python操作RabbitMQ(不错)
一、rabbitmq
RabbitMQ是一个在AMQP基础上完整的,可复用的企业消息系统。他遵循Mozilla Public License开源协议。
MQ全称为Message Queue, 消息队列(MQ)是一种应用程序对应用程序的通信方法。应用程序通过读写出入队列的消息(针对应用程序的数据)来通信,而无需专用连接来链接它们。消 息传递指的是程序之间通过在消息中发送数据进行通信,而不是通过直接调用彼此来通信,直接调用通常是用于诸如远程过程调用的技术。排队指的是应用程序通过 队列来通信。队列的使用除去了接收和发送应用程序同时执行的要求。
1.1 安装rabbitmq
RabbitMQ安装
|
1
2
3
4
5
6
7
8
|
安装配置epel源 $ rpm -ivh http://dl.fedoraproject.org/pub/epel/6/i386/epel-release-6-8.noarch.rpm 安装erlang $ yum -y install erlang 安装RabbitMQ $ yum -y install rabbitmq-server |
注意:service rabbitmq-server start/stop
安装API:
|
1
2
3
4
5
6
7
8
9
|
pip install pikaoreasy_install pikaor源码orpycharmhttps://pypi.python.org/pypi/pika |
1.3 用python操作rabbitmq
1.3.1 基于Queue实现生产者消费者模型

#!/usr/bin/env python
# -*- coding:utf-8 -*-
import Queue
import threading message = Queue.Queue(10) def producer(i):
while True:
message.put(i) def consumer(i):
while True:
msg = message.get() for i in range(12):
t = threading.Thread(target=producer, args=(i,))
t.start() for i in range(10):
t = threading.Thread(target=consumer, args=(i,))
t.start()
1.3.2 rabbitmq实现消息队列
对于RabbitMQ来说,生产和消费不再针对内存里的一个Queue对象,而是某台服务器上的RabbitMQ Server实现的消息队列。
先运行消费者脚本,让它监听队列消息,然后运行生产者脚本,生产者往队列里发消息。然后消费者往队列里取消息。
import pika # ########################### 消费者 ########################### connection = pika.BlockingConnection(pika.ConnectionParameters(
host='192.168.137.208'))
channel = connection.channel() channel.queue_declare(queue='abc') # 如果队列没有创建,就创建这个队列 def callback(ch, method, propertities,body):
print(" [x] Received %r" % body) channel.basic_consume(callback,
queue='abc', # 队列名
no_ack=True) # 不通知已经收到,如果连接中断可能消息丢失 print(' [*] Waiting for message. To exit press CTRL+C')
channel.start_consuming()
import pika
# ############################## 生产者 ##############################
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='192.168.137.208'
))
channel = connection.channel()
channel.queue_declare(queue='abc') # 如果队列没有创建,就创建这个队列
channel.basic_publish(exchange='',
routing_key='abc', # 指定队列的关键字为,这里是队列的名字
body='Hello World!') # 往队列里发的消息内容
print(" [x] Sent 'Hello World!'")
connection.close()
先运行消费者,然后再运行生产者:
'''
打印:
生产者:
[x] Sent 'Hello World!'
消费者:
[*] Waiting for message. To exit press CTRL+C
[x] Received b'Hello World!'
