【Python】Python简易爬虫爬取百度贴吧图片
通过python 来实现这样一个简单的爬虫功能,把我们想要的图片爬取到本地。(Python版本为3.6.0)
一.获取整个页面数据
def getHtml(url):
page=urllib.request.urlopen(url)
html=page.read()
return html
说明:
向getHtml()函数传递一个网址,就可以把整个页面下载下来.
urllib.request 模块提供了读取web页面数据的接口,我们可以像读取本地文件一样读取www和ftp上的数据.
二.筛选页面中想要的数据
在百度贴吧找到了几张漂亮的图片,想要下载下来.使用火狐浏览器,在图片位置鼠标右键单单击有查看元素选项,点进去之后就会进入开发者模式,并且定位到图片所在的前段代码
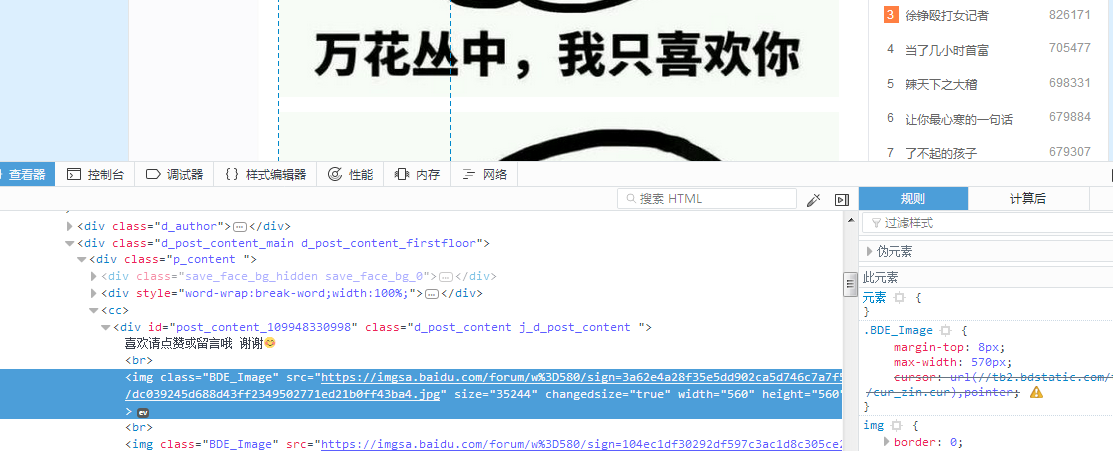
现在主要观察图片的正则特征,编写正则表达式.
reg=r'src="(https://imgsa[^>]+\.(?:jpeg|jpg))"'
#参考正则
编写代码
def getImg(html):
reg=r'src="(https://imgsa[^>]+\.(?:jpeg|jpg))"'
imgre = re.compile(reg)
imglist = re.findall(imgre,html.decode('utf-8'))
return imglist
说明:
re.compile() 可以把正则表达式编译成一个正则表达式对象.
re.findall() 方法读取html 中包含 imgre(正则表达式)的数据。
运行脚本将得到整个页面中包含图片的URL地址。
三.将页面筛选的数据保存到本地
编写一个保存的函数
def saveFile(x):
if not os.path.isdir(path):
os.makedirs(path)
t = os.path.join(path,'%s.img'%x)
return t
完整代码:
'''
Created on 2017年7月15日 @author: Administrator
'''
import urllib.request,os
import re def getHtml(url):
page=urllib.request.urlopen(url)
html=page.read()
return html path='D:/workspace/Python1/reptile/__pycache__/img' def saveFile(x):
if not os.path.isdir(path):
os.makedirs(path)
t = os.path.join(path,'%s.img'%x)
return t html=getHtml('https://tieba.baidu.com/p/5248432620') print(html) print('\n') def getImg(htnl):
reg=r'src="(https://imgsa[^>]+\.(?:jpeg|jpg))"'
imgre=re.compile(reg)
imglist=re.findall(imgre,html.decode('utf-8'))
x=0
for imgurl in imglist:
urllib.request.urlretrieve(imgurl,saveFile(x))
print(imgurl)
x+=1
if x==23:
break
print(x)
return imglist getImg(html)
print('end')
核心是用到了urllib.request.urlretrieve()方法,直接将远程数据下载到本地
【Python】Python简易爬虫爬取百度贴吧图片的更多相关文章
- Python简易爬虫爬取百度贴吧图片
通过python 来实现这样一个简单的爬虫功能,把我们想要的图片爬取到本地.(Python版本为3.6.0) 一.获取整个页面数据 def getHtml(url): page=urllib.requ ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- python爬虫-爬取百度图片
python爬虫-爬取百度图片(转) #!/usr/bin/python# coding=utf-8# 作者 :Y0010026# 创建时间 :2018/12/16 16:16# 文件 :spider ...
