Redis设计实现-学习笔记
最近在准备面试,问到redis相关知识,只能说个皮毛,说的既不深入也不全面,所以抓紧突击一下,先学《redis设计与实现》。
选择看书的原因是:
书中全面深入,且能出书一定十分用心;
搜博客也找不到比书更全面的文章,且费时;
直接看源码一个是对C掌握不好,且易困,效率不高,所以跟着书同步学源码,是我认为现在最好的选择。
一:五种常用数据类型
简单动态字符串
redis做了一个用作字符串的SDS,除了一些不需要修改的场景,都是用SDS
C字符串的底层实现总是一 个N+1个字符长的数组
sds.h:
struct sdshdr {
// buf 中已占用空间的长度
int len;
// buf 中剩余可用空间的长度
int free;
// 数据空间
char buf[];
};
| 1 | C字符串 | SDS |
| 2 | 求长度,需要遍历O(n) | 直接取len就可以O(1) |
| 3 | 容易造成缓冲区溢出 | |
| 4 |
减少了内存重新分配次数 (速度要求严苛,避免分配内存耗时多) |
|
| 5 | 二进制安全 |
4:SDS有free,可以比C字符串多一些预留空间。空间优化策略主要有两种:
- 空间预分配
- SDS进行修改时,会额外获得未使用空间。
- 修改后空间n
- n<1M;free分配n+1byte(空字符)
- n>=1M;free分配1M+1byte
- 惰性空间释放
- SDS进行缩短时,不释放删除的空间,加到free里。
SDS的API
- sdsnew 创建
- sdsempty 创建空的SDS
- sdsfree 释放
- sdslen 获取len
- sdsvail 获取free数量
- sdsdup 创建一个sds副本
- 。。
链表
redis自己构建的链表:
/*
* 双端链表节点
*/
typedef struct listNode { // 前置节点
struct listNode *prev; // 后置节点
struct listNode *next; // 节点的值
void *value; } listNode;
/*
* 双端链表迭代器
*/
typedef struct listIter { // 当前迭代到的节点
listNode *next; // 迭代的方向
int direction; } listIter;
/*
* 双端链表结构
*/
typedef struct list { // 表头节点
listNode *head; // 表尾节点
listNode *tail; // 节点值复制函数
void *(*dup)(void *ptr); // 节点值释放函数
void (*free)(void *ptr); // 节点值对比函数
int (*match)(void *ptr, void *key); // 链表所包含的节点数量
unsigned long len; } list;
字典
也叫:符号表、关联数组、映射,用于保存键值对;
/*
* 字典
*/
typedef struct dict { // 类型特定函数
dictType *type; // 私有数据
void *privdata; // 哈希表
dictht ht[2]; // rehash 索引
// 当 rehash 不在进行时,值为 -1
int rehashidx; /* rehashing not in progress if rehashidx == -1 */ // 目前正在运行的安全迭代器的数量
int iterators; /* number of iterators currently running */ } dict;
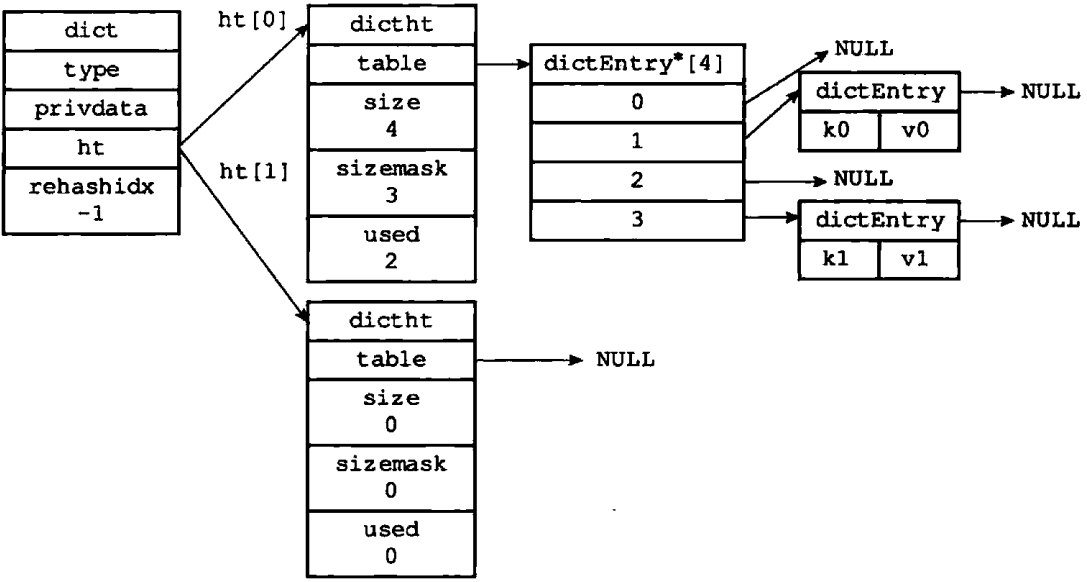
理解:
- 字典dict;
- 属性type是指向dictType的;dictType是保存特定类型键值对的函数;redis会为不同的字典设置不同的函数。
- 属性privateData是存储对应类型的可选参数。
- ht是指向dictht的引用;
- 其中table是指向dictEntry的二维引用,有两级。
- 第一级是hash后的值,到阈值就要rehash扩缩容
- dictEntry是哈希节点
- key是键
- value是值
- 还有指向下一个节点的引用next,用于成链。
hash算法
冲突解决
哈希表使用链地址法来解决键冲突:
哈希表节点dictEntry的指针构成一个链,hash相同的就排在当前dictEntry的next
rehash
1.为ht[1]分配空间,与ht[0]比较,扩容则分配
// 新哈希表的大小至少是目前已使用节点数的两倍
// T = O(N)
return dictExpand(d, d->ht[0].used*2);
收缩则分配大小等于ht[0]的?
