.NET性能优化-ArrayPool同时复用数组和对象
前两天在微信后台收到了读者的私信,问了一个这样的问题,由于私信回复有字数和篇幅限制,我在这里统一回复一下。读者的问题是这样的:
大佬您好,之前读了您的文章受益匪浅,我们有一个项目经常占用 7-8GB 的内存,使用了您推荐的
ArrayPool以后降低到 4GB 左右,我还想着能不能继续优化,于是 dump 看了一下,发现是ArrayPool对应的一个数组有几万个对象,这个类有 100 多个属性。我想问有没有方法能复用这些对象?感谢!
根据读者的问题,我们摘抄出重点,现在他的数组已经得到池化,但是数组里面存的对象很大,从而导致内存很大。
我觉得一个类有 100 多个属性应该是不太正常的,当然也可能是报表导出之类的需求,如果是普通类有 100 多个属性,那应该做一些抽象和拆分了。
如果是少部分的大对象需要重用,那其实可以使用ObjectPool,如果是数万个对象要重用,那么ObjectPool里面的 CAS 算法会成为瓶颈,那有没有更好的方式呢?其实解决方案就在ArrayPool类本身,可能大家平时没有注意过。
再聊 ArrayPool
我们再来回顾一下ArrayPool的用法,它的用法很简单,核心就是Rent和Return两个方法,演示代码如下所示:
using System.Buffers;
namespace BenchmarkPooledList;
public class ArrayPoolDemo
{
public void Demo()
{
// get array from pool
var pool = ArrayPool<byte>.Shared.Rent(10);
try
{
// do something
}
finally
{
// return
ArrayPool<byte>.Shared.Return(pool);
}
}
}
其实对于上面的这个问题,ArrayPool已经有了解决方案,不知道大家有没有注意Return方法有一个默认参数clearArray=false.
public abstract void Return (T[] array, bool clearArray = false);
其中clearArray的含义就是当数组被归还到池时,是不是清空数组,也就是会不会将数组的所有元素重置为null,看下面的例子就明白了。
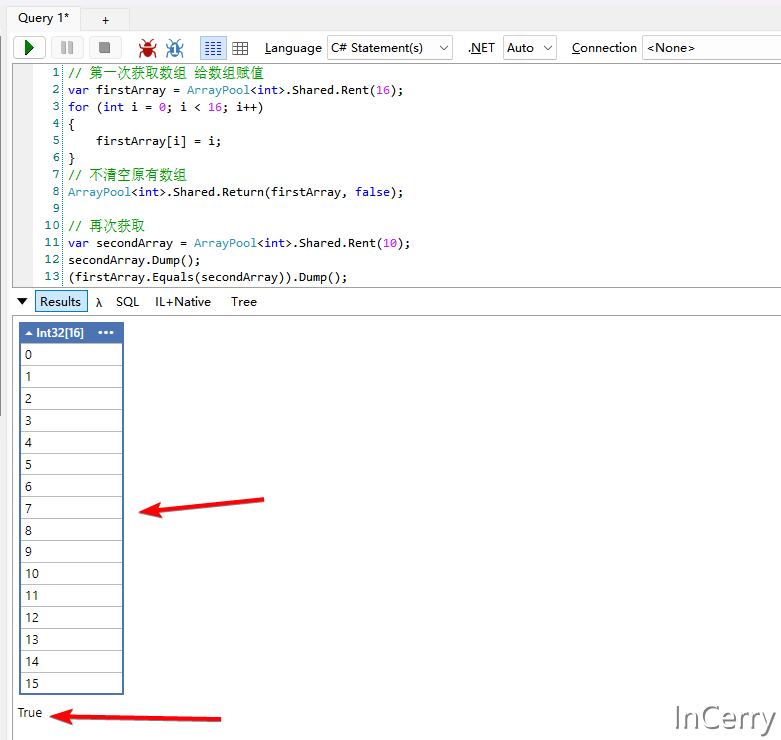
可以发现只要在归还到数组时不清空,那么第二次拿到的数组还是会保留值,基于这样一个设计,我们就可以在复用数组的同时复用对应的元素对象。
性能比较
那么这样是否能解决之前提到的问题呢?我们很简单就可以构建一个测试用例,一个在代码里面使用new每次创建对象,另外一个尽量复用对象,为null时才创建。
// 定义一个大对象,放了40个属性
public class BigObject
{
public string P1 { get; set; }
public string P2 { get; set; }
public string P3 { get; set; }
.....
