聊聊 elasticsearch 之分词器配置 (IK+pinyin)
系统:windows 10
elasticsearch版本:5.6.9
es分词的选择
- 使用es是考虑服务的性能调优,通过读写分离的方式降低频繁访问数据库的压力,至于分词的选择考虑主要是根据目前比较流行的分词模式,根据参考文档自己搭建测试。
es配置目录结构
- 在此先贴出es下plugins的目录结构,避免安装时一脸茫然(出自本人配置目录,可根据自身需要进行调整):
- es插件目录结构:

- ik压缩包内文件列表:
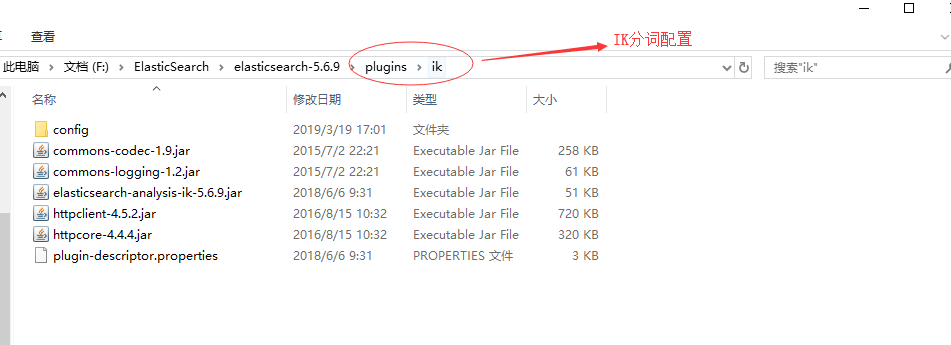
- pinyin压缩包内文件目录:

IK 分词器
