爬虫实战【9】Selenium解析淘宝宝贝-获取宝贝信息并保存
通过昨天的分析,我们已经能到依次打开多个页面了,接下来就是获取每个页面上宝贝的信息了。
分析页面宝贝信息
【插入图片,宝贝信息各项内容】
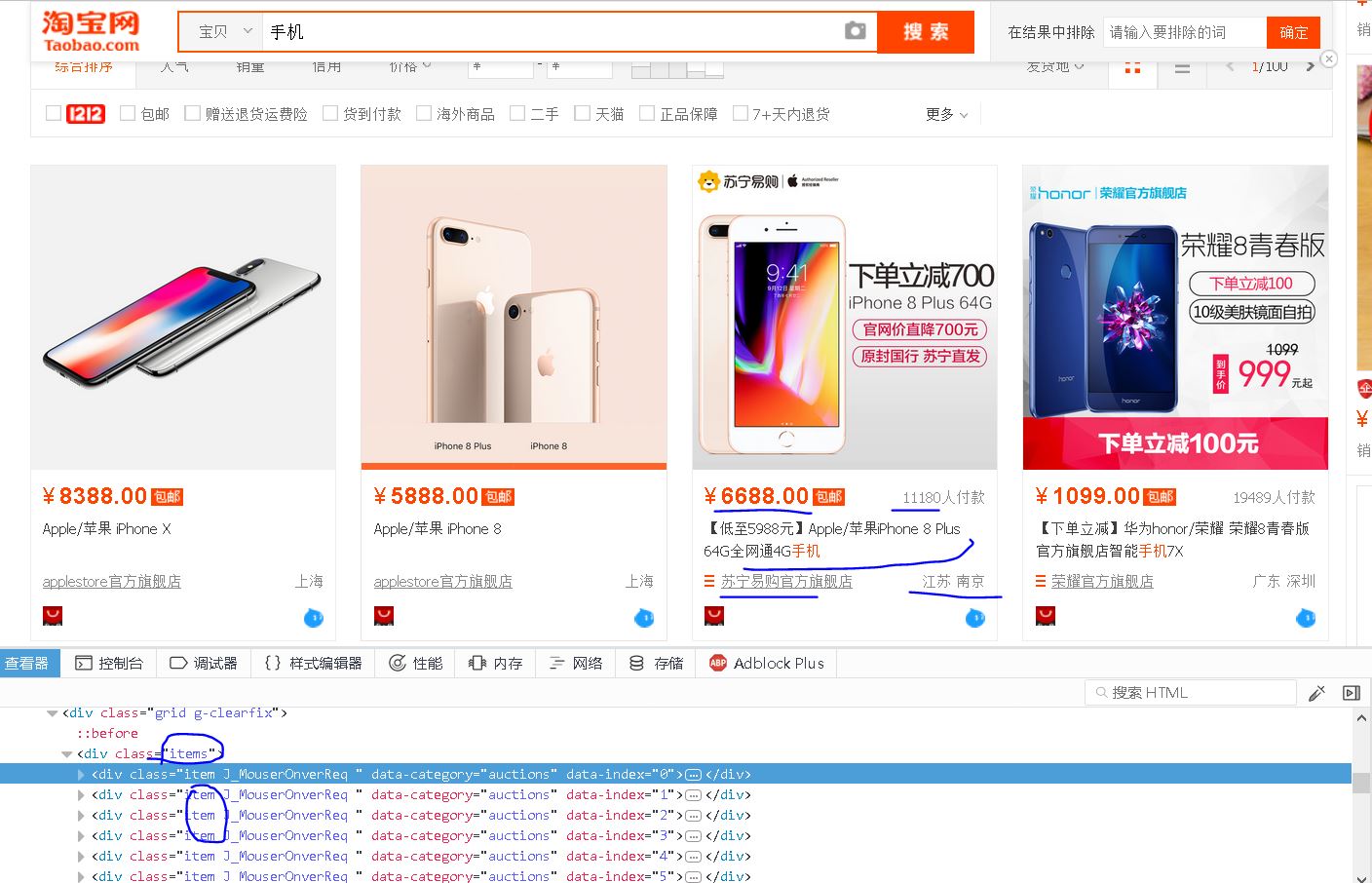
从图片上看,每个宝贝有如下信息;price,title,url,deal amount,shop,location等6个信息,其中url表示宝贝的地址。
我们通过查看器分析,每个宝贝都在一个div里面,这个div的class属性包含item。
而所有的item都在一个div内,这个总的div具有class属性为items,也就是单个页面上包含所有宝贝的一个框架。
因而,只有当这个div已经加载了,才能够断定页面的宝贝信息是可以提取的,所以再提取信息之前,我们要判断这个div的存在。
对于网页源码的解析,这次我们使用Pyquery,轮换着用一下嘛,感觉还是PyQuery比较好用,尤其是pyquery搜索到的对象还能在此进行搜索,很方便。
Pyquery的使用方法请查看我之前的文章,或者看一下API。
下面我们依次来分析一下每项信息应该如何提取。
1、Price
【插入图片,price】
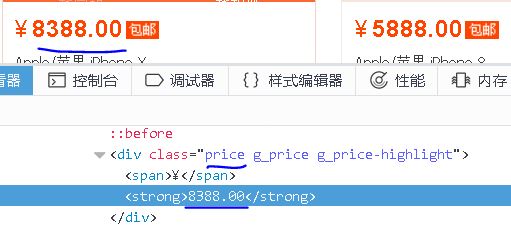
可以看出,price的信息在一个div里面,具有clas属性price,我们如果通过text来获取的话,还会将前面的人民币符号得到,回头切片切掉就好了。
2、Deal Amount
【插入图片,amount】
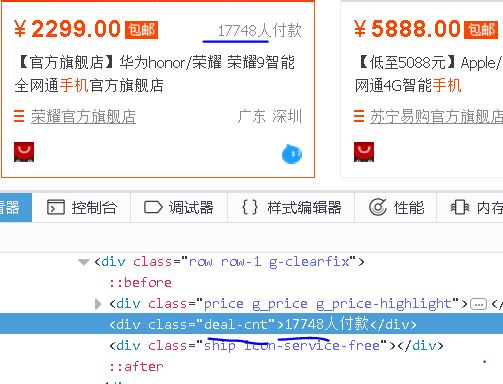
成交量信息再一个class属性为deal-cnt的div标签里面,仍然需要将最后三个字符切掉。
3、Title
【插入图片,title】
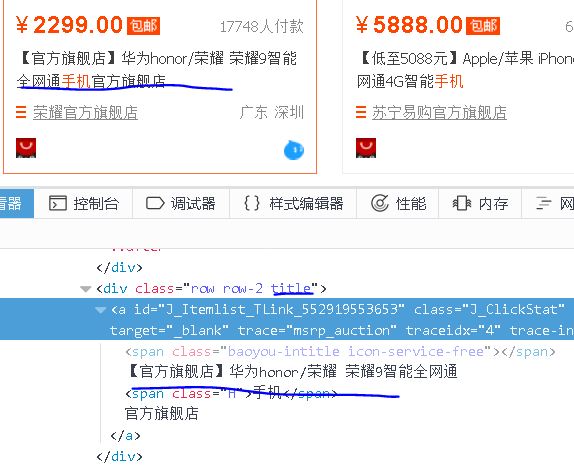
宝贝的标题在一个class属性为title的div标签里面,通过text可以获取。
4、Shop
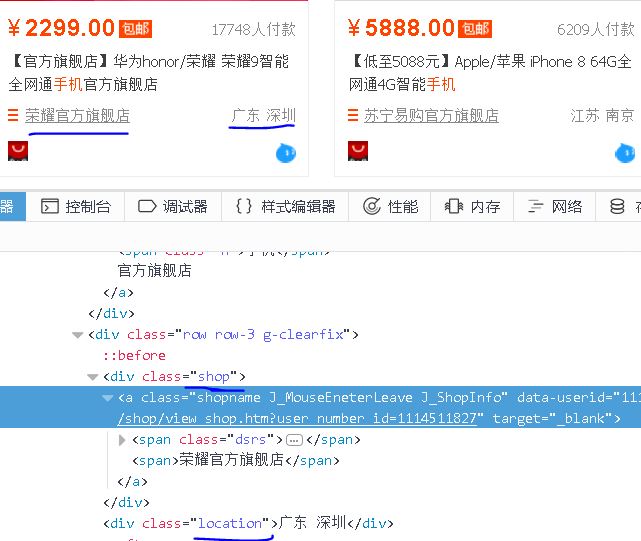
【插入图片,shop和location】
店铺名在一个class属性为shop的div标签呢。
5、Location
同上图,class属性为location。
6、URL
【插入图片,宝贝的地址】

url地址在一个a标签,class属性为pic-link,这个a标签的href属性就是url地址。
from pyquery import PyQuery as pq
def get_products():
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'.grid > div:nth-child(1)')))
html=browser.page_source
doc=pq(html)
