【机器学习 Azure Machine Learning】Azure Machine Learning 访问SQL Server 无法写入问题 (使用微软Python AML Core SDK)
问题情形
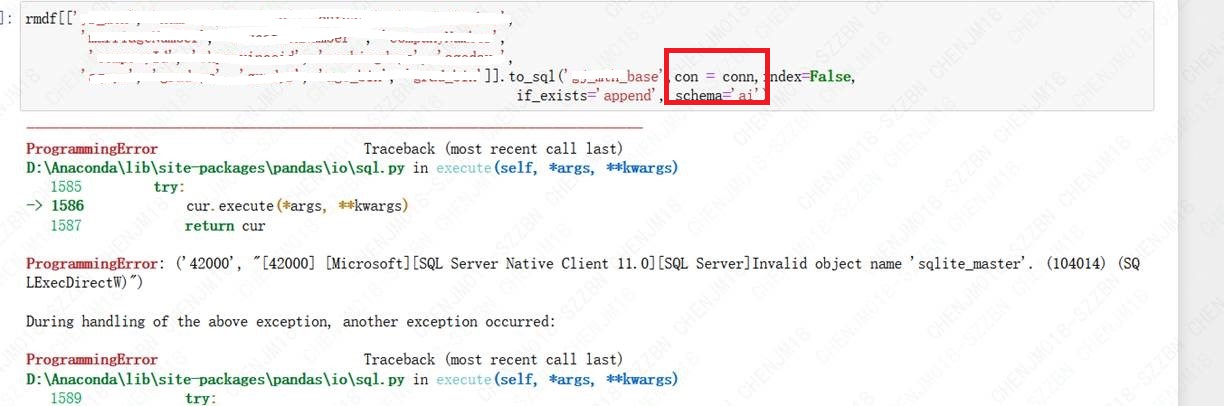
使用Python SDK在连接到数据库后,连接数据库获取数据成功,但是在Pandas中用 to_sql 反写会数据库时候报错。错误信息为:ProgrammingError: ('42000', "[42000] [Microsoft][SQL Server Native Client 11.0][SQL Server]Invalid object name 'sqlite_master'. (104014) (SQLExecDirectW)")。
出错代码片段:
import pyodbc
import itertools
import sys
from sqlalchemy import create_engine
import urllib
import scipy.stats as stats conn = pyodbc.connect(r'DRIVER={SQL Server Native Client 11.0};SERVER=database.database.chinacloudapi.cn;DATABASE=db;UID=user;PWD=pwd') rmdf[[‘']].to_sql('xxxx_base',con = conn,index=False, if_exists='append', schema='ai')
错误截图:
详细日志
ActivityCompleted: Activity=to_pandas_dataframe, HowEnded=Failure, Duration=672.71 [ms], Info =
{'activity_id': 'e850f767-0c12-4864-8d01-d11dc5817ec9', 'activity_name': 'to_pandas_dataframe', 'activity_type': 'PublicApi', 'app_name': 'TabularDataset',
'source': 'azureml.dataset', 'version': '1.0.76', 'completionStatus': 'Success', 'durationMs': 6.05},
Exception=DatasetExecutionError; Could not connect to specified database.|session_id=f648402f-f619-469d-a6f4-aee7031bd438
---------------------------------------------------------------------------
ExecutionError Traceback (most recent call last) /anaconda/envs/azureml_py36/lib/python3.6/site-packages/azureml/data/dataset_error_handling.py in _try_execute(action, **kwargs) 82 else:
---> 83 return action() 84 except Exception as e: /anaconda/envs/azureml_py36/lib/python3.6/site-packages/azureml/dataprep/api/_loggerfactory.py in wrapper(*args, **kwargs) 130 try:
--> 131 return func(*args, **kwargs) 132 except Exception as e: /anaconda/envs/azureml_py36/lib/python3.6/site-packages/azureml/dataprep/api/dataflow.py
in to_pandas_dataframe(self, extended_types, nulls_as_nan) 676 self._engine_api.execute_anonymous_activity(
--> 677 ExecuteAnonymousActivityMessageArguments(anonymous_activity=Dataflow._dataflow_to_anonymous_activity_data(dataflow_to_execute)))
678 /anaconda/envs/azureml_py36/lib/python3.6/site-packages/azureml/dataprep/api/_aml_helper.py in wrapper(op_code, message, cancellation_token)
37 engine_api_func().update_environment_variable(changed)
---> 38 return send_message_func(op_code, message, cancellation_token) 39 /anaconda/envs/azureml_py36/lib/python3.6/site-packages/azureml/dataprep/api/engineapi/api.py
in execute_anonymous_activity(self, message_args, cancellation_token) 93
def execute_anonymous_activity(self, message_args: typedefinitions.ExecuteAnonymousActivityMessageArguments, cancellation_token: CancellationToken = None) -> None:
---> 94 response = self._message_channel.send_message('Engine.ExecuteActivity', message_args, cancellation_token)
95 return response /anaconda/envs/azureml_py36/lib/python3.6/site-packages/azureml/dataprep/api/engineapi/engine.py
in send_message(self, op_code, message, cancellation_token) 118 if 'error' in response:
--> 119 raise_engine_error(response['error']) 120 elif response.get('id') == message_id: /anaconda/envs/azureml_py36/lib/python3.6/site-packages/azureml/dataprep/api/errorhandlers.py
in raise_engine_error(error_response) 21 if 'ActivityExecutionFailed' in error_code:
---> 22 raise ExecutionError(error_response) 23 elif 'UnableToPreviewDataSource' in error_code: ExecutionError: Could not connect to specified database.
