深入理解Java:String
在讲解String之前,我们先了解一下Java的内存结构。
一、Java内存模型
按照官方的说法:Java 虚拟机具有一个堆,堆是运行时数据区域,所有类实例和数组的内存均从此处分配。
JVM主要管理两种类型内存:堆和非堆,堆内存(Heap Memory)是在 Java 虚拟机启动时创建,非堆内存(Non-heap Memory)是在JVM堆之外的内存。
简单来说,非堆包含方法区、JVM内部处理或优化所需的内存(如 JITCompiler,Just-in-time Compiler,即时编译后的代码缓存)、每个类结构(如运行时常数池、字段和方法数据)以及方法和构造方法的代码。
Java的堆是一个运行时数据区,类的(对象从中分配空间。这些对象通过new、newarray、 anewarray和multianewarray等指令建立,它们不需要程序代码来显式的释放。堆是由垃圾回收来负责的,堆的优势是可以动态地分配内存大小,生存期也不必事先告诉编译器,因为它是在运行时动态分配内存的,Java的垃圾收集器会自动收走这些不再使用的数据。但缺点是,由于要在运行时动态分配内存,存取速度较慢。
栈的优势是,存取速度比堆要快,仅次于寄存器,栈数据可以共享。但缺点是,存在栈中的数据大小与生存期必须是确定的,缺乏灵活性。栈中主要存放一些基本类型的变量数据(int, short, long, byte, float, double, boolean, char)和对象句柄(引用)。
虚拟机必须为每个被装载的类型维护一个常量池。常量池就是该类型所用到常量的一个有序集合,包括直接常量(string,integer和 floating point常量)和对其他类型,字段和方法的符号引用。
对于String常量,它的值是在常量池中的。而JVM中的常量池在内存当中是以表的形式存在的, 对于String类型,有一张固定长度的CONSTANT_String_info表用来存储文字字符串值,注意:该表只存储文字字符串值,不存储符号引用。说到这里,对常量池中的字符串值的存储位置应该有一个比较明了的理解了。在程序执行的时候,常量池会储存在Method Area,而不是堆中。常量池中保存着很多String对象; 并且可以被共享使用,因此它提高了效率
具体关于JVM和内存等知识请参考:
二、案例解析
public static void main(String[] args) {
/**
* 情景一:字符串池
* JAVA虚拟机(JVM)中存在着一个字符串池,其中保存着很多String对象;
* 并且可以被共享使用,因此它提高了效率。
* 由于String类是final的,它的值一经创建就不可改变。
* 字符串池由String类维护,我们可以调用intern()方法来访问字符串池。
*/
String s1 = "abc";
//↑ 在字符串池创建了一个对象
String s2 = "abc";
//↑ 字符串pool已经存在对象“abc”(共享),所以创建0个对象,累计创建一个对象
System.out.println("s1 == s2 : "+(s1==s2));
//↑ true 指向同一个对象,
System.out.println("s1.equals(s2) : " + (s1.equals(s2)));
//↑ true 值相等
//↑------------------------------------------------------over
/**
* 情景二:关于new String("")
*
*/
String s3 = new String("abc");
//↑ 创建了两个对象,一个存放在字符串池中,一个存在与堆区中;
//↑ 还有一个对象引用s3存放在栈中
String s4 = new String("abc");
//↑ 字符串池中已经存在“abc”对象,所以只在堆中创建了一个对象
System.out.println("s3 == s4 : "+(s3==s4));
//↑false s3和s4栈区的地址不同,指向堆区的不同地址;
System.out.println("s3.equals(s4) : "+(s3.equals(s4)));
//↑true s3和s4的值相同
System.out.println("s1 == s3 : "+(s1==s3));
//↑false 存放的地区多不同,一个栈区,一个堆区
System.out.println("s1.equals(s3) : "+(s1.equals(s3)));
//↑true 值相同
//↑------------------------------------------------------over
/**
* 情景三:
* 由于常量的值在编译的时候就被确定(优化)了。
* 在这里,"ab"和"cd"都是常量,因此变量str3的值在编译时就可以确定。
* 这行代码编译后的效果等同于: String str3 = "abcd";
*/
String str1 = "ab" + "cd"; //1个对象
String str11 = "abcd";
System.out.println("str1 = str11 : "+ (str1 == str11));
//↑------------------------------------------------------over
/**
* 情景四:
* 局部变量str2,str3存储的是存储两个拘留字符串对象(intern字符串对象)的地址。
*
* 第三行代码原理(str2+str3):
* 运行期JVM首先会在堆中创建一个StringBuilder类,
* 同时用str2指向的拘留字符串对象完成初始化,
* 然后调用append方法完成对str3所指向的拘留字符串的合并,
* 接着调用StringBuilder的toString()方法在堆中创建一个String对象,
* 最后将刚生成的String对象的堆地址存放在局部变量str3中。
*
* 而str5存储的是字符串池中"abcd"所对应的拘留字符串对象的地址。
