学python,怎么能不学习scrapy呢!
摘要:本文讲述如何编写scrapy爬虫。
本文分享自华为云社区《学python,怎么能不学习scrapy呢,这篇博客带你学会它》,作者: 梦想橡皮擦 。
在正式编写爬虫案例前,先对 scrapy 进行一下系统的学习。
scrapy 安装与简单运行
使用命令 pip install scrapy 进行安装,成功之后,还需要随手收藏几个网址,以便于后续学习使用。
- scrapy 官网:https://scrapy.org;
- scrapy 文档:https://doc.scrapy.org/en/latest/intro/tutorial.html;
- scrapy 更新日志:https://docs.scrapy.org/en/latest/news.html。
安装完毕之后,在控制台直接输入 scrapy,出现如下命令表示安装成功。
> scrapy
Scrapy 2.5.0 - no active project
Usage:
scrapy <command> [options] [args]
Available commands:
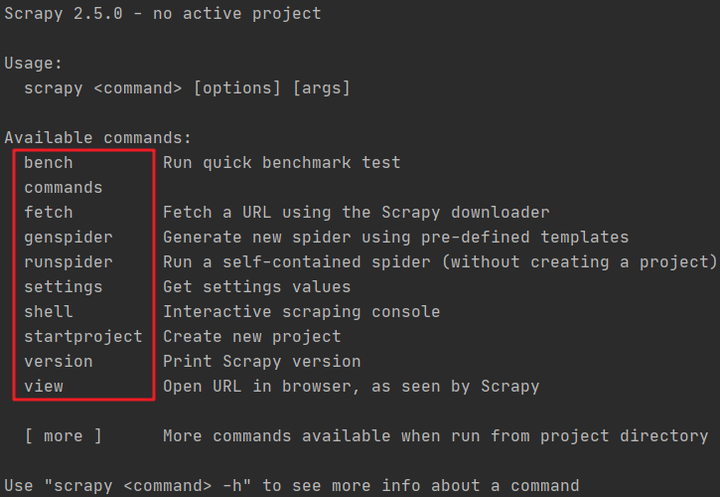
上述截图是 scrapy 的内置命令列表,标准的格式的 scrapy <command> <options> <args>,通过 scrapy <command> -h 可以查看指定命令的帮助手册。
scrapy 中提供两种类型的命令,一种是全局的,一种的项目中的,后者需要进入到 scrapy 目录才可运行。
这些命令无需一开始就完全记住,随时可查,有几个比较常用,例如:
**scrpy startproject <项目名> **
该命令先依据 项目名 创建一个文件夹,然后再文件夹下创建于个 scrpy 项目,这一步是后续所有代码的起点。
> scrapy startproject my_scrapy
> New Scrapy project 'my_scrapy', using template directory 'e:\pythonproject\venv\lib\site-packages\scrapy\templates\project', created in: # 一个新的 scrapy 项目被创建了,使用的模板是 XXX,创建的位置是 XXX
E:\pythonProject\滚雪球学Python第4轮\my_scrapy
You can start your first spider with: # 开启你的第一个爬虫程序
cd my_scrapy # 进入文件夹
scrapy genspider example example.com # 使用项目命令创建爬虫文件
上述内容增加了一些注释,可以比对着进行学习,默认生成的文件在 python 运行时目录,如果想修改项目目录,请使用如下格式命令:
scrapy startproject myproject [project_dir]
例如
scrapy startproject myproject d:/d1
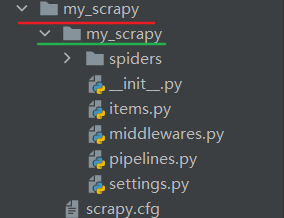
命令依据模板创建出来的项目结构如下所示,其中红色下划线的是项目目录,而绿色下划线才是 scrapy 项目,如果想要运行项目命令,则必须先进入红色下划线 my_scrapy 文件夹,在项目目录中才能控制项目。
下面生成一个爬虫文件
