究竟什么时候该使用MQ?
究竟什么时候该使用MQ?
任何脱离业务的组件引入都是耍流氓。引入一个组件,最先该解答的问题是,此组件解决什么问题。
MQ,互联网技术体系中一个常见组件,究竟什么时候不使用MQ,究竟什么时候使用MQ,MQ究竟适合什么场景,是今天要分享的内容。
MQ是什么?消息总线(Message Queue),后文称MQ,是一种跨进程的通信机制,用于上下游传递消息。画外音:这两个进程,一般不在同一台服务器上。 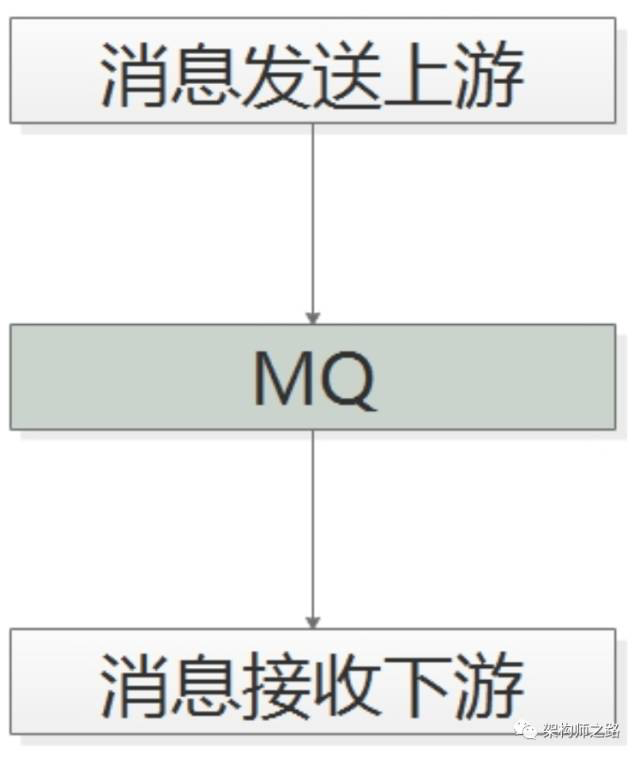
在互联网架构中,MQ经常用做“上下游解耦”:(1)消息发送方只依赖MQ,不关注消费方是谁;(2)消息消费方也只依赖MQ,不关注发送方是谁;
画外音:发送方与消费方,逻辑上和物理上都不依赖彼此。
什么时候不使用MQ?当调用方需要关心消息执行结果时,通常不使用MQ,而使用RPC调用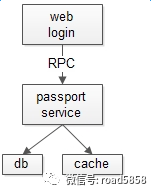
ret = PassportService::userAuth(name, pass);
switch(ret){
case(YES) : return YesHTML();
case(NO) : return NoHTML();
case(JUMP) : return 304HTML():
default : return 500HTML();
}
如上例所示,上游调用Passport服务,处理结果不同,业务会走不同的逻辑处理分支(登录成功,登录失败,执行错误等),即“处理结果强依赖”,此时应该使用RPC调用。画外音:绝大部分情况,应该使用RPC。 此时如果强行使用MQ呢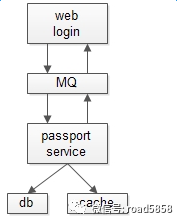
如果强行使用MQ通讯,调用方不能直接告之用户登录成功又或失败,则要等待另一个MQ通知回调。这么玩,不但使得编码复杂,还会引入消息丢失的风险,中间多加入一层,多此一举。 究竟什么时候使用MQ呢?下面四类典型场景,应该使用MQ。
典型场景一:数据驱动的任务依赖
什么是任务依赖?举个栗子,互联网公司经常在凌晨进行一些数据统计任务,这些任务之间有一定的依赖关系,例如:(1)task3需要使用task2的输出作为输入;(2)task2需要使用task1的输出作为输入;这样的话,tast1, task2, task3之间就有任务依赖关系,必须task1先执行,再task2执行,载task3执行。
对于这类需求,通常怎么实现呢?常见的玩法是,crontab人工排执行时间表。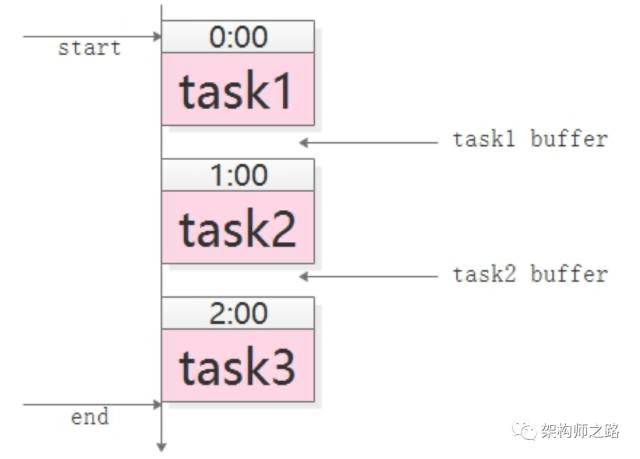
