图像分类学习:X光胸片诊断识别----迁移学习
引言
刚进入人工智能实验室,不知道是在学习机器学习还是深度学习,想来他俩可能是一个东西,查阅之后才知道这是两个领域,或许也有些交叉,毕竟我也刚接触,不甚了解。
在我还是个纯度小白之时,写下这篇文章,希望后来同现在的我一样,刚刚涉足此领域的同学能够在这,跨越时空,在小白与小白的交流中得到些许帮助。
开始
在只会一些python语法,其他啥都没有,第一周老师讲了一些机器学习和深度学习的了解性内容,就给了一个实验,让我们一周内弄懂并跑出来,其实老师的代码已经完成了,我们可以直接放进Pycharm里跑出来,但是代码细节并没有讲,俗话说师傅领进门,修行在个人。那就从最基本的开始,把这个代码弄懂,把实验理解。
下面我会先把整个代码贴出来,之后一步一步去分析每个模块,每个函数的作用。
说明
本实验来自此处博客,我们的实验也是基于这个博客的内容学习的。
一、数据集
数据源于kaggle,可在此链接自行下载
二、运行代码
三、解析
从头开始,先来看这段代码(注释进行解释):
# 进行一系列数据增强,然后生成训练(train)、验证(val)、和测试(test)数据集data_transforms = {'train': transforms.Compose([transforms.RandomResizedCrop(input_size),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),'val': transforms.Compose([transforms.Resize(input_size),transforms.CenterCrop(input_size),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),'test': transforms.Compose([transforms.Resize(input_size),transforms.CenterCrop(input_size),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}
这是一个字典数据类型,其中键分别为:train、val、test对应数据集里的三个文件夹train、val、test
键train对应的值是一个操作transfroms.Compose( [列表] )
参数为一个列表,列表中的元素为四个操作:
transforms.RandomResizedCrop()
transforms.RandomHorizontalFlip()
transforms.ToTensor
transforms.ToTensortransforms.Normalize()
transforms在torchvision中,一个图像处理包,可以通过它调用一些图像处理函数,对图像进行处理
transfroms.Compose( [列表] ):此函数存在于torchvision.transforms中,一般用Compose函数把多个步骤整合到一起
transforms.RandomResizedCrop(数字):将给定图像随机裁剪为不同的大小和宽高比,然后缩放所裁剪得到的图像为制定的大小;(即先随机采集,然后对裁剪得到的图像缩放为同一大小)
例如:
transforms.RandomHorizontalFlip():以给定的概率随机水平旋转给定的PIL的图像,默认为0.5;
例如:

transforms.ToTensor:将给定图像转为Tensor(一个数据类型,类似有深度的矩阵)
例如:
transforms.ToTensortransforms.Normalize():归一化处理
例如:
函数详细内容请查看此处文章
可以看出,这一块的代码就是定义一种操作集合,将一张图片进行剪裁、旋转、转为一种数据、数据归一化
继续往下看,相应的解释都在注释中
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x]) for x in['train', 'val', 'test']}dataloaders_dict = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=batch_size, shuffle=True, num_workers=0) for x in['train', 'val', 'test']}
首先是数据导入部分,这里采用官方写好的torchvision.datasets.ImageFolder接口实现数据导入。这个接口需要你提供图像所在的文件夹
x是字典的键,从后面的for迭代的范围中获取,有'train', 'val', 'test'三个值