使用命令 scrapy genspider [-t template] <name> <domain> 生成爬虫文件,该方式是一种快捷操作,也可以完全手动创建。创建的爬虫文件会出现在 当前目录或者项目文件夹中的 spiders 文件夹中,name 是爬虫名字,domain 用在爬虫文件中的 alowed_domains 和 start_urls 数据中,[-t template] 表示可以选择生成文件模板。
查看所有模板使用如下命令,默认模板是 basic。
> scrapy genspider -l
basic
crawl
csvfeed
xmlfeed
创建第一个 scrapy 爬虫文件,测试命令如下:
>scrapy genspider pm imspm.com
Created spider 'pm' using template 'basic' in module:
my_project.spiders.pm
此时在 spiders 文件夹中,出现 pm.py 文件,该文件内容如下所示:
import scrapy
class PmSpider(scrapy.Spider):
name = 'pm'
allowed_domains = ['imspm.com']
start_urls = ['http://imspm.com/']
def parse(self, response):
pass
测试 scrapy 爬虫运行
使用命令 scrapy crawl <spider>,spider 是上文生成的爬虫文件名,出现如下内容,表示爬虫正确加载。
>scrapy crawl pm
2021-10-02 21:34:34 [scrapy.utils.log] INFO: Scrapy 2.5.0 started (bot: my_project)
[...]
scrapy 基本应用
scrapy 工作流程非常简单:
- 采集第一页网页源码;
- 解析第一页源码,并获取下一页链接;
- 请求下一页网页源码;
- 解析源码,并获取下一页源码;
- […]
- 过程当中,提取到目标数据之后,就进行保存。
接下来为大家演示 scrapy 一个完整的案例应用,作为 爬虫 120 例 scrapy 部分的第一例。
> scrapy startproject my_project 爬虫
> cd 爬虫
> scrapy genspider pm imspm.com
获得项目结构如下:
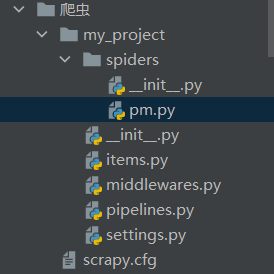
上图中一些文件的简单说明。
- scrapy.cfg:配置文件路径与部署配置;
- items.py:目标数据的结构;
- middlewares.py:中间件文件;
- pipelines.py:管道文件;
- settings.py:配置信息。
使用 scrapy crawl pm 运行爬虫之后,所有输出内容与说明如下所示:
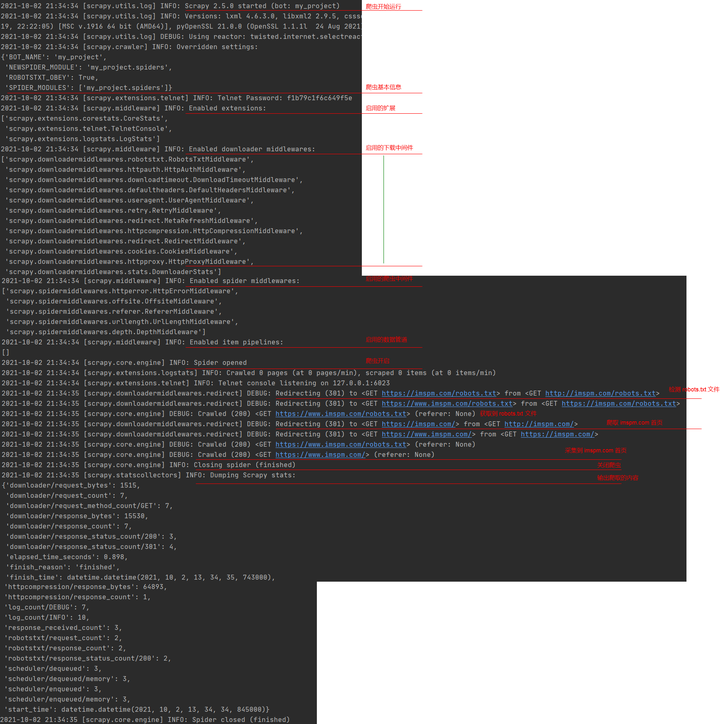
上述代码请求次数为 7 次,原因是在 pm.py 文件中默认没有添加 www,如果增加该内容之后,请求次数变为 4。

现在的 pm.py 文件代码如下所示:
import scrapy
class PmSpider(scrapy.Spider):
name = 'pm'
allowed_domains = ['www.imspm.com']
start_urls = ['http://www.imspm.com/']
def parse(self, response):
print(response.text)
其中的 parse 表示请求 start_urls 中的地址,获取响应之后的回调函数,直接通过参数 response 的 .text 属性进行网页源码的输出。
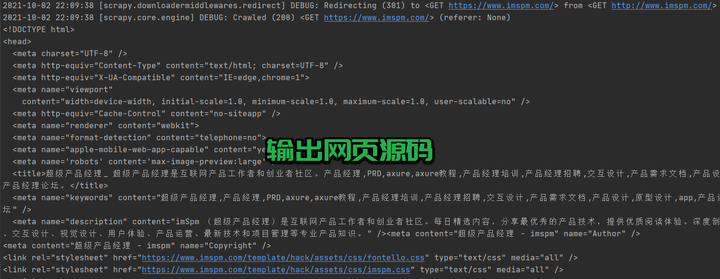
获取到源码之后,要对源码进行解析与存储
