电商AARRR模型分析(一)——R语言
在2010年,互联网创业者增长黑客之父肖恩·埃利斯(Sean Ellis)就创造了增长黑客(Growth hacker)这样一个概念。2015年,范冰撰写的一本新书《增长黑客》确立了Growth hacker的概念,同时引进了AARRR(增长黑客理论)基本模型,通常采用的手段包括A/B测试,搜索引擎优化,电子邮件召回,病毒营销等,而页面加载速度,注册转化率,E-mail到达水平,病毒因子等指标成为他们日常关注的对象。AARRR模型因其掠夺式的增长方式也被称为海盗模型、海盗指标,也叫增长黑客理论模型、增长模型、2A3R模型、决策模型,是硅谷著名风险投资人戴夫·麦克卢尔(Dave McClure )2007提出的,核心就是AARRR漏斗模型。AARRR是Acquisition、Activation、Retention、Revenue、Referral,五个单词的缩写,分别对应用户生命周期中的5个阶段。

一、什么是AARRR模型?
AARRR是Acquisition、Activation、Retention、Revenue、Refer,这个五个单词的缩写,分别对应用户生 命周期中的5个重要环节:获取用户、提高用户活跃度、提高用户留存率、获取收入、自传播。AARRR模型因其掠夺式的增长方式也被称为海盗模型,同时它也是一个典型的漏斗模型可以用来评估连续的业务流程节点转化率。通过该模型可以有针对性的对出现问题的重要节点进行优化,达到提升ROI的目的。
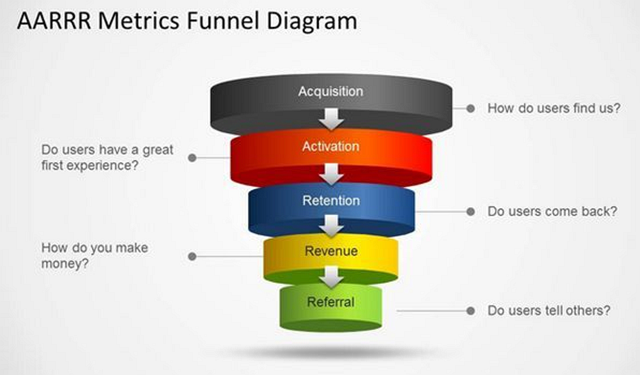
漏斗模型图(来源于网络)
获取
也叫拉新、获客。运营一款移动应用的第一步,毫无疑问是获取用户,也就是大家通常所说的推广。如果没有用户,就谈不上运营。获取用户阶段需要关注的指标:日新登用户数(DNU),对于DNU的定义也可以是,首次登录或启动APP的用户。需要说明的是,在移动统计中,有时候用户也特指设备。解决问题:1.渠道贡献的用户份额。2.宏观走势,确定投放策略。3.是否存在大量垃圾用户。4.注册转化率分析。
激活
其他说法,促活、提高活跃度。很多用户可能是通过终端预置(刷机)、广告等不同的渠道进入应用的,这些用户是被动地进入应用的。如何把他们转化为活跃用户,是运营者面临的第一个问题。新增用户经过沉淀转化为活跃(Activation)用户。这时我们需要关注活动用户的数量以及用户使用频次、停留时间的数据。
(1)日活跃用户数(DAU),定义:每日登录过游戏的用户数,活跃用户的计算是排重的。
解决问题:1.核心用户规模。2.产品生命周期分析。3.产品活跃用户流失,分解活跃用户。4.用户活跃率,活跃用户计用户量。
(2)周活跃用户数(WAU),定义:最近7日(含当日)登录过APP的用户数,一般按照自然周计算。
解决问题:1.周期性用户规模。2.周期性变化趋势,主要是推广期和非推广期的比较。
(3)月活跃用户数(MAU),定义:最近一个月即30日(含当日)登录过APP的用户数,一般按照自然月计算。
推广时期,版本更新、运营活动的调整,对于MAU的冲击则更加明显。此外,产品的生命周期阶段不同,MAU的趋势变化也不同。
解决问题:1.用户规模稳定性。2.推广效果评估。3.总体用户规模变化。
(4)日均使用时长(DAOT),定义:每日总计在线时长/日活跃用户数。
关于使用时长,可以分为单次使用时长、日使用时长和周使用时长等指标,通过对这些指标做区间分布和平均计算,了解参与黏性。
解决问题:1.分析产品的质量问题。2.观察不同时间维度的平均使用时长,了解不同用户群的习惯。3.渠道质量衡量标准之一。4.留存即流失分析的依据。
(5)DAU/MAU,定义:日活与月活的比值。