datasets.ImageFolder(os.path.join(data_dir, x), data_transforms[x])高亮部分是数据集的文件夹路径,找到文件后,确定x,在执行第二个参数data_transforms[x],把x进行一些列处理
前面torchvision.datasets.ImageFolder只是返回列表,列表是不能作为模型输入的(我也不知道为什么),因此在PyTorch中需要用另一个类来封装列表,那就是:torch.utils.data.DataLoader
torch.utils.data.DataLoader类可以将列表类型的输入数据封装成Tensor数据格式,以备模型使用。
好,我们继续往下看
# 定义一个查看图片和标签的函数def imshow(inp, title=None):# transpose(0,1,2),0是x轴,1是y轴,2是z轴,由(0,1,2)变为(1,2,0)就是x和z轴先交换,x和y轴再交换inp = inp.numpy().transpose((1, 2, 0))mean = np.array([0.485, 0.456, 0.406]) # 创建一个数组[0.485, 0.456, 0.406]std = np.array([0.229, 0.224, 0.225]) # 同样也是创建一个数组inp = std * inp + mean # 调整图像尺寸大小等inp = np.clip(inp, 0, 1) # 小于0的都为0,大于1的都为1,之间的不变plt.imshow(inp) # 设置图像为灰色if title is not None: # 如果图像有标题则显示标题plt.title(title) # 设置图像标题plt.pause(0.001) # 窗口绘制后停留0.001秒imgs, labels = next(iter(dataloaders_dict['train'])) # 自动往下迭代参数对象out = torchvision.utils.make_grid(imgs[:8]) # 将8个图拼成一张图片classes = image_datasets['test'].classes # 每个图像的文件名# out是一个8个图片拼成的长图,经过imshow()处理后附加标题(图片文件名的前8个字母)输出# imshow(out, title=[classes[x] for x in labels[:8]])
输出后,在IDE中是这样的(右上角):
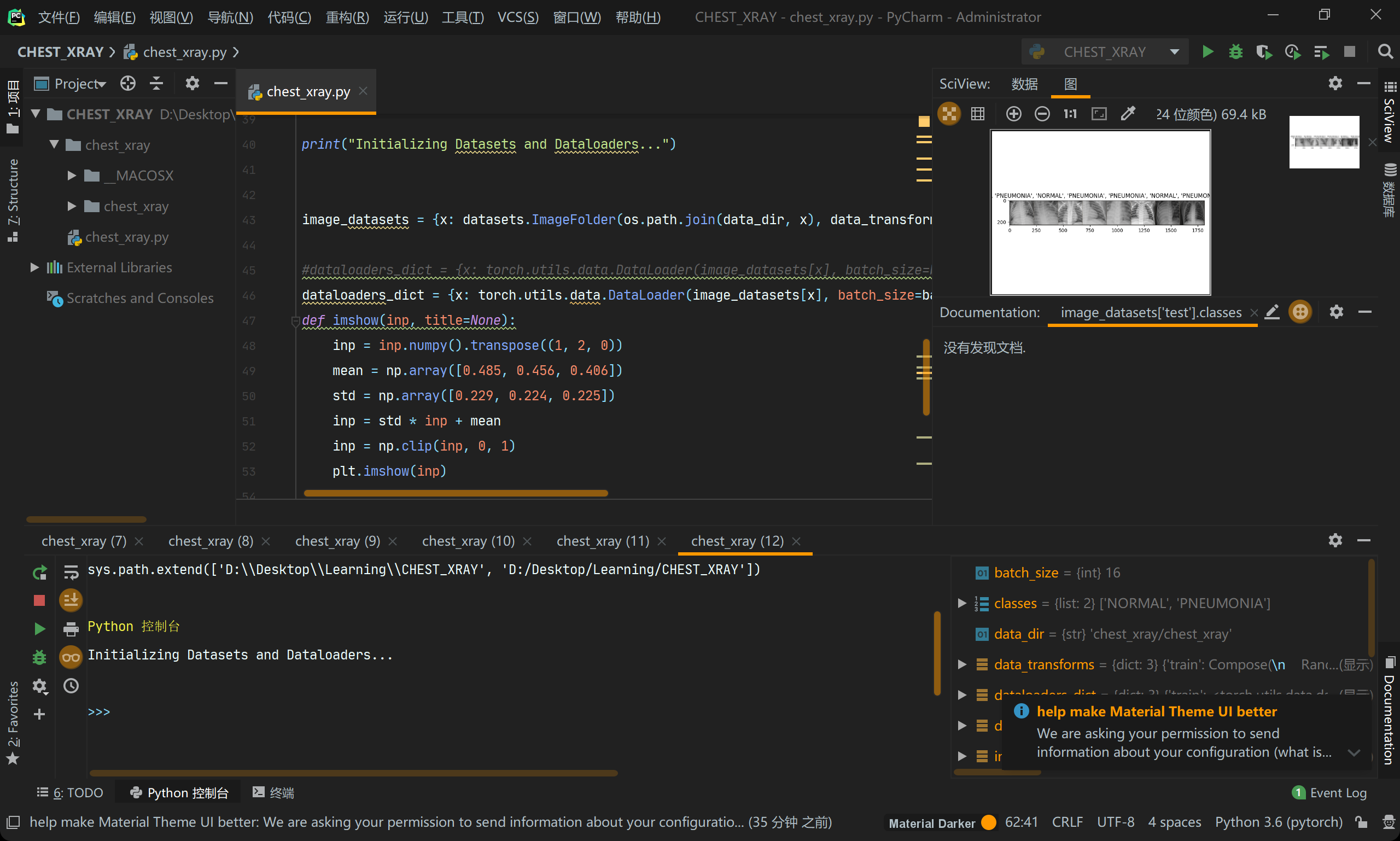
好,想在继续往下走
下面呢给出了四个训练模型,实战中我们只需要挑其中一个进行训练就好,其他的模型要注释掉,下面代码上四个模型我都会分析
# inception------------------------------------------------------inception模型,有趣的是它可以翻译为盗梦空间model = models.inception_v3(pretrained=True)# inception_v3是一个预训练模型, pretrained=True执行后会把模型下载到我们的电脑上model.aux_logits = False # 是否给模型创建辅助,具体增么个辅助太复杂,请观众老爷们自行谷歌num_fc_in = model.fc.in_features # 提取fc层固定的参数# 改变全连接层,2分类问题,out_features = 2model.fc = nn.Linear(num_fc_in, num_classes) # 修改fc层参数为num_classes = 4(最前面前面定义了)# alexnet--------------------------------------------------------alexnet模型model = models.alexnet(pretrained=True) # alexnet是一个预训练模型, pretrained=True执行后会把模型下载到我们的电脑上num_fc_in = model.classifier[6].in_features # 提取fc层固定的参数model.fc = torch.nn.Linear(num_fc_in, num_classes) # 修改fc层参数为num_classes = 4(最前面前面定义了)model.classifier[6] = model.fc#将图层初始化为model.fc#相当于model.classifier[6] = torch.nn.Linear(num_fc_in, num_classes)# 建立VGG16迁移学习模型------------------------------------------------vgg16模型model = torchvision.models.vgg16(pretrained=True)# vgg16是一个预训练模型, pretrained=True执行后会把模型下载到我们的电脑上# 