如上图,手动设定如下:(1)task1,0:00执行,经验执行时间为50分钟;(2)task2,1:00执行(为task1预留10分钟buffer),经验执行时间也是50分钟;(3)task3,2:00执行(为task2预留10分钟buffer); crontab手动排表有什么坏处呢?(1)如果有一个任务执行时间超过了预留buffer的时间,将会得到错误的结果,因为后置任务不清楚前置任务是否执行成功,此时要手动重跑任务,还有可能要调整排班表;(2)总任务的执行时间很长,总是要预留很多buffer,如果前置任务提前完成,后置任务不会提前开始;(3)如果一个任务被多个任务依赖,这个任务将会称为关键路径,排班表很难体现依赖关系,容易出错;(4)如果有一个任务的执行时间要调整,将会有多个任务的执行时间要调整;
无论如何,采用“crontab排班表”的方法,各任务严重耦合,谁用过谁痛谁知道。画外音:用过的,痛过的,请留言。
应该如何优化呢?采用MQ解耦。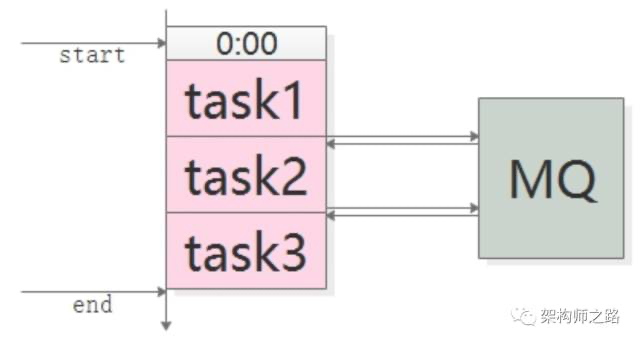
如上图,任务之间通过MQ来传递“开始”与“结束”的通知:(1)task1准时开始,结束后发一个“task1 done”的消息;(2)task2订阅“task1 done”的消息,收到消息后第一时间启动执行,结束后发一个“task2 done”的消息;(3)task3同理; 采用MQ有什么好处呢?(1)不需要预留buffer,上游任务执行完,下游任务总会在第一时间被执行;(2)依赖多个任务,被多个任务依赖都很好处理,只需要订阅相关消息即可;(3)有任务执行时间变化,下游任务都不需要调整执行时间; 需要特别说明的是,MQ只用来传递上游任务执行完成的消息,并不用于传递真正的输入输出数据。 典型场景二:上游不关心执行结果
上游需要关注执行结果时要用“RPC调用”,上游不关注执行结果时,使用MQ。 举个栗子,58同城的很多下游需要关注“用户发布帖子”这个事件,比如:(1)招聘用户发布帖子后,招聘业务要奖励58豆;(2)房产用户发布帖子后,房产业务要送2个置顶;(3)二手用户发布帖子后,二手业务要修改用户统计数据;
对于这类需求,可以采用什么方式实现呢?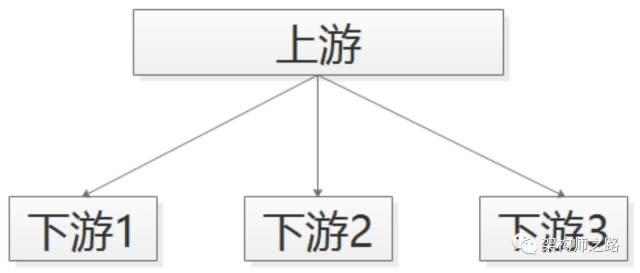
比较无脑的,可以使用RPC调用来实现:帖子发布服务执行完成之后,调用下游招聘业务、房产业务、二手业务,来完成消息的通知。
