【ConcurrentHashMap】浅析ConcurrentHashMap的构造方法及put方法(JDK1.7)
引言
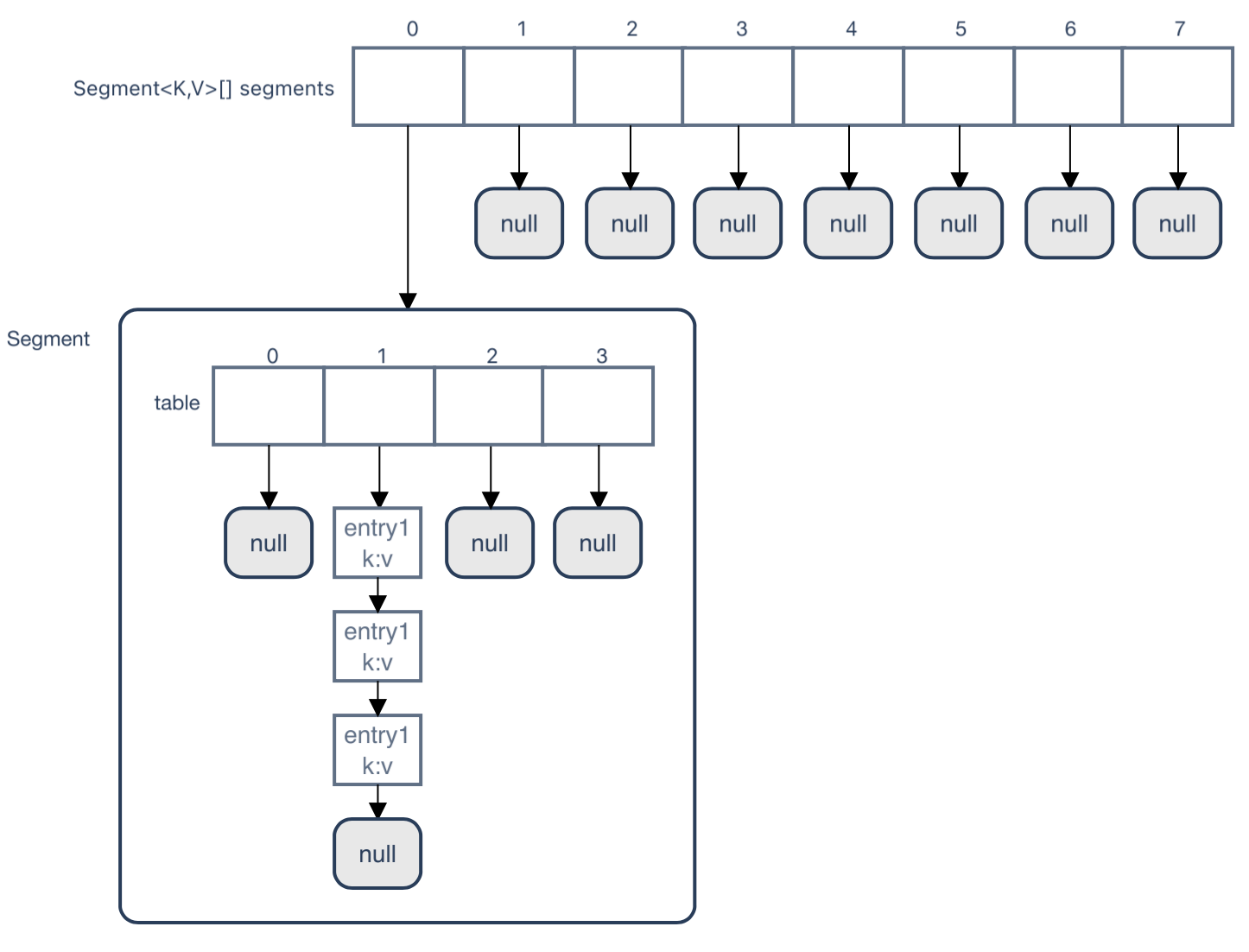
ConcurrentHashMap的数据结构如下。
和HashMap的最大区别在于多了一层Segment数组,Segment数组下再挂table。这也是ConcurrentHashMap既能保证并发安全,又能保证一定并非性能的关键。
一个k-v键值对想要放进ConcurrentHashMap的话,先计算出它在segment数组中的下标,然后再去计算它在table中的下标。在放进table的这段进行加锁,保证并非安全。所以如果两个线程同时想放k-v键值对进ConcurrentHashMap的话,它们所属的segment数组的下标不同,那么它们就可以并行操作。
除了对segment的操作、加锁操作(非阻塞锁)以外,对table的操作和HashMap中的逻辑差不多。
代码讲解
构造方法
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
// ---- 1.计算segment的size --------------------------------------------
// 并发性最大为2的16次方
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// 找到大于concurrencyLevel的最小2次幂,ssize即为segment的size
// segment的size在构造时就确定下来,后面不会扩容
// sshift记录的是,当前sssize是2的多少次幂
int sshift = 0;
int ssize = 1;
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
// ---- 2.计算segment相关的一些属性 --------------------------------------------
this.segmentShift = 32 - sshift;
// 计算segments下标的一个掩码
this.segmentMask = ssize - 1;
// ---- 3.计算table的初始size --------------------------------------------
// 初始的所有entry的capacity最大为2的30次方
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
// 第一次计算table的size:将capacity平均分到每个segment中
int c = initialCapacity / ssize;
// 第二次计算table的size:如果平均分了后,capacity小于用户传入的,期望的capacity,则将每个table的size+1
if (c * ssize < initialCapacity)
++c;
// 第三次计算table的size:找到大于c的最小2次幂,最终成为table的size
int cap = MIN_SEGMENT_TABLE_CAPACITY;
while (cap < c)
cap <<= 1;
// ---- 4.创建segment数组 --------------------------------------------
// 创建出segment的第0号元素,里面创建出了segment的数组。(所以第0号元素里包含有segment创建table数组的各种信息)
Segment<K,V> s0 =
new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]);
// 创建出segment的数组
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
// 将s0放到ss[0]上
// 所以最终创建的segment数组,除了第一个位置上有元素外,其它都为null
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
this.segments = ss;
}
put方法
public V put(K key, V value) {
Segment<K,V> s;
// concurrent hash map 的value不能为null
if (value == null)
throw new NullPointerException();
// 计算hash值
int hash = hash(key);
// 计算在segment中的index
int j = (hash >>> segmentShift) & segmentMask;
// 如果segment[j]上没有segment对象的话,则先创建出一个
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);
// ------- 到此处时,segment[j]上肯定有个segment对象了 -------------------------
// 将k:v放进map
return s.put(key, hash, value, false);
}
ensureSegment