* str4与str5地址当然不一样了。
*
* 内存中实际上有五个字符串对象:
* 三个拘留字符串对象、一个String对象和一个StringBuilder对象。
*/
String str2 = "ab"; //1个对象
String str3 = "cd"; //1个对象
String str4 = str2+str3;
String str5 = "abcd";
System.out.println("str4 = str5 : " + (str4==str5)); // false
//↑------------------------------------------------------over
/**
* 情景五:
* JAVA编译器对string + 基本类型/常量 是当成常量表达式直接求值来优化的。
* 运行期的两个string相加,会产生新的对象的,存储在堆(heap)中
*/
String str6 = "b";
String str7 = "a" + str6;
String str67 = "ab";
System.out.println("str7 = str67 : "+ (str7 == str67));
//↑str6为变量,在运行期才会被解析。
final String str8 = "b";
String str9 = "a" + str8;
String str89 = "ab";
System.out.println("str9 = str89 : "+ (str9 == str89));
//↑str8为常量变量,编译期会被优化
//↑------------------------------------------------------over
}
总结:
1.String类初始化后是不可变的(immutable)
这一说又要说很多,大家只要知道String的实例一旦生成就不会再改变了,比如说:String str=”kv”+”ill”+” “+”ans”; 就是有4个字符串常量,首先”kv”和”ill”生成了”kvill”存在内存中,然后”kvill”又和” ” 生成 “kvill “存在内存中,最后又和生成了”kvill ans”;并把这个字符串的地址赋给了str,就是因为String的”不可变”产生了很多临时变量,这也就是为什么建议用StringBuffer的原 因了,因为StringBuffer是可改变的。
下面是一些String相关的常见问题:
String中的final用法和理解
final StringBuffer a = new StringBuffer("111");
final StringBuffer b = new StringBuffer("222");
a=b;//此句编译不通过 final StringBuffer a = new StringBuffer("111");
a.append("222");// 编译通过
可见,final只对引用的"值"(即内存地址)有效,它迫使引用只能指向初始指向的那个对象,改变它的指向会导致编译期错误。至于它所指向的对象的变化,final是不负责的。
2.代码中的字符串常量在编译的过程中收集并放在class文件的常量区中,如"123"、"123"+"456"等,含有变量的表达式不会收录,如"123"+a。
3.JVM在加载类的时候,根据常量区中的字符串生成常量池,每个字符序列如"123"会生成一个实例放在常量池里,这个实例是不在堆里的,也不会被GC,这个实例的value属性从源码的构造函数看应该是用new创建数组置入123的,所以按我的理解此时value存放的字符数组地址是在堆里,如果有误的话欢迎大家指正。
4.使用String不一定创建对象
在执行到双引号包含字符串的语句时,如String a = "123",JVM会先到常量池里查找,如果有的话返回常量池里的这个实例的引用,否则的话创建一个新实例并置入常量池里。如果是 String a = "123" + b (假设b是"456"),前半部分"123"还是走常量池的路线,但是这个+操作符其实是转换成[SringBuffer].Appad()来实现的,所以最终a得到是一个新的实例引用,而且a的value存放的是一个新申请的字符数组内存空间的地址(存放着"123456"),而此时"123456"在常量池中是未必存在的。
要注意: 我们在使用诸如String str = "abc";的格式定义类时,总是想当然地认为,创建了String类的对象str。担心陷阱!对象可能并没有被创建!而可能只是指向一个先前已经创建的对象。只有通过new()方法才能保证每次都创建一个新的对象
5.使用new String,一定创建对象
在执行String a = new String("123")的时候,首先走常量池的路线取到一个实例的引用,然后在堆上创建一个新的String实例,走以下构造函数给value属性赋值,然后把实例引用赋值给a:
public String(String original) {
int size = original.count;
char[] originalValue = original.value;
char[] v;
if (originalValue.length > size) {
// The array representing the String is bigger than the new
// String itself. Perhaps this constructor is being called
// in order to trim the baggage, so make a copy of the array.
int off = original.offset;
v = Arrays.copyOfRange(originalValue, off, off+size);
} else {
// The array representing the String is the same
// size as the String, so no point in making a copy.
