WCF经典代码
Array.CreateInstance(typeof(object), methodCall.Args.Length)
1、 DataContractSerializer支持的类型.................................................................................................................. 2
1.1. 用[DataContract]属性标记的类型........................................................................................................................ 2
1.2. .net 原生类型............................................................................................................................................................... 2
1.3. 用[Serializable]属性标记的类型........................................................................................................................... 2
1.4. 枚举类型.......................................................................................................................................................................... 3
1.5. 呈现为xml的类型....................................................................................................................................................... 3
1.6. 集合类型.......................................................................................................................................................................... 3
2、 定义需要使用DataContractSerializer序列化的类....................................................................................... 3
2.1. DataContract属性的参数........................................................................................................................................ 3
2.2. DataMember属性的参数........................................................................................................................................ 4
2.3. [DataContract]属性标识的类型跟XmlSerializer序列化器的类型的不同............................................ 4
2.4. 准备待序列化的用 DataContract标识类............................................................................................................ 5
2.5. 准备待序列化的用DataContract标识类型的对象........................................................................................... 7
3、 使用DataContractSerializer类不同的方法序列化用DataContract标识类型的对象................... 7
3.1. 使用WriteObject(Stream stream, object graph)方法序列化............................................................. 8
3.2. 使用WriteObject(XmlDictionaryWriter writer, object graph)方法序列化................................ 10
3.2.1. CreateTextWriter方法..................................................................................................................................... 10
3.2.2. CreateMtomWriter方法................................................................................................................................. 13
3.2.3. CreateBinaryWriter方法................................................................................................................................ 18
3.3. DataContractSerializer序列化总结................................................................................................................ 19