|session_id=f648402f-f619-469d-a6f4-aee7031bd438 During handling of the above exception, another exception occurred:
DatasetExecutionError Traceback (most recent call last) <ipython-input-7-7f54b930998f> in <module>
----> 1 dataset.to_pandas_dataframe() /anaconda/envs/azureml_py36/lib/python3.6/site-packages/azureml/data/_loggerfactory.py in wrapper(*args, **kwargs) 76
with _LoggerFactory.track_activity(logger, func.__name__, activity_type, custom_dimensions) as al: 77 try:
---> 78 return func(*args, **kwargs) 79 except Exception as e: 80 if hasattr(al, 'activity_info')
and hasattr(e, 'error_code'): /anaconda/envs/azureml_py36/lib/python3.6/site-packages/azureml/data/tabular_dataset.py
in to_pandas_dataframe(self) 138 """ 139 dataflow = get_dataflow_for_execution(self._dataflow, 'to_pandas_dataframe', 'TabularDataset')
--> 140 df = _try_execute(dataflow.to_pandas_dataframe) 141 return df
142 /anaconda/envs/azureml_py36/lib/python3.6/site-packages/azureml/data/dataset_error_handling.py in _try_execute(action, **kwargs)
83 return action() 84 except Exception as e:
---> 85 raise DatasetExecutionError(str(e)) DatasetExecutionError: Could not connect to specified database.|session_id=f648402f-f619-469d-a6f4-aee7031bd438
问题原因
根据代码判断,问题是在to_sql方法中使用的con对象的问题,此处需要使用的是由 sqlalchemy所创建的 create_engine对象,而不能使用 pyodbc的conn对象。 同时也必须根据环境选择正确的DB驱动。如Windows环境中,则可以使用'Driver={SQL Server};',而在Linux中,则可以使用DRIVER={SQL Server Native Client 11.0};