- IK分词器下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases?after=v5.6.11
- 进入链接,选择对应版本编译好的压缩包,点击即可下载。如下图:
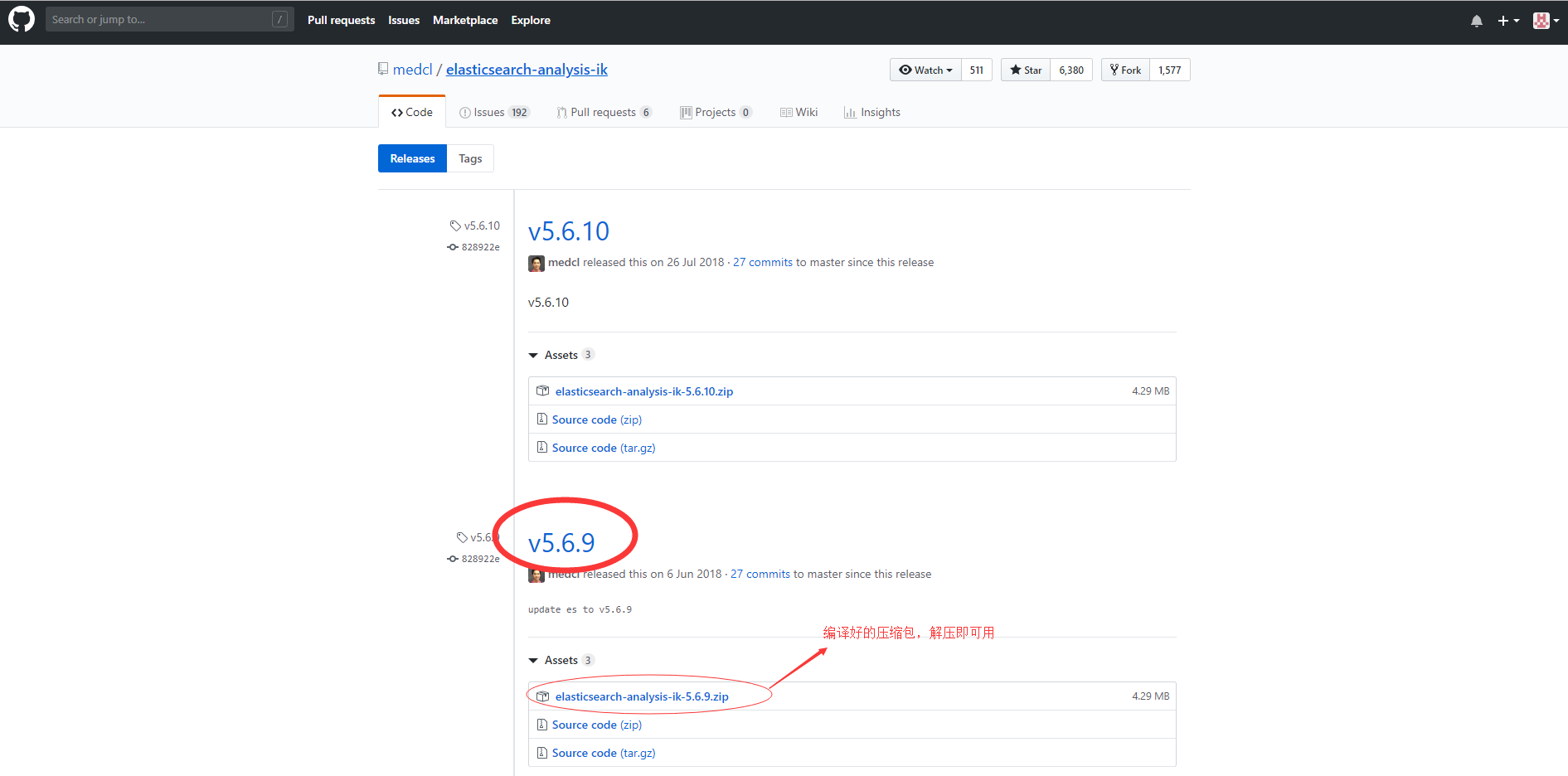 、
、 - 上述步骤下载后,解压文件到至\elasticsearch5.6.9\plugins\ik目录下(如无ik目录,手动创建即可),重新启动es服务,即可看到控制台输出的插件信息,表示配置成功。如下图:
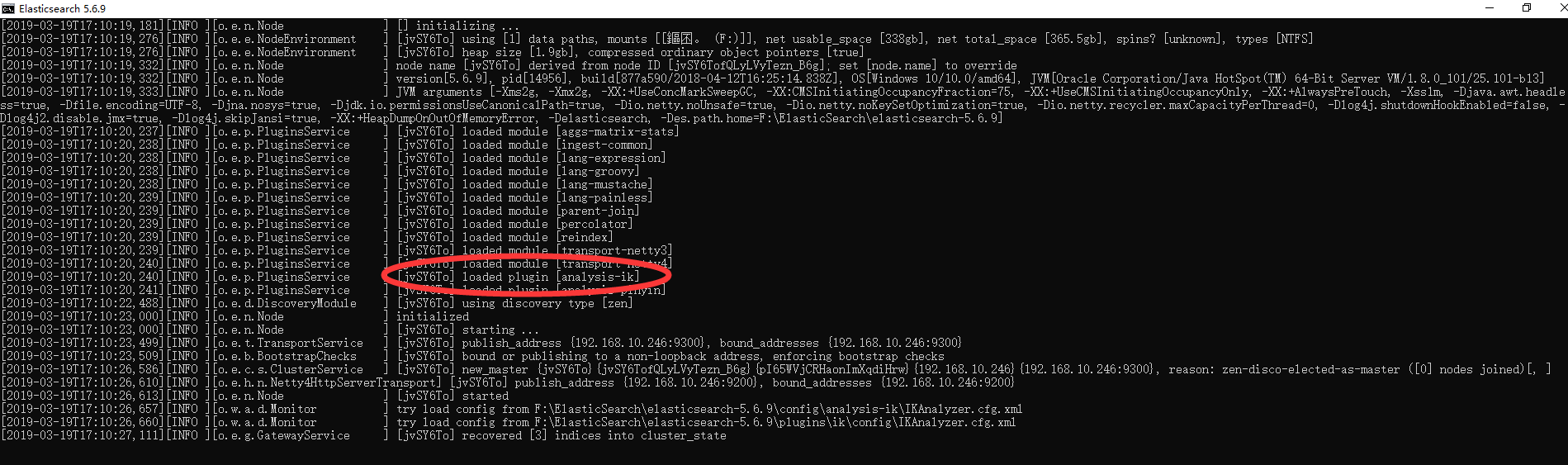
pinyin分词器
- 拼音分词器下载地址:https://github.com/medcl/elasticsearch-analysis-pinyin/releases?after=v5.6.11