在WCF中,DataContractSerializer是默认的序列化器,不过WCF中还有一个叫NetDataContractSerializer的序列化器,它跟DataContractSerializer一样也是从XmlObjectSerializer类继承。NetDataContractSerializer跟DataContractSerializer一个主要的不同是:NetDataContractSerializer序列化后的xml中包含了.net的类型信息,反序列化时必须要被反序列化为同样类型的对象,这点跟BinaryFormatter和SoapFormatter这两个序列化器类似。DataContractSerializer序列化后的xml中则不包含.net的类型信息,通用性和交互性更好。在实际应用中DataContractSerializer是WCF的默认序列化器,绝大多数情况下都是使用DataContractSerializer,下面我们只对DataContractSerializer做详细介绍。
本文完整测试源代码下载: DataContractSerializer.rar
一般情况下WCF的基础结构(infrastructure)会调用DataContractSerializer对要传输的数据对象就行序列化,不过也有特殊情况,WCF会调用别的序列化器序列化数据对象。
当遇到数据类成员中标记有类似[XmlAttribute]属性这样的细致设置生成xml格式的属性时,这时WCF infrastructure需要调用XmlSerializer序列化器来序列化这样的数据对象,通过在一个方法前加上[XmlSerializerFormat]属性值是WCF infrastructure调用XmlSerializer序列化器。
[XmlSerializerFormat]属性可以标记一个方法,表示这个方法使用XmlSerializer序列化器。
[XmlSerializerFormat]属性也可以用来标记一个ServiceContract,表示整个ServiceContract都用XmlSerializer序列化器。
比如:
[ServiceContract]
public interface IAirfareQuoteService
{
[OperationContract]
[XmlSerializerFormat]
float GetAirfare(Itinerary itinerary, DateTime date);
}
public class Itinerary
{
public string fromCity;
public string toCity;
[XmlAttribute]
public bool isFirstClass;
}
1、 DataContractSerializer支持的类型
DataContractSerializer支持绝大多数的可序列化的类型的序列化,具体包括:
1.1. 用[DataContract]属性标记的类型
这种类型是为DataContractSerializer定制的可序列化类型,DataContractSerializer对这种了类型提供最全面的支持。
1.2. .net原生类型
.net内建的一些简单的数据类型,比如:Byte, SByte, Int16,string等,还有一些不是原生类型但是可以视作原声类型的类型,比如:DateTime, TimeSpan, Guid, Uri。
1.3. 用[Serializable]属性标记的类型
这是为rometing准备的序列化类型,被DataContractSerializer完全支持。
使用DataContractSerializer序列化前面SoapFormatter序列化的那个例子得到的结果:
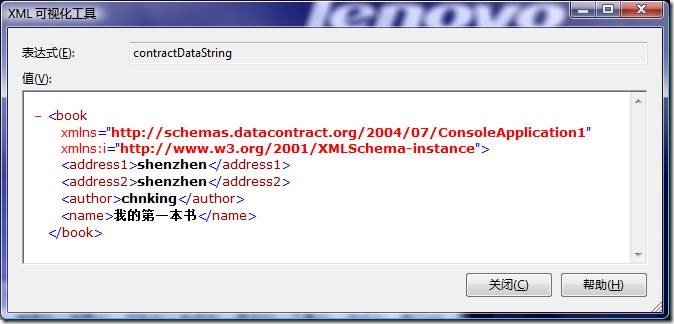
把这个序列化后的结果跟直接使用SoapFormatter序列化的结果比较一下有以下几点不同:
l DataContractSerializer序列化是面向数据的,不保留对象之间的引用关系,所以虽然address1和address2指向的是同一个对象,但DataContractSerializer还是分别给他们赋了同样的值。
l 不再包含.net的类型相关的信息,类的全限定名、版本、区域、KeyToken等等。
1.4. 枚举类型
1.5. 呈现为xml的类型
类型本身就可以呈现为xml的类型,比如XmlElement ,XmlNode,或者ADO.NET相关的类型,比如DataTable , DataSet。这些类型序列化时会被直接以xml的形式呈现。
1.6. 集合类型
可被序列化的类型组成的集合类型也被支持。
2、 定义需要使用DataContractSerializer序列化的类
自定义一个类或结构,这个类或结构:
首先,在类前面加上[DataContract],表示这个类包含有数据契约
其次,在需要对外暴露的成员用[DataMember]属性标记。在这个类中,只有被标记为[DataMember]的成员才会被序列化,不管成员是公有的还是私有的。
2.1. DataContract属性的参数
[DataContract]可以用来描述一个class或者struct,可以带有两个参数:
l Name
指定这个数据契约对外的类型名,如果没有指定此参数,缺省的就是类名。
l Namespace
指定这个类被序列化为xml后的Root元素的名称空间,为URI形式。
如果没有指定此参数,缺省名称空间为:“http://schemas.datacontract.org/2004/07/这个类的.net类名称空间”
比如有这样一个标记为DataContract的类型:
namespace DataContractSerializerTest.Myspace
{
[DataContract]
class Person
{
//代码
}
}
这个类型的默认名称空间就是http://schemas.datacontract.org/2004/07/ DataContractSerializerTest.Myspace
2.2. DataMember属性的参数
[DataMember]可以用来描述Property和field,不管这个成员是public或者private,只要标记了[DataMember],这个成员就会被序列化。
[DataMember]属性可以带有以下几个参数:
l Name
指定这个成员对外暴露的名称,如果没有指定此参数,缺省的就是此Property或field名。
l Isrequired
这个参数告诉DataContractSerializer序列化器把xml数据反序列化为这个类型时,这个成员是不是必须有的。此属性在反序列化时起作用。
l Order
指示这个成员被序列化后的顺序。此属性在序列化时起作用。如果在一个类中既存在用Order参数约束的成员,又有没用Order参数约束的成员,那么序列化后没有Order参数约束的成员排在Order参数约束的成员之前。
l EmitDefaultValue
此参数告诉DataContractSerializer序列化器,在序列化时如果这个数据成员的值是这个成员类型的缺省值(比如成员是int类型,缺省值为0,如果成员是个引用类型,缺省值为null),是否将此成员序列化。=true时表示要序列化,=false时表示不序列化,此参数的默认值为true。
当引用类型的成员为null时,此参数设置为true时,这个成员被序列化后的xml表现为xsi:nil="true",比如:
<Name xsi:nil="true" />
2.3. [DataContract]属性标识的类型跟XmlSerializer序列化器的类型的不同
这两种类型都是面向数据的,都不关心数据的.net类型信息。但是他们还是有所不同:
l DataContract的类型只能把用DataMember标识的成员序列化成element形式,不能序列化为attribute,如果一定要把数据成员序列化为attribute形式就需要用使用XmlSerializer序列化器。
l DataMember属性可以通过order参数指定此成员序列化后的出现顺序,用于XmlSerializer序列化器的XmlElement属性无此功能。
l DataContract的类型只要在成员前加上DataMember标记,不管成员是public或private的,都会被序列化,XmlSerializer序列化器只序列化public的成员。
l DataContract的类型的成员的名称空间跟整个类的一致,成员不能独立设置自己的名称空间(DataMember属性没有名称空间参数),XmlSerializer序列化器允许成员拥有自己的名称空间(XmlAttribut和XmlElement都有namespage参数设置成员独立的名称空间)。
2.4. 准备待序列化的用 DataContract标识类
设计一个的Person类型,其中包含五个成员,binaryBuffer1、binaryBuffer2、name、address、age,其中name和address又分别是DataContract标识的简单类型。
binaryBuffer1和 binaryBuffer2是byte[]类型的数据,表示二进制的数据,可能包含任何非二进制的对象,比如图片、声音等等。这里放两个二进制的数据为了测试不同长度的二进制数据在DataContractSerializer不同的方法中会被如何处理。
[DataContract(Namespace = "htttp://chnking")]
class Person
{
private Name name;
private Address address;
private int age;
[DataMember]
public byte[] binaryBuffer1;
[DataMember]
public byte[] binaryBuffer2;
public Person(Name name, Address address, int age)
{
this.name = name;
this.address = address;
this.age = age;
}
[DataMember(Order = 2)]
public int Age
{
get { return age; }
set { age = value; }
}
[DataMember(EmitDefaultValue = true, Order = 0)]
public Name Name
{
get { return name; }
set { name = value; }
}
[DataMember(Order = 1)]
public Address Address
{
get { return address; }
set { address = value; }
}
}
[DataContract(Namespace = "htttp://chnking")]
class Name
{
private string firstname;
private string lastname;
public Name(string firstname, string lastname)
{
this.firstname = firstname;
this.lastname = lastname;
}
[DataMember]
public string Lastname
{
get { return lastname; }
set { lastname = value; }
}
[DataMember]
public string Firstname
{
get { return firstname; }
set { firstname = value; }
}
}
[DataContract(Namespace = "htttp://chnking")]
class Address
{
private string city;
private string postcode;
private string street;
public Address(string city, string postcode, string street)
{
this.city = city;
this.postcode = postcode;
this.street = street;
}
[DataMember]
public string Street
{
get { return street; }
set { street = value; }
}
[DataMember]
public string Postcode
{
get { return postcode; }
set { postcode = value; }
}
[DataMember]
public string City
{
get { return city; }
set { city = value; }
}
}
2.5. 准备待序列化的用DataContract标识类型的对象
实例化一个Person的对象,后续步骤将要序列化这个对象。
注意,这里给第一个二进制数据赋了一个20字节长数据,第二个二进制数据赋了一个768字节长度的数据,为什么这么赋值,后面会有说明。
//构造一个需要序列化的DataContract的对象
Person person = new Person(new Name("比尔", "盖茨"),
new Address("shenzhen", "518000", "fuqiang road"),
40);
//用一个重复的值填充第一个二进制数据bufferbytes1
int size1 = 20;
byte[] bufferbytes1 = new byte[size1];
for (int i = 0; i < size1; i++)
{
//65表示ASCII码的A
bufferbytes1[i] = 65;
}
person.binaryBuffer1 = bufferbytes1;
//用一个重复的值填充第二个二进制数据bufferbytes2
int size2 = 768;
byte[] bufferbytes2 = new byte[size2];
for (int i = 0; i < size2; i++)
{
//66表示ASCII码的B
bufferbytes2[i] = 66;
}
person.binaryBuffer2 = bufferbytes2;
3、 使用DataContractSerializer类不同的方法序列化用DataContract标识类型的对象
实例化一个DataContractSerializer序列化器,DataContractSerializer序列化器跟XmlSerializer序列化器一样,没有缺省构造方法,至少需要提供要序列化对象的类型参数。
//准备DataContractSerializer序列化器
DataContractSerializer dcs = new DataContractSerializer(typeof(Person));
DataContractSerializer序列化对象的方法是WriteObject,这个WriteObject主要有两个重载,WriteObject(Stream stream, object graph)和WriteObject(XmlDictionaryWriter writer, object graph)。
下面对这两种序列化方法分别讨论。
3.1. 使用WriteObject(Stream stream, object graph)方法序列化
这个方法跟XmlSerializer序列化器的Serialize方法类似,是把序列化的对象的xml字符串直接编码序列化为字节流,而且跟XmlSerializer一样,从字符串到字节流的使用UTF8进行编码。
Stream(dcs, person);
private static void Stream(DataContractSerializer dcs, Person person)
{
//构造用于保存序列化后的DataContract对象的流
MemoryStream contractDataStream = new MemoryStream();
//将DataContract对象序列化到流
dcs.WriteObject(contractDataStream, person);
//为了查看序列化到流中的内容,将流内容读取出来并用UTF8解码为字符串
byte[] contractDataByte = new byte[contractDataStream.Length];
contractDataStream.Position = 0;
contractDataStream.Read(contractDataByte, 0, (int)contractDataStream.Length);
string contractDataString = Encoding.UTF8.GetString(contractDataByte);
//将流反序列化为DataContract对象
contractDataStream.Position = 0;
person = (Person)dcs.ReadObject(contractDataStream);
}
这部分代码跟XmlSerializer部分的类似,不加更多的说明了。
序列化后的xml这样的:
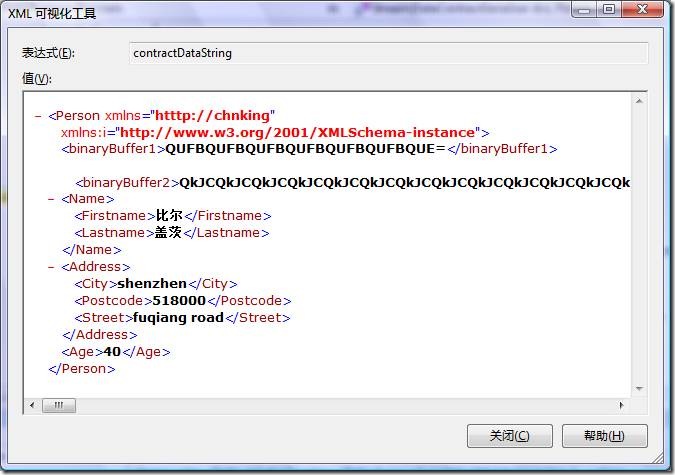
WriteObject(Stream stream, object graph)方法序列化有以下特点:
l DataContractSerializer首先把对象序列化为一个xml 形式的字符串。
l 对于其中的二进制数据,不管多大长度,一律转成base64编码的字符串。本例中bufferbytes2被设置为768字节长度,序列化结果是一串base64的编码,又测试了把bufferbytes2长度增加为7680个字节,序列化的结果仍然是一串更长的base64的编码。
l DataContractSerializer然后把序列化后的xml形式的字符串以UTF8编码(这是默认的编码,并且没有提供可以使用别的编码的接口,所以对其解码也必须使用UTF8,这点跟XmlSerializer和SoapFormatter序列化器一样)对其进行编码,转换到字节流,最终保存到一个流对象中,本例中就是MemoryStream。可以通过对字节流进行UTF8解码得到xml的字符串,就是上图看到的结果。
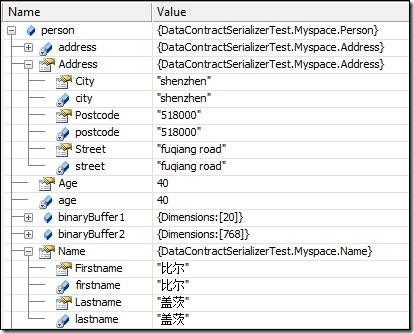
反序列化后的Person对象是这样的:
3.2. 使用WriteObject(XmlDictionaryWriter writer, object graph)方法序列化
这个方法是DataContractSerializer序列化器把对象序列化为xml字符串后,不直接对xml进行编码转换成字节流,而是把xml写入到XmlDictionaryWriter,XmlDictionaryWriter提供了多种对xml进行编码的选择,最终再由XmlDictionaryWriter把编码后的xml写入到目标流中。
XmlDictionaryWriter提供了三类静态方法,构造三种不同类型的XmlDictionaryWriter,分别对xml进行不同的编码操作。
它们分别是:
3.2.1. CreateTextWriter方法
CreateTextWriter方法构建的XmlDictionaryWriter写入器,这样的写入器跟WriteObject(Stream stream, object graph)方法的作用类似,也是直接把xml的内容直接编码为字节流,但是允许选择编码时使用哪种编码。
XmlDictionaryWriter的CreateTextWriter方法主要下面两种重载形式。
public static XmlDictionaryWriter CreateTextWriter (Stream stream)
public static XmlDictionaryWriter CreateTextWriter (Stream stream, Encoding encoding)
第一个重载方法没有Encoding参数,默认采用UTF8进行编码,这样第一个方法的作用其实跟WriteObject(Stream stream, object graph)方法一样。
第二个重载方法有Encoding参数,可以指定在编码时采用何种编码,是Unicode还是UTF8等。下面的示例代码使用第二个重载方法,指定UTF8编码。
XmlDictionaryCreateTextWriter(dcs, person);
private static void XmlDictionaryCreateTextWriter(DataContractSerializer dcs, Person person)
{
//构造用于保存序列化并编码后的DataContract对象的流
MemoryStream contractDataStream = new MemoryStream();
//新建一个CreateTextWriter方法构建的指定Unicode的XmlDictionaryWriter对象
XmlDictionaryWriter xdw = XmlDictionaryWriter.CreateTextWriter(contractDataStream, Encoding.UTF8);
//调用WriteObject方法将对象通过XmlDictionaryWriter序列化并编码
dcs.WriteObject(xdw, person);
//将序列化并编码后的字节流写入到原始流对象
xdw.Flush();
contractDataStream.Position = 0;
//为了查看序列化到流中的内容,将流内容读取出来并用Unicode解码为字符串
byte[] contractDataByte = new byte[contractDataStream.Length];
contractDataStream.Read(contractDataByte, 0, (int)contractDataStream.Length);
string contractDataString = Encoding.UTF8.GetString(contractDataByte);
//将流反序列化为DataContract对象
contractDataStream.Position = 0;
XmlDictionaryReader reader = XmlDictionaryReader.CreateTextReader(contractDataStream, Encoding.UTF8, new XmlDictionaryReaderQuotas(), newOnXmlDictionaryReaderClose(OnReaderClose));
person = (Person)dcs.ReadObject(reader);
reader.Close();
}
public static void OnReaderClose(XmlDictionaryReader reader)
{
return;
}
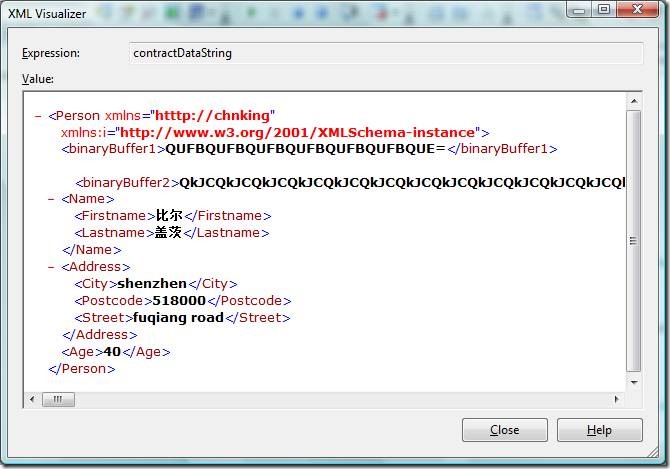
序列化后,contractDataStream中获得的序列化后的数据长度为1385字节。
将contractDataStream中的字节流用UTF8解码,得到的内容跟前面的WriteObject(Stream stream, object graph)方法序列化后的结果一模一样:
再用Encoding.Unicode 编码测试,序列化后,contractDataStream中获得的序列化后的数据长度为2756字节,明显比前面使用UTF8编码得到的结果长的多。这是很正常的结果,因为一般ASCII可表示的字符,使用UTF8编码也是用一个字节表示,并跟ASCII编码兼容,而UTF-16编码会把所有字符都编码为2个字节,所以使用Encoding.Unicode编码后的结果会大很多,几乎是UTF的2倍(因为测试的内容字符绝大多数是ASCII可表示的字符)
将contractDataStream中的字节流用Encoding.Unicode解码,查看内容为,解码后的内容跟UTF8解码后的内容也是一致的:
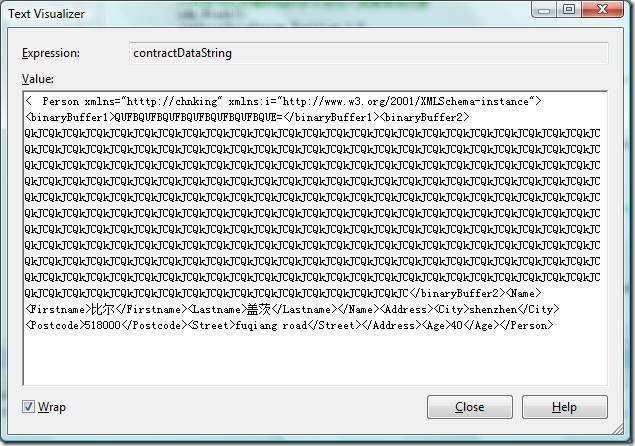
实际测试CreateTextWriter方法中的Encoding参数只能为:Encoding.Unicode、Encoding.UTF8和Encoding.BigEndianUnicode 三种。
CreateTextWriter方法构建的XmlDictionaryWriter写入器有以下特点:
l DataContractSerializer首先把对象序列化为xml的各个元素写入到XmlDictionaryWriter对象。
l XmlDictionaryWriter把内容最后写入到基础流的时候,对于二进制数据类型的元素,不管多大长度,一律转成base64编码的字符串。对于字符串类类型的元素以指定的编码对其进行编码,转换到字节流,最终保存到一个流对象中,本例中就是MemoryStream。
序列化时,使用XmlDictionaryWriter的CreateTextWriter方法建立的XmlDictionaryWriter对象作为写入器,反序列化时,相应的就要用XmlDictionaryReader的CreateTextReader建立的XmlDictionaryReader对象来作为读取器。
CreateTextReader方法签名如下:
CreateTextReader(Stream stream, Encoding encoding, XmlDictionaryReaderQuotas quotas, OnXmlDictionaryReaderClose onClose);
参数说明:
stream – 保存序列化后数据的流对象。
encoding – 反序列化时使用的编码,应该跟序列化时使用的编码一致。
quotas – 指定XmlDictionaryReader对象的一些极限值,比如可以读取的stream的最长长度等等。XmlDictionaryReaderQuotas的默认构造方法对这些极限值构造了一个比较安全的缺省值,比如MaxArrayLength = 16384,可以反序列化数据的最长长度。当序列化后的stream中的字节长度长于MaxArrayLength设定的值,反序列化时将会抛出异常。
onClose – delegate类型,指定一个方法,在XmlDictionaryReader关闭时触发
3.2.2. CreateMtomWriter方法
前面CreateTextWriter方法构造的XmlDictionaryWriter写入器,处理二进制数据的方式是把二进制数据转成base64编码的字符串,这个处理方法在一般情况下是个不错的方案,但是base64编码会增加编码后的长度,在二进制数据比较长的情况下,base64编码带来的长度增加将不能忽视。
Base64编码将每3个字节的数据拆散重组为4字节可表示简单字符的数据,编码后的数据长度比为3:4,如果数据长度不长,增加的长度影响不大,但是如果原来的二进制数据就比较大,比如300K,编码后的数据将会是400K,再如果原来是30M,编码后为40M,多出来的数据量难以忽视。
鉴于这种情况,W3C制定了XOP(XML-binary Optimized Packages,XOP)协议来解决二进制问题,XOP 提供一个机制,可选择性地提取要优化的信息,将其添加到多部分MIME 消息中(其中也包括您的 SOAP 消息)并显式地对其进行引用。使用 XOP 的过程称为 MTOM(SOAP 消息传输优化机制——Message Transmission Optimization Mechanism)。
经过MTOM处理的数据,形式上为MIME(邮件的内容形式),XML 数据组成第一部分,而二进制数据视其长度的不同或者被编码成base64放在xml中,或者作为附加部分添加到xml部分的后面。
CreateMtomWriter用来构造XmlDictionaryWriter最常用的方法重载是:
CreateMtomWriter(Stream stream, Encoding encoding, int maxSizeInBytes, string startInfo);
参数说明:
stream – 保存序列化后数据的流对象。
encoding – 序列化时使用的编码。
maxSizeInBytes – 将被缓冲到XmlDictionaryWriter写入器的数据最大字节数
startInfo – 在生成的MIME消息的ContentType增加一个名称为start-info的header,header的值就是这个参数提供的。
看一下用CreateMtomWriter构造的XmlDictionaryWriter序列化前面例子的代码:
XmlDictionaryCreateMtomWriter(dcs, person);
private static void XmlDictionaryCreateMtomWriter(DataContractSerializer dcs, Person person)
{
//构造用于保存序列化并编码后的DataContract对象的流
MemoryStream contractDataStream = new MemoryStream();
//新建一个CreateMtomWriter方法构建的指定Unicode的XmlDictionaryWriter对象
XmlDictionaryWriter xdw = XmlDictionaryWriter.CreateMtomWriter(contractDataStream, Encoding.UTF8, 2048000, "text/xml");
//调用WriteObject方法将对象通过XmlDictionaryWriter序列化并编码
dcs.WriteObject(xdw, person);
//将序列化并编码后的字节流写入到原始流对象
xdw.Flush();
contractDataStream.Position = 0;
//为了查看序列化到流中的内容,将流内容读取出来并用Unicode解码为字符串
byte[] contractDataByte = new byte[contractDataStream.Length];
contractDataStream.Read(contractDataByte, 0, (int)contractDataStream.Length);
string contractDataString = Encoding.UTF8.GetString(contractDataByte);
//将流反序列化为DataContract对象
contractDataStream.Position = 0;
XmlDictionaryReader reader = XmlDictionaryReader.CreateMtomReader(contractDataStream, Encoding.UTF8, XmlDictionaryReaderQuotas.Max);
person = (Person)dcs.ReadObject(reader);
reader.Close();
}
生成的序列化后的数据用UTF8解码后看:
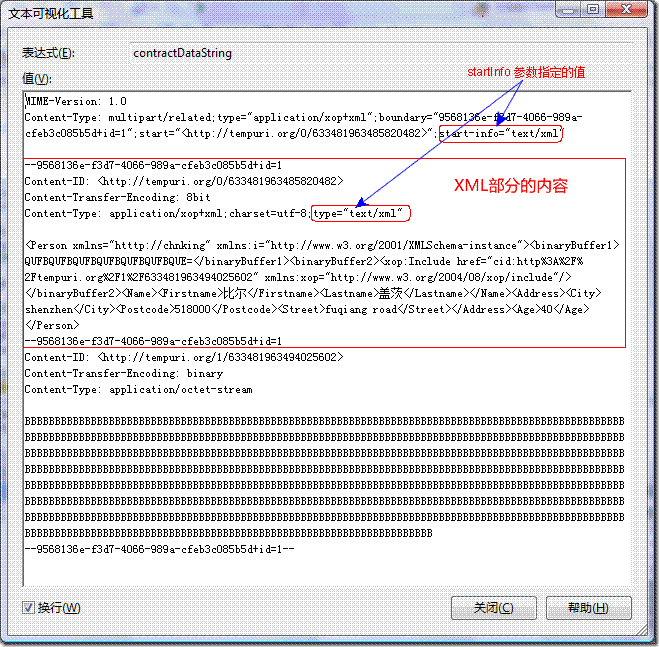
可以看出CreateMtomWriter构造的XmlDictionaryWriter将xml的内容转成了MIME的形式,下面仔细的分析一下MIME消息的构成。
XmlMtomWriter生成的MIME的消息一般分为三个部分:
l MIME头
MIME-Version: 1.0 - 表示MIME的版本号
头部最重要的内容是Content-Type中的一些内容,它们是:
Content-Type: multipart/related – 表示是多部分的消息
type="application/xop+xml" – 表示是xop协议的MIME消息格式
Boundary – 部分之间的边界,这个值插在不同的部分之间以分割不同的部分内容
Start – 开始的那个部分的Content-ID,每个部分都有一个唯一的Content-ID标识。这里开始部分就是xml的部分。
l 第一部分(xml部分)
MIME头部跟第一部分之间有个空行,表示头部结束后面是部分的内容。
Boundary指定的字符串前面加上”—“字符是部分开始和结束的标识。
每个部分也分header和body部分,以空行分割。
Content-ID: <http://tempuri.org/0/633482733255804248> – 此部分的标识id
Content-Transfer-Encoding: 8bit – 表示body部分的内容可能是非ASCII编码的编码内容,这里xml的内容一般以UTF8或UTF16编码,使用了每个字节的所有8位。
Content-Type: application/xop+xml;charset=utf-8;type="text/xml" – 表示body的内容类型为xop的xml内容。
Body部分就是xml的内容,重点关注一下二进制数据binaryBuffer2的表现形式。
二进制binaryBuffer1数据部分被直接编码成base64字符串放在xml中。
binaryBuffer2部分的数据实际上从xml中剥离出来,作为一个单独的部分存在。看一下在xml中的binaryBuffer2:
<binaryBuffer2><xop:Include href="cid:http%3A%2F%2Ftempuri.org%2F1%2F633482781614236973" xmlns:xop="http://www.w3.org/2004/08/xop/include"/></binaryBuffer2>
其中href=cid:http%3A%2F%2Ftempuri.org%2F1%2F633482781614236973指向表示这部分二进制数据的部分的标识id,实际的二进制数据被放在指向的那个部分。
l 后续部分(二进制数据部分)
没有被直接放在第一部分xml中的内容都会被放置在随后的那些部分中,本例中就只有一个binaryBuffer2部分的数据被放置到后续部分。
同样这个部分有header和body部分,以空行分割。
Content-ID: http://tempuri.org/1/633482781614236973 - 就是xml部分中binaryBuffer2引用的id。
Content-Transfer-Encoding: binary – 表示body部分是二进制的未经编码的。
Content-Type: application/octet-stream – 内容类型为数据流。
在测试中我们把binaryBuffer2的数据长度设置为768,如果改成767,看看结果:
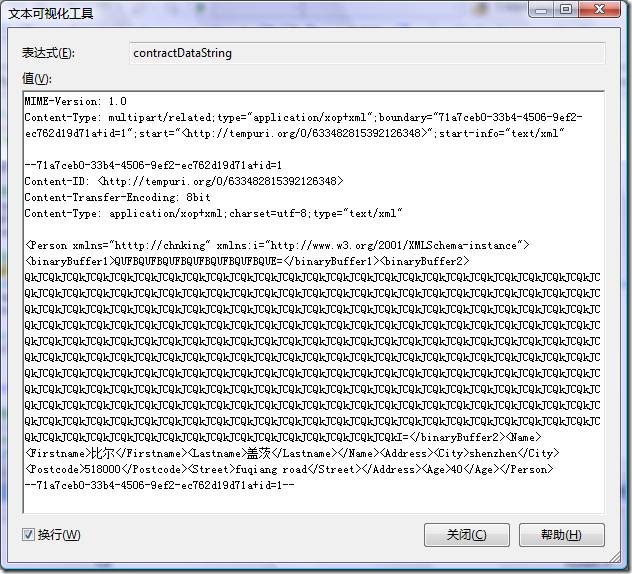
可以发现这时binaryBuffer2的数据也被编码成base64直接放入到xml中了。
也就是说,CreateMtomWriter构造的XmlDictionaryWriter是根据二进制数据的长度来决定数据如何表现,如果小于768则把数据编码为base64,如果大于等于768则把数据单独放到一个部分,并保持二进制数据的原样。
CreateMtomWriter方法构建的XmlDictionaryWriter写入器有以下特点:
l DataContractSerializer首先把对象序列化为xml的各个元素写入到XmlDictionaryWriter对象。(这步跟CreateTextWriter方法构建的XmlDictionaryWriter一样,其实DataContractSerializer传到XmlDictionaryWrite的内容是一样的)
l CreateMtomWriter方法构建的XmlDictionaryWriter写入器分析DataContractSerializer传进来的xml元素的内容,如果包含二进制的内容,则判断如果二进制的数据大于等于768字节的就把它放到一个单独部分保持二进制,如果小于依然保存在xml中以base64编码。
l MTOM的header和Boundary部分边界符都使用UTF8编码,xml部分的编码由CreateMtomWriter方法中的encoding参数决定,最终将MTOM的内容根据各自的编码转换到字节流,保存到一个流对象中,本例中就是MemoryStream。
3.2.3. CreateBinaryWriter方法
DataContractSerializer还提供了一种最高效的序列化方式,二进制序列化,把xml内容直接转成二进制的数据,不过这样的转换是微软自己的定义的,只能在.net环境下使用,跟别的技术不具有交互性。
看一下用CreateBinaryWriter构造的XmlDictionaryWriter序列化前面例子的代码:
XmlDictionaryCreateBinaryWriter(dcs, person);
private static void XmlDictionaryCreateBinaryWriter(DataContractSerializer dcs, Person person)
{
//构造用于保存序列化并编码后的DataContract对象的流
MemoryStream contractDataStream = new MemoryStream();
//新建一个CreateTextWriter方法构建的指定Unicode的XmlDictionaryWriter对象
XmlDictionaryWriter xdw = XmlDictionaryWriter.CreateBinaryWriter(contractDataStream);
//调用WriteObject方法将对象通过XmlDictionaryWriter序列化并编码
dcs.WriteObject(xdw, person);
//将序列化并编码后的字节流写入到原始流对象
xdw.Flush();
contractDataStream.Position = 0;
//为了查看序列化到流中的内容,将流内容读取出来并用UTF8解码为字符串
byte[] contractDataByte = new byte[contractDataStream.Length];
contractDataStream.Read(contractDataByte, 0, (int)contractDataStream.Length);
string contractDataString = Encoding.UTF8.GetString(contractDataByte);
//将流反序列化为DataContract对象
contractDataStream.Position = 0;
XmlDictionaryReader reader = XmlDictionaryReader.CreateBinaryReader(contractDataStream, new XmlDictionaryReaderQuotas());
person = (Person)dcs.ReadObject(reader);
reader.Close();
}
序列化后的结果是二进制的,不具可读性,下面试着用UTF8编码强行把二进制的数据转成字符串看一下:
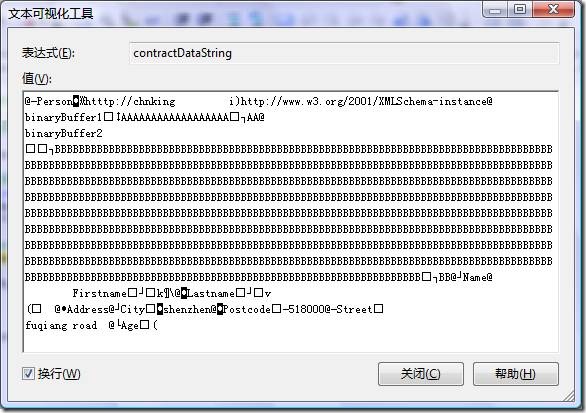
本例中,序列化后的二进制数据长度为1010字节,前面使用CreateTextWriter方法并使用UTF8编码的序列化后的数据长度为1385。可见二进制序列化后的数据长度最短。
3.3. DataContractSerializer序列化总结
DataContractSerializer本身完成了把要序列化的对象序列化为xml的形式,之后再由不同的编码方案对这个xml进行编码,最后形成完全序列化的数据流。
DataContractSerializer实际上提供了四种编码方案,其中WriteObject(Stream stream, object graph)直接序列化到流和CreateTextWriter方法构建的XmlDictionaryWriter这两种,是直接把xml字符进行编码,只是WriteObject(Stream stream, object graph)使用固定的UTF8编码,CreateTextWriter方法构建的XmlDictionaryWriter可以选择序列化使用的编码。
CreateMtomWriter方法构建的XmlDictionaryWriter是把对象的xml编码为MTOM的形式。
CreateBinaryWriter构造的XmlDictionaryWriter是把对象的xml编码为二进制的形式。
Xml形式具有最佳的互操作性,适应面最广。
MTOM的形式适合传输含有二进制大数据的对象。
二进制的形式传输效率最高,但是不具互操作性,只能用于.net环境的交换。
WCF经典代码的更多相关文章
- js让菜单栏一直悬浮在顶部,经典代码
js让菜单栏一直悬浮在顶部,经典代码 很简单,你只需要把下面代码放到js中:$(function(){ //获取要定位元素距离浏览器顶部的距离 var na ...
- wcf纯代码创建控制台应用
https://svn.apache.org/repos/asf/incubator/stonehenge/contrib/stocktrader/dotnet/ stocktrader项目的dotn ...
- epoll经典代码示例
1. epoll原理 原理性的知识不再另做说明,我在这里附上收藏整理的两篇经典文章: select与epoll的本质关系. select.poll.epoll之间的区别. 2. epoll服务器端经典 ...
- Java Web项目中的经典代码抽取
前言: 众所周知的,项目开发中做得最多的无非就是增删查改(CRUD)操作.自从国内Web项目开发渐渐盛行SSH框架之后,其开发开发流程也变得更加灵活:本文就项目开发中的业务层代码作个简单的抽取,供业内 ...
- Javascript中最常用的61段经典代码
1. oncontextmenu="window.event.returnValue=false" 将彻底屏蔽鼠标右键<table border oncontextmenu= ...
- PHP之session相关实例教程与经典代码
·php 中cookie和session的用法比较 ·phpmyadmin报错:Cannot start session without errors问题 ·php中cookie与session应用学 ...
- PHP之cookie相关实例教程与经典代码
·php 中cookie和session的用法比较 ·php会话控制cookie与Session会话处理 ·php中利用cookie实现购物车实例 ·php中cookie与session应用学习笔记 ...
- JavaScript经典代码总结
1. oncontextmenu="window.event.returnvalue=false" 将彻底屏蔽鼠标右键<table border oncontextmenu= ...
- 《转载》常用算法经典代码(C++版)
转自:http://blog.renren.com/blog/311453043/736944237 一.快速排序 void qsort(int x,int y) //待排序的数据存放在a[1]..a ...
随机推荐
- ssd算法论文理解
这篇博客主要是讲下我在阅读ssd论文时对论文的理解,并且自行使用pytorch实现了下论文的内容,并测试可以用. 开篇放下论文地址https://arxiv.org/abs/1512.02325,可以 ...
- Python 使用标准库根据进程名获取进程PID
应用场景 在进行 Linux 运维的环境中,我们经常会遇到维护同一台服务器上的多个程序,涉及到程序的启动.关闭和重启操作. 通常这些程序之间存在着相互依存的关系需要进行依次的启动关闭操作. 下面介绍几 ...
- [MachineLearning]KNN
# -*- coding: utf-8 -*- """ Created on Wed Jun 18 11:46:15 2014 @author: hp "&qu ...
- 网页(aspx)与用户控件(ascx)交互逻辑处理实现
几个页面(ASPX)都使用一些相同的控件,一个文本框,二个按钮(搜索和导出),为了以后好维护,把这相同的部分抽取放在一个用户控件(ASCX)上.现需要处理逻辑如下 搜索事件处理的逻辑在各个页面处理. ...
- java三大框架SSH(Struts2 Spring Hibernate)
http://www.cnblogs.com/qiuzhongyang/p/3874149.html
- 线段树lazy标记??Hdu4902
Nice boat Time Limit: 30000/15000 MS (Java/Others) Memory Limit: 131072/131072 K (Java/Others) To ...
- 报错 findMergedAnnotation activemq
springmvc 集成activemq引入activemq-all-5.14.4有冲突 springmvc 4.2.9集成activemq-5.14.4时报错,错误信息如下 NoSuchMethod ...
- Mac中pico编辑器的使用方法
Pico是一个由华盛顿大学(University of Washington)计算与通讯研究所(Computing and Communications Group)编写并维护的文本编辑程序,在多个版 ...
- .then()
reference: http://www.html-js.com/article/Study-JavaScript-jQuery-Deferred-and-promise-every-day 1.5 ...
- phantomjs学习之网页访问测速
1.编写loadpage2.js文件: loadpage2.js var page = require('webpage').create(), system = require('system'), ...