错误的连接对象:
import pyodbc
conn = pyodbc.connect(r'DRIVER={SQL Server Native Client 11.0};SERVER=xxxx.database.chinacloudapi.cn;DATABASE=xx;UID=xx;PWD=')
正确的SQL连接对象:
from sqlalchemy import create_engine
engine = create_engine('mssql+pyodbc://%s:%s@%s/%s?driver=SQL Server' % (
'user name',
'pwd',
'<service name>.database.chinacloudapi.cn',
#cf.ju_db_post,
'DB Name'
),connect_args={'charset':'utf8'})
解决方案
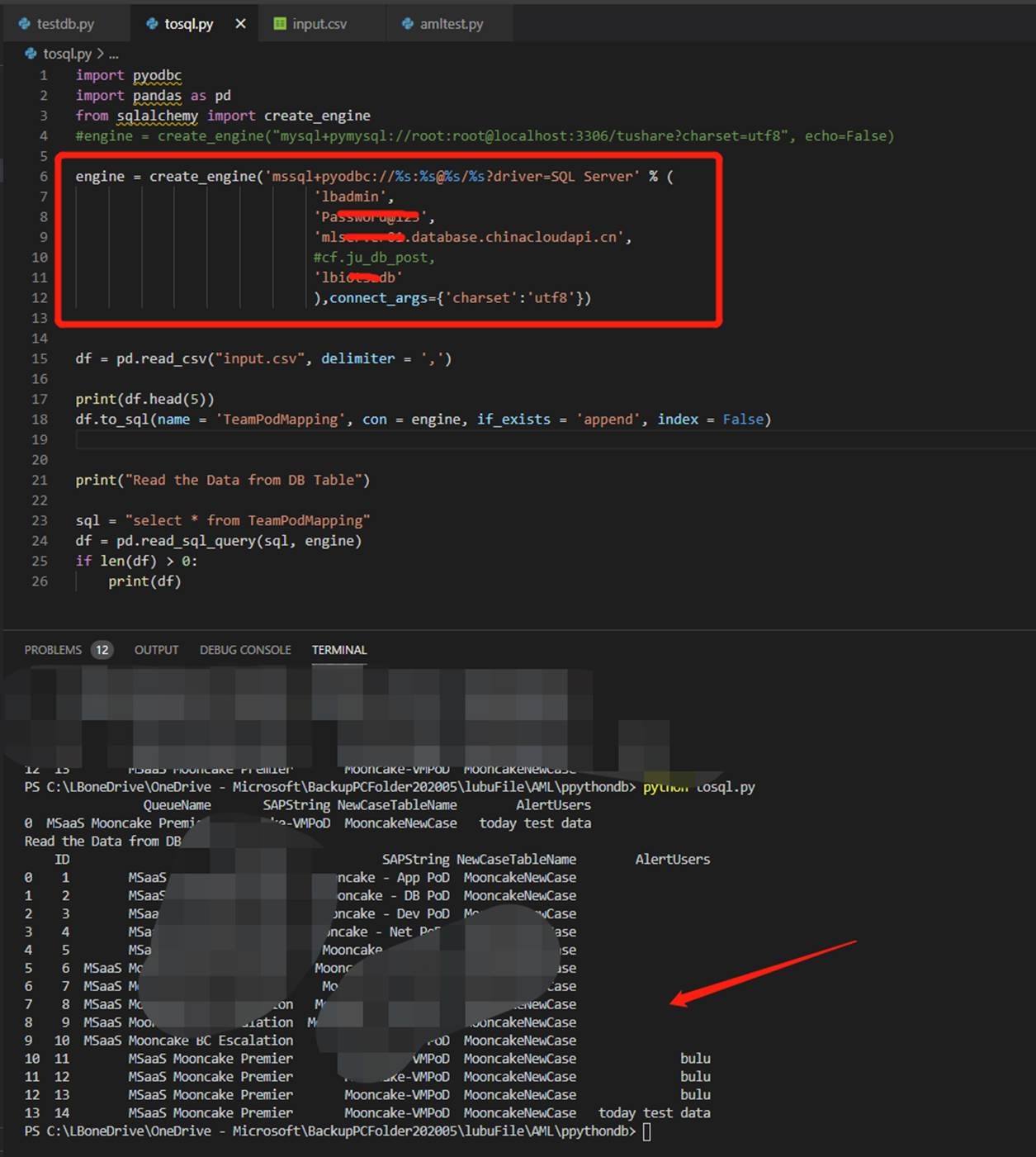
使用Create_engine创建engine并且使用在to_sql方法中,具体代码如下图:
注意:如出现类似错误消息是“Error: ('01000', "[01000] [unixODBC][Driver Manager]Can't open lib 'SQL Server' : file not found (0) (SQLDriverConnect)")”,则需要检查当前VM中的ODBC Driver。
参考资料:
pandas.DataFrame.to_sql:https://pandas.pydata.org/pandas-docs/version/0.23.4/generated/pandas.DataFrame.to_sql.html
【机器学习 Azure Machine Learning】Azure Machine Learning 访问SQL Server 无法写入问题 (使用微软Python AML Core SDK)的更多相关文章
- SQL Azure (14) 将云端SQL Azure中的数据库备份到本地SQL Server
<Windows Azure Platform 系列文章目录> 注意: 1.只有SQL Server 2012 CU4及以上版本才支持本章内容 2.当你的数据库文件很大时,建议优化以下内容 ...
- EF 数据库连接字符串-集成安全性访问 SQL Server
使用 Windows 集成安全性访问 SQL Server 如果您的应用程序运行在基于 Windows 的 Intranet 上,则也许可以将 Windows 集成身份验证用于数据库访问.集成安全性使 ...
- ORACLE透明网关访问SQL Server配置总结
透明网关概念 ORACLE透明网关(Oracle Transparent Gateway)可以解决ORACLE数据库和非ORACLE数据库交互数据的需求.在一个异构的分布式环境中,通过ORACLE ...
