论文解读(GROC)《Towards Robust Graph Contrastive Learning》
论文信息
论文标题:Towards Robust Graph Contrastive Learning
论文作者:Nikola Jovanović, Zhao Meng, Lukas Faber, Roger Wattenhofer
论文来源:2021, arXiv
论文地址:download
论文代码:download
1 Introduction
创新点:从对抗攻击和对抗防御考虑数据增强策略。
2 Graph robust contrastive learning
2.1 Background
目的:期望同一节点在 $\tau_{1}$ 和 $\tau_{2}$ 下的嵌入是相似的。同时,期望不同节点的嵌入在两个图视图之间的嵌入是不同的。
令:$N e g(v)=\left\{\tau_{1}(u) \mid u \in V \backslash\{v\}\right\} \cup\left\{\tau_{2}(u) \mid u \in V \backslash\{v\}\right\}$ 是两个图视图中除 $v$ 以外的节点的嵌入。$ \sigma$ 是相似性度量函数。
即:
通过下式计算编码器的参数 $ \theta $ :
$ \underset{\theta}{ \arg \max } \;\;\; \mathbb{E}_{\tau_{1}, \tau_{2} \sim \mathrm{T}}\left[\sum\limits _{v \in V} \sigma\left(z_{1}, z_{2}\right)-\sum\limits_{u \in N e g(v)} \sigma\left(z_{1}, f_{\theta}(u)\right)\right]$
其中 $z_{1} \equiv f_{\theta}\left(\tau_{1}(v)\right)$ , $z_{2} \equiv f_{\theta}\left(\tau_{2}(v)\right) $
由于转换 $T$ 的搜索空间较大,且缺乏优化算法,上述优化问题难以解决。我们遵循GRACE方法来解决这个问题。即 先对 $z_{1}, z_{2}$ 施加一个两层的 MLP ,然后再计算余弦相似度,损失函数变为:
$\frac{1}{2 n} \sum\limits _{v \in V}\left[\mathcal{L}\left(v, \tau_{1}, \tau_{2}\right)+\mathcal{L}\left(v, \tau_{2}, \tau_{1}\right)\right]\quad\quad\quad(1)$
其中:
$\mathcal{L}\left(v, \tau_{1}, \tau_{2}\right)=-\log {\Large \frac{\exp \left(\sigma\left(z_{1}, z_{2}\right) / t\right)}{\exp \left(\sigma\left(z_{1}, z_{2}\right) / t\right)+\sum\limits _{u \in N e g(v)} \exp \left(\sigma\left(z_{1}, f_{\theta}(u)\right) / t\right)}} $
2.2 Motivation
上述对比学习方法在无标签的情况下效果不错,但是其准确率在对抗攻击的条件下显著下降。
2.3 Method
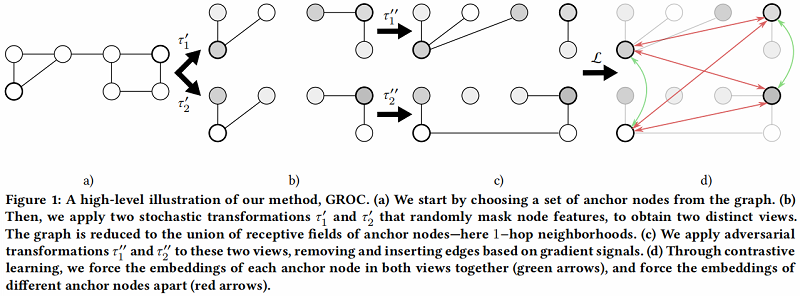
对于 $ \tau_{i}^{\prime}$,我们只是使用随机特征掩蔽。对于 $\tau_{2}^{\prime}$,我们使用了两种类型的基于边缘的转换。