在存储之前,需要手动定义一个数据结构,该内容在 items.py 文件实现,对代码中的类名进行了修改,MyProjectItem → ArticleItem。
import scrapy
class ArticleItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field() # 文章标题
url = scrapy.Field() # 文章地址
author = scrapy.Field() # 作者
修改 pm.py 文件中的 parse 函数,增加网页解析相关操作,该操作类似 pyquery 知识点,直接观察代码即可掌握。
def parse(self, response):
# print(response.text)
list_item = response.css('.list-item-default')
# print(list_item)
for item in list_item:
title = item.css('.title::text').extract_first() # 直接获取文本
url = item.css('.a_block::attr(href)').extract_first() # 获取属性值
author = item.css('.author::text').extract_first() # 直接获取文本
print(title, url, author)
其中 response.css 方法返回的是一个选择器列表,可以迭代该列表,然后对其中的对象调用 css 方法。
- item.css('.title::text'),获取标签内文本;
- item.css('.a_block::attr(href)'),获取标签属性值;
- extract_first():解析列表第一项;
- extract():获取列表。
在 pm.py 中导入 items.py 中的 ArticleItem 类,然后按照下述代码进行修改:
def parse(self, response):
# print(response.text)
list_item = response.css('.list-item-default')
# print(list_item)
for i in list_item:
item = ArticleItem()
title = i.css('.title::text').extract_first() # 直接获取文本
url = i.css('.a_block::attr(href)').extract_first() # 获取属性值
author = i.css('.author::text').extract_first() # 直接获取文本
# print(title, url, author)
# 对 item 进行赋值
item['title'] = title
item['url'] = url
item['author'] = author
yield item
此时在运行 scrapy 爬虫,就会出现如下提示信息。
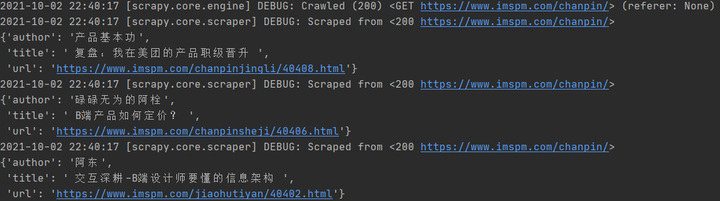
此时完成了一个单页爬虫
接下来对 parse 函数再次改造,使其在解析完第 1 页之后,可以解析第 2 页数据。
def parse(self, response):
# print(response.text)
list_item = response.css('.list-item-default')
# print(list_item)
for i in list_item:
item = ArticleItem()
title = i.css('.title::text').extract_first() # 直接获取文本
url = i.css('.a_block::attr(href)').extract_first() # 获取属性值
author = i.css('.author::text').extract_first() # 直接获取文本
# print(title, url, author)
# 对 item 进行赋值
item['title'] = title
item['url'] = url
item['author'] = author
yield item
next = response.css('.nav a:nth-last-child(2)::attr(href)').extract_first() # 获取下一页链接
# print(next)
# 再次生成一个请求
yield scrapy.Request(url=next, callback=self.parse)
上述代码中,变量 next 表示下一页地址,通过 response.css 函数获取链接,其中的 css 选择器请重点学习。
yield scrapy.Request(url=next, callback=self.parse) 表示再次创建一个请求,并且该请求的回调函数是 parse 本身,代码运行效果如下所示。

如果想要保存运行结果,运行下面的命令即可。
scrapy crawl pm -o pm.json
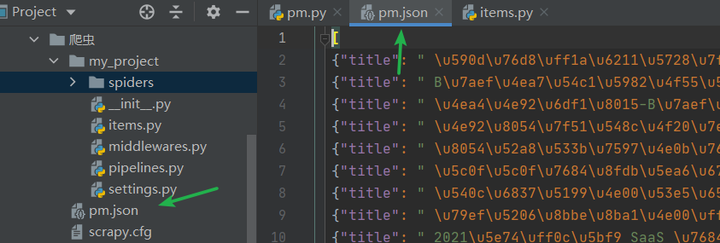
如果想要将每条数据存储为单独一行,使用如下命令即可 scrapy crawl pm -o pm.jl 。
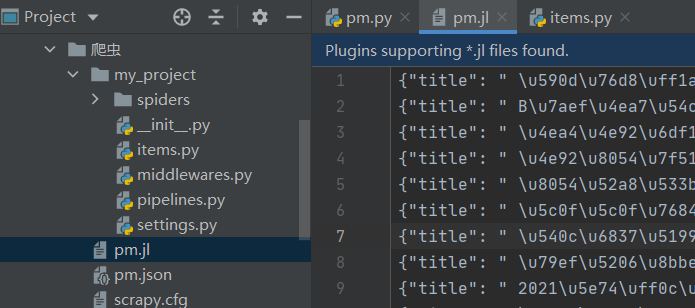
生成的文件还支持 csv 、 xml、marchal、pickle ,可自行尝试。
下面将数据管道利用起来
打开 pipelines.py 文件,修改类名 MyProjectPipeline → TitlePipeline,然后编入如下代码:
class TitlePipeline:
def process_item(self, item, spider): # 移除标题中的空格
if item["title"]:
item["title"] = item["title"].strip()
return item
else:
return DropItem("异常数据")
该代码用于移除标题中的左右空格。
编写完毕,需要在 settings.py 文件中开启 ITEM_PIPELINES 配置。
ITEM_PIPELINES = {
'my_project.pipelines.TitlePipeline': 300,
}
300 是 PIPELINES 运行的优先级顺序,根据需要修改即可。再次运行爬虫代码,会发现标题的左右空格已经被移除。
到此 scrapy 的一个基本爬虫已经编写完毕。
学python,怎么能不学习scrapy呢!的更多相关文章
- 【我要学python】面向对象系统学习
第一节:初识类的定义和调用 c1.py #类 = 面向对象 #类 最基本作用:封装 #类中不仅可以定义变量 还可以定义函数等等,例: class student( ): name = ' ' age ...
- 零基础学Python不迷茫——基本学习路线及教程!
什么是Python? 在过去的2018年里,Python成功的证明了它自己有多火,它那“简洁”与明了的语言成功的吸引了大批程序员与大数据应用这的注意,的确,它的实用性的确是配的上它的热度. Pyt ...
