Windows11安装Hadoop3.3.2
Windows11安装Hadoop3.3.2
JDK 安装
Hadoop的Java版本https://cwiki.apache.org/confluence/display/HADOOP/Hadoop+Java+Versions
>## Hadoop支持的 Java 版本
>
>- Apache Hadoop 3.3 及更高版本支持 Java 8 和 Java 11(仅限运行时)
> - 请使用 Java 8 编译 Hadoop。不支持使用 Java 11 编译 Hadoop: [HADOOP-16795](https://issues.apache.org/jira/browse/HADOOP-16795)-Java 11 编译支持**OPEN** [](https://issues.apache.org/jira/browse/HADOOP-16795)
>- 从 3.0.x 到 3.2.x 的 Apache Hadoop 现在仅支持 Java 8
>- 从 2.7.x 到 2.10.x 的 Apache Hadoop 支持 Java 7 和 8
所以安装jdk8来运行Hadoop
官网下载:https://www.oracle.com/java/technologies/downloads/#jre8-windows
选择Windows下的64位安装程序下载

运行安装程序即可,不需配置环境变量
Hadoop 安装
下载解压
阿里云开源镜像站下载:https://mirrors.aliyun.com/apache/hadoop/core/hadoop-3.3.2/
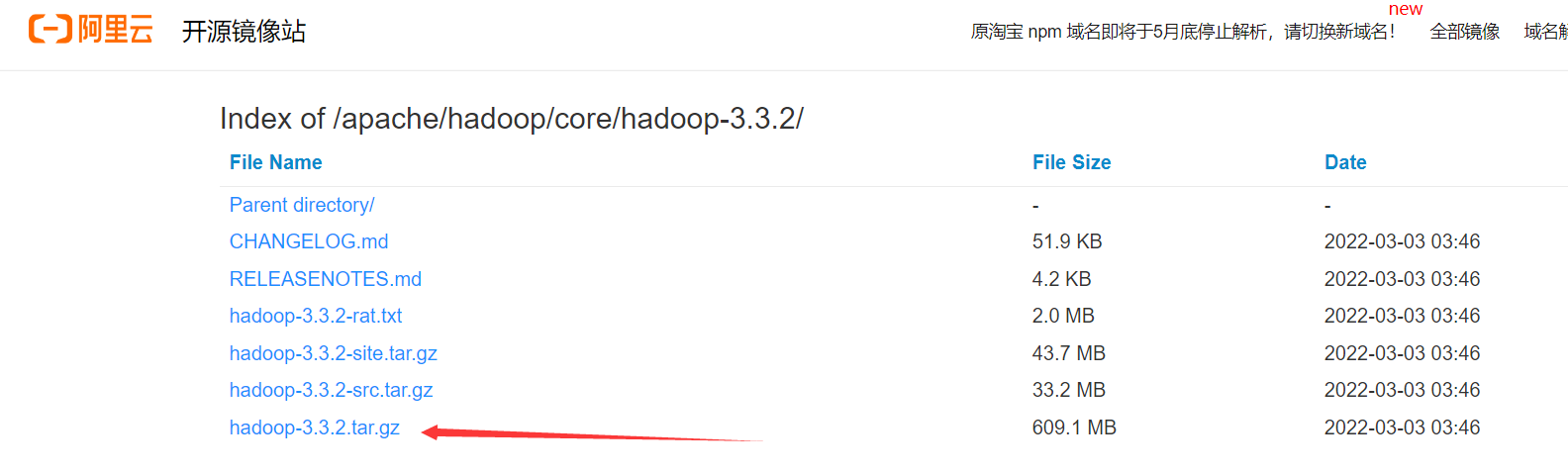
推荐使用下载Bandzip来解压
解压之后的目录
Windows环境变量配置
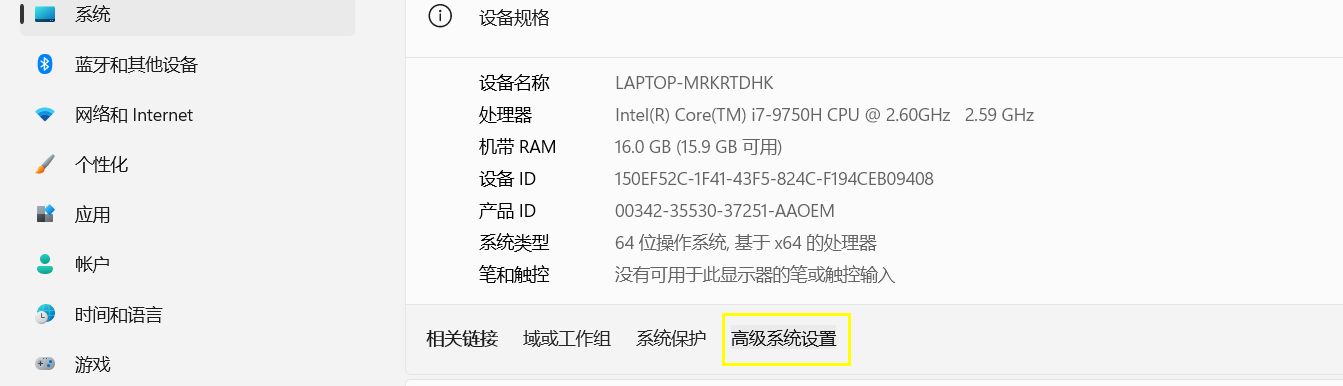
设置->系统->系统信息
点击高级系统设置,环境变量
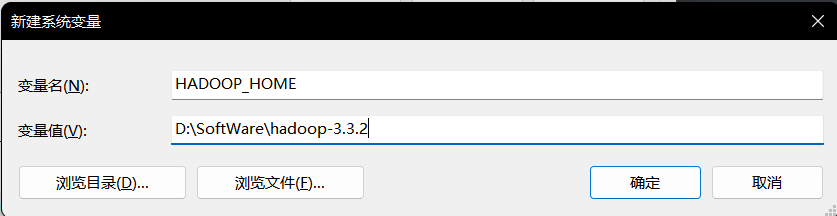
在系统变量处新建
HADOOP_HOME
变量值为hadoop的解压目录
D:\SoftWare\hadoop-3.3.2
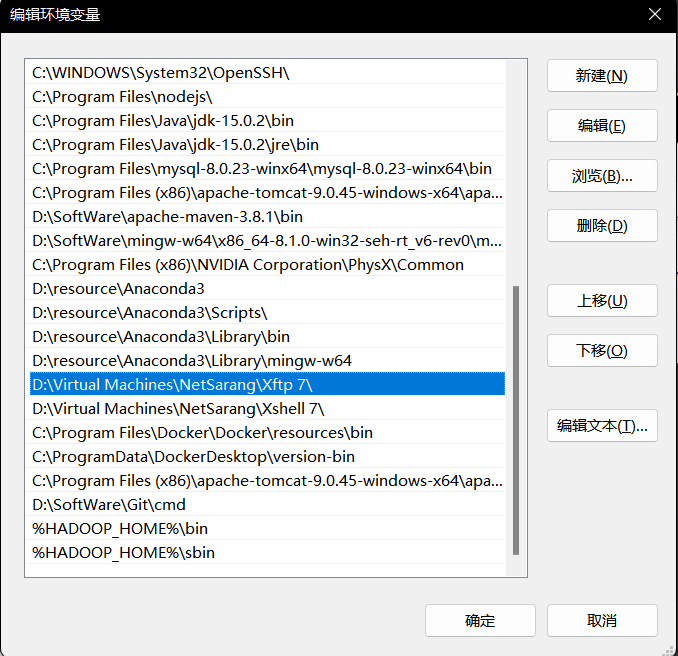
在系统变量的Path下新建两个变量
%HADOOP_HOME%\bin
%HADOOP_HOME%\sbin
hadoop文件配置
hadoop-env.cmd