令 $\tau_{i} \in T$ 表示为数据增强组合 $ \tau_{i}=\tau_{i}^{\prime} \circ \tau_{i}^{\prime \prime} $,即随机数据增强和对抗(攻击和防御)。
普通数据增强层面:
分别应用随机数据增强(只用特征隐藏)$\tau_{1}^{\prime} $、 $\tau_{2}^{\prime}$ 于原始图,得到对应两个视图。
对抗层面:(边删除和边插入)
受对抗防御的影响,本文提出基于梯度信息选择要删除的边的策略。先对应用 $\tau^{\prime}$ 后的两个视图进行一次前向和反向传播过程,得到边缘上的梯度。因为需要最小化 $\text{Eq.1}$ ,所以选择一个最小梯度值的边子集合。
同时,引入基于梯度信息的边插入。由于插入所有未在图中的边不切实际,所以考虑在每个 batch $b$上处理,还将将插入集合 $S^{+}$ 限制在 边 $(u,v)$ 上。设 $ v$ 是一个锚节点,$ u$ 在 $v^{\prime} \neq v$ 的 $-hop$ 邻域内,而不在 $ v$ 的 $-hop$ 邻域内,这里暂时将 $S^{+}$ 中的边权重设置为 $1/|S^{+}|$。这里先将 $S^{+}$ 插入到两个视图。
然后在 Batch 中计算损失。最后分别在两个视图上进行基于梯度最小的边删除和基于最大的边插入。
此外,假设节点批处理还有一个额外的好处,因为这大大减少了每个 $v$ 的 $Neg(v)$ 中的负例子的数量,使个 $v$ 更多地关注它在另一个视图中的表示。GROC算法如图 1 所示,详见算法1。

3 Experiments
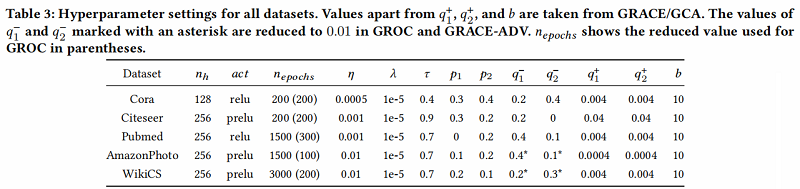
数据集及超参数设置
参数:
- 编码器 $f_{\theta} $ 是两层的 GCN ,每层的大小分别为:$2n_h$ 、$n_h$
- 学习率:$\eta$
- 训练次数:$n_{epoch}$
- L2惩罚项的惩罚因子:$\lambda$
- 温度参数:$\tau$
- 特征掩蔽率:$p_1$、$p_2$
- 边删除率:$q_{1}^{-}$、$q_{2}^{-}$
- 边插入率:$q_{1}^{+}$、$q_{2}^{+}$
- 节点批次大小 :$b$
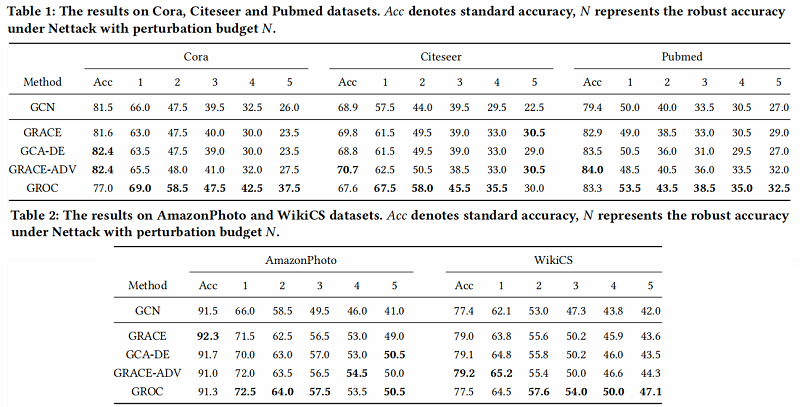
基线实验
结论
在本研究中,我们关注图形自监督学习方法的对抗鲁棒性问题。我们怀疑,并且通过后来的实验证实,先前引入的对比学习方法很容易受到对抗性攻击。作为在这种情况下实现鲁棒性的第一步,我们引入了一种新的方法,GROC,它通过引入对抗性转换和边缘插入来增强图视图的生成。我们通过一组初步的实验证实了该方法可以提高所产生的表示的对抗性鲁棒性。我们希望这项工作最终将导致在图上产生更成功和更鲁棒的对比学习算法。
相关论文
微小扰动对高精度 GNNs 任然有影响:[7, 25, 31]
使用对抗变换是能有效提高表示能力的:[19]
基于预训练的带属性图:[12]
视觉上的对比学习:[2, 10]
图上的对比学习:[9, 27, 28, 30, 33, 36, 39, 40]
两视图(删边和属性隐藏)的对比学习:[40]
多视图图级对比学习:[36]
不需要加负样本:[8]
图上不需要加负样本:[1, 32]
论文解读(GROC)《Towards Robust Graph Contrastive Learning》的更多相关文章
- 论文解读(SimGRACE)《SimGRACE: A Simple Framework for Graph Contrastive Learning without Data Augmentation》
论文信息 论文标题:SimGRACE: A Simple Framework for Graph Contrastive Learning without Data Augmentation论文作者: ...