先将模型参数改为不可更新for param in model.parameters():param.requires_grad = False# 再更改最后一层的输出,至此网络只能更改该层参数model.classifier[6] = nn.Linear(4096, num_classes)model.classifier = torch.nn.Sequential( # 修改全连接层 自动梯度会恢复为默认值torch.nn.Linear(25088, 4096),torch.nn.ReLU(),torch.nn.Dropout(p=0.5),torch.nn.Linear(4096, 4096),torch.nn.Dropout(p=0.5),torch.nn.Linear(4096, num_classes))# resnet18---------------------------------------------------------------resnet模型(和前几个模型差不多,自己脑部吧)model = models.resnet18(pretrained=True)# 全连接层的输入通道in_channels个数num_fc_in = model.fc.in_features# 改变全连接层,2分类问题,out_features = 2model.fc = nn.Linear(num_fc_in, num_classes)
继续,解释都在注释里了
# 定义训练函数def train_model(model, dataloaders, criterion, optimizer, mundde_epochs=25):since = time.time() # 返回当前时间的时间戳(1970纪元后经过的浮点秒数)# state_dict变量存放训练过程中需要学习的权重和偏执系数,state_dict作为python的字典对象将每一层的参数映射成tensor张量,# 需要注意的是torch.nn.Module模块中的state_dict只包含卷积层和全连接层的参数best_model_wts = copy.deepcopy(model.state_dict()) # copy是一个复制函数best_acc = 0.0# 下面这个迭代就是一个进度条的输出,从0到9显示进度for epoch in range(num_epochs):print('Epoch {}/{}'.format(epoch, num_epochs - 1))print('-' * 10)# 下面这个迭代,范围就两个'train', 'val',对应不执行不同的训练模式for phase in ['train', 'val']:if phase == 'train':model.train()else:model.eval()running_loss = 0.0running_corrects = 0.0for inputs, labels in dataloaders[phase]:# 下面这行代码的意思是将所有最开始读取数据时的tensor变量copy一份到device所指定的GPU或CPU上去,# 之后的运算都在GPU或CPU上进行inputs, labels = inputs.to(device), labels.to(device)optimizer.zero_grad() # 模型梯度设为0# 接下来所有的tensor运算产生的新的节点都是不可求导的with torch.set_grad_enabled(phase == 'train'):outputs = model(inputs) # output等于把inputs放到指定设备上去运算loss = criterion(outputs, labels) # loss为outputs和labels的交叉熵损失# 举例:output = torch.max(input, dim)# 输入# input是softmax函数输出的一个tensor# dim是max函数索引的维度0 / 1,0是每列的最大值,1是每行的最大值# 输出# 函数会返回两个tensor,第一个tensor是每行的最大值,softmax的输出中最大的是1,所以第一个tensor是全1的tensor;# 第二个tensor是每行最大值的索引。