zookeeper要点总结
简述:zookeeper分布式协调服务,节点数据存储在内存,高吞吐,低延时,zkserver cluster组建zookeeper service保证自身高可用
zookeeper数据模型为类文件目录树结构的文件系统,node节点可以存放1m数据(主要用于存储同步数据及节点元数据,注:数据存储在内存,log存储于磁盘)
角色组成:
- Leader:负责zxid维护,数据同步,与follower之间消息队列维护
- Follower:接受client请求,负责写请求转到leader数据的读取
- Observer:监控指定节点数据变化
数据模型:
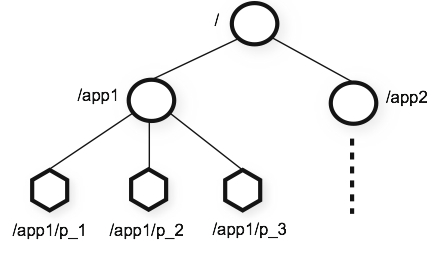
zookeeper节点类型:
- 持久节点:(persistent):client默认创建的znode节点,都是持久节点
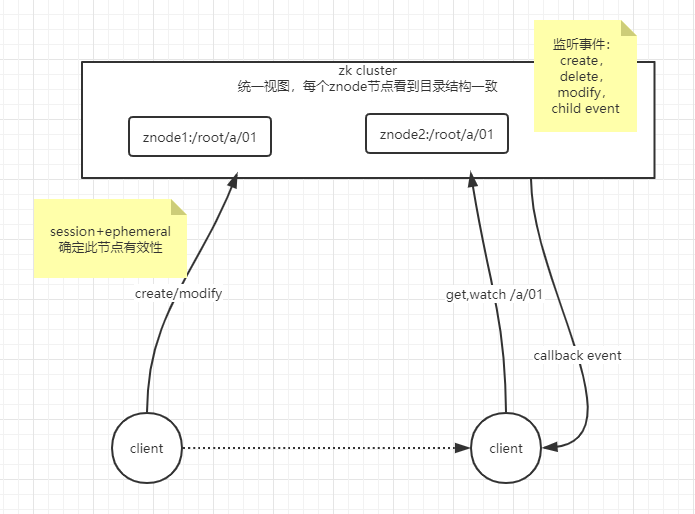
- 临时节点(Ephemeral Nodes):client与zookeeper保持连接时有效,断开znode节点消失。用于session,session结束节点删除,此节点不能有子节点
- 顺序节点(Sequence Nodes):可以是临时也可以是持久的。zookeeper维护一个计数器,保证在相同父节点下,节点的唯一性,注:计数器使用4bytes的int存储下一个节点序号
zookeeper特征/保证:
- 顺序一致性:按client发送过来顺序对数据进行更新
- 原子性:数据更新只有失败和成功两种状态,没有其它结果
- 相同的视图:client无论连接到哪个server,client都将看到相同的视图
- 可靠性:一旦数据更新,从更新的那个时刻一直延续到下一次覆盖更新
- 及时性:clint的视图保证在特定时间内,client看到的视图是最新的
zookeeper角色关联:
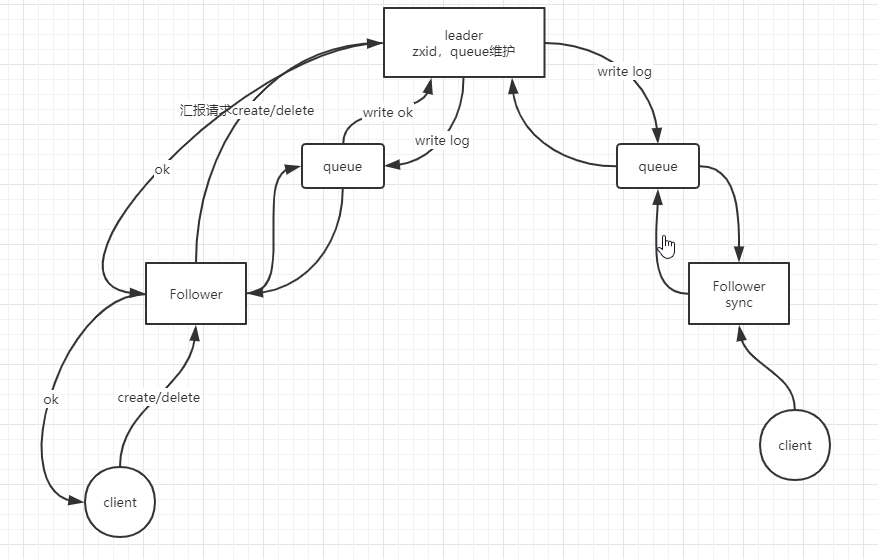
注:当leader挂掉,没有新的leader时则zookeeper拒绝对外服务
zookeeper会话(session):
client与server建立连接zookeeper会分配id,client在特定时间间隔内发送心跳到server保持session有效,如果指定时间未收到心跳,则认为client无效,session中创建的ephemeral节点会被删除
zookeeper监控(Watch):
client在读取特定的节点上设置watch,当此节点发生变化时,会向注册watch的client发送通知。注:这里指触发一次,如client想再次获取通知,则必须通过另一个读取操作来完成,client断开则watch也被删除
zookeeper应用:
1,HA,主的选举:
2,分布式锁:ephemeral特点
zookeeper要点总结的更多相关文章
- 《OD学hadoop》第三周0710
一.分布式集群安装1. Hadoop模式本地模式.伪分布模式.集群模式datanode 使用的机器上的磁盘,存储空间nodemanager使用的机器上的内存和CPU(计算和分析数据) 2. 搭建环境准 ...
