Python爬虫实战 批量下载高清美女图片
彼岸图网站里有大量的高清图片素材和壁纸,并且可以免费下载,读者也可以根据自己需要爬取其他类型图片,方法是类似的,本文通过python爬虫批量下载网站里的高清美女图片,熟悉python写爬虫的基本方法:发送请求、获取响应、解析并提取数据、保存到本地。
很多人学习python,不知道从何学起。
很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手。
很多已经做案例的人,却不知道如何去学习更加高深的知识。
那么针对这三类人,我给大家提供一个好的学习平台,免费领取视频教程,电子书籍,以及课程的源代码!
QQ群:101677771
目标url:http://pic.netbian.com/4kmeinv/index.html
1. 爬取一页的图片
正则匹配提取图片数据
网页源代码部分截图如下:
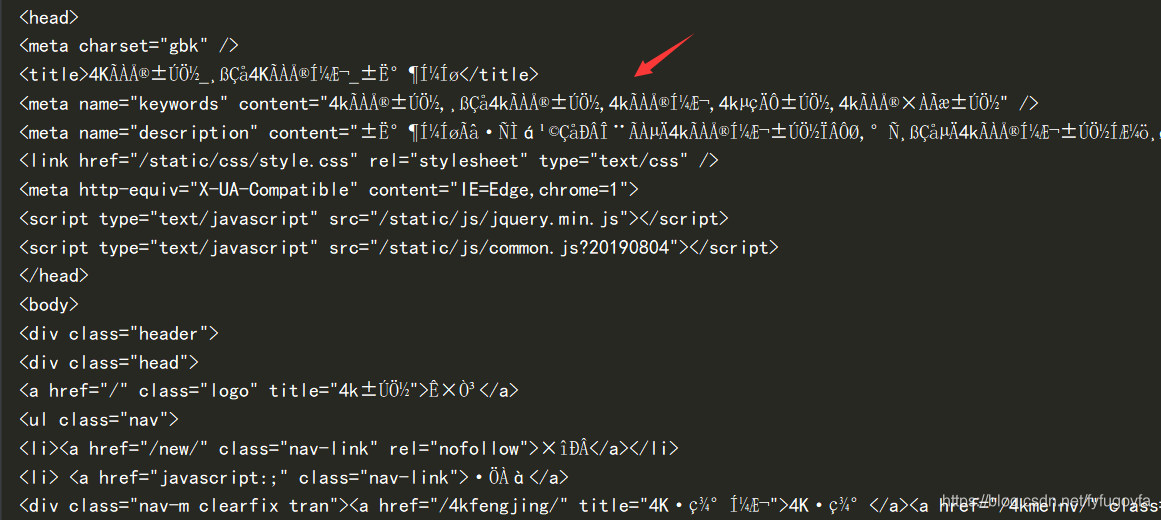
重新设置GBK编码解决了乱码问题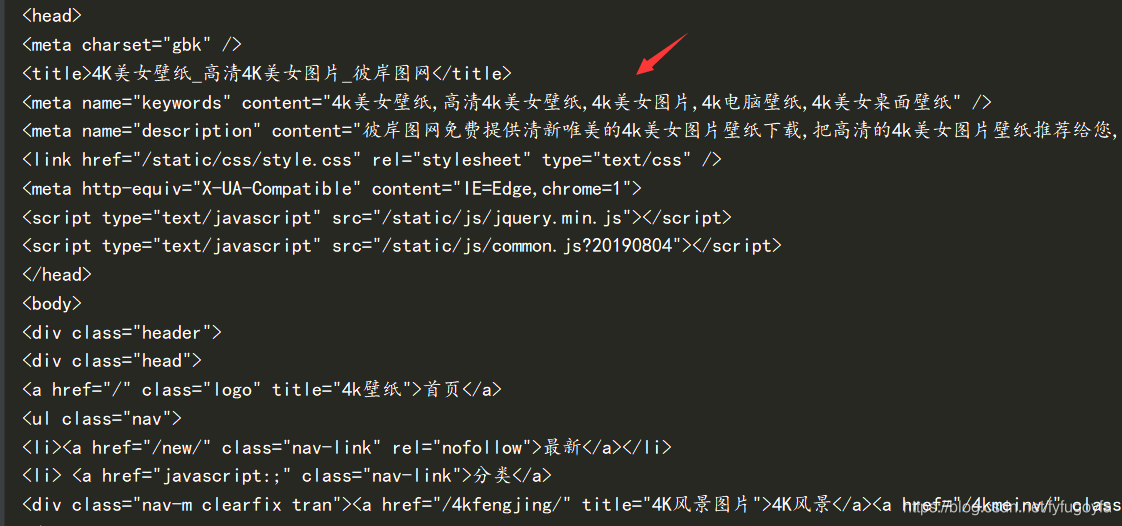
代码实现:
import requests
import re
# 设置保存路径
path = r'D:\test\picture_1\ '
# 目标url
url = "http://pic.netbian.com/4kmeinv/index.html"
# 伪装请求头 防止被反爬
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Referer": "http://pic.netbian.com/4kmeinv/index.html"
}
# 发送请求 获取响应
response = requests.get(url, headers=headers)
# 打印网页源代码来看 乱码 重新设置编码解决编码问题
# 内容正常显示 便于之后提取数据
response.encoding = 'GBK'
# 正则匹配提取想要的数据 得到图片链接和名称
img_info = re.findall('img src="(.*?)" alt="(.*?)" /', response.text)
for src, name in img_info:
img_url = 'http://pic.netbian.com' + src # 加上 'http://pic.netbian.com'才是真正的图片url
img_content = requests.get(img_url, headers=headers).content
img_name = name + '.jpg'
with open(path + img_name, 'wb') as f: # 图片保存到本地
print(f"正在为您下载图片:{img_name}")
f.write(img_content)
Xpath定位提取图片数据
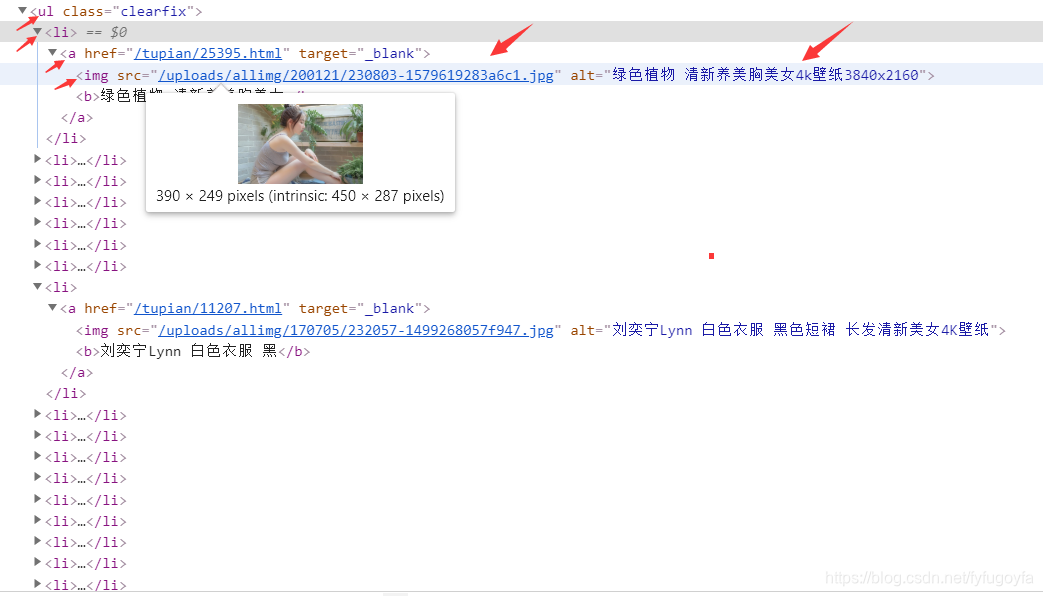
检查分析网页可以找到图片的链接和名称的Xpath路径,写出xpath表达式定位提取出想要的图片数据,但得到的每个图片的src前面需要都加上 ‘http://pic.netbian.com’ 得到的才是图片真正的url,可以用列表推导式一行代码实现。
代码实现:
import requests
from lxml import etree
# 设置保存路径
path = r'D:\test\picture_1\ '