- 写一个python 爬虫爬取百度电影并存入mysql中
目标是利用python爬取百度搜索的电影 在类型 地区 年代各个标签下 电影的名字 评分 和图片连接 以及 电影连接 首先我们先在mysql中建表 create table liubo4( id in ...
- python爬虫—爬取百度百科数据
爬虫框架:开发平台 centos6.7 根据慕课网爬虫教程编写代码 片区百度百科url,标题,内容 分为4个模块:html_downloader.py 下载器 html_outputer.py 爬取数 ...
- Python爬虫爬取百度贴吧的帖子
同样是参考网上教程,编写爬取贴吧帖子的内容,同时把爬取的帖子保存到本地文档: #!/usr/bin/python#_*_coding:utf-8_*_import urllibimport urlli ...
- python简单爬虫爬取百度百科python词条网页
目标分析:目标:百度百科python词条相关词条网页 - 标题和简介 入口页:https://baike.baidu.com/item/Python/407313 URL格式: - 词条页面URL:/ ...
- Python爬虫爬取百度贴吧的图片
根据输入的贴吧地址,爬取想要该贴吧的图片,保存到本地文件夹,仅供参考: #!/usr/bin/python#_*_coding:utf-8_*_import urllibimport urllib2i ...
- Python编写网页爬虫爬取oj上的代码信息
OJ升级,代码可能会丢失. 所以要事先备份. 一開始傻傻的复制粘贴, 后来实在不能忍, 得益于大潇的启示和聪神的原始代码, 网页爬虫走起! 已经有段时间没看Python, 这次网页爬虫的原始代码是 p ...
随机推荐
- 分享Centos6.5升级glibc过程
默认的Centos6.5 glibc版本最高为2.12, 而在进行Nodejs开发时项目所依赖的包往往需要更高版本的glibc库支持, 因此在不升级系统的前提下, 需要主动更新系统glibc库. 一般 ...
- sigmoid function和softmax function
sigmoid函数(也叫逻辑斯谛函数): 引用wiki百科的定义: A logistic function or logistic curve is a common “S” shape (sigm ...
- 20145209刘一阳《网络对抗》实验五:MSF基础应用
20145209刘一阳<网络对抗>实验五:MSF基础应用 主动攻击 首先,我们需要弄一个xp sp3 English系统的虚拟机,然后本次主动攻击就在我们kali和xp之间来完成. 然后我 ...
- 北京Uber优步司机奖励政策(3月9日)
滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:http://www.cnblogs.com/mfry ...
- 3551: [ONTAK2010]Peaks加强版
3551: [ONTAK2010]Peaks加强版 https://www.lydsy.com/JudgeOnline/problem.php?id=3551 分析: kruskal重构树 + 倍增 ...
- HTML5 离线应用程序
离线Web应用:当客户端本地与Web应用程序的服务器没有建立连接时,也能正常在客户端本地使用该Web应用. Web应用程序的本地缓存与浏览器的网页缓存的区别 1. 本地缓存为整个Web应用程序服务,网 ...
- DSP5509之采样定理
1. 在实际种信号是模拟连续的,但是AD采样确实离散的数字的,根据采样定理,采样频率要是模拟信号的频率2倍以上采样到的值才没问题. 2. 打开工程 unsigned ]; main() { int i ...
- MySQL - 问题集 - Access denied; you need the SUPER privilege for
当执行存储过程相关操作时,如果出现该错误,则往下看. 打开存储过程,会发现“CREATE ALGORITHM=UNDEFINED DEFINER=`root`@`localhost`”. 由于DEFI ...
- 使用materialization
explain select `countries`.`id` AS `id`,`countries`.`sortname` AS `sortname`,`countries`.`name` AS ` ...
- C#新特性记录
C#6.0新特性笔记 Getter专属赋值 可以在构造函数中,给只有get的属性赋初始值. class Point { public int x { get; } public Point() { x ...