在D:\SoftWare\hadoop-3.3.2\etc\hadoop目录下
右键编辑,Ctrl+F搜索JAVA_HOME找到set JAVA_HOME这一项,将其修改为jdk8的安装路径
set JAVA_HOME=C:\PROGRA~1\Java\jdk-8
使用PROGRA~1来代替Program Files,是其dos文件名模式下的缩写
直接使用Program Files会报错,里面包含一个空格
在命令行查看hadoop版本,没有报错说明配置成功
hadoop -version
输出信息:
PS C:\Users\Ran> hadoop -version Active code page: 65001 java version "1.8.0_333" Java(TM) SE Runtime Environment (build 1.8.0_333-b02) Java HotSpot(TM) 64-Bit Server VM (build 25.333-b02, mixed mode)
core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/D:/SoftWare/hadoop-3.3.2/data/tmp</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/D:/SoftWare/hadoop-3.3.2/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/D:/SoftWare/hadoop-3.3.2/data/datanode</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>1</value>
</property>
</configuration>
下载 winutils.exe hadoop.dll
Github:https://github.com/cdarlint/winutils
找到对应的版本,下载winutils.exe hadoop.dll,放到hadoop的bin目录下
<img src="../AppData/Roaming/Typora/typora-user-images/image-20220608174808274.png" alt="image-20220608174808274" style="zoom: 50%;" />