'''
1.4 no-ack=False:rabbitmq消费者连接断了 消息不丢失
rabbitmq支持一种方式:应答。比如我从消息里拿一条消息,如果全处理完,你就不要帮我记着了。如果没处理完,突然断开了,再连接上的时候,消息队列就会重新发消息。
总结:
- Basic.Ack 发回给 RabbitMQ 以告知,可以将相应 message 从 RabbitMQ 的消息缓存中移除。
- Basic.Ack 未被 consumer 发回给 RabbitMQ 前出现了异常,RabbitMQ 发现与该 consumer 对应的连接被断开,之后将该 message 以轮询方式发送给其他 consumer (假设存在多个 consumer 订阅同一个 queue)。
- 在 no_ack=true 的情况下,RabbitMQ 认为 message 一旦被 deliver 出去了,就已被确认了,所以会立即将缓存中的 message 删除。所以在 consumer 异常时会导致消息丢失。
- 来自 consumer 侧的 Basic.Ack 与 发送给 Producer 侧的 Basic.Ack 没有直接关系
注意:
1)只有在Consumer(消费者)断开连接时,RabbitMQ才会重新发送未经确认的消息。
2)超时的情况并未考虑:无论Consumer需要处理多长时间,RabbitMQ都不会重发消息。
消息不丢失的关键代码:
1)在接收端的callback最后:
channel.basic_ack(delivery_tag=method.delivery_tag)
|
1
2
3
|
ack即acknowledge(承认,告知已收到)也就是消费者每次收到消息,要通知一声:已经收到,如果消费者连接断了,rabbitmq会重新把消息放到队列里,下次消费者可以连接的时候,就能重新收到丢失消息。A message MUST not be acknowledged morethan once. The receiving peer MUST validate that a non-zero delivery-tag refersto a delivered message, <br>and raise a channel exception if this is not the case. |
2)除了callback函数,还要在之前设置接收消息时指定no_ack(默认False):
channel.basic_consume(callback, queue='hello', no_ack=False)
消费者:
import pika
# ########################### 消费者 ##########################
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='10.211.55.4'))
channel = connection.channel() channel.queue_declare(queue='hello') def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
import time
time.sleep(10)
print('ok')
ch.basic_ack(delivery_tag = method.delivery_tag) channel.basic_consume(callback,
queue='hello',
no_ack=False) print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
消费者断掉连接,再次连接,消息还会收到。
1.5 durable:rabbitmq服务端宕机 消息不丢失
发数据的时候,就说了:我这条数据要持久化保存。
如果rabbitmq服务端机器如果挂掉了,会给这台机器做持久化。如果启动机器后,消息队列还在。
生产者.py:
import pika
# ############################## 生产者 ##############################
connection = pika.BlockingConnection(pika.ConnectionParameters(host='10.211.55.4'))
channel = connection.channel() # make message persistent
channel.queue_declare(queue='hello', durable=True) channel.basic_publish(exchange='',
routing_key='hello',
body='Hello World!',
properties=pika.BasicProperties(
delivery_mode=2, # make message persistent
))
print(" [x] Sent 'Hello World!'")
connection.close()
消费者.py:
import pika
# ########################### 消费者 ###########################
connection = pika.BlockingConnection(pika.ConnectionParameters(host='10.211.55.4'))
channel = connection.channel() # make message persistent
channel.queue_declare(queue='hello', durable=True) def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
import time
time.sleep(10)
print('ok')
ch.basic_ack(delivery_tag = method.delivery_tag) channel.basic_consume(callback,
queue='hello',
no_ack=False) print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
测试:
1)把生产者.py执行三次。
2)然后在linux上停掉rabbitmq服务,然后再开启rabbitmq服务
|
1
2
3
4
5
6
|
[root@localhost ~]# /etc/init.d/rabbitmq-server stopStopping rabbitmq-server: rabbitmq-server.[root@localhost ~]# /etc/init.d/rabbitmq-server startStarting rabbitmq-server: SUCCESSrabbitmq-server. |
3)运行:消费者.py:三条消息都打印了:
|
1
2
3
4
5
6
7
|
[*] Waiting for messages. To exit press CTRL+C [x] Received b'Hello World!'ok [x] Received b'Hello World!'ok [x] Received b'Hello World!'ok |
1.6 消息获取顺序
默认消息队列里的数据是按照顺序被消费者拿走,例如:消费者1 去队列中获取 奇数 序列的任务,消费者1去队列中获取 偶数 序列的任务。
因为默认是跳着取得。第一个消费者取得很快,已经执行到20了,但是第二个消费者只取到13,可能消息执行的顺序就有问题了。