- 拼音分词的配置类似于ik分词,进入链接,选择对应版本编译好的压缩包,点击即可下载。如下图:
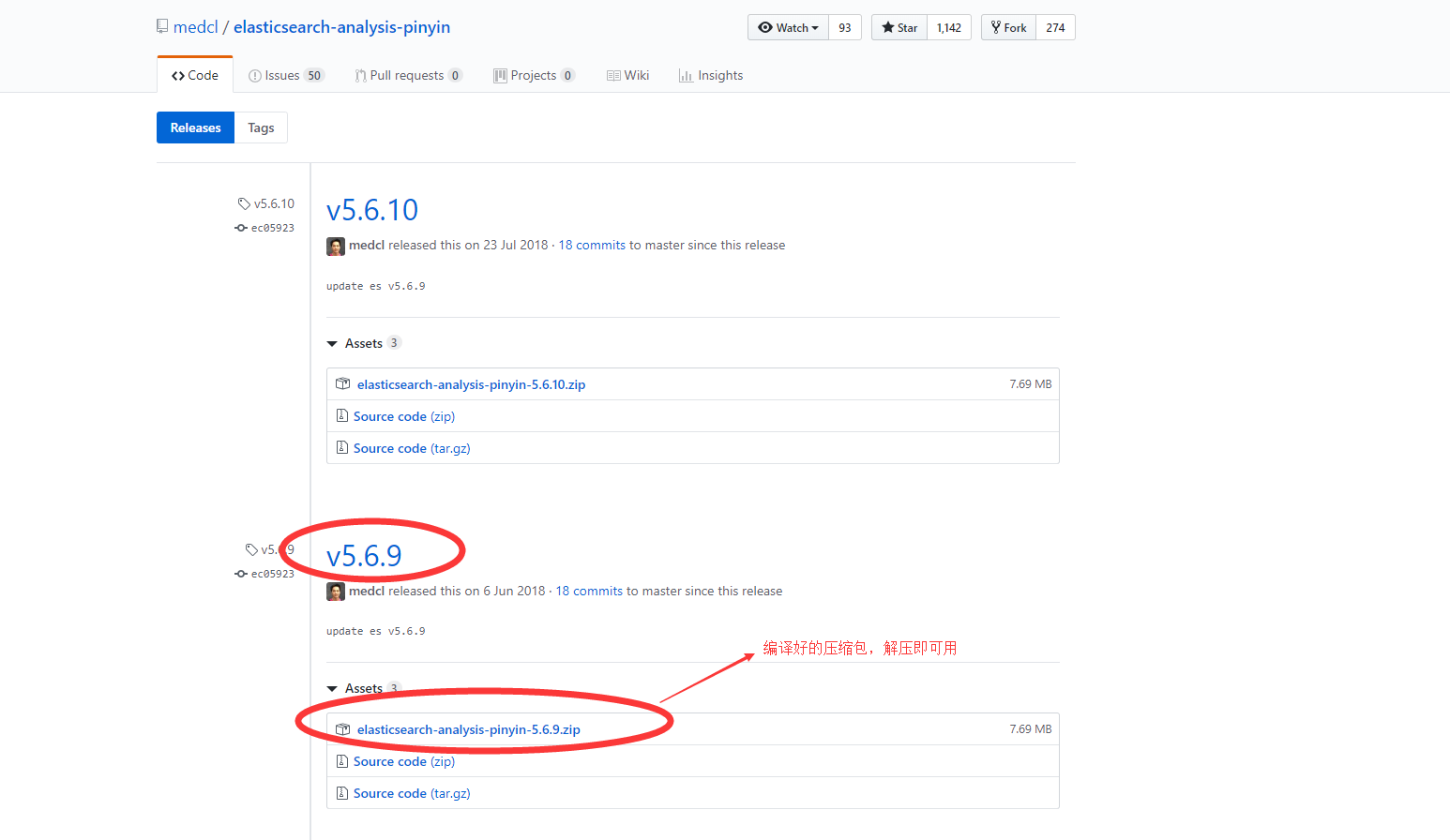
- 上述步骤下载后,解压文件到至\elasticsearch5.6.9\plugins\pinyin目录下(如无pinyin目录,手动创建即可),重新启动es服务,即可看到控制台输出的插件信息,表示配置成功。如下图:

分词器的测试案例
- IK分词,主要强调两种分词模式:ik_smart和ik_max_word
- ik_smart是将文本做了正确的拆分,如下图:
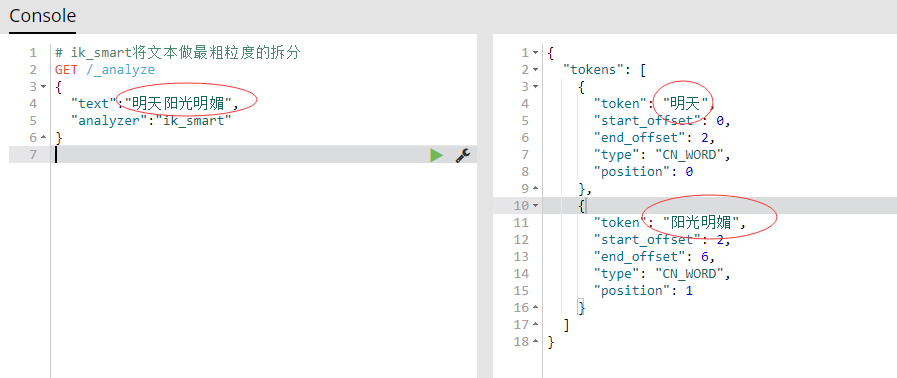