items=doc('div.item').items()#讲解一下
for item in items:
product={
'url':item('a.pic-link').attr('href'),
'price':item.find('.price').text()[1:],
'amount':item.find('.deal-cnt').text()[:-3],
'title':item.find('.title').text(),
'shop':item.find('.shop').text(),
'location':item.find('.location').text()
}
print(product)
#save_to_mongo(product)
save_to_csv(product)
这里我们在讲一下items的内容,看一下源码中的范例:
> d = PyQuery('<div><span>foo</span><span>bar</span></div>')
> [i.text() for i in d.items('span')]
['foo', 'bar']
>[i.text() for i in d('span').items()]
['foo', 'bar']
>list(d.items('a')) == list(d('a').items())
True
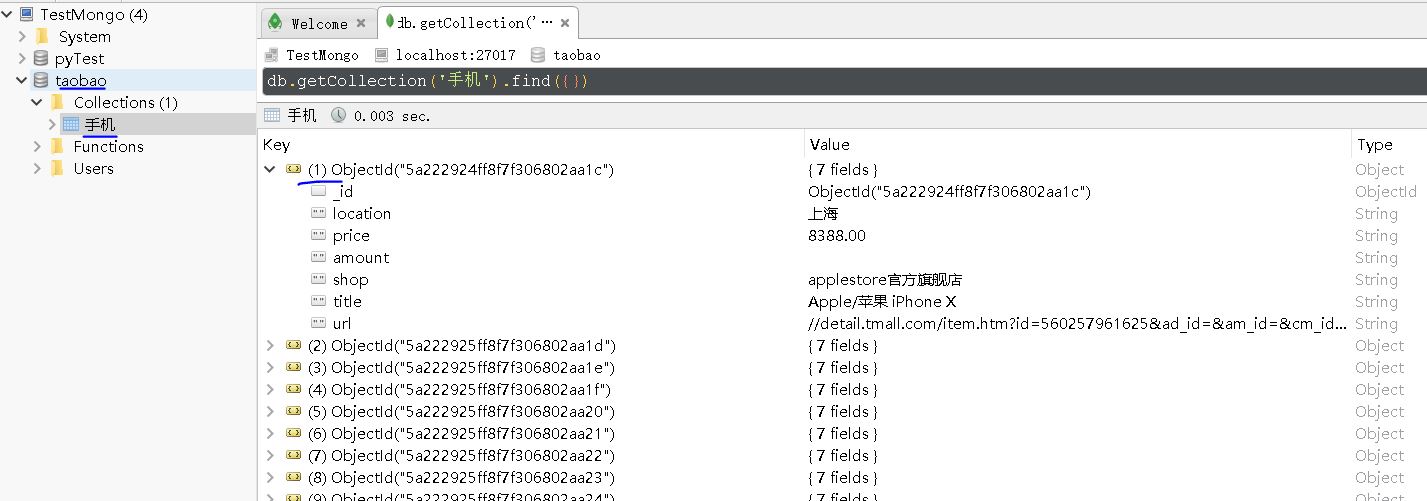
保存数据到MongoDb
如果我们获取到product,想保存到MongoDb数据库中,其实是很简单的,设置好数据库的url、数据库名、表名,通过pymongo链接到对应的数据库。
即使我们数据库还未建立,没关系的,会动态创建表格和数据。
import pymongo
'''MONGO设置'''
MONGO_URL='localhost'
MONGO_DB='taobao'
MONGO_Table=KEYWORD
client=pymongo.MongoClient(MONGO_URL)
db=client[MONGO_DB]
def save_to_mongo(product):
try:
if db[MONGO_Table].insert(product):
print('保存成功',product)
except Exception:
print('保存出错',product)
pass
【插入图片,MongoDB数据】
保存数据到CSV文件
其实也就是文本文件,只不过可以通过excel打开,方便我们做一些分析。
这里就不展开讲了,请看代码。
def save_to_csv(product):
with open(FileName,'a') as f:
s=product['title']+','+product['price']+','+product['amount']+','+product['location']+','+product['shop']+','+product['url']+'\n'
