Citus 分布式 PostgreSQL 集群 - SQL Reference(查询分布式表 SQL)
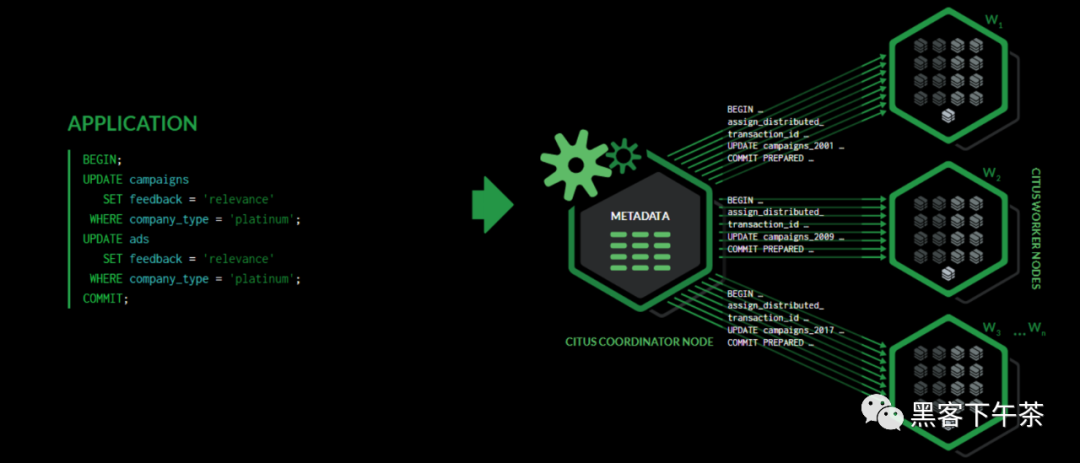
如前几节所述,Citus 是一个扩展,它扩展了最新的 PostgreSQL 以进行分布式执行。这意味着您可以在 Citus 协调器上使用标准 PostgreSQL SELECT 查询进行查询。 Citus 将并行化涉及复杂选择、分组和排序以及 JOIN 的 SELECT 查询,以加快查询性能。在高层次上,Citus 将 SELECT 查询划分为更小的查询片段,将这些查询片段分配给 worker,监督他们的执行,合并他们的结果(如果需要,对它们进行排序),并将最终结果返回给用户。
在以下部分中,我们将讨论您可以使用 Citus 运行的不同类型的查询。
聚合函数
Citus 支持和并行化 PostgreSQL 支持的大多数聚合函数,包括自定义用户定义的聚合。 聚合使用以下三种方法之一执行,优先顺序如下:
当聚合按表的分布列分组时,
Citus可以将整个查询的执行下推到每个worker。 在这种情况下支持所有聚合,并在worker上并行执行。(任何正在使用的自定义聚合都必须安装在worker身上。)当聚合没有按表的分布列分组时,
Citus仍然可以根据具体情况进行优化。Citus对sum()、avg()和count(distinct)等某些聚合有内部规则,允许它重写查询以对worker进行部分聚合。例如,为了计算平均值,Citus从每个worker那里获得一个总和和一个计数,然后coordinator节点计算最终的平均值。特殊情况聚合的完整列表:avg, min, max, sum, count, array_agg, jsonb_agg, jsonb_object_agg, json_agg, json_object_agg, bit_and, bit_or, bool_and, bool_or, every, hll_add_agg, hll_union_agg, topn_add_agg, topn_union_agg, any_value, var_pop(float4), var_pop(float8), var_samp(float4), var_samp(float8), variance(float4), variance(float8) stddev_pop(float4), stddev_pop(float8), stddev_samp(float4), stddev_samp(float8) stddev(float4), stddev(float8) tdigest(double precision, int), tdigest_percentile(double precision, int, double precision), tdigest_percentile(double precision, int, double precision[]), tdigest_percentile(tdigest, double precision), tdigest_percentile(tdigest, double precision[]), tdigest_percentile_of(double precision, int, double precision), tdigest_percentile_of(double precision, int, double precision[]), tdigest_percentile_of(tdigest, double precision), tdigest_percentile_of(tdigest, double precision[])
最后的手段:从
worker中提取所有行并在coordinator节点上执行聚合。 如果聚合未在分布列上分组,并且不是预定义的特殊情况之一,则Citus会退回到这种方法。 它会导致网络开销,并且如果要聚合的数据集太大,可能会耗尽coordinator的资源。(可以禁用此回退,见下文。)
请注意,查询中的微小更改可能会改变执行模式,从而导致潜在的令人惊讶的低效率。例如,按非分布列分组的 sum(x) 可以使用分布式执行,而 sum(distinct x) 必须将整个输入记录集拉到 coordinator。
SELECT sum(value1), sum(distinct value2) FROM distributed_table;
为避免意外将数据拉到 coordinator,可以设置一个 GUC:
SET citus.coordinator_aggregation_strategy TO 'disabled';
请注意,禁用 coordinator 聚合策略将完全阻止 “类型三”(最后的手段) 聚合查询工作。
Count (Distinct) 聚合
Citus 以多种方式支持 count(distinct) 聚合。
如果 count(distinct) 聚合在分布列上,Citus 可以直接将查询下推给 worker。