如果多个消费者,如果不想跳着取,就按消息的顺序取,而不是按着自己的间隔了。
channel.basic_qos(prefetch_count=1) 表示谁来谁取,不再按照奇偶数排列
#!/usr/bin/env python
# -*- coding:utf-8 -*-
__author__ = 'WangQiaomei'
import pika # ########################### 消费者 ###########################
connection = pika.BlockingConnection(pika.ConnectionParameters(host='192.168.137.208'))
channel = connection.channel() # make message persistent
channel.queue_declare(queue='hello1') def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
import time
time.sleep(10)
print('ok')
ch.basic_ack(delivery_tag = method.delivery_tag) channel.basic_qos(prefetch_count=1) channel.basic_consume(callback,
queue='hello1',
no_ack=False) print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
1.7发布订阅
发布订阅原理:
1)发布订阅和简单的消息队列区别在于,发布订阅会将消息发送给所有的订阅者,而消息队列中的数据被消费一次便消失。
2)所以,RabbitMQ实现发布和订阅时,会为每一个订阅者创建一个队列,而发布者发布消息时,会将消息放置在所有相关队列中。
3)exchange 可以帮你发消息到多个队列!type设为什么值,就把消息发给哪些队列。
发布订阅应用到监控上:
模板就是写上一段脚本,放在服务器上,
客户端每5分钟,从服务端拿到监控模板,根据模板来取数据,
然后把数据结果发步到服务端的redis频道里。
服务端收到数据,1)处理历史记录 2)报警 3)dashboard显示监控信息
服务端有三处一直来订阅服务端频道(一直来收取客户端监控数据)
1.7.1 发布给所有绑定队列
exchange type = fanout
exchange 可以帮你发消息到多个队列,type = fanout表示:跟exchange绑定的所有队列,都会收到消息。

发布者:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
__author__ = 'WangQiaomei
import pika
import sys
# ########################### 发布者 ########################### connection = pika.BlockingConnection(pika.ConnectionParameters(
host='192.168.137.208'))
channel = connection.channel() channel.exchange_declare(exchange='logs',
type='fanout') message = ' '.join(sys.argv[1:]) or "info: Hello World!"
channel.basic_publish(exchange='logs',
routing_key='',
body=message)
print(" [x] Sent %r" % message)
connection.close()
订阅者:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
__author__ = 'WangQiaomei' import pika
# ########################### 订阅者 ########################### connection = pika.BlockingConnection(pika.ConnectionParameters(
host='192.168.137.208'))
channel = connection.channel() channel.exchange_declare(exchange='logs',
type='fanout')
# 随机创建队列
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
# 绑定
channel.queue_bind(exchange='logs',
queue=queue_name) print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body):
print(" [x] %r" % body) channel.basic_consume(callback,
queue=queue_name,
no_ack=True) channel.start_consuming() '''
多次执行这个文件,就会随机生成多个队列。并且exchange都绑定这些队列。
然后发布者只需要给exchange发送消息,然后exchange绑定的多个队列都有这个消息了。订阅者就收到这个消息了。
'''
1.7.2关键字发送
一个队列还可以绑定多个关键字
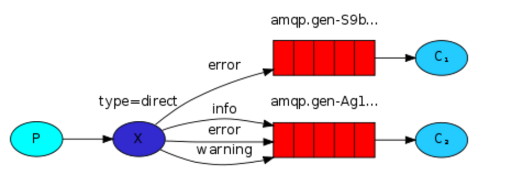
对一个随机队列,绑定三个关键字
再次执行,对另一个随机队列,只绑定一个关键字。
消费者:每执行一次可以生成一个队列。通过使用命令行传参的方式,来传入队列的关键字。
#!/usr/bin/env python
import pika
import sys connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel() channel.exchange_declare(exchange='direct_logs',
type='direct') result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue severities :]
if not severities:
sys.stderr.write("Usage: %s [info] [warning] [error]\n" % sys.argv[0])
sys.exit(1) for severity in severities:
channel.queue_bind(exchange='direct_logs',
queue=queue_name,
routing_key=severity) print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body)) channel.basic_consume(callback,
queue=queue_name,
no_ack=True) channel.start_consuming()
容易测试的版本:
消费者1:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
__author__ = 'WangQiaomei' import pika
import sys # ########################### 消费者1 ########################### connection = pika.BlockingConnection(pika.ConnectionParameters(