- 看到结果发现ik_smart分词模式拆分的不够细,“阳光明媚”并没有拆分开,所以接下来就该另一种分词出场了 ---- ik_max_word,直接上结果,如下图:

- 这种更加详细的拆分才是我想要的,这回不用担心高级搜索了····
- ik_smart是将文本做了正确的拆分,如下图:
- 拼音分词,简言之就是将文本拆分成更加详细拼音,图解如下:
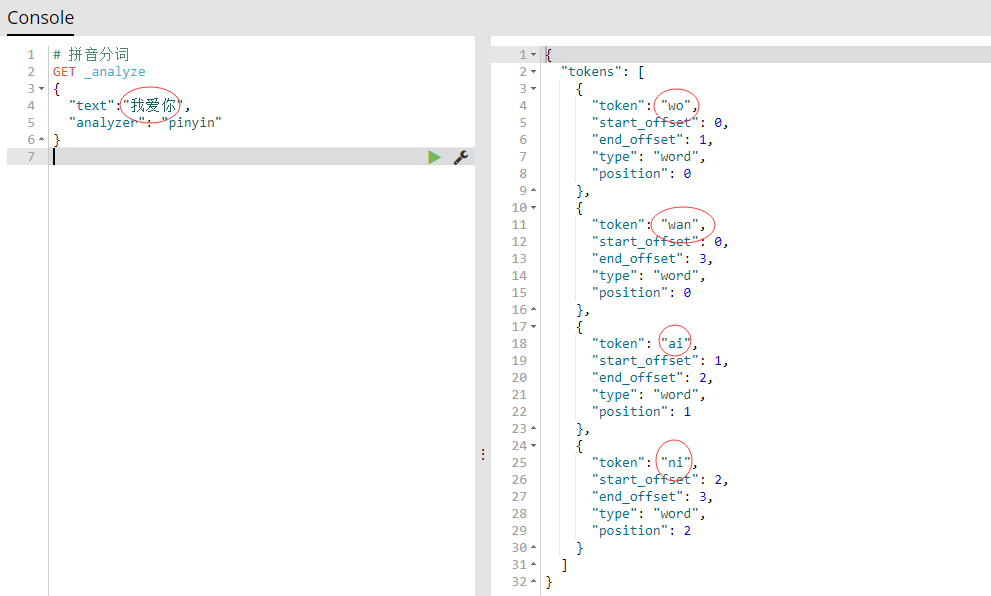
- ik与pinyin的结合使用(注:当使用分词搜索数据的时候,必须是通过分词器分析的数据才能搜索出来,否则无法搜索出数据)
- 创建索引时可以自定义分词器配置,通过映射可以指定自定义的分词器,配置如下图:
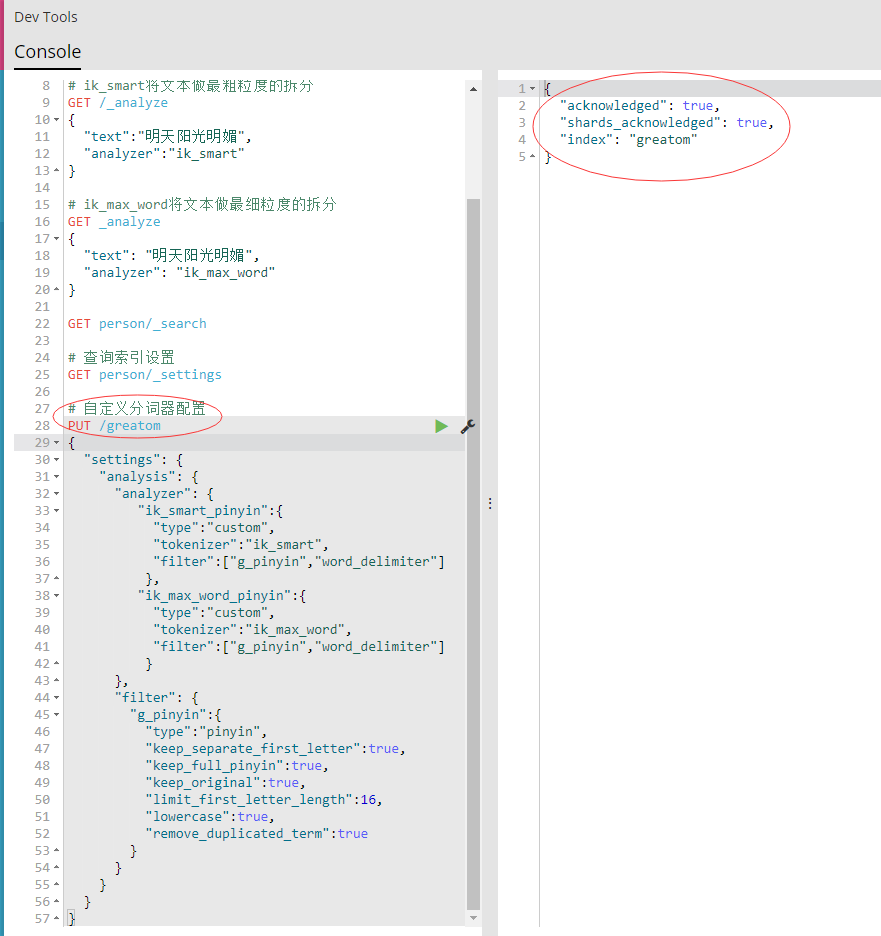