如果不是,Citus 对每个 worker 运行 select distinct 语句,
并将列表返回给 coordinator,从中获取最终计数。
请注意,当 worker 拥有更多 distinct 项时,传输此数据会变得更慢。
对于包含多个 count(distinct) 聚合的查询尤其如此,例如:
-- multiple distinct counts in one query tend to be slow
SELECT count(distinct a), count(distinct b), count(distinct c)
FROM table_abc;
对于这类查询,worker 上产生的 select distinct 语句本质上会产生要传输到 coordinator 的行的 cross-product(叉积)。
为了提高性能,您可以选择进行近似计数。请按照以下步骤操作:
- 在所有
PostgreSQL实例(coordinator和所有worker)上下载并安装hll扩展。有关获取扩展的详细信息,请访问 PostgreSQL hll github 存储库。 - 只需从
coordinator运行以下命令,即可在所有PostgreSQL实例上创建hll扩展CREATE EXTENSION hll;
- 通过设置
Citus.count_distinct_error_rate配置值启用计数不同的近似值。 此配置设置的较低值预计会提供更准确的结果,但需要更多时间进行计算。我们建议将其设置为0.005。SET citus.count_distinct_error_rate to 0.005;
在这一步之后,
count(distinct)聚合会自动切换到使用HLL,而无需对您的查询进行任何更改。 您应该能够在表的任何列上运行近似count distinct查询。
HyperLogLog 列
某些用户已经将他们的数据存储为 HLL 列。在这种情况下,他们可以通过调用 hll_union_agg(hll_column) 动态汇总这些数据。
估计 Top N 个项
通过应用 count、sort 和 limit 来计算集合中的前 n 个元素很简单。 然而,随着数据大小的增加,这种方法变得缓慢且资源密集。使用近似值更有效。
Postgres 的开源 TopN 扩展可以快速获得 “top-n” 查询的近似结果。该扩展将 top 值具体化为 JSON 数据类型。TopN 可以增量更新这些 top 值,或者在不同的时间间隔内按需合并它们。
基本操作
在查看 TopN 的实际示例之前,让我们看看它的一些原始操作是如何工作的。首先 topn_add 更新一个 JSON 对象,其中包含一个 key 被看到的次数:
select topn_add('{}', 'a');
-- => {"a": 1}
-- record the sighting of another "a"
select topn_add(topn_add('{}', 'a'), 'a');
-- => {"a": 2}
该扩展还提供聚合以扫描多个值:
-- for normal_rand
create extension tablefunc;
-- count values from a normal distribution
SELECT topn_add_agg(floor(abs(i))::text)
FROM normal_rand(1000, 5, 0.7) i;
-- => {"2": 1, "3": 74, "4": 420, "5": 425, "6": 77, "7": 3}
如果 distinct 值的数量超过阈值,则聚合会丢弃那些最不常见的信息。
这可以控制空间使用。阈值可以由 topn.number_of_counters GUC 控制。它的默认值为 1000。
现实例子
现在来看一个更现实的例子,说明 TopN 在实践中是如何工作的。让我们提取 2000 年的亚马逊产品评论,并使用 TopN 快速查询。首先下载数据集:
curl -L https://examples.citusdata.com/customer_reviews_2000.csv.gz | \
gunzip > reviews.csv
接下来,将其摄取到分布式表中:
CREATE TABLE customer_reviews
(
customer_id TEXT,
review_date DATE,
review_rating INTEGER,
review_votes INTEGER,
review_helpful_votes INTEGER,
product_id CHAR(10),
product_title TEXT,
product_sales_rank BIGINT,
product_group TEXT,
product_category TEXT,
product_subcategory TEXT,
similar_product_ids CHAR(10)[]