host='192.168.137.208'))
channel = connection.channel() channel.exchange_declare(exchange='direct_logs',
type='direct') result = channel.queue_declare(exclusive=True) # 随机生成队列
queue_name = result.method.queue severities ]
if not severities:
sys.stderr.write("Usage: %s [info] [warning] [error]\n" % sys.argv[0])
sys.exit(1) for severity in severities:
channel.queue_bind(exchange='direct_logs',
queue=queue_name,
routing_key=severity) print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body)) channel.basic_consume(callback,
queue=queue_name,
no_ack=True) channel.start_consuming()
消费者2:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
__author__ = 'WangQiaomei' import pika
import sys # ########################### 消费者2 ########################### connection = pika.BlockingConnection(pika.ConnectionParameters(
host='192.168.137.208'))
channel = connection.channel() channel.exchange_declare(exchange='direct_logs',
type='direct') result = channel.queue_declare(exclusive=True) # 随机生成队列
queue_name = result.method.queue severities ] for severity in severities:
channel.queue_bind(exchange='direct_logs',
queue=queue_name,
routing_key=severity) print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body)) channel.basic_consume(callback,
queue=queue_name,
no_ack=True) channel.start_consuming()
生产者:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
__author__ = 'WangQiaomei' import pika
import sys # ############################## 生产者 ############################## connection = pika.BlockingConnection(pika.ConnectionParameters(
host='192.168.137.208'))
channel = connection.channel() channel.exchange_declare(exchange='direct_logs',
type='direct') severity = 'info'
message = 'Hello World!'
channel.basic_publish(exchange='direct_logs',
routing_key=severity,
body=message)
print(" [x] Sent %r:%r" % (severity, message))
connection.close() '''
同时运行消费者1,消费者2,然后修改生产者的关键字,运行生产者。
当生产者:severity = 'info',则消费者1收到消息,消费者2没收到消息
当生产者:severity = 'error',则消费者1、消费者2 都收到消息
'''
1.7.2 模糊匹配

exchange type = topic
在topic类型下,可以让队列绑定几个模糊的关键字,之后发送者将数据发送到exchange,exchange将传入”路由值“和 ”关键字“进行匹配,匹配成功,则将数据发送到指定队列。
- # 表示可以匹配 0 个 或 多个 字符
- * 表示只能匹配 一个 任意字符
|
1
2
3
|
发送者路由值 队列中old.boy.python old.* -- 不匹配old.boy.python old.# -- 匹配 |
消费者:
#!/usr/bin/env python
import pika
import sys
# ############################## 消费者 ##############################
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='192.168.137.208'))
channel = connection.channel() channel.exchange_declare(exchange='topic_logs',
type='topic') result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue binding_keys = "*.orange.*" for binding_key in binding_keys:
channel.queue_bind(exchange='topic_logs',
queue=queue_name,
routing_key=binding_key) print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body)) channel.basic_consume(callback,
queue=queue_name,
no_ack=True) channel.start_consuming()
生产者:
#!/usr/bin/env python
import pika
import sys
# ############################## 生产者 ##############################
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='192.168.137.208'))
channel = connection.channel() channel.exchange_declare(exchange='topic_logs',
type='topic') # routing_key = 'abc.new.qiaomei.old'
routing_key = 'neworangeold'
message = 'Hello World!'