通过DAU/MAU可以看出用户每月访问App的平均天数是多少,比如:某个App拥有50万DAU,100万MAU,其DAU/MAU比值就是0.5,即用户每月平均访问的时间是30*0.5=15天。这也是评估用户粘性的一个比较重要的指标。DAU/MAU介于3.33%到100%之间,但显然这两种情况现实中基本不可能出现。在不同领域的App会有不同的基准值可参考,例如移动游戏会以20%为基线,王者荣耀在2017年6月和9月的值基本都在31%左右。而工具类App会以40%为基线。DAU/MAU的值越高,那么毫无疑问,App的粘性越强,表示有更多的用户愿意使用App;反之如果DAU/MAU的值很低,但并不能直接说这个App是失败的。我们还需要结合产品属性(比如定期理财/求职/买房/租房的App,可能天然属性DAU会相对低)、时间考量(工作日/假期等)、版本更新、运营活动、用户维度的ARPU值等多个条件进行多维分析,才能得出结论。所以,正确理解DAU/MAU的意义很重要。
留存
也有叫存留、提高留存率。解决了活跃度的问题,又发现了另一个问题:“用户来得快、走得也快”。有时候我们也说是游戏没有用户粘性或者留存。我们需要可以用于衡量用户粘性和质量的指标,这是一种评判APP初期能否留下用户和活跃用户规模增长的手段,留存率(Retention)是手段之一。
留存率:某段时间的新增用户数,记为A,经过一段时间后,仍然使用的用户占新增用户A的比例即为留存率。
(1)次日留存率(Day 1RetentionRatio),定义:日新增用户在+1日登录的用户数占新增用户的比例。
(2)三日留存率(Day 3Retention Ratio),定义:日新增用户在+3日登录的用户数占新增用户的比例。
(3)七日留存率(Day 7Retention Ratio),定义:日新增用户在+7日登录的用户数占新增用户的比例。
注意,计算留存率时,新增当日是不被计入天数的,也就是说我们提到的留存用户,指的是新增用户新增后的第1天留存、第3天留存和第7天留存。解决问题:1.APP质量评估。2.用户质量评估。3.用户规模衡量。
流失率:统计时间区间内,用户在不同的时期离开APP的情况。
(1)日流失率(Day 1ChurnRatio),定义:统计日登录APP,但随后7日未登录APP的用户占统计日活跃用户的比例。
(2)周流失率(Week Churn Ratio),定义:上周登录过APP,但是本周未登录过APP的用户占上周周活跃用户的比例。
(3)月流失率(Month Churn Ratio),定义:上月登录过APP,但是本月未登录过APP的用户占上月月活跃用户的比例。
流失率是在APP进入稳定期需要重点关注的指标,如果说关注留存是关注APP用户前期进入APP的情况,那么关注流失率则是在产品中期和后期关心产品的用户稳定性,收益能力转化。稳定期的收益和活跃都很稳定,如果存在较大的流失率,则需要通过该指标起到警示作用,并逐步查找哪部分用户离开了APP,问题出在哪里。尤其是对付费用户流失的分析,更需要重点关心。解决问题:1.活跃用户生命周期分析。2.渠道的变化情况。3.拉动收入的运营手段,版本更新对于用户的流失影响评估。4.什么时期的流失率较高。5.行业比较和产品中期评估。
收入
也有叫获取收益、付费、变现、转化。收入的来源有很多种,主要包括:应用付费、应用内功能付费、广告收入、流量变现等,主要考核的指标比如ARPU(客单价)。主要关注:
(1)付费率(PR或者PUR),定义:付费用户数占活跃用户的比例。
(2)活跃付费用户数(APA),定义:在统计时间区间内,成功付费的用户数。一般按照月计,在国际市场也称作MPU(Monthly Paying Users)。
