selenium上手
功能自动化
前提
- 自动化的主要目的并不是为了找Bug,是为了证明功能可用
- 不只是所有的功能都可以自动化,如UI
- 并不是所有的项目都可以使用自动化,如selenium只能使用bs项目,小项目不适合使用自动化
- 自动化在手动测试后
- 在软件版本还没有稳定的情况下,千万不要开展自动化
自动化的局限性
- 定制性项目
- 周期很短的项目
- 人体感官与易用性测试
- 涉及物理交互
- 发现缺陷少
- 维护成本高
- 可能会制约软件开发
- 不能灵活处理意外
selenium
selenium: B/S软件功能自动化
IDE: 录制、回放【不会自动打开浏览器】
webdriver: 支持多语言的类库方法
Python 3.4 selenium:2.53.6 firefox: 46
IDE
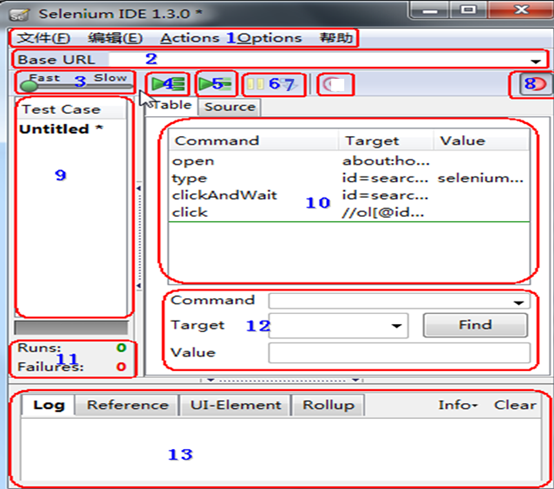
1、 文件:创建、打开和保存测试案例和测试案例集。
编辑:复制、粘贴、删除、撤销和选择测试案例中的所有命令。
Options :用于设置seleniunm IDE。
2、用来填写被测网站的地址。
3、速度控制:控制案例的运行速度。
4、运行所有:运行一个测试案例集中的所有案例。
5、运行:运行当前选定的测试案例。
6、暂停/恢复:暂停和恢复测试案例执行。
7、单步:可以运行一个案例中的一行命令。
8、录制:点击之后,开始记录你对浏览器的操作。
9、案例集列表。
10、测试脚本;table标签:用表格形式展现命令及参数。source标签:用原始方式展现,默认是HTML语言格式,也可以用其他语言展示。
11、查看脚本运行通过/失败的个数。
12、当选中前命令对应参数。
13、日志/参考/UI元素/Rollup
webdriver
定位方式
id:html标签的id属性值
name:html标签的name属性值
CSS:css样式选择器 # id选择器
xpath:通过标签在html页面源码路径
绝对路径:/html/body/table/tr/td[2]/input
相对路径:.//input[@aa="abc"]
.//标签名[@属性名="属性值"]
.//*[@aa="abc"]
.//*[@属性名="属性值"]
link:通过超链接标签内容
identifier:优先id的,如果没有再去找name的
js:dom=document.getElementById(“password”)
class:class=
dd=webdriver.Firefox() 打开浏览器
dd.get("url") :打开url对应页面
webdriver:
dd.find_element_by_id("html标签的id属性值")
dd.find_element_by_name("html标签的name属性值")
dd.find_element_by_css_selector("html标签的css样式选择器")
dd.find_element_by_xpath("html标签的xpath路径")
dd.find_element_by_link_text("超链接标签内容")
dd.find_element_by_tag_name("html标签名")
dd.find_element_by_class_name("html的class属性值")
操作:
文本框,密码框,文本域:
清空:dd.find_element_by_....(....).clear()
输入:dd.find_element_by_....(....).send_keys("输入内容")
单选按钮,复选框,超链接,按钮:
点击:dd.find_element_by_....(....).click()
下拉框:
选择:
Select(定位到的一个具体的下拉框).select_by_value("option的value属性值")
切焦点到frame/iframe:
dd.switch_to_frame("frame的id/name属性值")
dd.switch_to.frame("frame的id/name属性值")
当页面有刷新或者有跳转,需要加等待时间
time.sleep(数字秒)
selenium上手的更多相关文章
- Selenium 上手:Selenium扫盲区
Selenium 自述Selenium 是由Jason Huggins软件工程师编写的一个开源的浏览器自动化测试框架.主要用于测试自动化Web UI应用程序. Selenium 工作原理通过编程语言( ...
- selenium js
这几天的任务量比较大,还有一个挺棘手的网站cfda,不巧的是数据量还挺大,40W关于企业信息.上来就是debugger pause,调试中断,开始还是挺懵逼的,但这个还算简单毕竟google,百度,就 ...