try:
f.write(s)
print('保存到csv成功!',product)
except:
pass
全部代码
只要改变KEYWORD关键字的内容,就能搜索到不同的宝贝信息,并保存下来,我们默认保存到csv文件中,数据毕竟只有几千条,还是Excel方便。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
from pyquery import PyQuery as pq
import re
import pymongo
from multiprocessing import Pool
'''要搜索的关键字'''
KEYWORD='Iphone8'
'''MONGO设置'''
MONGO_URL='localhost'
MONGO_DB='taobao'
MONGO_Table=KEYWORD
'''要保存的csv文件'''
FileName=KEYWORD+'.csv'
'''PhantomJS参数'''
SERVICE_ARGS=['--load-images=false']#不加载图片,节省时间
client=pymongo.MongoClient(MONGO_URL)
db=client[MONGO_DB]
#browser=webdriver.Firefox()
browser=webdriver.PhantomJS(service_args=SERVICE_ARGS)
browser.set_window_size(1400,900)
index_url='https://www.taobao.com/'
wait=WebDriverWait(browser, 10)
def search(keyword):
try:
browser.get(index_url)
#user_search_input=browser.find_element_by_css_selector('#q')
#user_search_button=browser.find_element_by_css_selector('.btn-search')
user_search_input = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, "#q")))
user_search_button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, ".btn-search")))
user_search_input.send_keys(keyword)
user_search_button.click()
total=wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'div.total')))