(3)平均每用户收入(ARPU),定义:在统计时间内,活跃用户产生的平均收入。一般以月计。
(4)平均每付费用户收入(ARPPU),定义:在统计时间内,付费用户产生的平均收入。一般以月计。
(5)生命周期价值(LTV),定义:用户在生命周期内为创造的收入总和。可以看成是一个长期累积的ARPU。
传播
也叫推荐、自传播、口碑传播或者病毒式传播。其中有一个重要的指标K因子。
K因子的计算公式不算复杂,过程如下:K=(每个用户向他的朋友们发出的邀请的数量)×(接收到邀请的人转化为新用户的转化率)。假设平均每个用户会向20个朋友发出邀请,而平均的转化率为10%,则K=20×10%=2。当K>1时,用户群就会像滚雪球一样增大。当K<1时,用户群到某个规模时就会停止通过自传播增长。绝大部分APP还不能完全依赖于自传播,还必须和其他营销方式结合。但是,在产品设计阶段就加入有利于自传播的功能,还是有必要的,毕竟这种免费的推广方式可以部分地减少CAC(用户获取成本)。
二、AARRR模型的分析框架
分析矿棉可以帮助我们梳理分析流程,一是温故知新,二是为了便于今后复习。
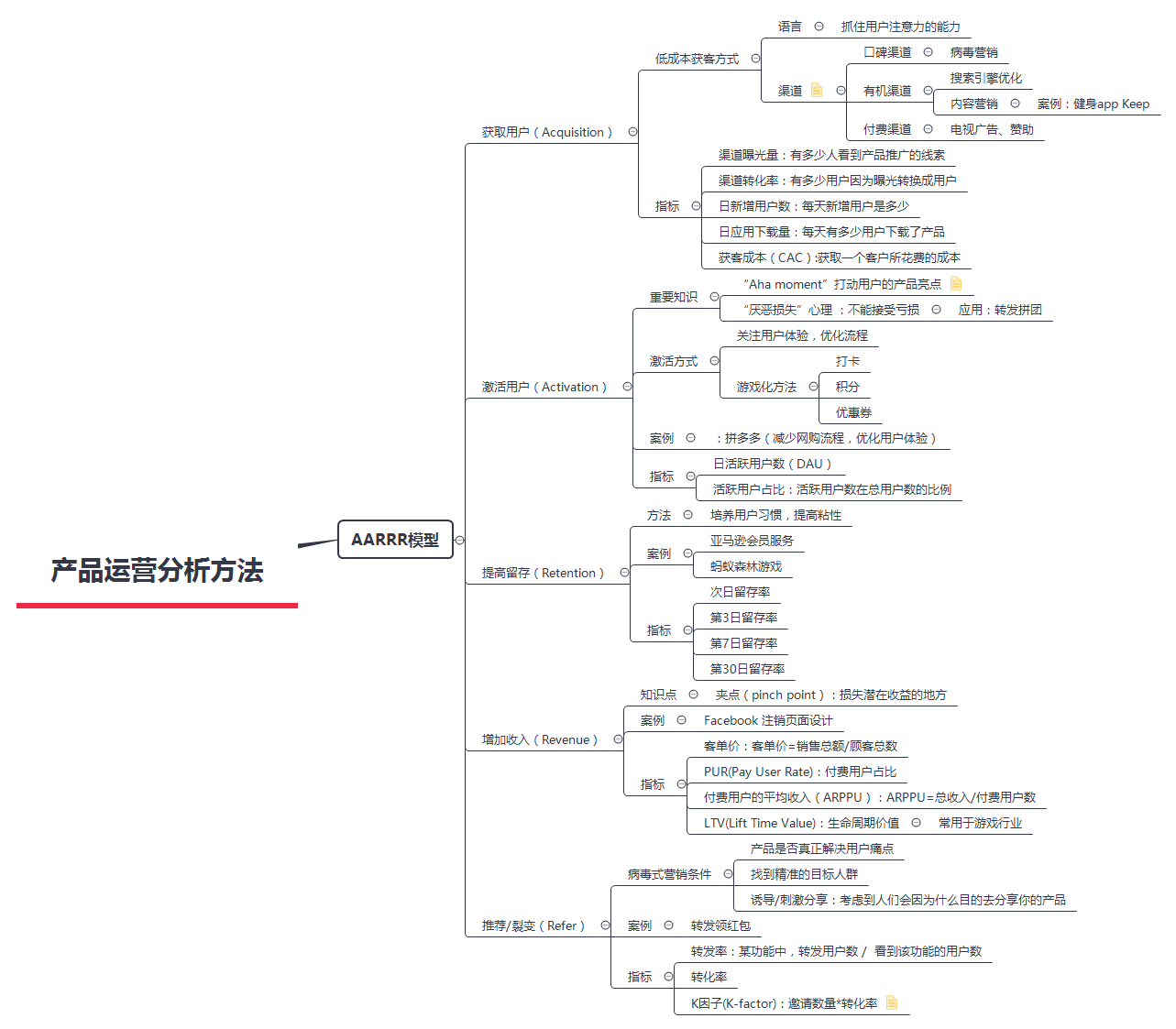
三、数据处理
3.1 数据来源
阿里云天池: https://tianchi.aliyun.com/dataset/dataDetail?dataId=649
本数据集包含了2017年11月25日至2017年12月3日之间,约有一百万随机用户的所有行为(行为包括点击、购买、加购、喜欢)。数据集的每一行表示一条用户行为,由用户ID、商品ID、商品类目ID、行为类型和时间戳组成,并以逗号分隔。时间跨度约为一个礼拜,从周六到下个周日。
library(stringr)
library(dplyr)
library(lubridate)
library(tidyverse)
columns<- cbind("user_id","item_id","category_id","behavior","timestamps")
df=read.csv('UserBehavior.csv',header=FALSE)
names(df) <-columns
columns1<- cbind("user","item","category","behavior","date")
data=df[5000001:8000000,]
names(data) <-columns1
user_id item_id category_id behavior timestamps
1 1 2268318 2520377 pv 1511544070
2 1 2333346 2520771 pv 1511561733
3 1 2576651 149192 pv 1511572885
4 1 3830808 4181361 pv 1511593493
5 1 4365585 2520377 pv 1511596146
6 1 4606018 2735466 pv 1511616481
7 1 230380 411153 pv 1511644942
8 1 3827899 2920476 pv 1511713473
9 1 3745169 2891509 pv 1511725471
10 1 1531036 2920476 pv 1511733732
各字段含义
| 列名称 | 解释 |
|---|---|
| 用户ID | 整数类型,序列化后的用户 |
| 商品ID | 整数类型,序列化后的商品ID |
| 商品类目ID | 整数类型,序列化后的商品所属类目ID |