- 创建名称为“greatom”的索引,自定义“ik_smart_pinyin”和“ik_max_word_pinyin”的分词器,过滤设置为“g_pinyin”,如上图右侧提示则表示设置成功,可以通过“GET greatom/settings”查询配置信息。
- 创建type时,需要在字段的解析属性(analyzer)中设置自定义名称的映射,如下图:
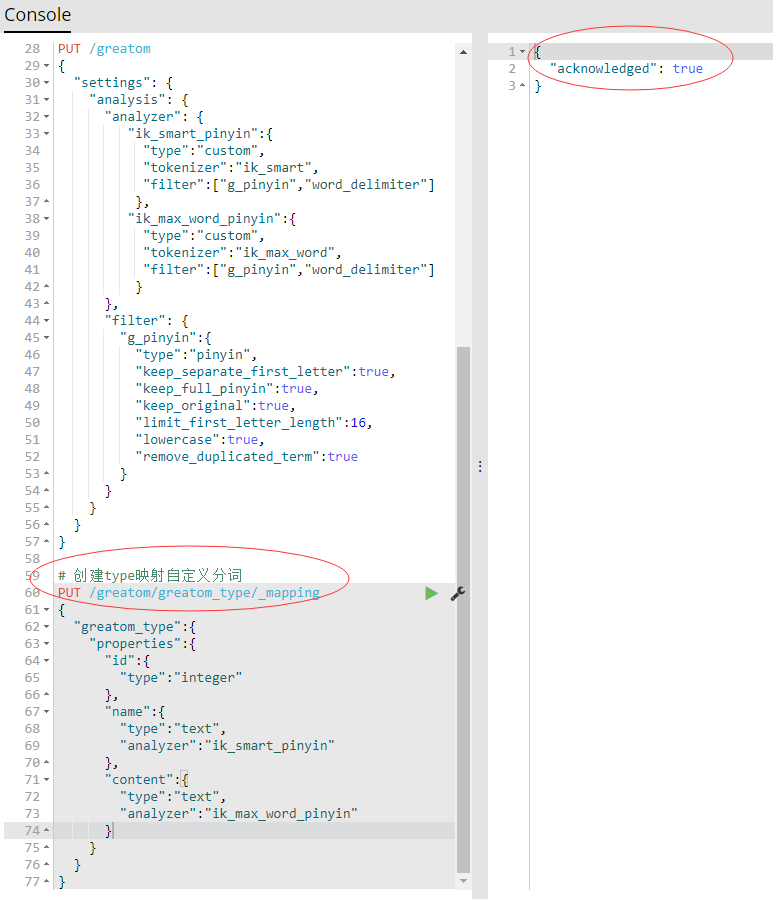
- 如上图右侧提示则表示创建成功,接下来增加点数据,以便后续测试。
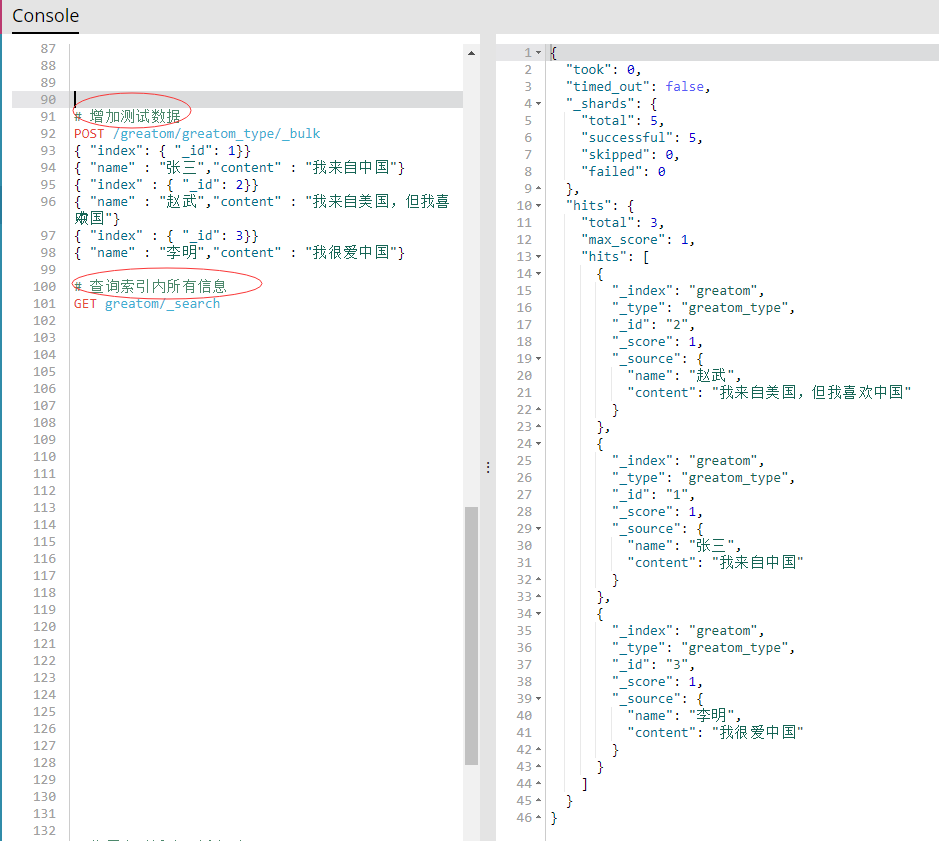
- 测试数据按照上图方式即可进行批量新增,也可对索引数据进行查询。接下来就开始正式的分词查询。