- ZooKeeper架构设计及其应用要点
问题导读: 1.ZooKeeper的数据模型是什么 ?2.ZooKeeper应用有哪些陷阱 ?3.每个节点(ZNode)中存储的是什么?4.一个ZNode维护了一个状态结构都包含了什么?5.ZNode ...
- Zookeeper配置要点必看
注意点 zookeeper需要在各个节点的机器上搭建,它的启动也要在各个节点的$ZOOKEEPER_HOME/bin 下启动. 环境搭建 下载安装包并解压. 在$ZOOKEEPER_HOME/conf ...
- 架构设计:远程调用服务架构设计及zookeeper技术详解(下篇)
一.下篇开头的废话 终于开写下篇了,这也是我写远程调用框架的第三篇文章,前两篇都被博客园作为[编辑推荐]的文章,很兴奋哦,嘿嘿~~~~,本人是个很臭美的人,一定得要截图为证: 今天是2014年的第一天 ...
- 搭建zookeeper集群
简介: Zookeeper 分布式服务框架是 Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务.状态同步服务.集群管理.分布式应用配置 ...
- zookeeper集群
0,Zookeeper基本原理 ZooKeeper集群由一组Server节点组成,这一组Server节点中存在一个角色为Leader的节点,其他节点都为Follower.当客户端Client连接到Zo ...
- 转载:ZooKeeper Programmer's Guide(中文翻译)
本文是为想要创建使用ZooKeeper协调服务优势的分布式应用的开发者准备的.本文包含理论信息和实践信息. 本指南的前四节对各种ZooKeeper概念进行较高层次的讨论.这些概念对于理解ZooKeep ...
- ZooKeeper程序员指南(转)
译自http://zookeeper.apache.org/doc/trunk/zookeeperProgrammers.html 1 简介 本文是为想要创建使用ZooKeeper协调服务优势的分布式 ...
- zookeeper 用法和日常运维
本文以ZooKeeper3.4.3版本的官方指南为基础:http://zookeeper.apache.org/doc/r3.4.3/zookeeperAdmin.html,补充一些作者运维实践中的要 ...
- 分布式中,zookeeper的部署
一:准备 1.概述 为分布式应用提供协调服务的项目 类似于文件系统那样的树形数据结构 目的:将分布式服务不再由于协作冲突而另外实现协作服务 2.数据结构 树形数据结构 zookeeper的每个节点都是 ...
随机推荐
- @ApiImplicitParams注解的详细使用
一.@ApiImplicitParams注解的详细使用 业务需求: 1.根据服务员类别id(单个id)+服务员星级id(id的list)查询对应的服务员列表 1.controller代码: 点击查看代 ...
- python画社交网络图
安装依赖包 pip3 install networkx 在图书馆的检索系统中,关于图书的信息里面有一个是图书相关借阅关系图.跟这个社交网络图是一样的,反映了不同对象间的关联性.利用python画社交网 ...
- Safari浏览器对SVG中的<foreignObject>标签支持不友好,渲染容易错位
在 svg 中需要写一个 markdown 编辑器,需要用到 <foreignObject> 绘制来html,编辑器选择了 simplemde.大致html部分结构如下,<markd ...
- [编程基础] C和C++内置宏说明
文章目录 1 内置的宏定义 2 运行平台宏 3 编译器宏 4 调试类型宏 5 代码 C和C++内置宏在代码调试.跨系统平台代码中会经常使用,本文记录说明一下.内置宏不需要调用头文件,可直接使用.在使用 ...
- Svelte框架实现表格协同文档
首先,从框架搭建上,本篇示例采用当下流行的前后端分离的开发方式,前端使用npm作为脚手架搭建Svelte框架. 后端使用Java的SpringBoot作为后端框架. 首先,介绍下在前端Svelte框架 ...
- Ubuntu desktop 文件的书写格式
首先切换到存放 desktop 文件的目录下,编辑好就可以保存了 cd /usr/share/applications/ vim name.desktop [Desktop Entry] Name=显 ...
- 最新编程语言排名Python、C、Java 和 C++ 已形成四足鼎立之势
引言 技术的千变万化,都是有迹可循的,随着最新的 TIOBE 十月编程语言榜单重磅发布,不同开发语言的排名和发展趋势也随之揭晓! 四大编程语言不断增强其主导地位 曾几何时,编程语言界中 Java.C. ...
- Java 进阶P-8.1+P-8.2
捕捉异常 异常的处理方式之一:捕获异常 捕获异常是通过3个关键词来实现的:try-catch-finally.用try来执行一段程序,如果出现异常,系统抛出一个异常,可以通过它的类型来捕捉(catch ...
- Node.js+Koa2+TypeScript技术概览
最近几年一直使用Node.js作为后端服务平台,通过Koa2框架中间件快速搭建Web服务,但是使用JavaScript开发大型后端服务时会使程序变得难以维护,继而使用TypeScript语言开发,使编 ...
- 【随笔记】Android 命令行联网、更新DNS、同步网络时间
一.命令行联网 # 启用网卡 busybox ifconfig wlan0 up # 启用服务 wpa_supplicant -iwlan0 -Dnl80211 -c/system/etc/wifi/ ...