);
SELECT create_distributed_table('customer_reviews', 'product_id');
\COPY customer_reviews FROM 'reviews.csv' WITH CSV
接下来我们将添加扩展,创建一个目标表来存储 TopN 生成的 json 数据,并应用我们之前看到的 topn_add_agg 函数。
-- run below command from coordinator, it will be propagated to the worker nodes as well
CREATE EXTENSION topn;
-- a table to materialize the daily aggregate
CREATE TABLE reviews_by_day
(
review_date date unique,
agg_data jsonb
);
SELECT create_reference_table('reviews_by_day');
-- materialize how many reviews each product got per day per customer
INSERT INTO reviews_by_day
SELECT review_date, topn_add_agg(product_id)
FROM customer_reviews
GROUP BY review_date;
现在,我们无需在 customer_reviews 上编写复杂的窗口函数,只需将 TopN 应用于 reviews_by_day。 例如,以下查询查找前五天中每一天最常被评论的产品:
SELECT review_date, (topn(agg_data, 1)).*
FROM reviews_by_day
ORDER BY review_date
LIMIT 5;
┌─────────────┬────────────┬───────────┐
│ review_date │ item │ frequency │
├─────────────┼────────────┼───────────┤
│ 2000-01-01 │ 0939173344 │ 12 │
│ 2000-01-02 │ B000050XY8 │ 11 │
│ 2000-01-03 │ 0375404368 │ 12 │
│ 2000-01-04 │ 0375408738 │ 14 │
│ 2000-01-05 │ B00000J7J4 │ 17 │
└─────────────┴────────────┴───────────┘
TopN 创建的 json 字段可以与 topn_union 和 topn_union_agg 合并。 我们可以使用后者来合并整个第一个月的数据,并列出该期间最受好评的五个产品。
SELECT (topn(topn_union_agg(agg_data), 5)).*
FROM reviews_by_day
WHERE review_date >= '2000-01-01' AND review_date < '2000-02-01'
ORDER BY 2 DESC;
┌────────────┬───────────┐
│ item │ frequency │
├────────────┼───────────┤
│ 0375404368 │ 217 │
│ 0345417623 │ 217 │
│ 0375404376 │ 217 │
│ 0375408738 │ 217 │
│ 043936213X │ 204 │
└────────────┴───────────┘
有关更多详细信息和示例,请参阅 TopN readme。
百分位计算
在大量行上找到精确的百分位数可能会非常昂贵,
因为所有行都必须转移到 coordinator 以进行最终排序和处理。
另一方面,找到近似值可以使用所谓的 sketch 算法在 worker 节点上并行完成。 coordinator 节点然后将压缩摘要组合到最终结果中,而不是读取完整的行。
一种流行的百分位数 sketch 算法使用称为 t-digest 的压缩数据结构,可在 tdigest 扩展中用于 PostgreSQL。Citus 集成了对此扩展的支持。
以下是在 Citus 中使用 t-digest 的方法:
- 在所有
PostgreSQL节点(coordinator和所有worker)上下载并安装tdigest扩展。tdigest 扩展 github 存储库有安装说明。 - 在数据库中创建
tdigest扩展。在coordinator上运行以下命令:CREATE EXTENSION tdigest;
coordinator也会将命令传播给worker。
当在查询中使用扩展中定义的任何聚合时,Citus 将重写查询以将部分 tdigest 计算下推到适用的 worker。
T-digest 精度可以通过传递给聚合的 compression 参数来控制。