private Segment<K,V> ensureSegment(int k) {
final Segment<K,V>[] ss = this.segments;
// 找到地址
long u = (k << SSHIFT) + SBASE; // raw offset
Segment<K,V> seg;
// 第一次尝试获取segment
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u)) == null) {
// 未获取到segment
// 创建table所需的基础数据
Segment<K,V> proto = ss[0]; // use segment 0 as prototype
int cap = proto.table.length;
float lf = proto.loadFactor;
int threshold = (int)(cap * lf);
// 创建出table
HashEntry<K,V>[] tab = (HashEntry<K,V>[])new HashEntry[cap];
// 第二次尝试获取segment
if ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))
== null) { // recheck
// 未获取到segment
// 以segment[0]为原型,创建出segment对象
Segment<K,V> s = new Segment<K,V>(lf, threshold, tab);
// 第三至n次尝试获取segment
while ((seg = (Segment<K,V>)UNSAFE.getObjectVolatile(ss, u))
== null) {
// 如果segment[k]上没有元素,则赋值(原子操作)
if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s))
break;
}
}
}
// 返回segment对象
return seg;
}
Segment.put
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// 尝试获取锁(非阻塞锁、自旋锁)
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
// ------- 到此处说明已经拿到了锁,node有可能有值,也可能没有 ------------------------------------------
V oldValue;
try {
HashEntry<K,V>[] tab = table;
// 找到在table中的位置,并拿到链表的头节点
int index = (tab.length - 1) & hash;
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
// 遍历所在的节点不为null(说明table下有链表)
if (e != null) {
K k;
// 找到了相同的key
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
// onlyIfAbsent -> 这个key不存在,才会去做修改。(key如果原来已经有值,则不动它)
// put方法中onlyIfAbsent为false,所以会进入这个方法,替换value的值
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
// 遍历所在的节点为null(table下没有链表,或链表遍历到了最后一个节点)
// 说明链表中没有key相同的节点,则生成新节点并放进去
else {
if (node != null)
// 如果node不为null,则只把first设置为node的next即可
node.setNext(first);
else
// 如果node为null,则创建node对象,并把first设置为node的next
node = new HashEntry<K,V>(hash, key, value, first);
// 头插法放入node
int c = count + 1;
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
// Doubles size of table and repacks entries, also adding the given node to new table
// 将table扩容为两倍,挪entry,并把node插入到链表中
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
// 解锁
unlock();
}
return oldValue;
}
【ConcurrentHashMap】浅析ConcurrentHashMap的构造方法及put方法(JDK1.7)的更多相关文章
- 【HashMap】浅析HashMap的构造方法及put方法(JDK1.7)
目录 引言 代码讲解 属性 HashMap的空参构造方法 HashMap的put方法 put inflateTable initHashSeedAsNeeded putForNullKey hash ...