/*
* 缩小给定字典
* 让它的已用节点数和字典大小之间的比率接近 1:1
* 返回 DICT_ERR 表示字典已经在 rehash ,或者 dict_can_resize 为假。
* 成功创建体积更小的 ht[1] ,可以开始 resize 时,返回 DICT_OK。
*/
int dictResize(dict *d)
{
int minimal;
// 不能在关闭 rehash 或者正在 rehash 的时候调用
if (!dict_can_resize || dictIsRehashing(d)) return DICT_ERR;
// 计算让比率接近 1:1 所需要的最少节点数量
minimal = d->ht[0].used;
if (minimal < DICT_HT_INITIAL_SIZE)
minimal = DICT_HT_INITIAL_SIZE;
// 调整字典的大小
// T = O(N)
return dictExpand(d, minimal);
}
2.把ht[0]复制并重新hash计算到ht[1]上
3.把ht[0]释放,ht[1]设置为ht[0]。
hash表的扩容与收缩
哈希表会自动在表的大小的二次方之间进行调整。
在没有bgSave或bgRewriteAOF命令时,负载因子大于1;或者有bgSave或bgRewriteAOF命令时,负载因子大于5;时执行
负载因子= 已保存/哈希表大小
渐进式rehash
跳跃表
skipList
命令:
ZRANGE
ZCARD
有序,按value值排序?
平均O(logN)复杂度
适用于有序集合元素较多或集合中元素是较长字符串等场景。
具体应用:
- 实现有序集合键
- 在集群节点中用作内部数据结构
/*
* 跳跃表
*/
typedef struct zskiplist { // 表头节点和表尾节点
struct zskiplistNode *header, *tail; // 表中节点的数量
unsigned long length; // 表中层数最大的节点的层数
int level; } zskiplist;
和
/*
* 跳跃表节点
*/
typedef struct zskiplistNode {
// 成员对象
robj *obj;
// 分值
double score;
// 后退指针
struct zskiplistNode *backward;
// 层
struct zskiplistLevel {
// 前进指针
struct zskiplistNode *forward;
// 跨度
unsigned int span;
} level[];
} zskiplistNode;
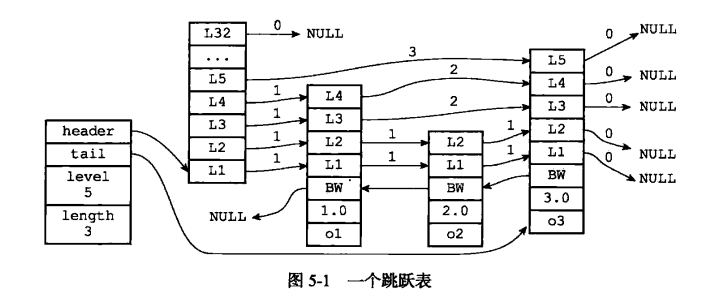
理解:
- 跳表zskipList;
- 属性header和tail分别指向zskiplistNode的头尾指针。
- zskiplistNode
- 层
- 后退
- 分支
- 成员对象
- zskiplistNode
- level记录层数最大的层数
- 属性header和tail分别指向zskiplistNode的头尾指针。
整数集合
命令:
SADD numbers 1 3 5 7 9
typedef struct intset {
// 编码方式
uint32_t encoding;
// 集合包含的元素数量
uint32_t length;
// 保存元素的数组
int8_t contents[];
} intset;
uint32_t 取值范围 0 ~ 4,294,967,295int8_t 取值范围 -128 ~ 127
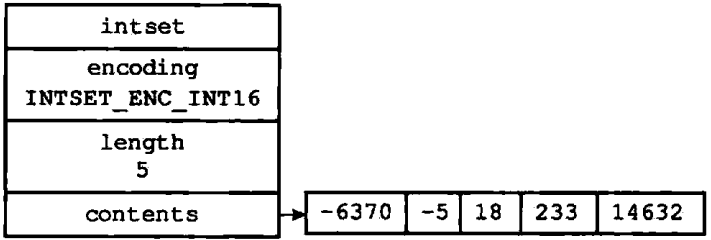
contents中的值从小到大排列,并且没有重复元素。
整数集合升级过程:
- 根据新元素的类型,扩展数组空间,为新元素分配空间。
- 将已有的数据转换成相同类型,保持排序。