| 行为类型 | 字符串、枚举类型,包括('pv','buy','cart','fav') |
| 时间戮 | 行为发生的时间点 |
注意到,用户行为类型共有四种,它们分别是
| 行为类型 | 说明 | 维度 | 容量 |
|---|---|---|---|
| pv | 商品详细页pv,等价于点击 | 用户数量 | 987994 |
| buy | 商品购买 | 商品数量 | 4162024 |
| cart | 将商品加入购物车 | 商品类目数量 | 9439 |
| fav | 收藏商品 | 所有行为数量 | 100150807 |
关于数据集大小的一些说明见上表。
3.2 数据清洗
观察记录
数据记录达到一亿条,为了方便分析及效率,源数据是已经按照user_id排序好的,取5百万行到8百万行之间的3百万行记录进行分析。
列名重命名
将原有的列名简化为user,item,category,behavior,date,见下面。
删除重复值
用户的购买行为由于时间精确到小时,确实会存在少量用户在一小时内重复购买或浏览统一商品的行为,因此不对此部分数据进行处理。
一致化处理
时间数据中原为时间戳格式,需要将其分为两列,以便研究每日和一段日期内数据变化。完成数据清洗后的数据:
tt<-as.POSIXlt(data$date,origin ='1970-01-01')
date=paste0(year(tt),"-",month(tt),"-",mday(tt))
date<-ymd(date)
data1 <- data.frame(data[,1:4],date,hour(tt))
columns2<- cbind("user","item","category","behavior","date","hour")
names(data1) <-columns2
head(data1,10)
user item category behavior date hour
5000001 309818 1461532 3102419 cart 2017-11-29 20
5000002 309818 4710383 1792277 pv 2017-11-29 20
5000003 309818 1421743 4069500 pv 2017-11-29 20
5000004 309818 800137 1216617 pv 2017-11-29 20
5000005 309818 2493122 1216617 pv 2017-11-29 20
5000006 309818 1461532 3102419 pv 2017-11-30 7
5000007 309818 3648099 4220654 buy 2017-11-30 9
5000008 309818 149503 58836 pv 2017-11-30 9
5000009 309818 5097964 3415753 pv 2017-11-30 9
5000010 309818 3648099 4220654 pv 2017-12-01 6
剔除时间区间外的数据
summary(data1)
data2<- filter(data1,data1$date<= "2017-12-3")
data3<- filter(data2,data2$date >= "2017-11-25") #根据时间过滤
summary(data3)
summary(data3)
user item category behavior date hour
Min. : 34 Min. : 8 Min. : 1147 Length:2998310 Min. :2017-11-25 Min. : 0.00