- PHP面向对象的构造方法与析构方法
构造方法与析构方法是对象中的两个特殊方法,它们都与对象的生命周期有关.构造方法时对象创建完成后第一个被对象自动调用的方法,这是我们在对象中使用构造方法的原因.而析构方法时对象在销毁之前最后一个被对象自 ...
- at java.util.concurrent.ConcurrentHashMap.hash(ConcurrentHashMap.java:333)
at java.util.concurrent.ConcurrentHashMap.hash(ConcurrentHashMap.java:333) 原因: null request
- Java中构造方法跟普通方法的区别?
构造方法与普通方法的调用时机不同. 首先在一个类中可以定义构造方法与普通方法两种类型的方法,但是这两种方法在调用时有明显的区别. 1.构造方法是在实例化新对象(new)的时候只调用一次 2.普通方法是 ...
- 2、转载一篇,浅析人脸检测之Haar分类器方法
转载地址http://www.cnblogs.com/ello/archive/2012/04/28/2475419.html 浅析人脸检测之Haar分类器方法 [补充] 这是我时隔差不多两年后, ...
- 怎样理解JAVA的“构造方法”和“主方法”
在类中除了成员方法之外,还存在一种特殊类型的方法,那就是构造方法.主方法是类的入口点,它定义了程序从何处开始: 主方法提供对程序流向的控制,Java编译器通过主方法来执行程序.那么,下面一起来看一下关 ...
- Java中构造方法与setter方法
今天在重温Java的同时,一个不是问题的问题,突然地冒出来,不知道大家是不是和我一样,也有过这个比较尴尬的问题 不啰嗦了,那咱就直接说问题吧~~~ 那么首先我们在Java中都会写构造函数,目的是在 ...
- 一篇文章看懂java反射机制(反射实例化对象-反射获得构造方法,获得普通方法,获得字段属性)
Class<?> cls = Class.forName("cn.mldn.demo.Person"); // 取得Class对象传入一个包名+类名的字符串就可以得到C ...
- 浅析人脸检测之Haar分类器方法:Haar特征、积分图、 AdaBoost 、级联
浅析人脸检测之Haar分类器方法 一.Haar分类器的前世今生 人脸检测属于计算机视觉的范畴,早期人们的主要研究方向是人脸识别,即根据人脸来识别人物的身份,后来在复杂背景下的人脸检测需求越来越大,人脸 ...
- 浅析JavaScript访问对象属性和方法及区别
属性是一个变量,用来表示一个对象的特征,如颜色.大小.重量等:方法是一个函数,用来表示对象的操作,如奔跑.呼吸.跳跃等. 在JavaScript中通常使用”."运算符来存取对象的属性的值.或 ...
随机推荐
- Java堆空间的划分:新生代、老年代
参考链接:Java堆空间的划分:新生代.老年代
- screen--后台不挂断运行
方法一:1.进入项目目录下,运行下面程序:nohup python manage.py runserver 0.0.0.0:5008 &nohup(no hang up)用途:不挂断的运行命令 ...
- Java语言的特点有哪些?
1.简单 Java最初是为对家用电器进行集成控制而设计的一种语言,因此它必须简单明了.Java语言的简单性主要体现在以下三个方面: 1) Java的风格类似于C++,因而C++程序员是非常熟悉的.从某 ...
- TCP 重传、滑动窗⼝、流量控制、拥塞控制
重传机制 TCP 会在以下两种情况发⽣超时重传: 数据包丢失 确认应答丢失 重传超时 重传超时是TCP协议保证数据可靠性的另一个重要机制,其原理是在发送某一个数据以后就开启一个计时器,在一定时间内如果 ...
- 顺利通过EMC实验(15)
- vue2.0开发聊天程序(八) 初步完成
项目地址 服务器源码地址:https://github.com/ermu592275254/chat-socket 网页源码地址:https://github.com/ermu592275254/ch ...
- ffmpeg将视频生成gif
1.安装ffmpeg 2.cmd中输入 ffmpeg -i 0.mp4 -f gif 0.gif 即可将视频转为gif
- jboss7学习4-具体下载安装
一.JBoss优点: a.Jboss支持热部署,将归档后的JAR.WAR文件到部署目录下自动加载部署,自动更新. b.在高并发访问时,性能比Tomcat更加优秀.高效. c.Jboss在设计方面与To ...
- FreeSql的各种工程demo上新啦
FreeSql的各种工程demo GitHub | Gitee console,winforms nf461,vb,wpf,webapi,workerSevice,signalIR xamarinFo ...
- TINY语言采用递归下降分析法编写语法分析程序
目录 自顶向下分析方法 TINY文法 消左提左.构造first follow 基本思想 python构造源码 运行结果 参考来源:聊聊编译原理(二) - 语法分析 自顶向下分析方法 自顶向下分析方法: ...