Deep Residual Learning for Image Recognition论文笔记
Abstract
We present a residual learning framework to ease the training
of networks that are substantially deeper than those used
previously. We explicitly reformulate the layers as learning residual functions with reference to the layer inputs, instead of learning unreferenced functions. We provide comprehensive empirical evidence showing that these residual
networks are easier to optimize, and can gain accuracy from
considerably increased depth.
本文主要是提出了一种残差学习的框架,能够简化使那些非常深的网络的训练,该框架使得层能根据其输入来学习残差函数而非原始函数
Introduction
An obstacle to answering this question was the notorious
problem of vanishing/exploding gradients [1, 9], which
hamper convergence from the beginning. This problem,
however, has been largely addressed by normalized initialization [23, 9, 37, 13] and intermediate normalization layers, which enable networks with tens of layers to start converging for stochastic gradient descent (SGD) with backpropagation [22].
堆叠多层网络的时候,存在梯度消失/梯度爆炸的问题,阻碍模型收敛,这一问题已经被 normalized initialization和 intermediate normalization解决。
The degradation (of training accuracy) indicates that not
all systems are similarly easy to optimize. Let us consider a
shallower architecture and its deeper counterpart that adds
more layers onto it. There exists a solution by construction
to the deeper model: the added layers are identity mapping,
and the other layers are copied from the learned shallower
model. The existence of this constructed solution indicates
that a deeper model should produce no higher training error
than its shallower counterpart.
但是网络可以收敛,又出现了退化问题,随着网络深度增加,准确率逐渐达到饱和然后迅速退化,这种情况不是因为过拟合产生的

In this paper, we address the degradation problem by
introducing a deep residual learning framework.

提出了一种深度残差学习的框架,本来的输入是x,期望输出是H(x),现在把原本的x通过恒等映射直接给到期望输出去,所以我们的网络需要学习的部分是F(x)=H(x)-x也就是残差,改变了原本的学习的目标
Identity shortcut connections add neither extra parameter nor computational
complexity. The entire network can still be trained
end-to-end by SGD with backpropagation, and can be easily
implemented using common libraries (e.g., Caffe [19])
without modifying the solvers.
shortcut connections 跨越一层或者多层
在原来网络的基础上,跳过一层或者多层来进行恒等映射,不增加额外的参数,不会增加计算的复杂度。
We show that: 1) Our extremely deep residual nets
are easy to optimize, but the counterpart “plain” nets (that
simply stack layers) exhibit higher training error when the
depth increases; 2) Our deep residual nets can easily enjoy
accuracy gains from greatly increased depth, producing results
substantially better than previous networks.
这种网络的优点有:
1) 更容易优化(easier to optimize)
2) can gain accuracy from increased depth,即能够做到网络越深,准确率越高
解决了深层网络的退化问题,也可以解决梯度消失的问题
1) 当F和x相同维度时,直接相加(element-wise addition):
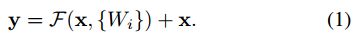
这种方法不会增加网络的参数以及计算复杂度。
2) 当F和x维度不同时,需要先将x做一个变换(linear projection),然后再相加:

Ws可能是卷积也可能是0-padding

Plain网络。
The convolutional layers mostly have 33 filters and
follow two simple design rules: (i) for the same output
feature map size, the layers have the same number of filters;
and (ii) if the feature map size is halved, the number
of filters is doubled so as to preserve the time complexity
per layer. We perform downsampling directly by
convolutional layers that have a stride of 2.
卷积层主要为3*3的滤波器,并遵循以下两点要求:(i) 输出特征尺寸相同的层含有相同数量的滤波器;(ii) 如果特征尺寸减半,则滤波器的数量增加一倍来保证每层的时间复杂度相同。我们直接通过stride 为2的卷积层来进行下采样。在网络的最后是一个全局的平均pooling层和一个1000 类的包含softmax的全连接层。加权层的层数为34.
残差网络。
When the dimensions increase (dotted line shortcuts
in Fig. 3), we consider two options: (A) The shortcut still
performs identity mapping, with extra zero entries padded
for increasing dimensions. This option introduces no extra
parameter; (B) The projection shortcut in Eqn.(2) is used to
match dimensions (done by 11 convolutions). For both
options, when the shortcuts go across feature maps of two
sizes, they are performed with a stride of 2.
维度改变时,考虑两种情况
(A) 仍然使用恒等映射,在增加的维度上使用0来填充,这样做不会增加额外的参数;
(B) 使用Eq.2的映射shortcut来使维度保持一致(通过1*1的卷积)。
对于这两个选项,当shortcut跨越两种尺寸的特征图时,均使用stride为2的卷积。