# 目标url
url = "http://pic.netbian.com/4kmeinv/index.html"
# 伪装请求头 防止被反爬
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Referer": "http://pic.netbian.com/4kmeinv/index.html"
}
# 发送请求 获取响应
response = requests.get(url, headers=headers)
# 打印网页源代码来看 乱码 重新设置编码解决编码问题
# 内容正常显示 便于之后提取数据
response.encoding = 'GBK'
html = etree.HTML(response.text)
# xpath定位提取想要的数据 得到图片链接和名称
img_src = html.xpath('//ul[@class="clearfix"]/li/a/img/@src')
# 列表推导式 得到真正的图片url
img_src = ['http://pic.netbian.com' + x for x in img_src]
img_alt = html.xpath('//ul[@class="clearfix"]/li/a/img/@alt')
for src, name in zip(img_src, img_alt):
img_content = requests.get(src, headers=headers).content
img_name = name + '.jpg'
with open(path + img_name, 'wb') as f: # 图片保存到本地
print(f"正在为您下载图片:{img_name}")
f.write(img_content)
2.翻页爬取,实现批量下载
手动翻页分析规律
第一页:http://pic.netbian.com/4kmeinv/index.html
第二页:http://pic.netbian.com/4kmeinv/index_2.html
第三页:http://pic.netbian.com/4kmeinv/index_3.html
最后一页:http://pic.netbian.com/4kmeinv/index_161.html
分析发现除第一页比较特殊,之后的页面都有规律,可以用列表推导式生成url列表,遍历url列表里的链接,进行请求,可实现翻页爬取图片。
单线程版
import requests
from lxml import etree
import datetime
import time
# 设置保存路径
path = r'D:\test\picture_1\ '
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1",
"Referer": "http://pic.netbian.com/4kmeinv/index.html"
}
start = datetime.datetime.now()
def get_img(urls):
for url in urls:
# 发送请求 获取响应
response = requests.get(url, headers=headers)
# 打印网页源代码来看 乱码 重新设置编码解决编码问题
# 内容正常显示 便于之后提取数据
response.encoding = 'GBK'
html = etree.HTML(response.text)