_, preds = torch.max(outputs, 1)if phase == 'train':loss.backward() # 反向传播计算得到每个参数的梯度值optimizer.step() # 通过梯度下降执行一步参数更新running_loss += loss.item() * inputs.size(0)running_corrects += (preds == labels).sum().item()epoch_loss = running_loss / len(dataloaders[phase].dataset)epoch_acc = running_corrects / len(dataloaders[phase].dataset)print('{} loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))if phase == 'val' and epoch_acc > best_acc:best_acc = epoch_accbest_model_wts = copy.deepcopy(model.state_dict())print()time_elapsed = time.time() - sinceprint('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))print('Best val Acc: {:.4f}'.format(best_acc))model.load_state_dict(best_model_wts)return model
继续往下看
# 定义优化器和损失函数model = model.to(device) # 前面解释过了optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)# optimizer = optim.Adam(model.classifier.parameters(), lr=0.0001)# sched = optim.lr_scheduler.StepLR(optimizer, step_size=4, gamma=0.1)criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
引用此文章
class torch.optim.SGD(params, lr=, momentum=0, dampening=0, weight_decay=0, nesterov=False)[source]
实现随机梯度下降算法(momentum可选)。
参数:
params (iterable) – 待优化参数的iterable或者是定义了参数组的dict
lr (float) – 学习率
momentum (float, 可选) – 动量因子(默认:0)
weight_decay (float, 可选) – 权重衰减(L2惩罚)(默认:0)
dampening (float, 可选) – 动量的抑制因子(默认:0)
nesterov (bool, 可选) – 使用Nesterov动量(默认:False)
例子:
optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9)optimizer.zero_grad()loss_fn(model(input), target).backward()optimizer.step()
class torch.optim.Adam(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0)
adam算法来源:Adam: A Method for Stochastic Optimization
Adam(Adaptive Moment Estimation)本质上是带有动量项的RMSprop,它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。它的优点主要在于经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳。
其公式如下:
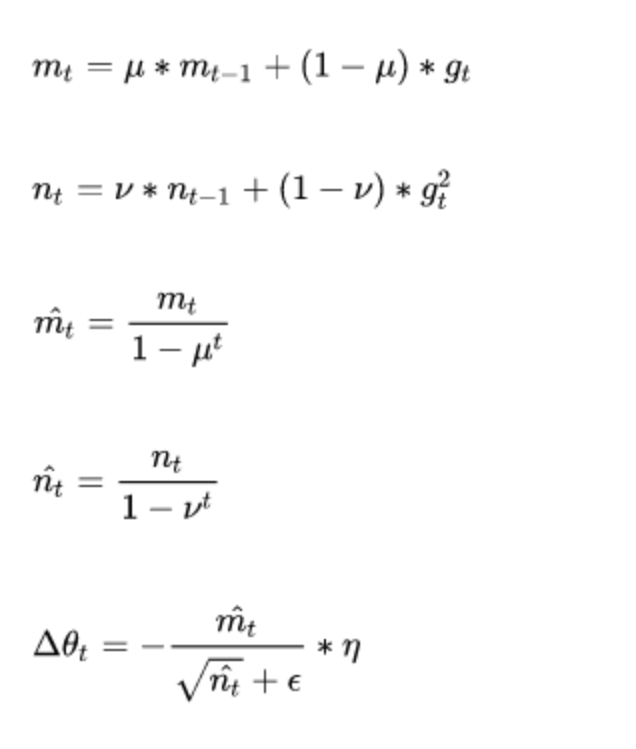
参数:
params(iterable):可用于迭代优化的参数或者定义参数组的dicts。lr (float, optional) :学习率(默认: 1e-3)betas (Tuple[float, float], optional):用于计算梯度的平均和平方的系数(默认: (0.9, 0.999))eps (float, optional):为了提高数值稳定性而添加到分母的一个项(默认: 1e-8)weight_decay (float, optional):权重衰减(如L2惩罚)(默认: 0)step(closure=None)函数:执行单一的优化步骤closure (callable, optional):用于重新评估模型并返回损失的一个闭包
图像分类学习:X光胸片诊断识别----迁移学习的更多相关文章
- 深度学习趣谈:什么是迁移学习?(附带Tensorflow代码实现)
一.迁移学习的概念 什么是迁移学习呢?迁移学习可以由下面的这张图来表示: 这张图最左边表示了迁移学习也就是把已经训练好的模型和权重直接纳入到新的数据集当中进行训练,但是我们只改变之前模型的分类器(全连 ...