total_page=re.compile(r'(\d+)').search(total.text).group(1)
print(total_page)
get_products()
return int(total_page)
except TimeoutException:
search(keyword)
def get_next_page(pageNum):
try:
user_page_input = wait.until(EC.presence_of_element_located((By.XPATH, "/html/body/div[1]/div[2]/div[3]/div[1]/div[26]/div/div/div/div[2]/input")))
user_page_button = wait.until(EC.element_to_be_clickable((By.XPATH, "/html/body/div[1]/div[2]/div[3]/div[1]/div[26]/div/div/div/div[2]/span[3]")))
user_page_input.clear()
user_page_input.send_keys(pageNum)
user_page_button.click()
wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR,'li.active > span:nth-child(1)'),str(pageNum)))
get_products()
except TimeoutException:
get_next_page(pageNum)
def get_products():
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'.grid > div:nth-child(1)')))
html=browser.page_source
doc=pq(html)
items=doc('div.item').items()
for item in items:
product={
'url':item('a.pic-link').attr('href'),
'price':item.find('.price').text()[1:],
'amount':item.find('.deal-cnt').text()[:-3],
'title':item.find('.title').text(),
'shop':item.find('.shop').text(),
'location':item.find('.location').text()
}
print(product)
#save_to_mongo(product)
save_to_csv(product)
def save_to_csv(product):
with open(FileName,'a') as f:
s=product['title']+','+product['price']+','+product['amount']+','+product['location']+','+product['shop']+','+product['url']+'\n'
try:
f.write(s)
print('保存到csv成功!',product)
except:
pass
def save_to_mongo(product):
try:
if db[MONGO_Table].insert(product):
print('保存成功',product)
except Exception:
print('保存出错',product)
pass
def main():
total=search(KEYWORD)
# p=Pool()
# p.map(get_next_page,[i for i in range(2,total+1)])
for i in range(2,total+1):
get_next_page(i)
browser.close()
if __name__=='__main__':
main()
简单分析一下结果
【插入图片,结果分析示例】
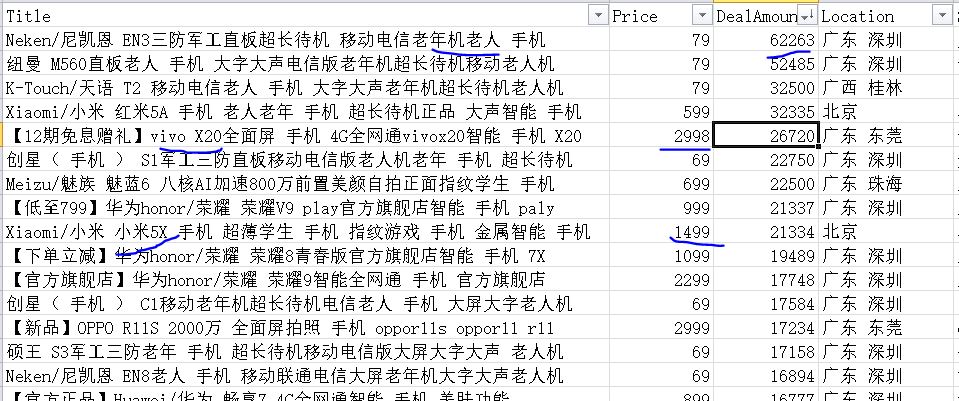
月成交量最好的是一款老人机,只有79元。。。。
智能手机里面,vivo X20是卖的最好的,2999元价位。
1500价位,小米5x出现了。。。
这种类似的分析都是建立在数据挖掘的基础上的,希望你能从本篇内容中学到一些知识。

爬虫实战【9】Selenium解析淘宝宝贝-获取宝贝信息并保存的更多相关文章
- Python 爬虫实战5 模拟登录淘宝并获取所有订单
经过多次尝试,模拟登录淘宝终于成功了,实在是不容易,淘宝的登录加密和验证太复杂了,煞费苦心,在此写出来和大家一起分享,希望大家支持. 本篇内容 python模拟登录淘宝网页 获取登录用户的所有订单详情 ...
- 爬虫实战【8】Selenium解析淘宝宝贝-获取多个页面
作为全民购物网站的淘宝是在学习爬虫过程中不可避免要打交道的一个网站,而是淘宝上的数据真的很多,只要我们指定关键字,将会出现成千上万条数据. 今天我们来讲一下如何从淘宝上获取某一类宝贝的信息,比如今天我 ...
- 芝麻HTTP:Python爬虫实战之抓取淘宝MM照片
本篇目标 1.抓取淘宝MM的姓名,头像,年龄 2.抓取每一个MM的资料简介以及写真图片 3.把每一个MM的写真图片按照文件夹保存到本地 4.熟悉文件保存的过程 1.URL的格式 在这里我们用到的URL ...
- python 爬虫实战4 爬取淘宝MM照片
本篇目标 抓取淘宝MM的姓名,头像,年龄 抓取每一个MM的资料简介以及写真图片 把每一个MM的写真图片按照文件夹保存到本地 熟悉文件保存的过程 1.URL的格式 在这里我们用到的URL是 http:/ ...