}
然后创建一个数据集,生成1000条数据,使用默认的方式,每次都new对象。
private static readonly string[] Datas = Enumerable.Range(0, 1000).Select(c => c.ToString()).ToArray();
[Benchmark(Baseline = true)]
public long UseArrayPool()
{
var pool = ArrayPool<BigObject?>.Shared.Rent(Datas.Length);
try
{
for (int i = 0; i < Datas.Length; i++)
{
pool[i] = new BigObject
{
P1 = Datas[i],
P2 = Datas[i],
P3 = Datas[i]
// .... 省略赋值代码
};
}
return pool.Length;
}
finally
{
ArrayPool<BigObject?>.Shared.Return(pool);
}
}
另外一种方式就是复用对象池的对象,只有为null时才创建:
[Benchmark]
public long UseArrayPoolNeverClear()
{
var pool = ArrayPool<BigObject?>.Shared.Rent(Datas.Length);
try
{
for (int i = 0; i < Datas.Length; i++)
{
// 复用obj 为null时才创建
var obj = pool[i] ?? (pool[i] = new BigObject());
obj.P1 = Datas[i];
obj.P2 = Datas[i];
obj.P3 = Datas[i];
// .... 省略赋值代码
}
return pool.Length;
}
finally
{
ArrayPool<BigObject?>.Shared.Return(pool, false);
}
}
可以看一下 Benchmark 的结果:
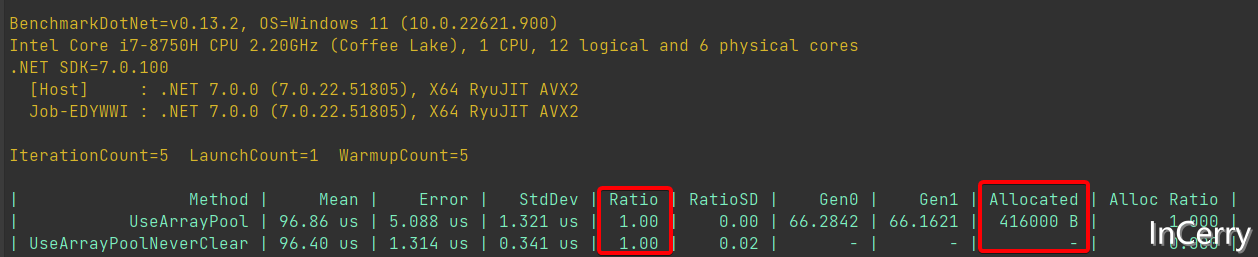
复用大对象的场景下,在没有造成性能的下降的情况下,内存分配几乎为0。
ArrayObjectPool
之前笔者实现了一个类,优化了一下上面代码的性能,但是之前换了电脑,没有备份一些杂乱数据,现在找不到了。
具体优化原理是每一次都要进行null比较还是比较麻烦,而且如果能确定其数组不变的话,这些 null 判断是可以移除的。
凭借记忆写了一个 Demo,主要是确立在池里的数组是私有的,初始化一次以后就不需要再初始化,所以只要检测第一个元素是否为null就行,实现如下所示:
// 应该要实现IList<T>接口 和 ICollection<T> 等等的接口
// 不过这只是简单的demo 各位可以自行实现
public class ArrayObjectPool<T> : IDisposable // , IList<T>
where T : new()
{
// 创建一个独享的池
private static ArrayPool<T> _pool = ArrayPool<T>.Create();
private readonly T[] _items;
public ArrayObjectPool(int size)