接下来把两种网络做了对比,残差网络和plain网络正好相反,在网络层数多的时候错误率反而低,而且根据表格数据,同样18层的时候,残差网络收敛更快
(图太多了放出来好麻烦,就这样吧。。。)
Deep Residual Learning for Image Recognition论文笔记的更多相关文章
- 论文笔记——Deep Residual Learning for Image Recognition
论文地址:Deep Residual Learning for Image Recognition ResNet--MSRA何凯明团队的Residual Networks,在2015年ImageNet ...
- [论文理解]Deep Residual Learning for Image Recognition
Deep Residual Learning for Image Recognition 简介 这是何大佬的一篇非常经典的神经网络的论文,也就是大名鼎鼎的ResNet残差网络,论文主要通过构建了一种新 ...
- Deep Residual Learning for Image Recognition这篇文章
作者:何凯明等,来自微软亚洲研究院: 这篇文章为CVPR的最佳论文奖:(conference on computer vision and pattern recognition) 在神经网络中,常遇 ...
- Deep Residual Learning for Image Recognition (ResNet)
目录 主要内容 代码 He K, Zhang X, Ren S, et al. Deep Residual Learning for Image Recognition[C]. computer vi ...
- [论文阅读] Deep Residual Learning for Image Recognition(ResNet)
ResNet网络,本文获得2016 CVPR best paper,获得了ILSVRC2015的分类任务第一名. 本篇文章解决了深度神经网络中产生的退化问题(degradation problem). ...
- Deep Residual Learning for Image Recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun Microsoft Research {kahe, v-xiangz, v-sh ...
- Deep Residual Learning for Image Recognition(残差网络)
深度在神经网络中有及其重要的作用,但越深的网络越难训练. 随着深度的增加,从训练一开始,梯度消失或梯度爆炸就会阻止收敛,normalized initialization和intermediate n ...
- 【网络结构】Deep Residual Learning for Image Recognition(ResNet) 论文解析
目录 0. 论文链接 1. 概述 2. 残差学习 3. Identity Mapping by shortcuts 4. Network Architectures 5. 训练细节 6. 实验 @ 0 ...
- Paper | Deep Residual Learning for Image Recognition
目录 1. 故事 2. 残差学习网络 2.1 残差块 2.2 ResNet 2.3 细节 3. 实验 3.1 短连接网络与plain网络 3.2 Projection解决短连接维度不匹配问题 3.3 ...
随机推荐
- js取整、四舍五入等数学函数
js只保留整数,向上取整,四舍五入,向下取整等函数1.丢弃小数部分,保留整数部分parseInt(5/2) 2.向上取整,有小数就整数部分加1 Math.ceil(5/2) 3,四舍五入. Math. ...
- MyBatis-Plus工具快速入门使用
MyBatis-plus有什么特色 1.代码生成 2.条件构造器 对我而言,主要的目的是使用它强大的条件构建器. 快速使用步骤: 1.添加pom文件依赖 <dependency> < ...
- RAC Cache Fusion Background Processes
Acdante--每日三省吾身-- . 什么是缓存融合? .缓存融合工作原理? .缓存融合关键进程以及作用?
- Pagination
using System.Collections.Generic; namespace Oyang.Tool { public interface IPagination { int PageInde ...
- hadoop jobhistory访问界面长时间打不开
1.浏览器无法直接通过url访问 可能原因 :主机名未配置,因此无法识别,在 c:\windows\system32\drivers\etc 目录添加主机名和对应ip hostname1[主机名 ] ...
- linux 搭建ss
因为收藏的各种教程被xx,所以决定自己写 第一步.安装ss sudo pip install shadowsocks 第二步.配置IP.端口.密码.加密方式 vi /etc/shadowsocks.j ...
- HCA数据下载
HCA data downloads HCA data downloads PeRl` 还记得去年看的时候还是什么都没有,今年已经有数据可以下载了.
- python中自定义超时异常的几种方法
最近在项目中调用第三方接口时候,经常会出现请求超时的情况,或者参数的问题导致调用异代码异常.针对超时异常,查询了python 相关文档,没有并发现完善的包来根据用户自定义的时间来抛出超时异常的模块.所 ...
- 成都Uber优步司机奖励政策(3月3日)
滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:http://www.cnblogs.com/mfry ...
- 成都Uber优步司机奖励政策(1月20日)
滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:http://www.cnblogs.com/mfry ...