- 学Python的第五天
最近忙着学MySQL,但是小编也不会放弃学Python!!! 因为热爱所以学习~ 好了各位,进入正题,由于时间问题今天学的不是很多.... #!/usr/bin/env python # -*- co ...
- python初学者必看学习路线图!!!
python应该是近几年比较火的语言之一,很多人刚学python不知道该如何学习,尤其是没有编程基础想要从事程序员工作的小白,想必应该都会有此疑惑,包括我刚学python的时候也是通过从网上查找相关资 ...
- 怎么快速学python?酒店女服务员一周内学会Python,一年后成为程序员
怎么快速学python?有人说,太难!但这个女生却在一个星期内入门Python,一个月掌握python所有的基础知识点. 说出来你应该不信,刚大学毕业的女生:琳,一边在酒店打工,一边自学python, ...
- 小白学 Python 爬虫(33):爬虫框架 Scrapy 入门基础(一)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 他学习一年Python找不到工作,大佬都说你别再学Python了!
引言: 都说,滴水穿石非一日之功.然而有些人即使奋斗一辈子也比不上别人一年,别人学习一年比不得你学习一个月.其中缘由,有些人看了大半辈子还没看明白. 即使Python这么火,为何你学习一年的Pytho ...
- 小白学 Python 爬虫(34):爬虫框架 Scrapy 入门基础(二)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(35):爬虫框架 Scrapy 入门基础(三) Selector 选择器
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
随机推荐
- spring boot 集成 rabbitmq 指南
先决条件 rabbitmq server 安装参考 一个添加了 web 依赖的 spring boot 项目 我的版本是 2.5.2 添加 maven 依赖 <dependency> &l ...
- SM3和Blake
在此给出SM3和Blake的对比 哈希函数 哈希算法 (Hash Algorithm) 是将任意长度的数据映射为固定长度数据的算法,也称为消息摘要.一般情况下,哈希算法有两个特点, 一是原始数据的细微 ...
- 设置VisualStudio以管理员身份运行
以vs2013为例 vs右键属性 ----- 找到目标位置如下 "C:\Program Files (x86)\Microsoft Visual Studio 12.0\Common7\ID ...
- unity---监听物体被点击
脚本 public void OnPointerClick(PointerEventData eventData) { Debug.LogFormat("{0} is Click" ...
- 项目下载依赖后面加 -S -D -g 分别代表什么意思
npm install name -S此依赖是在package的dependencies中,不仅在开发中,也在打包上线后的生产环境中,比如vue npm install name -D此依赖是在pac ...
- 如何让 Windows 把 TypeScript 文件当作文本文件
TL;DR 修改注册表项 HKEY_CLASSES_ROOT\.ts 为 HKEY_CLASSES_ROOT\.txt 的值 起因 Windows10 总把 TypeScript 文件自动当成视频,放 ...
- 深度学习与CV教程(2) | 图像分类与机器学习基础
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/37 本文地址:http://www.showmeai.tech/article-det ...
- 一文带你搞懂 JWT 常见概念 & 优缺点
在 JWT 基本概念详解这篇文章中,我介绍了: 什么是 JWT? JWT 由哪些部分组成? 如何基于 JWT 进行身份验证? JWT 如何防止 Token 被篡改? 如何加强 JWT 的安全性? 这篇 ...
- VMware 安装 Anolis OS
安装时参考的以下文章 VMware Workstation Pro 虚拟机安装 VMware Workstation Pro 安装 龙蜥操作系统(Anolis OS) Anolis OS 8 安装指南 ...
- Elasticsearch学习系列一(部署和配置IK分词器)
Elasticsearch简介 Elasticsearch是什么? Elaticsearch简称为ES,是一个开源的可扩展的分布式的全文检索引擎,它可以近乎实时的存储.检索数据.本身扩展性很好,可扩展 ...