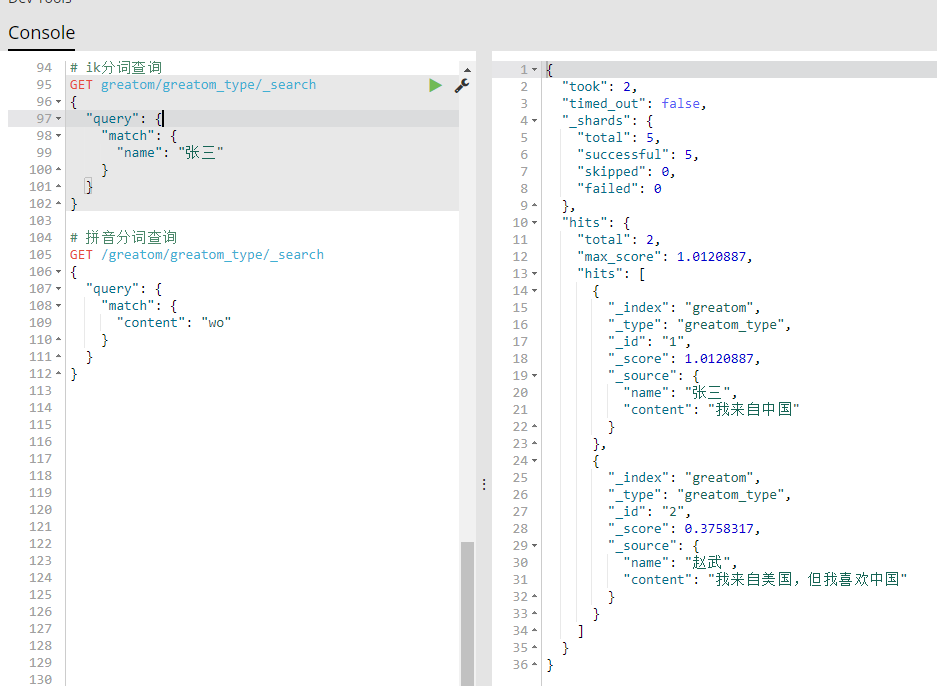
- 上图表示两种分词的查询格式,可以联想搜索出相关的所有数据,感觉比较智能了。
- 创建索引时可以自定义分词器配置,通过映射可以指定自定义的分词器,配置如下图:
结尾
- 通过对es分词的了解和使用,发现选择的两种分词模式已经满足自己项目的使用,还未进行更深入的了解,后续会继续了解底层及分词原理,如有瑕疵或更好的见解,希望可以交流学习。
聊聊 elasticsearch 之分词器配置 (IK+pinyin)的更多相关文章
- elasticsearch中文分词器(ik)配置
elasticsearch默认的分词:http://localhost:9200/userinfo/_analyze?analyzer=standard&pretty=true&tex ...
- Solr多核心及分词器(IK)配置
Solr多核心及分词器(IK)配置 多核心的概念 多核心说白了就是多索引库.也可以理解为多个"数据库表" 说一下使用multicore的真实场景,比若说,产品搜索和会员信息搜索 ...
- 真分布式SolrCloud+Zookeeper+tomcat搭建、索引Mysql数据库、IK中文分词器配置以及web项目中solr的应用(1)
版权声明:本文为博主原创文章,转载请注明本文地址.http://www.cnblogs.com/o0Iris0o/p/5813856.html 内容介绍: 真分布式SolrCloud+Zookeepe ...