v = originalValue;
}
this.offset = ;
this.count = size;
this.value = v;
}
从中我们可以看到,虽然是新创建了一个String的实例,但是value是等于常量池中的实例的value,即是说没有new一个新的字符数组来存放"123"。
如果是String a = new String("123"+b)的情况,首先看回第4点,"123"+b得到一个实例后,再按上面的构造函数执行。
6.String.intern()
String对象的实例调用intern方法后,可以让JVM检查常量池,如果没有实例的value属性对应的字符串序列比如"123"(注意是检查字符串序列而不是检查实例本身),就将本实例放入常量池,如果有当前实例的value属性对应的字符串序列"123"在常量池中存在,则返回常量池中"123"对应的实例的引用而不是当前实例的引用,即使当前实例的value也是"123"。
public native String intern();
存在于.class文件中的常量池,在运行期被JVM装载,并且可以扩充。String的 intern()方法就是扩充常量池的 一个方法;当一个String实例str调用intern()方法时,Java 查找常量池中 是否有相同Unicode的字符串常量,如果有,则返回其的引用,如果没有,则在常 量池中增加一个Unicode等于str的字符串并返回它的引用;看示例就清楚了
public static void main(String[] args) {
String s0 = "kvill";
String s1 = new String("kvill");
String s2 = new String("kvill");
System.out.println( s0 == s1 ); //false
System.out.println( "**********" );
s1.intern(); //虽然执行了s1.intern(),但它的返回值没有赋给s1
s2 = s2.intern(); //把常量池中"kvill"的引用赋给s2
System.out.println( s0 == s1); //flase
System.out.println( s0 == s1.intern() ); //true//说明s1.intern()返回的是常量池中"kvill"的引用
System.out.println( s0 == s2 ); //true
}
最后我再破除一个错误的理解:有人说,“使用 String.intern() 方法则可以将一个 String 类的保存到一个全局 String 表中 ,如果具有相同值的 Unicode 字符串已经在这个表中,那么该方法返回表中已有字符串的地址,如果在表中没有相同值的字符串,则将自己的地址注册到表中”如果我把他说的这个全局的 String 表理解为常量池的话,他的最后一句话,”如果在表中没有相同值的字符串,则将自己的地址注册到表中”是错的:
public static void main(String[] args) {
String s1 = new String("kvill");
String s2 = s1.intern();
System.out.println( s1 == s1.intern() ); //false
System.out.println( s1 + " " + s2 ); //kvill kvill
System.out.println( s2 == s1.intern() ); //true
}
在这个类中我们没有声名一个”kvill”常量,所以常量池中一开始是没有”kvill”的,当我们调用s1.intern()后就在常量池中新添加了一 个”kvill”常量,原来的不在常量池中的”kvill”仍然存在,也就不是“将自己的地址注册到常量池中”了。
s1==s1.intern() 为false说明原来的”kvill”仍然存在;s2现在为常量池中”kvill”的地址,所以有s2==s1.intern()为true。
StringBuffer与StringBuilder的区别,它们的应用场景是什么?
StringBuilder 始于 JDK 1.5
从 JDK 1.5 开始,带有字符串变量的连接操作(+),JVM 内部采用的是
StringBuilder 来实现的,而之前这个操作是采用 StringBuffer 实现的。
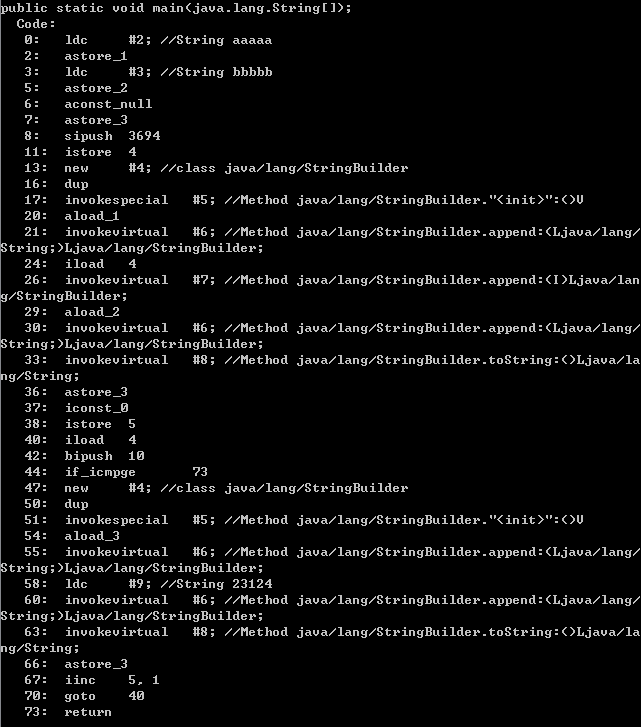
public class Buffer {
public static void main(String[] args) {
String s1 = "aaaaa";
String s2 = "bbbbb";
String r = null;
int i = ;
r = s1 + i + s2;
for(int j=;i<;j++){
r+="";
}
}
}
使用命令javap -c Buffer查看其字节码实现:
参考:
java那点事——StringBuffer与StringBuilder原理与区别
深入理解Java:String的更多相关文章
- 通过反编译深入理解Java String及intern(转)
通过反编译深入理解Java String及intern 原文传送门:http://www.cnblogs.com/paddix/p/5326863.html 一.字符串问题 字符串在我们平时的编码工作 ...