- 将新元素加到新数组里。
升级之后不支持降级,即使没有当前等级的元素。
压缩表
zipList 是列表键和hash键的底层实现之一。
RPUSH lst 1 3 5 10086 "hello" "world"
对象
- 字符串对象
- 列表对象
- 哈希对象
- 集合对象
- 有序集合对象
每种对象都最少对应上述一种数据类型
不同的对象有不同的特性~(省略)。
二:单机
数据库
struct redisServer{
// ~
// 一个数组保存,保存服务器中所有数据库
redisDb *db;
// ~
//根据此数量决定在初始化时创建数据库个数
int dbnum;
} intset;

通过SELECT n 可以切换到不同的库
//TODO
原理
保存键值对的方法
过期键删除策略
- 定时删除
- 设置过期时间的同时,创建一个定时器,定时器到时间执行对键的删除操作。 --- 定时器是怎么实现的??
- 惰性删除
- 放任过期时间不管,但是每次从键空间中获取键时,都检查取得的键是否过期。过期删除,没过期返回。--这个存在空间的浪费
- 定期删除
- 每隔一段时间,对数据库进行一次检查,删除过期key。检查力度由算法决定。
1.定时删除 对内存最友好 对CPU时间不友好
CPU紧张时,影响服务器的响应时间和吞吐量。
实现定时器,需要用到redis服务器中的时间事件,当前时间事件的实现方式是:无序链表,查找效率为O(N),效率较低。
现阶段来说不实用。
2.惰性删除 对CPU时间友好 对内存不友好
浪费内存,由内存泄漏的危险
3.定期删除
前两种的整合
每个一段时间执行一次删除过期键,减少内存浪费
删除太频繁或执行时间长,会退化成定时删除,节约CPU
所以这个要合理配置。
redis的过期键删除策略
惰性删除 + 定期删除
持久化机制
aof 和 rdb
事件、redis初始化过程等其他
三:分布式
Sentinel
复制
集群
四:独立功能
发布订阅
事务
Lua脚本
redis2.6引入Lua脚本
在redis客户端可以直接使用Lua脚本
redis> EVAL "return 'hello world'" 0
"hello world"
Lua环境初始化(对Lua环境进行修改产生的影响)
执行Lua脚本中包含redis命令的伪客户端
Lua脚本的脚本字典
管理脚本的命令SCRIPT FLUSH、SCRIPT EXISTS、SCRIPT LOAD、SCRIPT KILL
EVAL命令和EVALSHA命令
排序 SORT
Sort可以对int或者字符等进行排序
还可以使用 SORT ~ BY ~ 以什么字段为权重排序
sort命令的最简单的执行形式为 SORT <key>
redis> SORT numbsers
1)"1"
2)"2"
3)"3"
命令的详细步骤:
1.创建一个和numbsers列表长度相同的数组,数组的每一项都是redisSortObject结构
2.遍历数组,将Obj指针和列表之间一一对应
3.遍历数组,将obj指向的列表转换成double浮点数,放到u.score里
4.根据u.score属性从小到大排列
5.遍历数组,返回排序结果。
慢查询
redis分布式锁
https://www.cnblogs.com/jiangym/p/15877382.html#_label1_1
redisson
//todo
Redis设计实现-学习笔记的更多相关文章
- redis 安装配置学习笔记
redis 安装配置学习笔记 //wget http://download.redis.io/releases/redis-2.8.17.tar.gz 下载最新版本 wget http://downl ...
- Redis集群学习笔记
Redis集群学习笔记 前言 最近有个需求,就是将一个Redis集群中数据转移到某个单机Redis上. 迁移Redis数据的话,如果是单机Redis,有两种方式: a. 执行redis-cli shu ...