- 京东前端:PhantomJS 和NodeJS在网站前端监控平台的最佳实践
1. 为什么需要一个前端监控系统 通常在一个大型的 Web 项目中有很多监控系统,比如后端的服务 API 监控,接口存活.调用.延迟等监控,这些一般都用来监控后台接口数据层面的信息.而且对于大型网站系 ...
- SeleniumIDE从0到1 (Selenium IDE 安装)
换了工作后需要学习到自动化测试,经过一系列的筛选,最终选定了Selenium,原因是因为本人熟悉一点代码,用Selenium比较容易上手.刚开始接触Selenium的小伙伴是不是会觉得不知道从何动手呢 ...
- selenium 基本的键盘方法
今晚不想加班,于是赶紧回来看看书: 1.下了selenium的小工具:FireBug/FirePath. 2.确定了看书顺序,我觉得难度低点开始比较好,所以我还是先看基于Python的selenium ...
- Selenium Web 自动化 - 项目实战(三)
Selenium Web 自动化 - 项目实战(三) 2016-08-10 目录 1 关键字驱动概述2 框架更改总览3 框架更改详解 3.1 解析新增页面目录 3.2 解析新增测试用例目录 3. ...
- 【Robot Framework】robot framework 学习以及selenium、appnium、requests实践(一)
话说之前自己写了个selenium的自动化框架,然后又研究了下RF,觉得RF这种基于关键字驱动的框架更为容易上手,当然在做一些比较繁琐的验证时,似乎还不是太灵活,不如自己写几行python来的实惠(也 ...
- Selenium简单介绍
WEB自动化测试:指WEB应用系统从用户界面层面进行的自动化测试.通过用户界面测试内部的业务逻辑. 自身特点:(一)WEB页面上出现的元素有可能具有不确定性: (二)不同操作系统上不同WEB浏览器之间 ...
- 使用python selenium进行自动化functional test
Why Automation Testing 现在似乎大家都一致认同一个项目应该有足够多的测试来保证功能的正常运作,而且这些此处的‘测试’特指自动化测试:并且大多数人会认为如果还有哪个项目依然采用人工 ...
随机推荐
- Dropzone.js文件拖拽上传提示Dropzone already attached 解决
最近收到客户的反馈,在操作上传文件有时会出现没有任何.大部分时间是正常. 重现问题后,f12打开后台控制台发现如下提示: Uncaught Error: Dropzone already attach ...
- (转)交叉编译lrzsz
交叉编译lrzsz 2016-03-20 1. 系统环境: Distributor ID: Ubuntu Description: Ubuntu 14.04.1 LTS Release: ...
- Vulhub Docker环境部署
1:安装Linux 2:安装Docker : curl -s https://get.docker.com/ | sh 3:安装Docker-compose curl -s https://boots ...
- JDBC的开发步骤
一.JDBC概述 JDBC(Java Data Base Connectivity,java数据库连接)是一种用于执行SQL语句的Java API,可以为多种关系数据库提供统一访问, 它由一组用Jav ...
- Java—构造方法及this/super/final/static关键字
构造方法 构建创造时用的方法,即就是对象创建时要执行的方法. //构造方法的格式: 修饰符 构造方法名(参数列表) { } 构造方法的体现: 构造方法没有返回值类型.也不需要写返回值.因为它是为构建对 ...
- java循环语句for与无限循环
一 for循环 for循环语句是最常用的循环语句,一般用在循环次数已知的情况下. 格式: for(初始化表达式; 循环条件; 操作表达式){ 执行语句 ……… } 循环流程: for(① ; ② ; ...
- C++实现哈夫曼编码/译码器(数据结构)
设计一个哈夫曼编码.译码系统.对一个ASCII编码的文本文件中的字符进行哈夫曼编码,生成编码文件:反过来,可将编码文件译码还原为一个文本文件.(1) 从文件中读入任意一篇英文短文(文件为ASCII编码 ...
- C#LeetCode刷题之#674-最长连续递增序列( Longest Continuous Increasing Subsequence)
问题 该文章的最新版本已迁移至个人博客[比特飞],单击链接 https://www.byteflying.com/archives/3734 访问. 给定一个未经排序的整数数组,找到最长且连续的的递增 ...
- 用python爬取B站在线用户人数
最近在自学Python爬虫,所以想练一下手,用python来爬取B站在线人数,应该可以拿来小小分析一下 设计思路 首先查看网页源代码,找到相应的html,然后利用各种工具(BeautifulSoup或 ...
- java.util.Scanner中hasNext()方法和next()方法的区别
先说结论: 两者均根据空格划分数据 两者在没有数据输入时均会等待输入 next()方法会将空格划分的数据依次输出,运行一次,输出一个 hasNext()方法会跟着next()方法移动,当前数据不为空, ...