- Ubuntu12.10下Python(pyodbc)访问SQL Server解决方案
一.基本原理 请查看这个网址,讲得灰常详细:http://www.jeffkit.info/2010/01/476/ 二.实现步骤 1.安装linux下SQL Server的驱动程序 安装Free ...
- .NET跨平台之旅:升级至ASP.NET 5 RC1,Linux上访问SQL Server数据库
今天微软正式发布了ASP.NET 5 RC1(详见Announcing ASP.NET 5 Release Candidate 1),.NET跨平台迈出了关键一步. 紧跟这次RC1的发布,我们成功地将 ...
- ODBC database driver for Go:Go语言通过ODBC 访问SQL server
Go语言通过ODBC 访问SQL server,这里需要用到go-odbc库,开源地址::https://github.com/weigj/go-odbc 一.驱动安装 在cmd中打开GOPATH: ...
- 在oracle中通过链接服务器(dblink)访问sql server
在oracle中通过链接服务器(dblink)访问sql server 2013-10-16 一. 工作环境: <1> Oracle数据库版本:Oracle 11g 运行环境 :IB ...
- Oracle Gateways透明网关访问SQL Server
自己的本机安装了Oracle 12c,公司的平台需要同时支持Oracle与SQL Server,很多时候都有将数据从Oracle同步到SQL Server的需求.通过SQL Server的link S ...
- ADO.NET访问SQL Server调用存储过程带回参
1,ADO.NET访问SQL Server调用存储过程带回参 2,DatabaseDesign use northwind go --存储过程1 --插入一条商品 productname=芹菜 un ...
随机推荐
- 3.CDN加速简介
什么是CDN CDN的全称是Content Delivery Network,即内容分发网络.CDN的基本原理是广泛采用各种缓存服务器,将这些缓存服务器分布到用户访问相对集中的地区或网络中,在用户访问 ...
- [剑指Offer]57-和为s的数字
题目一 输入一个递增的数组和一个数字,在数组中查找2个数字,是他们的和正好为S,如果有多对的和为S,则输出任意一对即可. 题解 关键信息是数组有序.初始化i,j指向第一个和第二个数,与S比较,若小了, ...
- 微信小程序 | 模仿百思不得其姐
微信小程序 仿百思不得姐 设备 微信开发者工具 v1.02.1901230 扩展 修复了视频点击播放不流畅的问题 修复了视频的暂停够无法播放问题 优化了部分页面 接口 首页 http://api.bu ...
- C语言知识汇编
(20-) 1.局部变量:定义在大括号的变量是局部变量 作用域:从 定义变量到return或者遇到 } 结束为止 include <stdio.h> int main() { int nu ...
- vue 项目中实时请求接口 建立长连接
需求:在项目中需要每隔五秒请求一次接口 第一种方法:直接在mounted钩子函数中处理 mounted() { window.setInterval(() => { setTimeout(thi ...
- Spring Cloud Alibaba生态探索:Dubbo、Nacos及Sentinel的完美结合
@ 目录 背景 一.项目框架 1.1 采用IDEA和Maven多模块进行项目搭建 1.2 模块管理及版本管理 二.微服务公共接口 2.1 定义一个公共接口Api 2.2 pom.xml 2.3 Goo ...
- 联赛模拟测试5 涂色游戏 矩阵优化DP
题目描述 分析 定义出\(dp[i][j]\)为第\(i\)列涂\(j\)种颜色的方案数 然后我们要解决几个问题 首先是求出某一列涂恰好\(i\)种颜色的方案数\(d[i]\) 如果没有限制必须涂\( ...
- 并发编程(四)Thread类详解
一.引言 Thread类中存在着许多操作线程的方法,学习Thread类是非常有必要的,前面我们也嘘唏了创建线程的几种方式,若线程的创建不是以继承Thread类的方式创建的,那我们又改如何使用Threa ...
- 【云原生下离在线混部实践系列】深入浅出 Google Borg
Google Borg 是资源调度管理和离在线混部领域的鼻祖,同时也是 Kubernetes 的起源与参照,已成为从业人员首要学习的典范.本文尝试管中窥豹,简单从<Large-scale clu ...
- Docker 容器化部署 Python 应用
Docker 是一个开源项目,为开发人员和系统管理员提供了一个开放平台,可以将应用程序构建.打包为一个轻量级容器,并在任何地方运行.Docker 会在软件容器中自动部署应用程序. 在本篇中,我将介绍如 ...