<img src="../AppData/Roaming/Typora/typora-user-images/image-20220608180503994.png" alt="image-20220608180503994" style="zoom: 67%;" />
启动测试
进入命令行窗口,格式化hadoop
hadoop namenode -format
输出信息中提示有==namenode has been successfully formatted==即可
启动hadoop,在管理员权限的命令行中输入
start-all.cmd
然后启动四个进程的cmd,启动和报错信息会在里面显示
使用jps命令查看,如下即为正常启动
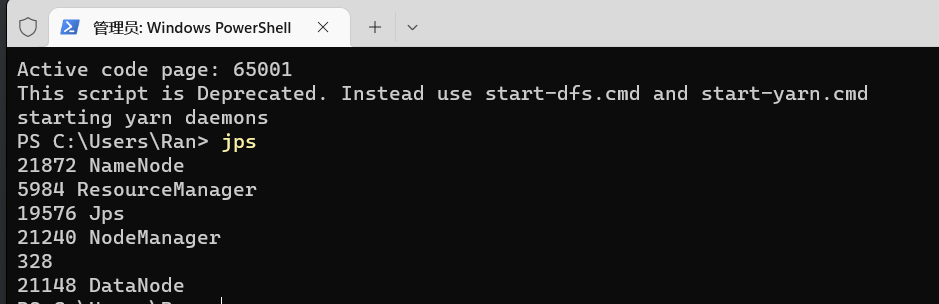
访问Web页面
http://localhost:9870/
Windows11安装Hadoop3.3.2的更多相关文章
- Ubuntn16.04.3安装Hadoop3.0+scale2.12+spark2.2
Ubuntn16.04.3安装Hadoop3.0+scale2.12+spark2.2 对比参照此博文.bovenson 前言:因为安装的Hadoop.Scale是基于JAVA的应用程序,所以必须先安 ...
- 基于zookeeper-3.5.5安装hadoop-3.1.2
目录 目录 1 1. 前言 3 2. 缩略语 3 3. 安装步骤 4 4. 下载安装包 4 5. 机器规划 4 6. 设置批量操作参数 5 7. 环境准备 5 7.1. 修改最大可打开文件数 5 7. ...
- ubuntu 18.04.1安装hadoop3.1.2
前提,虚拟机安装 见https://www.cnblogs.com/cxl-blog/p/11363183.html 一.按照https://blog.csdn.net/MastetHuang/art ...
- Hadoop3集群搭建之——hbase安装及简单操作
折腾了这么久,hbase终于装好了 ------------------------- 上篇: Hadoop3集群搭建之——虚拟机安装 Hadoop3集群搭建之——安装hadoop,配置环境 Hado ...
- Hadoop3集群搭建之——hive安装
Hadoop3集群搭建之——虚拟机安装 Hadoop3集群搭建之——安装hadoop,配置环境 Hadoop3集群搭建之——配置ntp服务 Hadoop3集群搭建之——hbase安装及简单操作 现在到 ...