channel.basic_publish(exchange='topic_logs',
routing_key=routing_key,
body=message)
print(" [x] Sent %r:%r" % (routing_key, message))
connection.close() '''
#.orange.# 匹配:new.orange.old neworangeold
*.orange.* 匹配:neworangeold,不匹配:new.orange.old
'''
1.8 saltstack原理实现
saltstack:zeromq:放到内存里的,会更快,会基于这个做rcp
openstack:大量使用:rabbitmq
saltstack上有master,有三个队列。,让三个客户端每个人取一个队列的任务
saltstack的原理:
1)发一条命令ifconfig,想让所有nginx主机组的机器,都执行。
2)在master我们可以发命令给exchange,nginx总共有10台服务器,创建10个带有nginx关键字的10个队列,
3)master随机生成队列,md5是一个队列的名字,exchange把命令和md5这个消息推送到nginx关键字的队列里。
4)nginx10台服务器从队列中取出消息,执行命令,并且把主机名和执行的结果返回给这个队列里。
5)master变为消费者,取出队列里的主机名和执行结果,并打印到终端上。
服务器1:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
__author__ = 'WangQiaomei' import pika
import sys # ########################### 消费者1 ########################### connection = pika.BlockingConnection(pika.ConnectionParameters(
host='192.168.137.208'))
channel = connection.channel() channel.exchange_declare(exchange='direct_logs',
type='direct') result = channel.queue_declare(exclusive=True) # 随机生成队列
queue_name = result.method.queue severities = ]
if not severities:
sys.stderr.write("Usage: %s [info] [warning] [error]\n" % sys.argv[0])
sys.exit(1) for severity in severities:
channel.queue_bind(exchange='direct_logs',
queue=queue_name,
routing_key=severity) print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body))
queue_md5=body.decode().split(",")[1]
hostname = 'nginx1'
channel.queue_declare(queue=queue_md5) # 如果队列没有创建,就创建这个队列
channel.basic_publish(exchange='',
routing_key=queue_md5, # 指定队列的关键字为,这里是队列的名字
body='%s|cmd_result1' %hostname) # 往队列里发的消息内容 channel.basic_consume(callback,
queue=queue_name,
no_ack=True) channel.start_consuming()
服务器2:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
__author__ = 'WangQiaomei' import pika
import sys # ########################### 消费者2 ########################### connection = pika.BlockingConnection(pika.ConnectionParameters(
host='192.168.137.208'))
channel = connection.channel() channel.exchange_declare(exchange='direct_logs',
type='direct') result = channel.queue_declare(exclusive=True) # 随机生成队列
queue_name = result.method.queue severities = ["nginx"] for severity in severities:
channel.queue_bind(exchange='direct_logs',
queue=queue_name,
routing_key=severity) print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body))
queue_md5=body.decode().split(",")[1]
hostname = 'nginx2'
channel.queue_declare(queue=queue_md5) # 如果队列没有创建,就创建这个队列
channel.basic_publish(exchange='',
routing_key=queue_md5, # 指定队列的关键字为,这里是队列的名字
body='%s|cmd_result2' %hostname) # 往队列里发的消息内容 channel.basic_consume(callback,
queue=queue_name,
no_ack=True) channel.start_consuming()
master:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
__author__ = 'WangQiaomei' import pika
import sys
import hashlib # ############################## 生产者 ############################## connection = pika.BlockingConnection(pika.ConnectionParameters(
host='192.168.137.208'))
channel = connection.channel() channel.exchange_declare(exchange='direct_logs',
type='direct') severity = 'nginx'
m2 = hashlib.md5()
m2.update(severity.encode('utf-8'))
md5_security=m2.hexdigest()
print('md5_security:',md5_security)
message = 'cmd,%s' % md5_security channel.basic_publish(exchange='direct_logs',
routing_key=severity,
body=message)
print(" [x] Sent %r:%r" % (severity, message))
connection.close() #################################3
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='192.168.137.208'))
channel = connection.channel() channel.queue_declare(queue=md5_security) # 如果队列没有创建,就创建这个队列 def callback(ch, method, propertities,body):
print(" [x] Received %r" % body) channel.basic_consume(callback,
queue=md5_security, # 队列名
no_ack=True) # 不通知已经收到,如果连接中断消息就丢失 print(' [*] Waiting for message. To exit press CTRL+C')
channel.start_consuming()
打印:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
'''服务器1,和服务器2都打印: [*] Waiting for logs. To exit press CTRL+C [x] 'nginx':b'cmd,ee434023cf89d7dfb21f63d64f0f9d74'master打印:md5_security: ee434023cf89d7dfb21f63d64f0f9d74 [x] Sent 'nginx':'cmd,ee434023cf89d7dfb21f63d64f0f9d74' [*] Waiting for message. To exit press CTRL+C [x] Received b'nginx2|cmd_result2' [x] Received b'nginx1|cmd_result1'''' |
python操作RabbitMQ(不错)的更多相关文章
- Python操作RabbitMQ
RabbitMQ介绍 RabbitMQ是一个由erlang开发的AMQP(Advanced Message Queue )的开源实现的产品,RabbitMQ是一个消息代理,从“生产者”接收消息并传递消 ...