{
Length = size;
_items = _pool.Rent(size);
if (_items[0] is not null) return;
// 如果第一个元素为null 说明是没初始化的
// 那么需要初始化
for (int i = 0; i < _items.Length; i++)
{
_items[i] = new T();
}
}
// 为了安全只实现get
public T this[int index]
{
get
{
if (index < 0 || index > Length)
throw new ArgumentOutOfRangeException(nameof(index));
return _items[index];
}
set => throw new NotSupportedException();
}
public int Length { get; }
// 释放时返回数据
public void Dispose()
{
_pool.Return(_items);
}
/// <summary>
/// 当ArrayPool过大时 可以重新创建
/// 旧的池就会被GC 回收
/// </summary>
public static void Flush()
{
_pool = ArrayPool<T>.Create();
}
}
同样的,对比了一下性能,因为会创建一个对象,所以内存占用比直接使用ArrayPool要高几十个字节,但是由于不用比较null,是实现里面最快的(当然也快不了多少,就 2%):
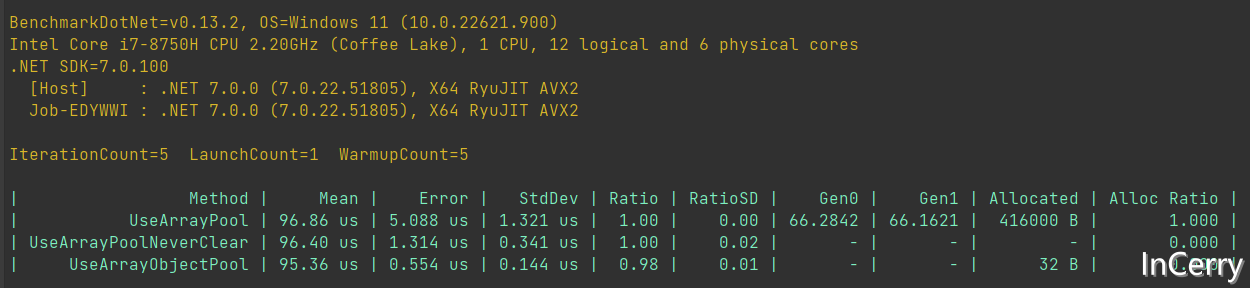
总结
我相信这个应该已经能回答提出的问题,我们可以在复用数组的时候复用数组所对应的对象,当然你必须确保复用对象没有副作用,比如复用了旧的脏数据。
如果不是经常写这样的代码,像笔者一样封装一个ArrayObjectPool也没有必要,笔者本人也就写过那么一次,如果经常有这样的场景,那可以封装一个安全的ArrayObjectPool,想必也不是什么困难的事情。
感谢阅读,如果您有什么关于性能优化的疑问,欢迎在公众号留言。
.NET 性能优化交流群
相信大家在开发中经常会遇到一些性能问题,苦于没有有效的工具去发现性能瓶颈,或者是发现瓶颈以后不知道该如何优化。之前一直有读者朋友询问有没有技术交流群,但是由于各种原因一直都没创建,现在很高兴的在这里宣布,我创建了一个专门交流.NET 性能优化经验的群组,主题包括但不限于:
- 如何找到.NET 性能瓶颈,如使用 APM、dotnet tools 等工具
- .NET 框架底层原理的实现,如垃圾回收器、JIT 等等
- 如何编写高性能的.NET 代码,哪些地方存在性能陷阱
希望能有更多志同道合朋友加入,分享一些工作中遇到的.NET 性能问题和宝贵的性能分析优化经验。由于已经达到 200 人,可以加我微信,我拉你进群: ls1075
.NET性能优化-ArrayPool同时复用数组和对象的更多相关文章
- .NET性能优化-为结构体数组使用StructLinq
前言 本系列的主要目的是告诉大家在遇到性能问题时,有哪些方案可以去优化:并不是要求大家一开始就使用这些方案来提升性能. 在之前几篇文章中,有很多网友就有一些非此即彼的观念,在实际中,处处都是开发效率和 ...