1st Qu.:332085 1st Qu.:1293007 1st Qu.:1343555 Class :character 1st Qu.:2017-11-27 1st Qu.:11.00
Median :369589 Median :2578287 Median :2693696 Mode :character Median :2017-11-29 Median :16.00
Mean :343053 Mean :2577554 Mean :2707065 Mean :2017-11-29 Mean :14.94
3rd Qu.:407347 3rd Qu.:3857246 3rd Qu.:4145813 3rd Qu.:2017-12-02 3rd Qu.:20.00
Max. :445081 Max. :5163064 Max. :5161669 Max. :2017-12-03 Max. :23.00
至此,数据预处理完毕。
3.3 构建模型
分析用户使用户行为的漏斗模型
利用AARRR模型分析用户行为,此处数据主要涉及用户刺激和购买转化的环节,通过用户从浏览到最终购买整个过程的流失情况,包括浏览、收藏、加入购物车和购买环节,一个周内的各项指标如下:
nunique(data3$user)
length(unique(data3$user))
table(data3$behavior)
访问用户总数(UV) |
页面总访问量(PV) |
平均每人每周访问量 |
|---|---|---|
| 29233 | 2683657 | 91.80 |
跳失率=只点击一次浏览的用户数量/总用户访问量
ff<-table(data3[,c("user","behavior")]) #生成交叉分组列表
gg=marginSums(ff,1) #求各行的和:公式中1代表以行求和,公式中2代表以列求和
gg=as.data.frame(gg)
count(filter(gg,gg[,2]<=1)) #统计只点击一次浏览的用户数量
统计时间为一周,只有1个人浏览了一次就离开淘宝,分析记录虽然仅为部分数据,但仍可以看出淘宝拥有足够的吸引力让用户停留app,这也符合日常观察。
用户总行为数的漏斗计算
table(data3$behavior)
buy cart fav pv
59329 168771 86553 2683657

由于收藏和加入购物车都为浏览和购买阶段之间确定购买意向的用户行为,且不分先后顺序,因此将其算作同一阶段,可以看到从浏览到有购买意向只有9.51%的转化率,当然有部分用户是直接购买而未通过收藏和加入购物车,但也说明大多数用户浏览页面次数较多,而使用购物车和收藏功能较少,而购买次数占使用购物车和收藏功能的23.24%,说明从浏览到进行收藏和加入购物车的阶段是指标提升的重点环节。
独立访客漏斗模型计算
replace(ff, ff >= 1, 1)
hh=marginSums(replace(ff, ff >= 1, 1),2)
behavior
buy cart fav pv
19865 22131 11638 29116
barplot(head(hh))

上面是每个用户行为的独立用户数,可以看到使用APP的用户中PUR(付费用户占比)为68.23%,用户付费转化率相当高。
总结
AARRR模型应用范围广,分析指标因行业差异而不同,在实际工作中要结合自身的业务特征灵活运用,同时需注意培养分析思维。漏斗模型在分析流程节点转化率的同时也需要考虑流失率问题,遇到问题多想想其他的维度,会给你不一样的惊喜。漏斗模型可能存在分析项目的一个环节,也就是说分析方法模型不是孤立存在的。往往一个完整的分析报告是一个多维度分析的产物。在用户运营体系中,AARRR是一个经典的框架模型,它可以帮助我们更好地理解用户生命周期,采取有针对性的营销。但是随着流量红利逐渐消失,增量空间变小,增长变得越来越难,AARRR模型不再是今天这个时代有效的黑客增长模型。