但事实上,这个通知是否正常正确的执行,帖子发布服务根本不关注。 通过RPC来传递不需要知道处理结果的通知,有什么坏处呢?(1)帖子发布流程的执行时间增加了;(2)下游服务当机,可能导致帖子发布服务受影响,上下游逻辑+物理依赖严重;(3)每当增加一个需要知道“帖子发布成功”信息的下游,修改代码的是帖子发布服务;画外音:这一点是最恶心的,属于架构设计中典型的反向依赖。
如何来进行优化呢?采用MQ解耦,代替RPC。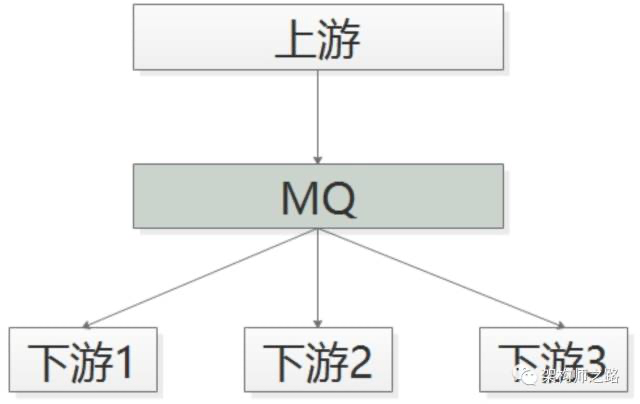
如上图所示:(1)帖子发布成功后,向MQ发一个消息;(2)哪个下游关注“帖子发布成功”的消息,主动去MQ订阅; 如此一来,有什么好处呢?(1)上游执行时间短;(2)上下游逻辑+物理解耦,除了与MQ有物理连接,模块之间都不相互依赖;(3)新增一个下游消息关注方,上游不需要修改任何代码; 典型场景三:上游关注执行结果,但执行时间很长
有时候上游需要关注执行结果,但执行结果时间很长(典型的是调用离线处理,或者跨公网调用),也经常使用回调网关+MQ来解耦。 举个栗子,微信支付,跨公网调用微信的接口,执行时间会比较长,但调用方又非常关注执行结果,此时一般怎么玩呢?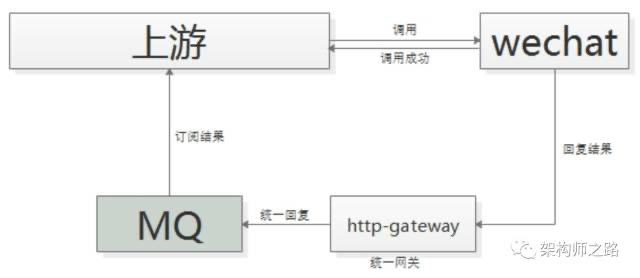
一般采用“回调网关+MQ”方案来解耦:(1)调用方直接跨公网调用微信接口;(2)微信返回调用成功,此时并不代表返回成功;(3)微信执行完成后,回调统一网关;(4)网关将返回结果通知MQ;(5)请求方收到结果通知; 这里需要注意的是,不应该由回调网关来RPC通知上游来通知结果,如果是这样的话,每次新增调用方,回调网关都需要修改代码,仍然会反向依赖,使用回调网关+MQ的方案,新增任何对微信支付的调用,都不需要修改代码。 结尾总结MQ是一个互联网架构中常见的解耦利器。
什么时候不使用MQ?上游实时关注执行结果,通常采用RPC。 什么时候使用MQ?(1)数据驱动的任务依赖;(2)上游不关心多下游执行结果;(3)异步返回执行时间长;
究竟什么时候该使用MQ?的更多相关文章
- 为什么会需要消息队列(MQ)?
为什么会需要消息队列(MQ)? #################################################################################### ...
- 消息队列一:为什么需要消息队列(MQ)?
为什么会需要消息队列(MQ)? #################################################################################### ...