- Hadoop3集群搭建之——虚拟机安装
现在做的项目是个大数据报表系统,刚开始的时候,负责做Java方面的接口(项目前端为独立的Java web 系统,后端也是Java web的系统,前后端系统通过接口传输数据),后来领导觉得大家需要多元化 ...
- 在Hadoop-3.1.2上安装HBase-2.2.1
目录 目录 1 1. 前言 3 2. 缩略语 3 3. 安装规划 3 3.1. 用户规划 3 3.2. 目录规划 4 4. 相关端口 4 5. 下载安装包 4 6. 修改配置文件 5 6.1. 修改策 ...
- 避坑之Hadoop安装伪分布式(Hadoop3.2.0/Ubuntu14.04 64位)
一.安装JDK环境(这个可以网上随意搜一篇教程了照着弄,这里不赘述) 安装成功之后 输入 输入:java -version 显示如下说明jdk安装成功(我这里是安装JDK8) 二.安装Hadoop3. ...
- CentOS7 hadoop3.3.1安装(单机分布式、伪分布式、分布式)
@ 目录 前言 预先设置 修改主机名 关闭防火墙 创建hadoop用户 SSH安装免密登陆 单机免密登陆--linux配置ssh免密登录 linux环境配置Java变量 配置Java环境变量 安装Ha ...
- linux18.04+jdk11.0.2+hadoop3.1.2部署伪分布式
1. 下载 安装hadoop3.1.2http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-3.1.2/hadoop-3.1.2.tar.gz 注意 ...
随机推荐
- uniapp输入空格
uniapp 密码框输入空格(去除空格)的时候一直回显不及时 经过一番折腾 终于搞定 1.先赋值: this.pwd = e.detail.value 2. 使用setTimeout(再 ...
- Go组件库总结之无等待锁
本篇文章我们用Go封装一个无等待锁库.文章参考自:https://github.com/brewlin/net-protocol 1.锁的封装 type Mutex struct { v int32 ...
- vue动态切换图片
1.踩的一个坑是:直接获取对象,使用style改变其背景图地址或者对img标签改变src值 因为经过vue经过打包编译后,图片地址已经被处理了,这时更新地址是无效的,会找不到图片. 所以可以用多个标签 ...
- 关于新手在使用git过程中的基本问题--前端开发篇
1.首先git是什么? git学名叫做分布式版本控制系统. 它能做啥呢?想一想,你在写项目的时候,尤其是大型的协作项目,往往一个项目会经过很多次修改才上线,在这个过程中,你会写项目1.0版.2.0版诸 ...
- 脚本执行sudo命令时: 免手动确认和免输入密码
1.sudo 命令有时候需要手动输入yes来确认执行 或者 软件在安装包下载完毕后还需要你输入y进行确认安装 .那如果是用脚本执行sudo 命令就可以用-y 参数来确认执行 sudo yum inst ...
- 解决问题mount.nfs: Stale file handle
原因出现在,机器1挂载了机器2的一个盘,然后机器2重启了,然后机器1变成没有响应的状态,然后卸载了机器1的对于这个盘的挂载,然后就一直挂不上,提示mount.nfs: Stale file handl ...
- IDEA使用fastjson1时maven引入依赖没报错,但是用不了JSONObject工具类
删除项目下的.idea文件夹重新打开项目就行, 不知道为什么
- linux系统:共享库问题之如version `ZLIB_1.2.9‘ not found
1. 错误提示: Gtk-WARNING **: Error loading image 'file:///usr/share/themes/Ambiance/gtk-3.0/assets/butto ...
- EXCEL函数总结
------------------截取"号"之前的字符 =MID(A45,1,FIND("号",A45,1)-1)
- MySQL Delete 表数据后,磁盘空间并未释放,为什么?
有开发小哥咨询了一个问题,记录一下处理过程分享给有需要的朋友.问题如下:MySQL数据库中有几张表增删比较频繁.数据变动剧烈且数据量大,导致数据增长过快,磁盘占用多.为了节约成本,定期进行数据备份,并 ...