随着流量红利逐渐消失,移动互联网行业获取新用户越来越难,推广成本也在水涨船高。行业亟需一套新的增长模型作为指导以完成存量竞争时代下的增长突围。一个全新的用户增长模型——“6R”,正向我们走来。“6R模型”沉淀了每日互动(个推)多年来深耕移动互联网领域的实践经验以及对数据智能行业的深入理解,在数据和技术的深度融合下增能智慧化运营,为移动互联网开发者打破增长困境开辟新路径。“6R模型”为移动互联网开发者提供了用户全生命周期智能管理的新路径。6R是数据、技术与场景的深度聚合,用对方法,行业才能够更自如地应对多样和复杂的市场变化,带动新的增长。移动互联网行业正加速迈进数据智能时代,新一轮的用户增长将会涌现哪些新奇迹?呈现何种新局面?我们拭目以待。
参考文献
1.(AARRR模型应用实例(分析淘宝用户行为数据))[https://zhuanlan.zhihu.com/p/285676746]
2.(淘宝用户行为数据分析报告(基于AARRR模型))[https://zhuanlan.zhihu.com/p/313235276]
3.(淘宝用户行为数据分析详解)[https://blog.csdn.net/qq_46893497/article/details/114010008?spm=1001.2101.3001.6650.7&utm_medium=distribute.pc_relevant.none-task-blog-2~default~OPENSEARCH~default-7-114010008-blog-122768573.pc_relevant_multi_platform_whitelistv1_exp2&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2~default~OPENSEARCH~default-7-114010008-blog-122768573.pc_relevant_multi_platform_whitelistv1_exp2&utm_relevant_index=10]
电商AARRR模型分析(一)——R语言的更多相关文章
- Java生鲜电商平台-电商促销业务分析设计与系统架构
Java生鲜电商平台-电商促销业务分析设计与系统架构 说明:Java开源生鲜电商平台-电商促销业务分析设计与系统架构,列举的是常见的促销场景与源代码下载 左侧为享受促销的资格,常见为这三种: 首单 大 ...
- 电商打折套路分析 —— Python数据分析练习
电商打折套路分析 ——2016天猫双十一美妆数据分析 数据简介 此次分析的数据来自于城市数据团对2016年双11天猫数据的采集和整理,原始数据为.xlsx格式 包括update_time/id/tit ...
- survival analysis 生存分析与R 语言示例 入门篇
原创博客,未经允许,不得转载. 生存分析,survival analysis,顾名思义是用来研究个体的存活概率与时间的关系.例如研究病人感染了病毒后,多长时间会死亡:工作的机器多长时间会发生崩溃等. ...
- R语言重要数据集分析研究——R语言数据集的字段含义
R语言数据集的字段含义 作者:马文敏 选择一种数据结构来储存数据 将数据输入或导入到这个数据结构中 数据集的概念 数据集通常是有数据结构的一个矩形数组,行表示规则,列表示变量. 不同的行业对数据集的行 ...