# xpath定位提取想要的数据 得到图片链接和名称
img_src = html.xpath('//ul[@class="clearfix"]/li/a/img/@src')
# 列表推导式 得到真正的图片url
img_src = ['http://pic.netbian.com' + x for x in img_src]
img_alt = html.xpath('//ul[@class="clearfix"]/li/a/img/@alt')
for src, name in zip(img_src, img_alt):
img_content = requests.get(src, headers=headers).content
img_name = name + '.jpg'
with open(path + img_name, 'wb') as f: # 图片保存到本地
# print(f"正在为您下载图片:{img_name}")
f.write(img_content)
time.sleep(1)
def main():
# 要请求的url列表
url_list = ['http://pic.netbian.com/4kmeinv/index.html'] + [f'http://pic.netbian.com/4kmeinv/index_{i}.html' for i in range(2, 11)]
get_img(url_list)
delta = (datetime.datetime.now() - start).total_seconds()
print(f"抓取10页图片用时:{delta}s")
if __name__ == '__main__':
main()
程序运行成功,抓取了10页的图片,共210张,用时63.682837s。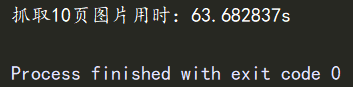
多线程版
import requests
from lxml import etree
import datetime
import time
import random
from concurrent.futures import ThreadPoolExecutor
# 设置保存路径
path = r'D:\test\picture_1\ '
user_agent = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]
start = datetime.datetime.now()
def get_img(url):
headers = {
"User-Agent": random.choice(user_agent),
"Referer": "http://pic.netbian.com/4kmeinv/index.html"
}
# 发送请求 获取响应
response = requests.get(url, headers=headers)
# 打印网页源代码来看 乱码 重新设置编码解决编码问题
# 内容正常显示 便于之后提取数据
response.encoding = 'GBK'
html = etree.HTML(response.text)
# xpath定位提取想要的数据 得到图片链接和名称
img_src = html.xpath('//ul[@class="clearfix"]/li/a/img/@src')
# 列表推导式 得到真正的图片url
img_src = ['http://pic.netbian.com' + x for x in img_src]