- 理解Java String和String Pool
本文转载自: http://blog.sina.com.cn/s/blog_5203f6ce0100tiux.html 要理解 java中String的运作方式,必须明确一点:String是一个非可变 ...
- 深入理解java String 及intern
一.字符串问题 字符串在我们平时的编码工作中其实用的非常多,并且用起来也比较简单,所以很少有人对其做特别深入的研究.倒是面试或者笔试的时候,往往会涉及比较深入和难度大一点的问题.我在招聘的时候也偶尔会 ...
- 深入理解Java String类(综合)
在Java语言了中,所有类似“ABC”的字面值,都是String类的实例:String类位于java.lang包下,是Java语言的核心类,提供了字符串的比较.查找.截取.大小写转换等操作:Java语 ...
- 通过反编译深入理解Java String及intern
一.字符串问题 字符串在我们平时的编码工作中其实用的非常多,并且用起来也比较简单,所以很少有人对其做特别深入的研究.倒是面试或者笔试的时候,往往会涉及比较深入和难度大一点的问题.我在招聘的时候也偶尔会 ...
- (转)通过反编译深入理解Java String及intern
原文链接:https://www.cnblogs.com/paddix/p/5326863.html 一.字符串问题 字符串在我们平时的编码工作中用的非常多,并且用起来非常简单,所以很少有人对其做特别 ...
- 深入理解Java String#intern() 内存模型
原文出处: codelog.me 大家知道,Java中string.intern()方法调用会先去字符串常量池中查找相应的字符串,如果字符串不存在,就会在字符串常量池中创建该字符串然后再返回. 字符串 ...
- 深入理解java String 对象的不可变性
下面我们通过一组图表来解释Java字符串的不可变性 1.声明一个String对象 String s = "abcd"; 2.将一个String变量赋值给另一个String变量 St ...
- 从Java String实例来理解ANSI、Unicode、BMP、UTF等编码概念
转(http://www.codeceo.com/article/java-string-ansi-unicode-bmp-utf.html#0-tsina-1-10971-397232819ff9a ...
- 深入理解Java中的String
一.String类 想要了解一个类,最好的办法就是看这个类的实现源代码,来看一下String类的源码: public final class String implements java.io.Ser ...
随机推荐
- ASP.NET MVC+EF框架+EasyUI实现权限管理系列(22)-为用户设置角色
ASP.NET MVC+EF框架+EasyUI实现权限管系列 (开篇) (1):框架搭建 (2):数据库访问层的设计Demo (3):面向接口编程 (4 ):业务逻辑层的封装 ...
- jquery右下角自动弹出关闭层
效果体验:http://keleyi.com/keleyi/phtml/jqtexiao/36.htm 右下角弹出层后,会在一定时间后自动隐藏.第一版本:http://www.cnblogs.com/ ...
- 操作数数据类型 ntext 对于 max 运算符无效
SoStyle.chi_description AS chi_description, SoStyle.description AS eng_description, SoStyle.chi_qual ...
- 走进SVG
什么是SVG?也许现在很多人都听说过SVG的人比较多,但不一定了解什么是SVG:SVG(Scalable Vector Graphics 一大串看不懂的英文)可伸缩矢量图形,它是用XML格式来定义用于 ...
- 理解CSV文件以及ABAP中的相关操作
在很多ABAP开发中,我们使用CSV文件,有时候,关于CSV文件本身的一些问题使人迷惑.它仅仅是一种被逗号分割的文本文档吗? 让我们先来看看接下来可能要处理的几个相关组件的词汇的语义. Separat ...
- SharePoint 2013 自定义扩展菜单(二)
接博文<SharePoint 2013 自定义扩展菜单>,多加了几个例子,方便大家理解. 例七 列表设置菜单扩展(listedit.aspx) 扩展效果 XML描述 <CustomA ...
- Alvin
Alvin Zhao 東京都 港区虎ノ門2-10-4 ホテルオークラ東京 M 663 電話番号: 0335820111
- IOS开发基础知识--碎片34
1:第三方插件SKSTableView在IOS7.1.1出现闪退的问题 解决办法,修改其内部源代码: (NSInteger)subRow { id indexpath = [NSIndexPath c ...
- java数组的常用函数
import java.util.*; class 数组索引{ public static void main(String args[]){ //数组中的使用工具:Arrays int[] arr ...
- Android 框架学习之 第一天 okhttp & Retrofit
最近面试,一直被问道新技术新框架,这块是短板,慢慢补吧. 关于框架的学习,分几个步骤 I.框架的使用 II.框架主流使用的版本和Android对应的版本 III.框架的衍生使用比如okhttp就会有R ...