- SpringCloud Alibaba实战(2:电商系统业务分析)
选用了很常见的电商业务来进行SpringCloud Alibaba的实战. 当然,因为仅仅是为了学习SpringCloud Alibaba,所以对业务进行了大幅度简化,这里只取一个精简版的用户下单业务 ...
- 模型验证方法——R语言
在数据分析中经常会对不同的模型做判断 一.混淆矩阵法 作用:一种比较简单的模型验证方法,可算出不同模型的预测精度 将模型的预测值与实际值组合成一个矩阵,正例一般是我们要预测的目标.真正例就是预测为正例 ...
- 插值和空间分析(二)_变异函数分析(R语言)
方法1.散点图 hscat(log(zinc)~, meuse, (:)*) 方法2.变异函数云图 library(gstat) cld <- variogram(log(zinc) ~ , m ...
- R语言中文分词包jiebaR
R语言中文分词包jiebaR R的极客理想系列文章,涵盖了R的思想,使用,工具,创新等的一系列要点,以我个人的学习和体验去诠释R的强大. R语言作为统计学一门语言,一直在小众领域闪耀着光芒.直到大数据 ...
- 电商系统中的商品模型的分析与设计—续
前言 在<电商系统中的商品模型的分析与设计>中,对电商系统商品模型有一个粗浅的描述,后来有博友对货品和商品的区别以及属性有一些疑问.我也对此做一些研究,再次简单的对商品模型做一个介 ...
- Cloudera Hadoop 4 实战课程(Hadoop 2.0、集群界面化管理、电商在线查询+日志离线分析)
课程大纲及内容简介: 每节课约35分钟,共不下40讲 第一章(11讲) ·分布式和传统单机模式 ·Hadoop背景和工作原理 ·Mapreduce工作原理剖析 ·第二代MR--YARN原理剖析 ·Cl ...
随机推荐
- formidable处理文件上传的细节
koa在请求体的处理方面依赖于通用插件koa-bodyparser或者koa-body,前者比较小巧,内部使用了co-body库,可以处理一般的x-www-form-urlencoded格式的请求,但 ...
- 如何简单使用Git
Git基本功能 Git基本功能 在具体介绍Git能做什么之前,先来了解下Git里的四个角色: workspace: 本地的工作空间. index:缓存区域,临时保存本地改动. local reposi ...
- PHP实现JWT登录鉴权
一.什么是JWT 1.简介 JWT(JSON Web Token)是为了在网络应用环境间传递声明而执行的一种基于JSON的开放标准. 简单的说,JWT就是一种Token的编码算法,服务器端负责根据一个 ...
- manjaro安装后配置与美化
时间同步 sudo timedatectl set-ntp true 换源 sudo pacman-mirrors -i -c China -m rank 更新 更新系统 sudo pacman -S ...
- SDN实验1
(一)基本要求 使用Mininet可视化工具,生成下图所示的拓扑,并保存拓扑文件名为学号.py. 使用Mininet的命令行生成如下拓扑: a) 3台交换机,每个交换机连接1台主机,3台交换机连接成一 ...
- swftools工具将pdf文件转换为swf文件 文字丢失
开发客户网站时遇到了一个需求,客户要求后台上传pdf文件,前台能以翻书的形式直接访问. 首先想到的是使用js解决,用户访问前端页面时,php将文件路径发送给js,让js呈现出来翻书的效果.在网上百度了 ...
- 使用Sales_data 类
添加两个Sales_data 对象 因为Sales_data 类没有提供任何操作,所以我们必须自己编码实现输入.输出和相加的功能.假设已知Sales_data 类定义于 Sales_data.h 文件 ...
- ansible介绍与简单的使用
在roles下建立site.yml文件#site.yml - hosts: webservers remote_user: root roles: - websrvs - dbsrvs#将文件拷贝到f ...
- 制作mnist格式数据集
import os from PIL import Image from array import * from random import shuffle # # 文件组织架构: # ├──trai ...
- 【VUE】关于pinia代替vuex
官方文档:https://pinia.web3doc.top/ 知乎讲解:https://zhuanlan.zhihu.com/p/533233367