img_alt = html.xpath('//ul[@class="clearfix"]/li/a/img/@alt')
for src, name in zip(img_src, img_alt):
img_content = requests.get(src, headers=headers).content
img_name = name + '.jpg'
with open(path + img_name, 'wb') as f: # 图片保存到本地
# print(f"正在为您下载图片:{img_name}")
f.write(img_content)
time.sleep(random.randint(1, 2))
def main():
# 要请求的url列表
url_list = ['http://pic.netbian.com/4kmeinv/index.html'] + [f'http://pic.netbian.com/4kmeinv/index_{i}.html' for i in range(2, 51)]
with ThreadPoolExecutor(max_workers=6) as executor:
executor.map(get_img, url_list)
delta = (datetime.datetime.now() - start).total_seconds()
print(f"爬取50页图片用时:{delta}s")
if __name__ == '__main__':
main()
程序运行成功,抓取了50页图片,共1047张,用时56.71979s。开多线程大大提高的爬取数据的效率。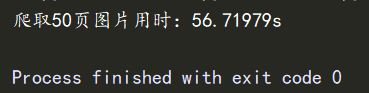
最终成果如下:
3. 其他说明
- 本文仅用于python爬虫知识交流,勿作其他用途,违者后果自负。
- 不建议抓取太多数据,容易对服务器造成负载,浅尝辄止即可。
Python爬虫实战 批量下载高清美女图片的更多相关文章
- 利用python爬虫关键词批量下载高清大图
前言 在上一篇写文章没高质量配图?python爬虫绕过限制一键搜索下载图虫创意图片!中,我们在未登录的情况下实现了图虫创意无水印高清小图的批量下载.虽然小图能够在一些移动端可能展示的还行,但是放到pc ...
- 【Python爬虫程序】抓取MM131美女图片,并将这些图片下载到本地指定文件夹。
一.项目名称 抓取MM131美女写真图片,并将这些图片下载到本地指定文件夹. 共有6种类型的美女图片: 性感美女 清纯美眉 美女校花 性感车模 旗袍美女 明星写真 抓取后的效果图如下,每个图集是一个独 ...
- Python爬虫之多线程下载豆瓣Top250电影图片
爬虫项目介绍 本次爬虫项目将爬取豆瓣Top250电影的图片,其网址为:https://movie.douban.com/top250, 具体页面如下图所示: 本次爬虫项目将分别不使用多线程和使 ...
- python爬虫实战(二)--------千图网高清图
相关代码已经修改调试----2017-3-21 实现:千图网上高清图片的爬取 程序运行20小时,爬取大约162000张图片,一共49G,存入百度云.链接:http://pan.baidu.com/s/ ...
- python爬虫实战——5分钟做个图片自动下载器
python爬虫实战——图片自动下载器 制作爬虫的基本步骤 顺便通过这个小例子,可以掌握一些有关制作爬虫的基本的步骤. 一般来说,制作一个爬虫需要分以下几个步骤: 分析需求(对,需求分析非常重要, ...
