发的小伙伴失业了,虽找到了一份工作,但高不成低不就,下半年金九银十有想法更换一份工作,很多需要大厂面试经验和大厂面试真题的小伙伴,想 ...
- vue-cli中使用swiper
1.当前项目配置 cnpm install swiper vue-awesome-swiper --save 或指定版本下载 cnpm install swiper@5.4.5 vue-awesome ...
- Spring中的BeanFactory与FactoryBean看这一篇就够了
前言 理解FactoryBean是非常非常有必要的,因为在Spring中FactoryBean最为典型的一个应用就是用来创建AOP的代理对象,不仅如此,而且对理解Mybatis核心源码也非常有帮助!如 ...
- python类变量与成员变量
类变量与成员变量 关注公众号"轻松学编程"了解更多. 在类中声明的变量我们称之为类变量[静态成员变量], 在__init__()函数中声明的变量并且绑定在实例上的变量我们称之为 ...
- 微信小程序-游记分享(无后台)
游记分享 博客班级 https://edu.cnblogs.com/campus/zjcsxy/SE2020 作业要求 https://edu.cnblogs.com/campus/zjcsxy/SE ...
- 解决SBT下载慢,dump project structure from sbt?
一. 安装SBT,参考https://blog.csdn.net/zcf1002797280/article/details/49677881 二. 在~/.sbt下新建repositories添加如 ...
- AC 自动机刷题记录
目录 简介 第一题 第二题 第三题 第四题 第五题 第六题 简介 这就是用来记录我对于<信息学奥赛一本通 · 提高篇>一书中的习题的刷题记录以及学习笔记. 一般分专题来写(全部写一起可能要 ...
- 微信小程序授权页面
这里也是比较简单的 直接复制粘贴就可以用,可能图片位置不对.. <template> <view id="imporwer"> <image src= ...
- node转发请求 .csv格式文件下载 中文乱码问题 + 文件上传笔记
用户无法直接访问后台接口 需要node端转发请求 并将数据以.csv文件格式生成以供客户端下载. 很不幸出现了中文乱码的问题 挖了各种坟帖,下了各种依赖包,csv.json2csv.bufferHel ...