- 图像识别 | AI在医学上的应用 | 深度学习 | 迁移学习
参考:登上<Cell>封面的AI医疗影像诊断系统:机器之心专访UCSD张康教授 Identifying Medical Diagnoses and Treatable Diseases b ...
- 基于双向LSTM和迁移学习的seq2seq核心实体识别
http://spaces.ac.cn/archives/3942/ 暑假期间做了一下百度和西安交大联合举办的核心实体识别竞赛,最终的结果还不错,遂记录一下.模型的效果不是最好的,但是胜在“端到端”, ...
- 《A Survey on Transfer Learning》迁移学习研究综述 翻译
迁移学习研究综述 Sinno Jialin Pan and Qiang Yang,Fellow, IEEE 摘要: 在许多机器学习和数据挖掘算法中,一个重要的假设就是目前的训练数据和将来的训练数据 ...
- 迁移学习( Transfer Learning )
在传统的机器学习的框架下,学习的任务就是在给定充分训练数据的基础上来学习一个分类模型:然后利用这个学习到的模型来对测试文档进行分类与预测.然而,我们看到机器学习算法在当前的Web挖掘研究中存在着一个关 ...
- 迁移学习(Transfer Learning)(转载)
原文地址:http://blog.csdn.net/miscclp/article/details/6339456 在传统的机器学习的框架下,学习的任务就是在给定充分训练数据的基础上来学习一个分类模型 ...
- 迁移学习(Transfer Learning)
原文地址:http://blog.csdn.net/miscclp/article/details/6339456 在传统的机器学习的框架下,学习的任务就是在给定充分训练数据的基础上来学习一个分类模型 ...
- 迁移学习(Transformer),面试看这些就够了!(附代码)
1. 什么是迁移学习 迁移学习(Transformer Learning)是一种机器学习方法,就是把为任务 A 开发的模型作为初始点,重新使用在为任务 B 开发模型的过程中.迁移学习是通过从已学习的相 ...
- 【转载】 第四范式首席科学家杨强:AlphaGo的弱点及迁移学习的应对(附视频)
原文地址: https://www.jiqizhixin.com/articles/2017-06-02-2 ============================================= ...
随机推荐
- 一目了然的 Node.js Windows10 安装篇
本篇文章 介绍 NodeJS 的安装 及环境变量配置 Node JS 的 了解 1.Node.js简介 简单的说 Node.js 就是运行在服务端的 JavaScript.Node.js 是一个基于 ...
- 拥抱云原生,如何将开源项目用k8s部署?
微信搜索[阿丸笔记],关注Java/MySQL/中间件各系列原创实战笔记,干货满满. k8s以及云原生相关概念近年来一直比较火热,阿丸最近搞了个相关项目,小结一下. 本文将重点分享阿里开源项目otte ...
- MATLAB绘图,绘双坐标轴,绘一图二轴等
clc; clear all; close all; % %% 画极坐标系 % x = 0:.01 * pi:0.5 * pi; % y = cos(x) + sqrt(-1) * sin(x); % ...
- win7开机登录界面壁纸修改
1.选择一张自己喜欢的图(一定要是jpg格式,亲测png格式不行),分辨率最好和自己电脑的分辨率差不多. 2.将图片改名为"backgroundDefault.jpg": 3.按下 ...
- Access 数据库容量问题
1.单个表的最大容量 2G. 2.单个表的最大条数 3.自动编号的最大数 4.数据库的最大容量 5.text备注形式的字段的最大数据量 6.ole对象字段的最大数据量,图片的最大大小 7.文本字段的 ...
- 浅析Python闭包
1.什么是闭包 在介绍闭包概念前,我们先来看一段简短的代码 def sum_calc(*args): def wrapper(): sum = 0 for n in args: sum += n; r ...
- [leetcode]48RotateImage二维数组翻转
import java.util.Arrays; /** * You are given an n x n 2D matrix representing an image. Rotate the im ...
- python之scrapy篇(二)
一.创建工程 scarpy startproject xxx 二.编写iteam文件 # -*- coding: utf-8 -*- # Define here the models for your ...
- eclipse中安装jetty插件并使用
一.eclipse中jetty插件安装: 打开eclipse,依次点击菜单Help->Eclipse Marketplace,在Find后面的框中输入jetty,选择第一项进行install即可 ...
- 远程分支删除后,git branch -a还能看到的解决方法
详情https://www.cnblogs.com/wangiqngpei557/p/6058115.html 大家在删除远程分支后 git branch -a 还是可以看到已删除的远程分支,时间一长 ...