- 【图文详解】python爬虫实战——5分钟做个图片自动下载器
python爬虫实战——图片自动下载器 之前介绍了那么多基本知识[Python爬虫]入门知识,(没看的先去看!!)大家也估计手痒了.想要实际做个小东西来看看,毕竟: talk is cheap sho ...
- Python静态网页爬取:批量获取高清壁纸
前言 在设计爬虫项目的时候,首先要在脑内明确人工浏览页面获得图片时的步骤 一般地,我们去网上批量打开壁纸的时候一般操作如下: 1.打开壁纸网页 2.单击壁纸图(打开指定壁纸的页面) 3.选择分辨率(我 ...
- 《Python金融大数据分析》高清PDF版|百度网盘免费下载|Python数据分析
<Python金融大数据分析>高清PDF版|百度网盘免费下载|Python数据分析 提取码:mfku 内容简介 唯一一本详细讲解使用Python分析处理金融大数据的专业图书:金融应用开发领 ...
- 《精通Python网络爬虫》|百度网盘免费下载|Python爬虫实战
<精通Python网络爬虫>|百度网盘免费下载|Python爬虫实战 提取码:7wr5 内容简介 为什么写这本书 网络爬虫其实很早就出现了,最开始网络爬虫主要应用在各种搜索引擎中.在搜索引 ...
随机推荐
- Qt自定义控件之仪表盘3--雷达扫描图
1.设计思想 雷达扫描图,在影视作品中见到较多,比如飞机雷达.舰艇雷达,有一个扫描线转圈代表雷达一周旋转或一个批次的收发,发现目标就在表盘上标记位置.和汽车仪表盘类似,汽车仪表盘有底盘背景图.同圆.刻 ...
- ios 富文本 加颜色 删除线
UILabel *valueL = [JAppViewTools getLabel:CGRectMake(JFWidth(15), CGRectGetMaxY(proName.frame)+JFWid ...
- Weighted-Residual-Connections
- Eclipse开发Android项目报错解决方案详细教程,最新版一篇就够了!
本文记录刚接触Android开发搭建环境后新建工程各种可能的报错,并亲身经历漫长的解决过程(╥╯^╰╥),寻找各种偏方,避免大家采坑,希望能帮助到大家. 报错信息 出错一:The import and ...
- 08 vi全屏文本编辑器
打开文件vim /path/to/somefilevim +# :打开文件,并定位于第#行(如下的 vi +33 profile) vim +:打开文件,定位至最后一行vim +/PATTERN : ...
- 【LeetCode/LintCode】 题解丨微软面试题:大楼轮廓
水平面上有 N 座大楼,每座大楼都是矩阵的形状,可以用一个三元组表示 (start, end, height),分别代表其在x轴上的起点,终点和高度.大楼之间从远处看可能会重叠,求出 N 座大楼的外轮 ...
- C#LeetCode刷题之#155-最小栈(Min Stack)
问题 该文章的最新版本已迁移至个人博客[比特飞],单击链接 https://www.byteflying.com/archives/4020 访问. 设计一个支持 push,pop,top 操作,并能 ...
- Kinect+unity 实现体感格斗闯关小游戏
文章目录 项目地址 1 项目概况 1.1 项目简介 1.2 项目目的 1.3 主要技术 2 设计 2.1 基本概念 2.2 框架 2.3 算法 2.4 模型 2.5 调查问卷 3 实现 3.1 技术难 ...
- three.js 着色器材质内置变量
这篇郭先生说一下three.js着色器的内置变量,分别是 gl_PointSize:在点渲染模式中,控制方形点区域渲染像素大小(注意这里是像素大小,而不是three.js单位,因此在移动相机是,所看到 ...
- node.js 出现server instance pool was destroyed
初步判断为MongodbClient断开连接的原因. 之所以断开连接,可能是多个操作间隔时间比较久. 解决方法之一,不要调用close方法.