- Python之路【第九篇】:Python操作 RabbitMQ、Redis、Memcache、SQLAlchemy
Python之路[第九篇]:Python操作 RabbitMQ.Redis.Memcache.SQLAlchemy Memcached Memcached 是一个高性能的分布式内存对象缓存系统,用 ...
- python - 操作RabbitMQ
python - 操作RabbitMQ 介绍 RabbitMQ是一个在AMQP基础上完整的,可复用的企业消息系统.他遵循Mozilla Public License开源协议.MQ全称为Mess ...
- 文成小盆友python-num12 Redis发布与订阅补充,python操作rabbitMQ
本篇主要内容: redis发布与订阅补充 python操作rabbitMQ 一,redis 发布与订阅补充 如下一个简单的监控模型,通过这个模式所有的收听者都能收听到一份数据. 用代码来实现一个red ...
- Python之路第十二天,高级(4)-Python操作rabbitMQ
rabbitMQ RabbitMQ是一个在AMQP基础上完整的,可复用的企业消息系统.他遵循Mozilla Public License开源协议. MQ全称为Message Queue, 消息队列(M ...
- Python菜鸟之路:Python基础-Python操作RabbitMQ
RabbitMQ简介 rabbitmq中文翻译的话,主要还是mq字母上:Message Queue,即消息队列的意思.rabbitmq服务类似于mysql.apache服务,只是提供的功能不一样.ra ...
- Python操作 RabbitMQ、Redis、Memcache
Python操作 RabbitMQ.Redis.Memcache Memcached Memcached 是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载.它通过在内存中缓存数 ...
- Python 【第六章】:Python操作 RabbitMQ、Redis、Memcache、SQLAlchemy
Memcached Memcached 是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载.它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态.数据库驱动网站的速度 ...
- Python操作 RabbitMQ、Redis、Memcache、SQLAlchemy
Memcached Memcached 是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载.它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态.数据库驱动网站的速度 ...
随机推荐
- Maven:如何在eclipse里新建一个Maven的java项目和web项目
如何在eclipse里新建一个Maven的java项目和web项目: 一:java项目 New-->Other-->Maven 右击项目-->properties,修改以下文件: ① ...
- 做Webservice时报错java.util.List是接口, 而 JAXB 无法处理接口。
Caused by: com.sun.xml.bind.v2.runtime.IllegalAnnotationsException: 1 counts of IllegalAnnotationExc ...
- [Android]android Service后台防杀
网上有很多办法,方法一:在JNI里面fork出子进程service在单独的进程中,在service中调用JNI的代码,然后fork出一个进程,然后让我们的service进程和fork出来的子进程一直运 ...
- centos 6的LAMP一键安装包(可选择/升级版本)
安装步骤 事前准备(安装 wget.screen.unzip,创建 screen 会话) yum -y install wget screen git git clone 并赋予脚本执行权限 git ...
- LeetCode——Insertion Sort List
LeetCode--Insertion Sort List Question Sort a linked list using insertion sort. Solution 我的解法,假设第一个节 ...
- css常用知识点——思维导图
如图 思维导图图片链接 http://www.edrawsoft.cn/viewer/public/s/21032425741486 有道云笔记图片链接 http://note.youdao.com/ ...
- NumPy来自现有数据的数组
NumPy - 来自现有数据的数组 这一章中,我们会讨论如何从现有数据创建数组. numpy.asarray 此函数类似于numpy.array,除了它有较少的参数. 这个例程对于将 Python 序 ...
- C++ 函数后面的const
一个函数 AcGePoint3dstartPoint() const; const放在后面跟前面有区别么 ==> 准确的说const是修饰this指向的对象的 譬如,我们定义了 classA{ ...
- RedHat设置Yum源
Linux:RedHat AS 6.2的版本 1.删除原有的yum: rpm -aq | grep yum | xargs rpm -e –nodeps 2.安装新的yum <1>rpm ...
- python之list,tuple,str,dic简单记录(二)
切片对象:例子:In [13]: l = [1,23,4,5,5,6,8]In [14]: l[::1]Out[14]: [1, 23, 4, 5, 5, 6, 8] In [15]: l[::2]O ...