权衡是准确性与 worker 和 coordinator 之间共享的数据量。
有关如何在 tdigest 扩展中使用聚合的完整说明,请查看官方 tdigest github 存储库中的文档。
限制下推
Citus 还尽可能将限制条款下推到 worker 的分片,以最大限度地减少跨网络传输的数据量。
但是,在某些情况下,带有 LIMIT 子句的 SELECT 查询可能需要从每个分片中获取所有行以生成准确的结果。 例如,如果查询需要按聚合列排序,则需要所有分片中该列的结果来确定最终聚合值。 由于大量的网络数据传输,这会降低 LIMIT 子句的性能。 在这种情况下,如果近似值会产生有意义的结果,Citus 提供了一种用于网络高效近似 LIMIT 子句的选项。
LIMIT 近似值默认禁用,可以通过设置配置参数 citus.limit_clause_row_fetch_count 来启用。
在这个配置值的基础上,Citus 会限制每个任务返回的行数,用于在 coordinator 上进行聚合。 由于这个 limit,最终结果可能是近似的。增加此 limit 将提高最终结果的准确性,同时仍提供从 worker 中提取的行数的上限。
SET citus.limit_clause_row_fetch_count to 10000;
分布式表的视图
Citus 支持分布式表的所有视图。有关视图的语法和功能的概述,请参阅 CREATE VIEW 的 PostgreSQL 文档。
请注意,某些视图导致查询计划的效率低于其他视图。
有关检测和改进不良视图性能的更多信息,请参阅子查询/CTE 网络开销。
(视图在内部被视为子查询。)
Citus 也支持物化视图,并将它们作为本地表存储在 coordinator 节点上。
连接(Join)
Citus 支持任意数量的表之间的 equi-JOIN,无论它们的大小和分布方法如何。
查询计划器根据表的分布方式选择最佳连接方法和 join 顺序。
它评估几个可能的 join 顺序并创建一个 join 计划,该计划需要通过网络传输最少的数据。
共置连接
当两个表共置时,它们可以在它们的公共分布列上有效地 join。co-located join(共置连接) 是 join 两个大型分布式表的最有效方式。
注意
确保表分布到相同数量的分片中,并且每个表的分布列具有完全匹配的类型。尝试加入类型略有不同的列(例如 `int` 和 `bigint`)可能会导致问题。
引用表连接
引用表可以用作“维度”表,
以有效地与大型“事实”表连接。因为引用表在所有 worker 上完全复制,
所以 reference join 可以分解为每个 worker 上的本地连接并并行执行。
reference join 就像一个更灵活的 co-located join 版本,
因为引用表没有分布在任何特定的列上,并且可以自由地 join 到它们的任何列上。
引用表也可以与 coordinator 节点本地的表连接。
重新分区连接
在某些情况下,您可能需要在除分布列之外的列上连接两个表。
对于这种情况,Citus 还允许通过动态重新分区查询的表来连接非分布 key 列。
在这种情况下,要分区的表由查询优化器根据分布列、连接键和表的大小来确定。
使用重新分区的表,可以确保只有相关的分片对相互连接,从而大大减少了通过网络传输的数据量。
通常,co-located join 比 repartition join 更有效,因为 repartition join 需要对数据进行混洗。
因此,您应该尽可能通过 common join 键来分布表。
更多
- Citus 分布式 PostgreSQL 集群 - SQL Reference(创建和修改分布式表 DDL)
- Citus 分布式 PostgreSQL 集群 - SQL Reference(摄取、修改数据 DML)
Citus 分布式 PostgreSQL 集群 - SQL Reference(查询分布式表 SQL)的更多相关文章
- Citus 分布式 PostgreSQL 集群 - SQL Reference(查询处理)
一个 Citus 集群由一个 coordinator 实例和多个 worker 实例组成. 数据在 worker 上进行分片和复制,而 coordinator 存储有关这些分片的元数据.向集群发出的所 ...
- Citus 分布式 PostgreSQL 集群 - SQL Reference(手动查询传播)
手动查询传播 当用户发出查询时,Citus coordinator 将其划分为更小的查询片段,其中每个查询片段可以在工作分片上独立运行.这允许 Citus 将每个查询分布在集群中. 但是,将查询划分为 ...
- Citus 分布式 PostgreSQL 集群 - SQL Reference(摄取、修改数据 DML)
插入数据 要将数据插入分布式表,您可以使用标准 PostgreSQL INSERT 命令.例如,我们从 Github 存档数据集中随机选择两行. INSERT http://www.postgresq ...