- ElasticSearch中分词器组件配置详解
首先要明确一点,ElasticSearch是基于Lucene的,它的很多基础性组件,都是由Apache Lucene提供的,而es则提供了更高层次的封装以及分布式方面的增强与扩展. 所以要想熟练的掌握 ...
- Solr IK分词器配置
下载地址:https://search.maven.org/search?q=com.github.magese 分词器配置: 参考:https://www.cnblogs.com/mengjinlu ...
- elasticsearch kibana + 分词器安装详细步骤
elasticsearch kibana + 分词器安装详细步骤 一.准备环境 系统:Centos7 JDK安装包:jdk-8u191-linux-x64.tar.gz ES安装包:elasticse ...
- Solr入门之(8)中文分词器配置
Solr中虽然提供了一个中文分词器,但是效果很差,可以使用IKAnalyzer或Mmseg4j 或其他中文分词器. 一.IKAnalyzer分词器配置: 1.下载IKAnalyzer(IKAnalyz ...
- 2.IKAnalyzer 中文分词器配置和使用
一.配置 IKAnalyzer 中文分词器配置,简单,超简单. IKAnalyzer 中文分词器下载,注意版本问题,貌似出现向下不兼容的问题,solr的客户端界面Logging会提示错误. 给出我配置 ...
- Solr6.5.0配置中文分词器配置
准备工作: solr6.5.0安装成功 1.去官网https://github.com/wks/ik-analyzer下载IK分词器 2.Solr集成IK a)将ik-analyzer-solr6.x ...
随机推荐
- eclipse中将java项目变成web项目
今天,用Eclipse开发项目的时候,把一个Web项目导入到Eclipse里会变成了一个java工程,将无法在Tomcat中进行部署运行. 方法: 1.找到.project文件,找到里面的<na ...
- NMS总结
目录 NMS总结 一. NMS 二. Soft-NMS 三. IOU-Guided NMS 四. Softer-NMS 五. DIOU-NMS 六. 总结 NMS总结 一. NMS 目标检测:同一个类 ...
- js根据ip地址获取城市地理位置
一.使用js根据ip获取地址位置 <script src="http://pv.sohu.com/cityjson?ie=utf-8"></script>& ...
- 晚间测试13 A. Dove 打扑克 vector +模拟
题目描述 分析 这道题比较关键的一点就是要看出最终牌数的种类数不会超过 \(\sqrt{n}\) 种 知道了这个性质我们就可以用 \(vector\) 维护一个有序的序列 \(vector\) 中存放 ...
- 【总结】zookeeper
一.入门 1.概述 Zookeeper 是一个开源的分布式的,为分布式应用提供协调服务的 Apache 项目 2.zookeeper特点 (1)Zookeeper:一个领导者(Leader),多个跟随 ...
- ASP.NET Core Authentication系列(四)基于Cookie实现多应用间单点登录(SSO)
前言 本系列前三篇文章分别从ASP.NET Core认证的三个重要概念,到如何实现最简单的登录.注销和认证,再到如何配置Cookie 选项,来介绍如何使用ASP.NET Core认证.感兴趣的可以了解 ...
- ETCD核心机制解析
ETCD整体机制 etcd 是一个分布式的.可靠的 key-value 存储系统,它适用于存储分布式系统中的关键数据. etcd 集群中多个节点之间通过Raft算法完成分布式一致性协同,算法会选举出一 ...
- HashMap的初始化,到底都做了什么?
HashMap的初始化,到底都做了什么? HashMap初始化参数都是什么?默认是多少? 为什么建议初始化设置容量? tableSizeFor方法是做什么的? 如何获取到一个key的hash值?及计算 ...
- .net 实现签名验签
本人被要求实现.net的签名验签,还是个.net菜鸡,来分享下采坑过程 依然,签名验签使用的证书格式依然是pem,有关使用openssl将.p12和der转pem的命令请转到php实现签名验签 .ne ...
- opencv--ORB::create
static Ptr<ORB> cv::ORB::create ( int nfeatures = 500, ...