- 浅谈服务间通信【MQ在分布式系统中的使用场景】
解决的问题 一项技术的产生必然是为了解决问题而生,了解了一项技术解决的问题,就能够很轻松的理解这项技术的设计根本,从而更好地理解与使用这项技术. 消息中间件和RPC从根本上来说都是为了解决分布式系统的 ...
- 到底什么时候该使用MQ?
一.缘起 一切脱离业务的架构设计与新技术引入都是耍流氓. 引入一个技术之前,首先应该解答的问题是,这个技术解决什么问题. 就像微服务分层架构之前,应该首先回答,为什么要引入微服务,微服务究竟解决什么问 ...
- 朱晔的互联网架构实践心得S2E1:业务代码究竟难不难写?
注意,这是我的架构实践心得的第二季的系列文章,第一季有10篇你也可以回顾. 见https://www.cnblogs.com/lovecindywang/category/1296779.html 最 ...
- 架构-到底什么时候该使用MQ【转】
点击:<查看原文> 一.缘起 一切脱离业务的架构设计与新技术引入都是耍流氓. 引入一个技术之前,首先应该解答的问题是,这个技术解决什么问题. 就像微服务分层架构之前,应该首先回答,为什么要 ...
- 使用MQ要考虑的问题
一般现代软件系统都会用到MQ,几乎所有开发人员也都会想到用MQ,但真正能用好的人估计不多,因为要用好MQ有很多方面问题要考虑: 1.在原直接交互的系统间增加MQ中间层,MQ的性能.可靠程度会严重影响原 ...
- 【转】到底什么时候应该用MQ
原文地址:http://zhuanlan.51cto.com/art/201704/536407.htm 一.缘起 一切脱离业务的架构设计与新技术引入都是耍流氓. 引入一个技术之前,首先应该解答的问题 ...
- mq使用场景、不丢不重、时序性
mq使用场景.不丢不重.时序性.削峰 参考: http://zhuanlan.51cto.com/art/201704/536407.htm http://zhuanlan.51cto.com/art ...
随机推荐
- MFC 结束线程
在wtl工程中定义一个现成,如下:DWORD WINAPI ThreadFunc( LPVOID pParam ){if( g_pMainlg )g_pMainlg->DoEnumNetwork ...
- emacs-显示行号以及跳转到指定行
[显示行号]M+x display-line-number-mode <Return> [跳转行号]M+x goto-line 然后输入你想跳转到的行号 <Return> (在 ...
- vim常用指令参考
(完)
- 使用selenium抓取淘宝信息并存储mongodb
selenium模块 简单小例子 Author:song import pyquery from selenium import webdriver from selenium.common.exce ...
- 学习 Java 网站推荐给你
推荐几个非常不错的 Java 学习网站 LearnJava 在线 这是一个非常不错的学习 Java 的在线网站,纯免费.这是一个个人项目,旨在通过简单有效的在浏览器中进行练习让你快速掌握 Java 编 ...
- 前段人员必藏的7 个 CSS 好用的属性绝对干货
学习CSS是构建好看网页的一种方式. 但是,在学习过程中,我们倾向于(大部分时间)限制自己,一遍又一遍地使用相同的属性. 毕竟,我们是一种习惯性的动物,我们会使用自己习惯且熟悉的东西. 因此,在这篇文 ...
- HTTP响应头拆分/CRLF注入详解
转自:https://blog.csdn.net/gstormspire/article/details/8183598 https://blog.csdn.net/cqf539/article/de ...
- [JAVA]使用字节流拷贝文件
import java.io.*; /** * @Description: * @projectName:JavaTest * @see:PACKAGE_NAME * @author:郑晓龙 * @c ...
- 数据可视化基础专题(六):Pandas基础(五) 索引和数据选择器(查找)
1.序言 如何切片,切块,以及通常获取和设置pandas对象的子集 2.索引的不同选择 对象选择已经有许多用户请求的添加,以支持更明确的基于位置的索引.Pandas现在支持三种类型的多轴索引. .lo ...
- 爬虫页面解析 lxml 简单教程
一.与字符串的相互转换 1.字符串转变为etree 对象 import lxml.html tree = lxml.html.fromstring(content) # content 字符串对象 2 ...