- javascript性能优化之使用对象、数组直接量代替典型的对象创建和赋值
1.典型的对象创建和赋值操作代码示例 var myObject = new Object(); myObject.name = "Nicholas"; myObject.count ...
- QF——UITableViewCell性能优化(视图复用机制)
这几篇博客总结的不错: 点击进入 点击进入 总结起来方案一般有以下几种: 1.不使用透明视图: 2.减少视图的个数: 3.cell复用机制:(重点) 4.图片缓存: 5.网络请求使用非主线程. 6.预 ...
- JAXB性能优化
前言: 之前在查阅jaxb相关资料的同时, 也看到了一些关于性能优化的点. 主要集中于对象和xml互转的过程中, 确实有些实实在在需要注意的点. 这边浅谈jaxb性能优化的一个思路. 案列: 先来构造 ...
- php多层数组与对象的转换实例代码
通过json_decode(json_encode($object)可以将对象一次性转换为数组,但是object中遇到非utf-8编码的非ascii字符则会出现问题,比如gbk的中文,何况json_e ...
- iOS性能优化-数组、字典便利时间复杂
上图是几种时间复杂度的关系,性能优化一定程度上是为了降低程序执行效率减低时间复杂度. 如下是几种时间复杂度的实例: O(1) return array[index] == value; 复制代码 O( ...
- .NET性能优化-复用StringBuilder
在之前的文章中,我们介绍了dotnet在字符串拼接时可以使用的一些性能优化技巧.比如: 为StringBuilder设置Buffer初始大小 使用ValueStringBuilder等等 不过这些都多 ...
- .NET性能优化-推荐使用Collections.Pooled
简介 性能优化就是如何在保证处理相同数量的请求情况下占用更少的资源,而这个资源一般就是CPU或者内存,当然还有操作系统IO句柄.网络流量.磁盘占用等等.但是绝大多数时候,我们就是在降低CPU和内存的占 ...
- 【腾讯Bugly干货分享】跨平台 ListView 性能优化
本文来自于腾讯Bugly公众号(weixinBugly),未经作者同意,请勿转载,原文地址:https://mp.weixin.qq.com/s/FbiSLPxFdGqJ00WgpJ94yw 导语 精 ...
- Java 性能优化之 String 篇
原文:http://www.ibm.com/developerworks/cn/java/j-lo-optmizestring/ Java 性能优化之 String 篇 String 方法用于文本分析 ...
随机推荐
- MySQL8 二进制日志
启用二进制日志 # cat /etc/my.cnf [mysqld] server_id=100 log_bin=/var/log/mysql/binlogs/server1 # mkdir -p / ...
- 组件化开发2-安装cocoaPods
第一步:安装ruby 不能一上来就换ruby源.虽然mac自带了ruby,但是版本一般都偏低,如果不进行更新会导致版本依赖问题. 这里使用rvm来管理ruby,它允许共存多个ruby.RVM:Ruby ...
- google浏览器个人常用快捷键
分享一下个人常用快捷键. 说明:字母排序规则遵循字母表(a->z) 快捷键 介绍 ctrl+0 恢复页面到100% ctrl+数字(1~9) 切换至序号对应的标签页 ctrl+d 将当前标签页添 ...
- DophineSheduler上下游任务之间动态传参案例及易错点总结
作者简介 淡丹 数仓开发工程师 5年数仓开发经验,目前主要负责百得利MOBY新车业务 二手车业务及售后服务业务系统数仓建设 业务需求 在ETL任务之间调度时,我们有的时候会需要将上游的 ...
- Node.js(二)express
npm init -y(初始化项目) npm install express(引入express) npx express-generator -e(自动生成模板.添加对 ejs 模板引擎的支持) a ...
- 洛谷P7960 [NOIP2021] 报数 (筛法)
禁止报的数的生成规则与埃式筛法类似,考虑用筛法预处理可以报出的数字列表和不可报出的数字,从而 O(1) 回答每一组询问. 用check函数判断数字中是否含有7,用nx[i]记录数字i的下一个合法数. ...
- Dytechlab Cup 2022 (A - C)
Dytechlab Cup 2022 (A - C) A - