2.hbase原理(未完待续)
相关概念
hmster
hregionserver
表
region
hstore
memstore
storefile
hfile
blockcache
WAL
minorcompact
majorcompact
region split
hbase架构
zookeeper
master
regionserver
hbase的表
表结构
表的读写
hbase的元数据表
-ROOT-
hbase:meta
hbase:meta表结构:
Block Cache
LruBlockCache的设计
LruBlockCache的使用
非堆内存off-heap
blockcache压缩
WAL
WAL切分
regions
region的个数
控制region的个数据
region的分配
1.hbase启动时
2.故障转移
region的状态
region的本地化
region的分裂
region分裂的过程
手工分裂Region
region的合并
hstore
memstore
memstore flush的原因
scan操作读memstore
hbase存储与文件格式
keyvalue
参考资料
http://www.jianshu.com/p/84bf8c907c6b
http://blog.csdn.net/u011812294/article/details/53944628
http://blog.csdn.net/ldds_520/article/details/51648833
http://www.blogjava.net/DLevin/archive/2015/08/22/426877.html
hbase是一个很复杂的组件,本文的内容是自己的理解+官方文档+网上的博客拼凑而成,不保证内容正确.
hbase简介
hbase是一个分布式\列式存储的key-value数据.有以下特点:
1.分布式:数据分片存储在多个节点,而非单个节点,因此能支持海量数据存储
2.列式存储:数据按列族存储,而非按行存储
3.key-values:数据按key存入和读取
4.无模式:表中的列不需要定义数据类型,可以动态的增加减少列的个数.而不像RDBMS那样,要预告定义好表的列及类型并严格遵守.
5.高性能:超高的并发性写,极快的按rowkey查询.
相关概念
hmster
hbase的管理节点,负责管理元数据等.
hregionserver
hbase的工作节点,负责表的读写\region分裂合并等,hbase最核心的组件.
表
和RDBMS一样,hbase中也有表,表由行和列族组成.行包括一个行键和若干列族(可以把行键看作RDBMS的主键,列族看作RDMBS的列),列族中包括若干列.列可以动态的增加减少,因此hbase是无模式的.表的数据按rowkey排序.此外,每一行数据都有一个时间版本,可以读取指定时间版本的行数据.
region
hbase是分布式的数据库,表中的数据分布在各个节点上.表的数据按rowkey分成一块块连接的rowkey区间放在各个节点上运行,这些区间叫做region.
hstore
存储region数据的"仓库",region的数据由hstore来负责存储.hstore以包含memstore和storefile.表中的每个列族都对应一个hstore.
memstore
memstore是hstore的内存写缓冲区.写入hbase中的数据,先写到memstore中,当hstore中满了以后,再刷新到磁盘.
storefile
memstore中的数据刷到磁盘上保存在storefile中,在磁盘表现为一个个较小的hfile.
hfile
hbase文件存储格式.hfile中存储了数据\索引\元数据\布尔过滤器等
blockcache
hbase的读缓冲,用户数据时,首先在blockcache中查找,如果没有命中,则到hfile中查找.blockcache也是以列族来区分.
WAL
write ahead log,数据在刷新到hfile之前,先写到WAL中,保证不会因为服务器宕机而丢失.在regionserver宕机后,master会将之前的region转移到其它主机,并读取对应的WAL,重现region中的数据.参考oracle的redo log来理解
minorcompact
小合并,memstore中的数据刷新到磁盘成为一个个较小的hfile,当hfile数量达到一定数据量后,执行小合并,将这些小文件合并成一个较大的hfile.
majorcompact
大合并,将memstore刷出来的hfile(及小合并产生的较大hifle)与磁盘上(已经存在的,巨大的)的hfile合并,在合并的过程中删除被标记为删除的行.
region split
当一个region对应的hifle超过一定的大小之后,region将会分裂两个较小的region.新分裂的两个region可以在原来的regionserver上也可以在两个不同的regionserver上.
hbase架构
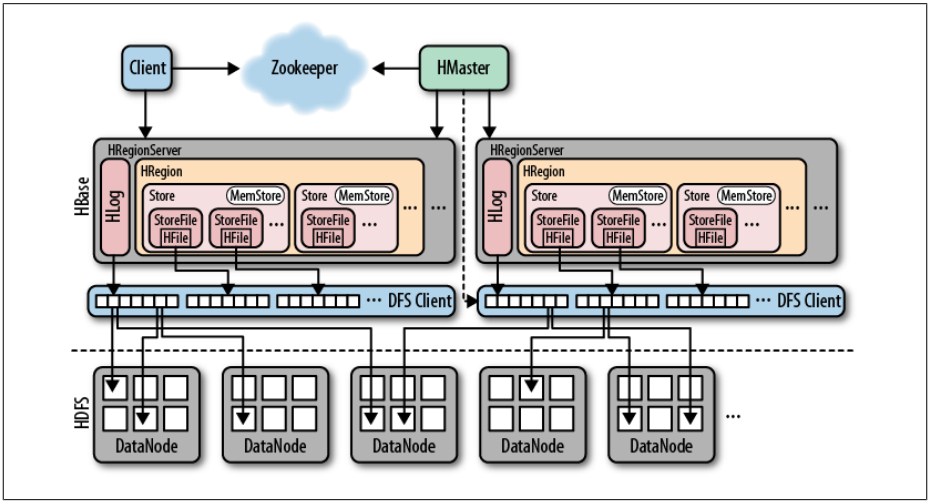
从上图可知,在hbase集群包括zookeeper master regionserver ,底层的存储用的是hdfs.regionserver中有region hstore memerycache hfile等
zookeeper
zookeeper:协调整个集群的运行.具体包括:
regionserver
1.保存regionserver的状态信息,当regionserver启动后,向zookeeper注册自己的状态以及region信息.master
1.确定集群中只有一个active的master.当master宕机后,实现failover.
2.master通过zk中注册的regionserver信息找到各个regionserver.master读取regionserver注册的信息来管理集群.元数据meta表
hbas将meta表保存在zk上,meta表中有region列表, 每个region的start rowkey, 对应的server地址. client访问meta表找到要读写的regionserver
master
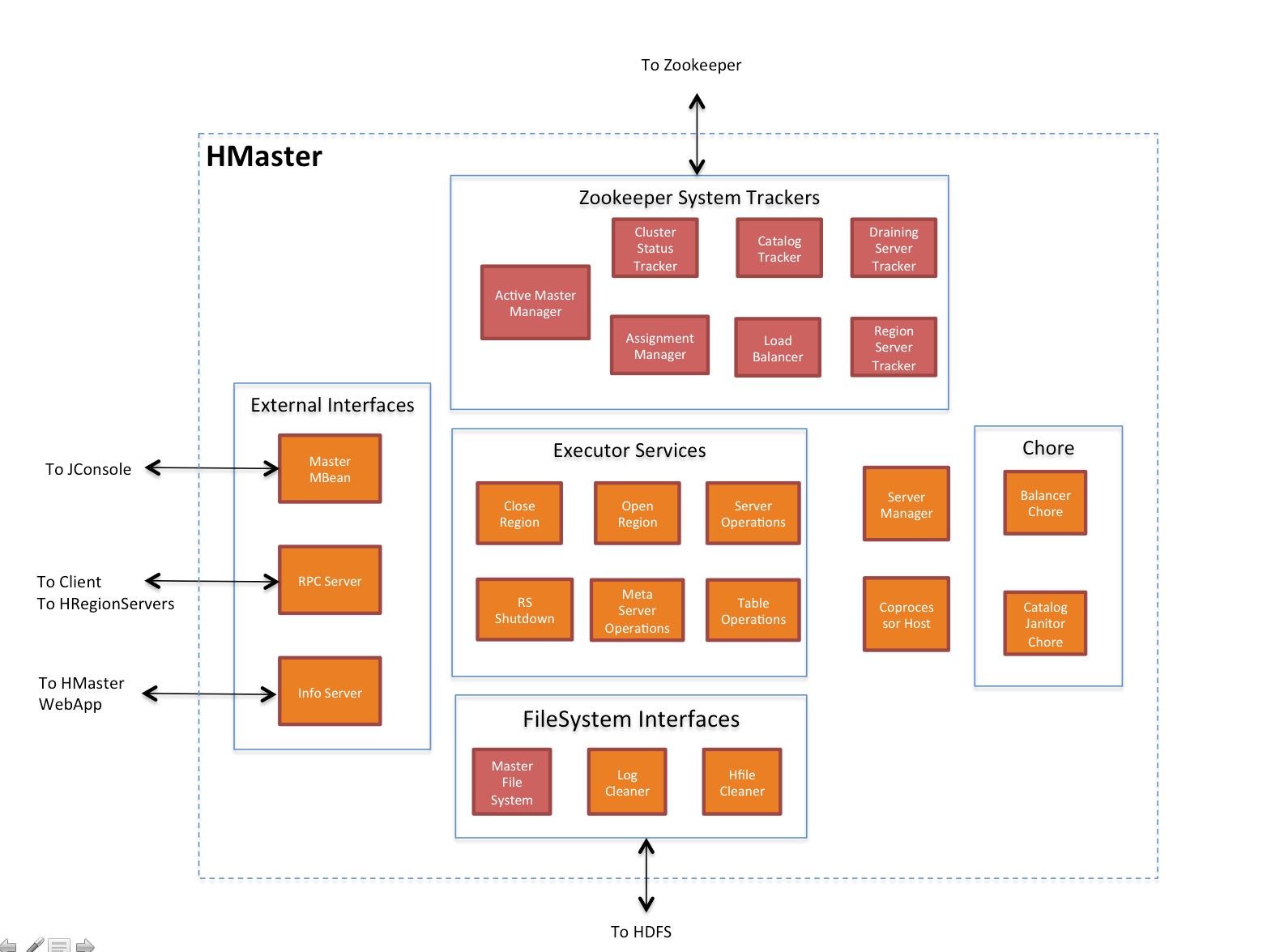
master是集群的管理节点,主要负责:
1.通过zk监控regionserver的运行状态
2.管理和分配region.在resionserver发生故障时,转移故障的regionserver上的region;当region发生分裂时,分配region;
3.提供相关操作接口
client可以调用这些接口,如创建\删除表,修改\增加列族等,移动\标记region等:
Table (createTable, modifyTable, removeTable, enable, disable) #表的修改 禁用等
ColumnFamily (addColumn, modifyColumn, removeColumn) #列族的修改
Region (move, assign, unassign) For example, when the Admin method disableTable is invoked, it is serviced by the Master server. #region的变动
4.负载均衡
master每隔一段时间(默认5分钟)启动一次平衡器,如果集群中没有region in transition(没有region在过渡?应该是在分裂\合并等)且region分布满足不均衡的条件,则会执行平衡,使用各个节点的region数量满足一条的均衡条件.
5.检查并清理元数据
master会定期的检查meta表.如发现有parent region可以清理(一个较大的region分裂成两个region,原来的region叫parent region),则清理meta中的相关信息
关于master更详细的说明,参考:
http://blog.zahoor.in/2012/08/hbase-hmaster-architecture/
regionserver
regionserver是hbase中最重要的组件,主要作用是:
1.操作数据(并提供相应接口)\保存数据到hdfs:put get scan delete
2.管理region(并提供相应接口):split region,compact region,转移region等
3.CompactSplitThread:处理小合并
4.MajorCompactionChecker:处理大合并
5.MemStoreFlusher:刷memstore到hdfs
6.写wal
7.LogRoller:滚动wal日志
8.提供协处理器接口完成复杂操作
9.管理blockcache
hbase的表

表结构
hbase中的数据按表存储,表由两部分组成:rowkey,列族.
- rowkey
表的索引,中的ra,rb,rc即是rowkey,通过rowkery访问表中的数据.rowkey按照字典顺序由小到大排列. - version
表中的每一条数据都按时间生成一个版本,默认下按key访问时只返回最新的版本,可以指定返回特定的版本,如通过ra默认返回ra,v13这一行.hbase对同一rowkey默认保存3个版本,建表时可以指定 - 列族
即是key-value中的"value",一个列族中可以包含多个列,列可以不是固定的,并可以动态增减列.数据按列族中的数据存储在一起,图中CF1和CF2两个列族分别存储在不同的hstore中,因此hbase是列式存储的数据库.
表的读写
hbase支持查询\插入\更新\删除操作,通过get|scan put delete完成操作
- scan
可以指定起始和终止的rowkey执行范围扫描,默认返回表的所有数据,可以加过滤器选择特定的列族\列\版本等. - get
查询指定rowkey的数据,可以指定列族\列\版本等,本质上是调用scan - put
通过put向hbase中写入数据,如果没有该rowkey则增加一条数据,有该rowkey则修改该条数据(本质上是该rowkey增加一个新版本).put可以一次写入一条或者多条数据,每次执行put操作都会执行一次rpc请求. - delete
从表中删除指定rowkey的数据,可以只删除指定的版本.当数据被delete后,并不是立刻从hbase表中被清除,只是打上删除标记,在下一次major compact(大合并)时从表中删除.
hbase的元数据表
hbase:meta记录了所有的region信息,该表存储在hbase,当使用hbase shell执行list时不会显示这张表.
在hbase0.96之前,region的信息由两张表保存:-ROOT-和.META
-ROOT-
-ROOT-存储了.META的位置,表结构如下:
Key : .META. region key (.META.,,1) #.META表的region编号
Values:
info:regioninfo (serialized HRegionInfo instance of hbase:meta) #序列化的hbase:meta表的region信息
info:server (server:port of the RegionServer holding hbase:meta) #管理hbase:meta表的regionserver地址
info:serverstartcode (start-time of the RegionServer process holding hbase:meta) # 管理hbase:meta表的regionserver的启动时间
在hbase0.96之前,zookeeper中存储了-ROOT-在hbase中的位置,客户端先连接zookeeper读取到-ROOT-的所在的regionserver,然后找到-ROOT-表,读取该表得到.META表所在的regionserver,然后再连接到.META所在的regionserver,再通过.META表查出要查的rowkey所在的regionserver:
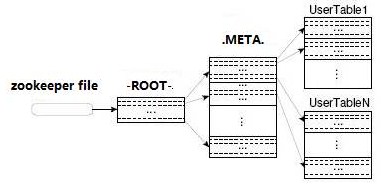
客户端第一次查询一共要经过4次查找才能定位到特定的region.之后客户端将缓存-ROOT-表和.META表的一部分.
hbase:meta
在hbase0.96之后,去掉了-ROOT-表(因为不需要支持那么多的region),并且将.META改名为hbase:meta. hbase:meta中保存了hbase中所有的region信息.
客户端通过zookeeper查询到hbase:meta所在的regionserver后,连接到该regionserver,查找regionserver表,查找要查询的rowkey所在的regionserver,连接该server查询.
中间少了查询-ROOT-一步,效率会提高.
客户端会缓存meta表的信息,优先从本地缓存查找regionserver,但如果region发生了变动(如regionserver挂了\region分裂了),缓存失效,就需要按上面的步骤重新缓存.
hbase:meta表结构:
Key : Region key of the format ([table],[region start key],[region id])
Values:
info:regioninfo (serialized HRegionInfo instance for this region)
info:server (server:port of the RegionServer containing this region)
info:serverstartcode (start-time of the RegionServer process containing this region)
http://hbase.apache.org/apidocs/org/apache/hadoop/hbase/HRegionInfo.html 中提到:
key中包含:
tableName : The name of the table
startKey : The startKey for the region.
regionId : A timestamp when the region is created.
replicaId : An id starting from 0 to differentiate replicas of the same region range but hosted in separated servers. The same region range can be hosted in multiple locations.
encodedName : An MD5 encoded string for the region name.而info:regioninfo 这一列包含:
endKey : the endKey for the region (exclusive)
split : Whether the region is split
offline : Whether the region is offline因此从hbase:meta表中能取到tableName\startKey\regionId\regionName\endKey\split状态\是否在线这些重要信息.
如果key中的[region start key]是空的,则是该表的第一个region,如果endkey也是空,则该表只有这一个region.
当一个region分裂成两个region时,会在对应的hbase:meta行中插入两个行:info:splitA info:splitB列的值也是序列化后的region名,代表两个新的region.当分裂完成后,在hbase:meta中删除父region所在的行,同时插入两个子region信息
Block Cache
在hbase中有两种读缓存的实现:LruBlockCache 和BucketCache.
LruBlockCache是比较原始的,完全在java heap中.虽然也可以使用heap,但BucketCache更倾向使用off-heap,此外也可以用文件做缓存.
和使用heap的LruBlockCache相比,BucketCache要慢一些.由于BucketCache倾向于使用更少的heap,因此在gc时需要处理的内存区域就小一些.对于off-heap部分的内存,完全由BucketCache管理而不是GC来管理.当BucketCache完全使用off-heap时,GC对BucketCache没有任何影响.由于减少甚至杜绝了GC的影响,所以使用BucketCache时hbase的访问延迟相对更稳定.
当使用BucketCache时,将会有两层的读缓存.L1层由LruBlockCache组成,L2层由BucketCache组成.L1层主要缓存元数据块:index块和bloom块.L2层主要缓存数据块.两个层之间的数据移动和管理由CombinedBlockCache类来决定.
LruBlockCache的设计
LruBlockCache有三中优化级:
1.当数据块第一次被读到时,此时优先级最低,在下一次清理内存时优先清理这些块.
2.当该块多次被读取时,优先级提升,清理完1中的块后内存还不够才考虑清理这些块.
3.如果一个列族被标记为"in memery"时,优先级最高,不会被从内存中清除.hbase:meta就是这样.
LruBlockCache的使用
hbase中可用来缓存的内存总量:
number of region servers * heap size * hfile.block.cache.size * 0.99hfile.block.cache.size表示blockcache最大使用的堆内存,默认是
在LruBlockCache中,存储的内容有以下几项
- -ROOT-表和hbase:meta
-ROOT-表和hbase:meta表被缓存中内存中,而且是最高优先级的.-ROOT-只会使用极少的内存,hbase:meta使用的也不多. - hfile indexs
hfile的中的索引也缓存在内存中,至于缓存多大的索引内容,由rowkey的长短以及所存储的数据决定.即使很大的数据量,index一般也不会超过1G.hbase往往只缓存一部分的index,因为lru策略会及时的将不常用的索引清除出内存. - key
这一点没看明白,原文
The values that are stored are only half the picture, since each value is stored along with its keys (row key, family qualifier, and timestamp)
这里说的应该是数据,把常用的数据缓存在内存中.key和values部分是放在一起的. - Bloom Filters
布隆过滤器数据的数据也存储在LRU中
关于LruBlockCache使用的要点
缓存在LruBlockCache中的数据应该是被经常用到的,像hbase:meta表一样.以下情况应该关闭表的缓存:
1.几乎全是随机查询
这种情况下,同一行很难被多次查到,如果在这样的表上做缓存,只会浪费内存和CPU时间,更重要的是会增加GC负担.因此这种情况下关闭表的缓存
2.mapreduce映射表
比如将hbase表映射到hive中做分析,hive往往只读一次,这时应该设置扫描对象关闭缓存setCaching(false)
非堆内存off-heap
- 设置bucketcache使用的缓存种类
前面说过bucketcache可以使用heap\off-heap\file来做缓存.设置hbase.bucketcache.ioengine为heap off-heap file:PATH_TO_FILE 来决定bucketcache使用的内存种类. - 缓存策略
前面已经说过,默认情况下,当启用了bucketcache后,会出现两层缓存:L1 L2.L1是LRUcache,用来缓存index和布隆过滤器数据;L2是bucketcache,用来缓存实际的数据.从hbase1.0之后可以修改这个设置.比如将index\bloom和数据都缓存到
L1中,当L1查找不到时再到L2中查找.设置HColumnDescriptor.setCacheDataInL1(true)或者在shell中执行:
hbase(main):003:0> create 't', {NAME => 't', CONFIGURATION => {CACHE_DATA_IN_L1 => 'true'}}通过上面的设置将数据也缓存在L1中.
绕过CombinedBlockCache:设置CacheConfig.BUCKET_CACHE_COMBINED_KEY=false.此时,数据被缓存在L1 L2中,当L1中找不到数据时,将去L2去找.这种情况称为:Raw L1+L2
- 启动off-heap
1.修改hbase-evn.sh,设置非堆内存的大小:
HBASE_OFFHEAPSIZE=5G2.修改hbase-site.xml
设置hbase.bucketcache.ioengine为offheap,设置hbase.bucketcache.size为>0的值.
<property>
<name>hbase.bucketcache.ioengine</name>
<value>offheap</value>
</property>
<property>
<name>hfile.block.cache.size</name>
<value>0.2</value>
</property>
<property>
<name>hbase.bucketcache.size</name>
<value>4196</value>
</property>分别设置了bucketcache的类型,lrucache所占heap的比例,bucketcache的大小.
3.重启整个集群,或者滚动重启regionserver
- 关于DirectMemory
DirectMemory指的是直接内存,即非JVM管理的内存,基本上也可以叫off-heap(off-heap中还有一小部分早JVM管理的栈),bucketcache设置为offheap时使用直接内存.因此,hbase-env.sh中设置的-XX:MaxDirectMemorySize要
大于hbase.bucketcache.size .此外,有些组件也使用直接内存,如DFSclient.在hbase-site.xml中,每个DFSclient使用120K的内存,由于参数hbase.dfs.client.read.shortcircuit.buffer.size决定.DFSclient总共使用的直接内存大小=打开的hfile数*hbase.dfs.client.read.shortcircuit.buffer.size . 在hbase的webUI上可以看到使用的堆内存和直接内存.
blockcache压缩
缓存延迟解压,数据将以在磁盘上的形势保存到缓存中,而不是在缓存之前解压.
测试(官方文档上):
对于有太多region要处理的机器上,无法缓存这么多的数据,启用压缩后,平移吞吐量提升50%,延迟提升30%,而GC提升80%,CPU使用提升2%.默认是不开启延迟解压.
WAL
wal是write ahead log,意思写在前面的日志,即数据会在写入memestore之前写入到WAL中持久化到磁盘上。WAL会记录hbase中所有的数据变更。如果没有WAL,当RS宕机后,memstore中数据会丢失。开启WAL后,当RS宕机后,数据可以从WAL中恢复。WAL在/hbase/WALs/目录下以region划分子目录。一个RS上只有一个WAL进程,负责写所有的region的数据。
在hbase1.0之前,只有一个管道写WAL,1.0之后,可以设置多个管理并行写WAL.多管道并行写是按region做了分区来写WAL,如果只有一个region,那多管道写入不起作用.
<property>
<name>hbase.wal.provider</name>
<value>multiwal</value>
</property>- WAL的大小:
按照官方的说话,要经HDFS块小一点,大约是HDFS块的95即可. - WAL的数目
按官方文档,在恢复时,要满足能恢复所有的memestore的状态,那么要参考memstore用的内存.那么一节点上WAL的数目应该是:RS的内存0.4/(hdfsblock.95).0.4是memstore占堆内存的比例.
例如:RS的内存是16G,一般memsotre占堆的40%,HDFS块是128MB,那么需要的WAL数是:1610240.4/(128*.95)=53.89个.但一般不需要这么多,大根一半的数目即可,因为不可能每个memstore在故障发生时都是满的
WAL切分
当RS宕机分,需要转移其上的region,这个时候就要把对应的WAL读出来构建一个个对应的region数据交给其它节点来处理
regions
region是表按rowkey分割出来的区域。如表中的rowkey由字母开关,按A-H I-Z可以划分出来两个region.
region是表获取和分布的基本元素,由每个列族的一个库(Store)组成。对象层级图如下:
Table (HBase table)
Region (Regions for the table)
Store (Store per ColumnFamily for each Region for the table)
MemStore (MemStore for each Store for each Region for the table)
StoreFile (StoreFiles for each Store for each Region for the table)
Block (Blocks within a StoreFile within a Store for each Region for the table)
region的个数
一般来说,每个RS上的region数目不应该太多.按官网的说法"HBase is designed to run with a small (20-200) number of relatively large (5-20Gb) regions per server",即RS运行20-200个5-20GB大小的region
控制region的个数据
为什么要控制region的个数据?
- region过多
1.每个memstore需要2MB的内存,每个region至少有一个memstore,如果有1000个region,则需要3.9GB的内存空间,这个空间不存储任务数据
2.过多的region会有过多的memstore,在总的heap内存不变的情况下,每个memstore的内存变小,很容易填满memsotre,导致各个memstore不停的刷到磁盘,占用大量的磁盘IO导致读写性能下降。
3.master要不断的检测region的分裂,不断的做region迁移.过多的region还会严重增加ZK的负担
4.在0.90及之前的版本,RS上的region太多会增大storefile的索引使用内存,有可能会引起OOM.
5.当启动mapreduce任务时每个region都对应一个mapreduce任务,太多的region会导致太多的mr任务 - region过少
1.影响扩展性.如果一张表5G大小,如果region大小为10G,那么只会在一个RS,这样只有一个服务器影响请求,读写性能都不高.如果region大小为1G,则会有5个RS来处理
region的分配
1.hbase启动时
当HBase启动时,区域分配如下(短版本):
- 启动时master调用
AssignmentManager. AssignmentManager在META 中查找已经存在的region分配。- 如果regionr分配还有效(如 RegionServer 还在线) ,那么对这此region的分配继续有效。
- 如果region的已经分配失效,
LoadBalancerFactory被调用来分配region。 - 随Region的分配,master将更新meta表,随后RegionServer 打开region
从以上的步骤看出,region的分配是由master来完成的,如果在master启动AssignmentManager时,之前分配的region依然有交,则继续使用。如果失效,将会使用LoadBalancerFactory来分配Region到RS.如果分配的过程中Region的信息变了,那么master将更新meta表。
2.故障转移
当RS出现故障时:
1.RS上的region立刻不可用
2.master检测到RS宕机
3.region被标记为不可用,并转移到其它RS上.
4.客户端的查询会重试,然后转移到其它RS上查询
花费的时间:
ZooKeeper session timeout + split time + assignment/replay time
region的状态
每个region都被标记为一种状态,保存在hbase:meta表中.而保存meta表本身的region的状态保存在zookeeper中。
- OFFLINE: the region is offline and not opening
- OPENING: the region is in the process of being opened
- OPEN: the region is open and the RegionServer has notified the master
- FAILED_OPEN: the RegionServer failed to open the region
- CLOSING: the region is in the process of being closed
- CLOSED: the RegionServer has closed the region and notified the master
- FAILED_CLOSE: the RegionServer failed to close the region
- SPLITTING: the RegionServer notified the master that the region is splitting
- SPLIT: the RegionServer notified the master that the region has finished splitting
- SPLITTING_NEW: this region is being created by a split which is in progress
- MERGING: the RegionServer notified the master that this region is being merged with another region
- MERGED: the RegionServer notified the master that this region has been merged
- MERGING_NEW: this region is being created by a merge of two regions
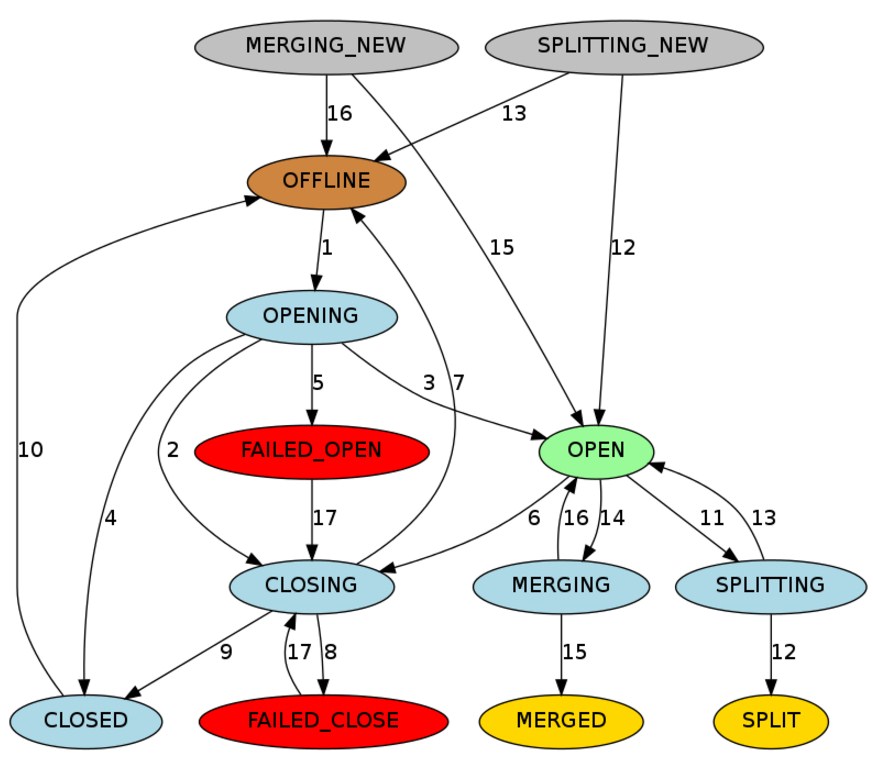
褪色:offline状态,可能是region的瞬间状态(如关闭之后打开之前),最终状态(被disable的表的region状态),或者初始化的状态(新建的表的region状态)
浅绿色:打开状态
淡蓝色:瞬间状态
红色:错误状态
黄色:regions split或者merged的最终状态
灰色:regions split或者merged初始状态
上图的流程:
1.master将region的状态从OFFLINE置为OPENING(也就是分配region的过程).这个过程中,会通知RS,如果RS没有接收到RPC请求,master会重试向RS发RPC请求,直至RS响应或者超过重试次数.
RS接收到请求后将会打开region
2.master向RS的RPC请求达到最大重试次数而RS未响应后,master会阻止RS打开这个region,并将region的状态置为CLOSING,即使RS已经准备打开这个region.
3.RS打开region后,将通知master将region的状态置为OPEN,master修改region状态后,会通知RS,此时这个region已经打开,并可以使用。
4.如果RS不能打开region,则master将region标识为CLOSED,并尝试将region转移到其它RS打开。
5.如果master不能在一定数量的RS上打开该region,master将该region标记为FAILED_OPEN,此时region将不能打开,直到通过hbase shell来处理,或者从ZK中确认该RS已经宕机(后再将该region分配给其它的RS)。
6.关闭region。master向RS发送RPC请求,一直到RS响应或者master请求超时,这个过程中region是CLOSING状态。
7.如果RS不在线或者抛出NotServingRegionException,master将region状态置为OFFLINE,并分配给其它RS打开。
8.当master要关闭region时,无法连接上RS,则master将region的状态置为FAILED_CLOSE,此时region将不能打开,直到通过hbase shell来处理,或者从ZK中确认该RS已经宕机。
9.当master要关闭RS上的region时,RS关闭成功后,master将region状态设置为CLOSED.
10.在分配region之前,master将CLOSED状态的region设置为OFFLINE
11.当region需要分裂时,RS会通知master,master将region的状态由OPEN设为SPLITTING,并且为RS分配两个新的region,这两个新的region的状态为SPLITTING_NEW
12.当region分裂完全后,即已经建了子region到父region的指针后,master将父region的状态从SPLITTING设置为SPLIT,将子region的状态从SPLITTING_NEW设置为OPEN
13.如果region分裂失败,则将父region的状态从SPLITTING设置为OPEN,将两个子region的状态从SPLITTING_NEW设置为OFFLEIN
14.当两个region要合并时RS会通知master,master为RS分配一个新的region,master将两个region的状态从OPEN设置为MERGING,并新分配的region状态设为MERGING_NEW
15.当合并完成后,master将之前合并的两个region的状态从MERGING设置为MERGED,合并后的region状态从MERGING_NEW设置为OPEN
16.如果合并失败,则将两个region的状态由MERGING设置为OPEN,将用来合并的region状态由MERGING_NEW设置为OFFLINE
17.如果region处于FAILED_OPEN和FAILED_CLOSE状态,当用户通过hbase shell执行重分配时,master尝试将其关闭。
region的本地化
region的本地化是和hfds一起的:
1.第一个副本写在本地,跟RS在一起
2.第二个副本写在同一个机架上的不同节点上
3.第三个副本写在不同机架上的节点上。
超过三个副本的,随机写到集群上的节点上。
当启动region平衡后,region存储的文件 可能和对应的RS不在同一台主机上,但是新写入数据是在本地的。当compact后,region对应的store也会本地化。
region的分裂
region分裂的过程
写入hbase的数据会先与到memstore中,当memstore写满后就会刷到磁盘上的hfile中.当一个region管理的hfile大小超过一定的值后,会将该region分裂为两个较小的region.region分裂以父region的rowkey的中值为界分成两个.分裂时,如果父region还在被使用,则不会立刻将父region下线,只是将分裂成的两个子region的指针分别指向父region的一部分.
region分裂是regionserver自己做出的决策,但是这个过程需要master协助处理.在region分裂前和分裂后会通知master修改meta的region信息,以便客户端能及时检查到最新的region.
分裂过程如下:
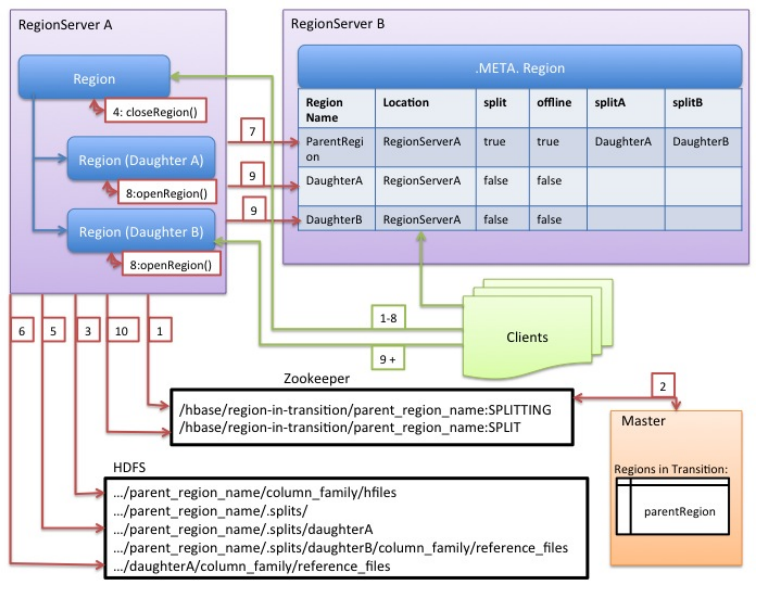
1.regionserver检测到region需要分裂,首先对表加共享锁,防止表结构在分裂的过程中修改.然后RS在zookeeper中/hbase/region-in-transition/region-name路径下创建一个znode,并将znode状态设置为SPLITING
2.master通过在region-in-transition上观察者发现了有region要分裂.
3.RS在父region上HDFS目录下创建.spits子目录
4.RS在节点上关闭要分裂的region.此时如果客户端要查询这个region会返回NotServingRegionException.
5.RS在.split目录下创建子region的目录,并创建相应的数据结构. 在.split下子region目录中建立两个引用指向父region分裂成的两个storefile(以中值rowkey,分成两部分,但数据并为分裂).此步只会在原父region的目录.split中创建指针指向父region,而不真正的分裂父region的store文件
6.在hdfs为子region创建region目录,并将指向父region的指针文件放到hdfs上子region的目录中.
7.完成以上步骤后,RS将请求修改meta表中region的状态为offline,并增加两列splitA splitB,值是分裂成的两个region.此时并不会先插入子region的条目,所以客户端不会发现分裂出来的两个region.一旦写入meat表完成,父region就会真正的进行分裂。如果在请求修改meta表状态时RS挂了,那么其它的RS将会恢复这个RS,并继续分裂。
8.当父region真正分裂完毕后,RS将会同时打开两个子region
9.RS向meta表插入子region的信息,然后客户端就能找到分裂出的region了。(不删除父region的条目吗?)
10.RS修改znode /hbase/region-in-transition/region-name状态为SPLIT,这样master可以检测到分裂出来的region,检查是否需要启动均衡器
11.虽然到此分裂过程已经完成了,但是两个子region中的数据实际上是引用父region的,hdfs上子region目录中并没有真正的数据,数据还在父region的目录中,等到下一次子region执行compaction时,将会把数据从父region写到子region中。当子region不再引用父region时,会删除父region的数据。
从上面的步骤来看,在region分裂时,只是创建了对父region的引用,并未实际分裂父region的数据,当下一次compact时,才会写数据。而且两个子region在没有合并之前也是在父region上的RS上的,合并后才会转移数据.
手工分裂Region
用户可以在表创建时就分裂表(预分区),或者在创建表后手动分裂。
手动分裂region的原因:
1.region热点。比如rowkey是排好序的,那么只有最新插入数据的RS在工作,其它节点是空闲的,hbase集群变了间节点工作,不能发挥集群的能力。
2.当大量插入数据后,希望快速的将数据平均分配在各个节点上。
- 设置region分裂的类
用户可以编写自己的类来控制region的分裂行为,必须继续IncreasingToUpperBoundRegionSplitPolicy类。
修改控制region分裂的类:
<property>
<name>hbase.regionserver.region.split.policy</name>
<value>org.apache.hadoop.hbase.regionserver.IncreasingToUpperBoundRegionSplitPolicy</value>
</property>也可以在shell中控制
hbase> create 'test', {METADATA => {'SPLIT_POLICY' => 'org.apache.hadoop.hbase.regionserver.ConstantSizeRegionSplitPolicy'}},{NAME => 'cf1'}
或者在代码中设置:
HTableDescriptor tableDesc = new HTableDescriptor("test");
tableDesc.setValue(HTableDescriptor.SPLIT_POLICY, ConstantSizeRegionSplitPolicy.class.getName());
tableDesc.addFamily(new HColumnDescriptor(Bytes.toBytes("cf1")));
admin.createTable(tableDesc);
----region的合并
region的合并是clinet发起的请求。(合并的意义是?如果不修改hfile的大小,那么最终不又要分裂?)。client发请求给master,然后master找到负载最大的RS,通知RS合并其上的Region.和split类似,也是先在hbase:meta里插入一条合并后的region的信息,并修改要合并的两个Region的状态为merging。在建立了引用后,就返回合并成功,等到compact时才会真正的合并region.一般来说,只有相邻的region才会合并。
以下是一个例子:
$ hbase> merge_region 'ENCODED_REGIONNAME', 'ENCODED_REGIONNAME'
$ hbase> merge_region 'ENCODED_REGIONNAME', 'ENCODED_REGIONNAME', true带true表示不但建立真正的合并,即立刻做compact合并磁盘上的数据
hstore
hstore是用来存储region中的列族的逻辑单位。hstore包括一个内存结构memstore和磁盘结构storefile(hfile).注意,每个列族都有一个hstore来保存数据。
memstore
memstore是region中列族的写缓冲,向列族中写入的数据,首先会保存到memstore中。当memstore写满后会flush将数据持久化到磁盘上。注意,每次flush memstore时,同一个region的所有memsotre都会flush.
换句话说,如果表中有多个列族,当一个列族发生flush memstore时,所有列族的memstore都会flush,导致同一时刻大量磁盘的I/O,这就是为什么不要建多个列族的原因。
memstore flush的原因
1.当一个region的memstore达到hbase.hregion.memstore.flush.size的大小,则该region的所有memstore都刷到磁盘
2.当RS上的所有memestore使用的内存大小达到hbase.regionserver.global.memstore.upperLimit时,会按memstore的大小降序flush到磁盘,直到满足hbase.regionserver.global.memstore.lowerLimit这个条件。
3.当RS上的WAL已经写满hbase.regionserver.max.logs指定的WAL个数,则会按memstore存在的时间倒序flush memstore。(WAL只是为了在RS宕机时恢复memstore的数据,WAL是滚动写入的,只会暂时持久化到磁盘)
scan操作读memstore
1.当client对一个表做scan时,hbase针对每个region创建一个RegionScanner来响应scan请求。
2.每个 RegionScanner对象包含一个StoreScanner对象列表,每个列族都都有一个StoreScanner
3.每个StoreScanner包含一个StoreFileScanner对象列表(读storefile)和一个KeyValueScanner对象列表(读)。最终这两个列表合并从一个.
4.当StoreFileScanner对象创建后,会与MultiVersionConcurrencyControl协作找出读取时间点read point对应的memstore即memstoreTS,memstoreTS过滤掉了memstore中read point之后更新。
hbase存储与文件格式
keyvalue
key values在磁盘上存储为一个字节数组,注意是在一个字节数组中.
keyvalues字节数组存有 keylength | valuelength | key value这几项,其中key部分存有
rowlength | row | columnfamilylength | columnfamily | columnqualifier | timestamp | keytype

2.hbase原理(未完待续)的更多相关文章
- Reading | 《数字图像处理原理与实践(MATLAB版)》(未完待续)
目录 一.前言 1.MATLAB or C++ 2.图像文件 文件头 调色板 像素数据 3.RGB颜色空间 原理 坐标表示 4.MATLAB中的图像文件 图像类型 image()函数 imshow() ...
- C++语言体系设计哲学的一些随想(未完待续)
对于静态类型语言,其本质目标在于恰当地操作数据,得到期望的值.具体而言,需要: (1)定义数据类型 你定义的数据是什么,是整形还是浮点还是字符.该类型的数据可以包含的值的范围是什么. (2)定义操作的 ...
- 从Socket入门到BIO,PIO,NIO,multiplexing,AIO(未完待续)
Socket入门 最简单的Server端读取Client端内容的demo public class Server { public static void main(String [] args) t ...
- 数据库索引(Index)【未完待续】
数据库索引是啥?有什么用?原理是什么?最佳实践什么? 索引是啥 一个索引是这样的数据结构:从数据上来说,不仅包含了从表中某一列或多列的数据拷贝,同时,还包含了指向这列数据行的链接: 从结构上来说,索引 ...
- javascript有用小功能总结(未完待续)
1)javascript让页面标题滚动效果 代码如下: <title>您好,欢迎访问我的博客</title> <script type="text/javasc ...
- ASP.NET MVC 系列随笔汇总[未完待续……]
ASP.NET MVC 系列随笔汇总[未完待续……] 为了方便大家浏览所以整理一下,有的系列篇幅中不是很全面以后会慢慢的补全的. 学前篇之: ASP.NET MVC学前篇之扩展方法.链式编程 ASP. ...
- 关于DOM的一些总结(未完待续......)
DOM 实例1:购物车实例(数量,小计和总计的变化) 这里主要是如何获取页面元素的节点: document.getElementById("...") cocument.query ...
- 我的SQL总结---未完待续
我的SQL总结---未完待续 版权声明:本文为博主原创文章,未经博主允许不得转载. 总结: 主要的SQL 语句: 数据操作(select, insert, delete, update) 访问控制(g ...
- virtualbox搭建ubuntu server nginx+mysql+tomcat web服务器1 (未完待续)
virtualbox搭建ubuntu server nginx+mysql+tomcat web服务器1 (未完待续) 第一次接触到 linux,不知道linux的确很强大,然后用virtualbox ...
随机推荐
- c#聊聊文件数据库kv
现在有很多KV嵌入式存储,或者已经增加的.leveldb,RaptorDB等,都是相对比较好的存储.基本存储,一般配置.大概在6w/s左右.当然还有缓存等设置问题.这些基本是字符串和int的存储,对于 ...
- 记一次MySQL中Waiting for table metadata lock问题的处理
起因:由于需要,要把一张表的一个字段从不是 null 改成 可null,我用的Navicat Premium ,但是在保存的时候,工具无响应了,几个同事操作都是这样的,很奇怪,怀疑是不是由于表被锁了还 ...
- 用原生JS写一个网页版的2048小游戏(兼容移动端)
这个游戏JS部分全都是用原生JS代码写的,加有少量的CSS3动画,并简单的兼容了一下移动端. 先看一下在线的demo:https://yuan-yiming.github.io/2048-online ...
- SQL Server 2012 - SQL查询
执行计划显示SQL执行的开销 工具→ SQL Server Profiler : SQL Server 分析器,监视系统调用的SQL Server查询 Top查询 -- Top Percent 选择百 ...
- phpcms v9 完美更换整合Ueditor 1.3
phpcms这套系统相信大家不陌生,它做的很不错,但是也有好多地方不满足我们的需求,比如在线编辑器. 它自带的是CKEditor编辑器,功能较少,比如代码加亮功能就没有. 所以我来说一下怎么替换php ...
- Python 爬虫 七夕福利
祝大家七夕愉快 妹子图 import requests from lxml import etree import os def headers(refere):#图片的下载可能和头部的referer ...
- (杭电2053)A + B Again(转换说明符)
Time Limit: 1000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total Submission(s): ...
- pygame---制作一只会转弯的小乌龟
Pygame Pygame是跨平台Python模块,专为电子游戏设计,包含图像.声音.建立在SDL基础上,允许实时电子游戏研发而无需被低级语言(如机器语言和汇编语言)束缚. 包含图像.声音. 建立在S ...
- Openstack Havana的两个排错过程
问题一:Timeout wating on RPC response, topic:"network" 描述: 启动实例一直等待,然后变为error.查看日志,是 timeout ...
- LeetCode: 59. Spiral Matrix II(Medium)
1. 原题链接 https://leetcode.com/problems/spiral-matrix-ii/description/ 2. 题目要求 给定一个正整数n,求出从1到n平方的螺旋矩阵.例 ...