- Python爬虫之一 PySpider 抓取淘宝MM的个人信息和图片
ySpider 是一个非常方便并且功能强大的爬虫框架,支持多线程爬取.JS动态解析,提供了可操作界面.出错重试.定时爬取等等的功能,使用非常人性化. 本篇通过做一个PySpider 项目,来理解 Py ...
- 简单的抓取淘宝关键字信息、图片的Python爬虫|Python3中级玩家:淘宝天猫商品搜索爬虫自动化工具(第一篇)
Python3中级玩家:淘宝天猫商品搜索爬虫自动化工具(第一篇) 淘宝改字段,Bugfix,查看https://github.com/hunterhug/taobaoscrapy.git 由于Gith ...
- Python爬虫实战五之模拟登录淘宝并获取所有订单
经过多次尝试,模拟登录淘宝终于成功了,实在是不容易,淘宝的登录加密和验证太复杂了,煞费苦心,在此写出来和大家一起分享,希望大家支持. 温馨提示 更新时间,2016-02-01,现在淘宝换成了滑块验证了 ...
- selenium实现淘宝的商品爬取
一.问题 本次利用selenium自动化测试,完成对淘宝的爬取,这样可以避免一些反爬的措施,也是一种爬虫常用的手段.本次实战的难点: 1.如何利用selenium绕过淘宝的登录界面 2.获取淘宝的页面 ...
- webMagic解析淘宝cookie 提示Invalid cookie header
webMagic解析淘宝cookie 提示Invalid cookie header 在使用webMagic框架做爬虫爬取淘宝极又家页面时候一直提醒cookie设置不可用如下图 淘宝的验证特别严重,c ...
随机推荐
- weblogic stuck实验2014-11-14
以往对weblogic stuck认识是: 1.会造成系统总体慢. 2.在weblogic console中线程监控中会有显示. 3.weblogic使用队列处理线程.隔一段时间会扫描线程队 ...
- 对于yum中没有的源的解决办法-EPEL
转载自:http://6260022.blog.51cto.com/6250022/1698352 EPEL 是什么? EPEL (Extra Packages for Enterprise Linu ...
- jQuery remove 内存 释放
解决方案(伪代码):(http://www.cnblogs.com/see7di/archive/2011/09/08/2239653.html)jQuery( “*”, obj).add([obj] ...
- Eclipse中屏蔽日志
如何在Eclipse中屏蔽日志 //屏蔽日志 Eclipse Java import org.apache.log4j.Level; import org.apache.log4j.Logger; L ...
- [k8s]组件日志级别说明
kubectl 执行命令时候 --v 调试, 也可以用作其他组件的 --v配置 参考: https://kubernetes.io/docs/user-guide/kubectl-cheatsheet ...
- Spring Aop基础总结
什么是AOP: Aop技术是Spring核心特性之中的一个,定义一个切面.切面上包括一些附加的业务逻辑代码.在程序运行的过程中找到一个切点,把切面放置在此处,程序运行到此处时候会运行切面上的代码.这就 ...
- 从A页面带参数跳转到B页面;进行解析,并显示数据,进行编辑
A页面跳转时候的地址: parent.layer.open({ type: 2, title:'新建草稿', shadeClose: true, shade: 0.8, scrollbar: fals ...
- superobject 序列数据集
unit uDBJson; interface {$HINTS OFF} uses SysUtils, Classes, Variants, DB, DBClient, SuperObject; ty ...
- java创建web服务
java开发web服务的方法有很多,但是常用的就两种一种是开发时用,一种发布时用.开发时使用jax-ws注解的方式开发调试,发布时使用tomcat. 注解方式: http://www.cnblogs. ...
- oracle instant client,tnsping,tnsnames.ora和ORACLE_HOME
前段时间要远程连接oracle数据库,可是又不想在自己电脑上完整安装oracleclient,于是到oracle官网下载了轻量级clientinstant client. 这玩意没有图形界面,全靠sq ...