- Citus 分布式 PostgreSQL 集群 - SQL Reference(SQL支持和变通方案)
由于 Citus 通过扩展 PostgreSQL 提供分布式功能,因此它与 PostgreSQL 结构兼容.这意味着用户可以使用丰富且可扩展的 PostgreSQL 生态系统附带的工具和功能来处理使用 ...
- Citus 分布式 PostgreSQL 集群 - SQL Reference(创建和修改分布式表 DDL)
创建和分布表 要创建分布式表,您需要首先定义表 schema. 为此,您可以使用 CREATE TABLE 语句定义一个表,就像使用常规 PostgreSQL 表一样. CREATE TABLE ht ...
- 分布式 PostgreSQL 集群(Citus)官方教程 - 迁移现有应用程序
将现有应用程序迁移到 Citus 有时需要调整 schema 和查询以获得最佳性能. Citus 扩展了 PostgreSQL 的分布式功能,但它不是扩展所有工作负载的直接替代品.高性能 Citus ...
- 分布式 PostgreSQL 集群(Citus),分布式表中的分布列选择最佳实践
确定应用程序类型 在 Citus 集群上运行高效查询要求数据在机器之间正确分布.这因应用程序类型及其查询模式而异. 大致上有两种应用程序在 Citus 上运行良好.数据建模的第一步是确定哪些应用程序类 ...
- 分布式 PostgreSQL 集群(Citus),官方快速入门教程
多租户应用程序 在本教程中,我们将使用示例广告分析数据集来演示如何使用 Citus 来支持您的多租户应用程序. 注意 本教程假设您已经安装并运行了 Citus. 如果您没有运行 Citus,则可以使用 ...
- 在 Kubernetes 上快速测试 Citus 分布式 PostgreSQL 集群(分布式表,共置,引用表,列存储)
准备工作 这里假设,你已经在 k8s 上部署好了基于 Citus 扩展的分布式 PostgreSQL 集群. 查看 Citus 集群(kubectl get po -n citus),1 个 Coor ...
随机推荐
- 基于containerd二进制部署k8s-v1.23.3
文章目录 前言 k8s 组件 环境准备 创建目录 关闭防火墙 关闭selinux 关闭swap 开启内核模块 分发到所有节点 启用systemd自动加载模块服务 配置系统参数 分发到所有节点 加载系统 ...
- 中国首个进入谷歌编程之夏(GSoC)的开源项目: Casbin, 2022 年预选生招募!
Casbin 明日之星预选生计划-Talent for Casbin 2022 "Casbin 明日之星预选生计划-Talent for Casbin 2022"是什么? &quo ...
- Java诊断神器:Arthas常用功能
最新原文:https://www.cnblogs.com/uncleyong/p/14944401.html Arthas是Alibaba开源的Java诊断工具,功能很强大,它是通过Agent方式来连 ...
- owasp中国
http://www.owasp.org.cn/OWASP-CHINA/owasp-project/owasp53415927969079c198ce9669-owasp_top_10_privacy ...
- 华为eNSP无限井号#解决方法
如下图所示,允许ensp相关应用通过防火墙
- RFC2544学习频率“Learning Frequency”详解—信而泰网络测试仪实操
在RFC2544中, 会有一个Learning Frequency的字段让我们选择, 其值有4个, 分别是learn once, learn Every Trial, Learn Every Fram ...
- 教你快速区分传统报表和商业智能BI
很多人分不清楚,传统报表和商业智能BI之间的区别?有些人认为,BI就是做报表的,其实不然,报表只是BI的一部分,报表是关于过去和现状的展示,而BI是关于如何通过分析数据,帮助决策者找到改变和提高的方案 ...
- 由浅入深--ORM简介
一.ORM简介 从传统的JDBC开始说起 下面是通过JDBC连接Oracle的步骤,如下代码所示: Connection conn = null; PreparedStatement stmt = n ...
- 为 CmakeLists.txt 添加 boost 组件
目录 为 CmakeLists.txt 添加 boost 组件 Boost 常用组件 1.时间与日期 timer, date_time, chrono 2.内存管理 system 3.实用工具库 4. ...
- git-切换远程仓库
1. 查看远程仓库地址 git remote -v 2. 切换远程仓库地址 (1)直接切换 git remote set-url origin URL //URL为新地址 (2)先删除后添加 git ...