- 论文解读(MLGCL)《Multi-Level Graph Contrastive Learning》
论文信息 论文标题:Structural and Semantic Contrastive Learning for Self-supervised Node Representation Learn ...
- 论文解读(GCA)《Graph Contrastive Learning with Adaptive Augmentation》
论文信息 论文标题:Graph Contrastive Learning with Adaptive Augmentation论文作者:Yanqiao Zhu.Yichen Xu3.Feng Yu4. ...
- 论文解读(GGD)《Rethinking and Scaling Up Graph Contrastive Learning: An Extremely Efficient Approach with Group Discrimination》
论文信息 论文标题:Rethinking and Scaling Up Graph Contrastive Learning: An Extremely Efficient Approach with ...
- 论文解读GALA《Symmetric Graph Convolutional Autoencoder for Unsupervised Graph Representation Learning》
论文信息 Title:<Symmetric Graph Convolutional Autoencoder for Unsupervised Graph Representation Learn ...
- 论文解读《Deep Attention-guided Graph Clustering with Dual Self-supervision》
论文信息 论文标题:Deep Attention-guided Graph Clustering with Dual Self-supervision论文作者:Zhihao Peng, Hui Liu ...
- 论文解读(GraRep)《GraRep: Learning Graph Representations with Global Structural Information》
论文题目:<GraRep: Learning Graph Representations with Global Structural Information>发表时间: CIKM论文作 ...
- 论文解读(GMT)《Accurate Learning of Graph Representations with Graph Multiset Pooling》
论文信息 论文标题:Accurate Learning of Graph Representations with Graph Multiset Pooling论文作者:Jinheon Baek, M ...
- 论文解读(JKnet)《Representation Learning on Graphs with Jumping Knowledge Networks》
论文信息 论文标题:Representation Learning on Graphs with Jumping Knowledge Networks论文作者:Keyulu Xu, Chengtao ...
随机推荐
- Redis Cluster 集群搭建与扩容、缩容
说明:仍然是伪集群,所有的Redis节点,都在一个服务器上,采用不同配置文件,不同端口的形式实现 前提:已经安装好了Redis,本文的redis的版本是redis-6.2.3 Redis的下载.安装参 ...
- 使用 rabbitmq 的场景?
1.服务间异步通信 2.顺序消费 3.定时任务 4.请求削峰
- javax.net.ssl.sslhandshakeException:sun.security.validator.validatorException:PKIX path buildind failed
前段时间开发的一个需求,需要通过图片URL获取图片的base64编码,测试的时候使用的是百度图片的url,测试没有问题,但是发布后测试时报如下错: javax.net.ssl.sslhandshake ...
- 为什么说 Mybatis 是半自动 ORM 映射工具?它与全自动 的区别在哪里?
Hibernate 属于全自动 ORM 映射工具,使用 Hibernate 查询关联对象或者关联 集合对象时,可以根据对象关系模型直接获取,所以它是全自动的.而 Mybatis 在查询关联对象或关联集 ...
- 客户端注册 Watcher 实现 ?
1.调用 getData()/getChildren()/exist()三个 API,传入 Watcher 对象 2.标记请求 request,封装 Watcher 到 WatchRegistrati ...
- 什么是 spring 的内部 bean?
只有将 bean 用作另一个 bean 的属性时,才能将 bean 声明为内部 bean. 为了定义 bean,Spring 的基于 XML 的配置元数据在 <property> 或 &l ...
- java-jdbc-all
jdbc相关解析 JDBC(Java DataBase Connectivity,Java数据库连接)是一种用于执行SQL语句的Java API,可以为多种关系数据库提供统一访问,它由一组用Java语 ...
- 如何理解 Spring 中的代理?
将 Advice 应用于目标对象后创建的对象称为代理.在客户端对象的情况下,目 标对象和代理对象是相同的. Advice + Target Object = Proxy
- resin服务之一---安装及部署
参考网站: http://caucho.com/ http://www.oschina.net/p/resin http://caucho.com/resin-4.0/admin/starting-r ...
- ACM - 动态规划 - UVA 1347 Tour
UVA 1347 Tour 题解 题目大意:有 \(n\) 个点,给出点的 \(x\).\(y\) 坐标.找出一条经过所有点一次的回路,从最左边的点出发,严格向右走,到达最右点再严格向左,回到最左点. ...