- 【Redis】命令学习笔记——列表(list)+集合(set)+有序集合(sorted set)(17+15+20个超全字典版)
本篇基于redis 4.0.11版本,学习列表(list)和集合(set)和有序集合(sorted set)相关命令. 列表按照插入顺序排序,可重复,可以添加一个元素到列表的头部(左边)或者尾部(右边 ...
- 【Redis】命令学习笔记——哈希(hash)(15个超全字典版)
本篇基于redis 4.0.11版本,学习哈希(hash)相关命令. hash 是一个string类型的field和value的映射表,特别适合用于存储对象. 序号 命令 描述 实例 返回 HSET ...
- 【Redis】命令学习笔记——字符串(String)(23个超全字典版)
Redis支持五种数据类型:string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合). 本篇基于redis 4.0.11版本,学习字符串( ...
- 【Redis】命令学习笔记——键(key)(20个超全字典版)
安装完redis和redis-desktop-manager后,开始学习命令啦!本篇基于redis 4.0.11版本,从对键(key)开始挖坑! 准备工作,使用db1(默认db0,由于之前练习用db0 ...
- Redis入门指南(第2版) Redis设计思路学习与总结
https://www.qcloud.com/community/article/222 宋增宽,腾讯工程师,16年毕业加入腾讯,从事海量服务后台设计与研发工作,现在负责QQ群后台等项目,喜欢研究技术 ...
- Redis设计思路学习与总结
版权声明:本文由宋增宽原创文章,转载请注明出处: 文章原文链接:https://www.qcloud.com/community/article/222 来源:腾云阁 https://www.qclo ...
- redis相关笔记(三.redis设计与实现(笔记))
redis笔记一 redis笔记二 redis笔记三 1.数据结构 1.1.简单动态字符串: 其属性有int len:长度,int free:空闲长度,char[] bur:字符数组(内容) 获取字符 ...
- redis环境搭建学习笔记
学习环境为windows.java环境 一.学习教程: 1.菜鸟教程:http://www.runoob.com/redis/redis-tutorial.html 2.redis中文网:http:/ ...
随机推荐
- Linux网络第六章:PXE高效批量网络装机及kickstart无人值守安装
目录 一.PXE基础知识 二.PXE使用服务 三.高效批量网络装机实操 1.环境准备 2.配置dhcpd服务 3.配置FTP服务 4.配置TFTP服务 5.配置kickstart无人值守 6.启动服务 ...
- Linuxt通过命令lsof或者extundelete工具恢复误删除的文件或者目录
Linux不像windows有那么显眼的回收站,不是简单的还原就可以了.linux删除文件还原可以分为两种情况,一种是删除以后在进程存在删除信息,一种是删除以后进程都找不到,只有借助于工具还原.这里分 ...
- 你应该知道的 50 个 Python 单行代码
你应该知道的 50 个 Python 单行代码 1. 字母移位词:猜字母的个数和频次是否相同 2. 二进制转十进制 3. 转换成小写字母 4. 转换成大写字母 5. 字符串转换为字节类型 6. 复制文 ...
- Win7+VS2010 环境配置
最后再次总结一些,Win7下的VS2010总共有三个变量配置: 1. 变量名:path 变量值:D:\Program Files\Microsoft Visual Studio 10.0\VC\bin ...
- Quartz.Net的简单使用
1.安装Quartz.Net Install-Package Quartz -Version 2.5.0 2.需要执行定时任务的代码,新建一个类,继承IJob接口,并实现该接口 public clas ...
- 宝塔部署 vue + thinkphp
部署https://blog.csdn.net/xinxinsky/article/details/105441164?spm=1001.2101.3001.6650.2&utm_medium ...
- (1019) rapidsvn 安装
https://blog.csdn.net/mzpmzk/article/details/106332039
- Java调试排错心得
首先这里没有报错,但是打印了四行相同的数据,还都是最后一行的数据.然后调试了一下 这里是重点: 下面哪里account = {Account@1580}是一直用的一个对象,所有每一次调试那些什么rs. ...
- ES6-Promise下
六.实例的finally方法: promise状态发生变化指的是由初始态变成成功或者失败态 处理错误指的是没有调用catch(失败态实例调用可以执行其回调的then) finally里面的回调函数只要 ...
- linux环境通过nginx转发allure报告
前言: 自动化测试生成的allure报告一般通过jenkins生成,生成后通过jenkins的view账号进行查看,但这样就必须登录jenkins才能看到,如何不通过登录jenkins从而看到al ...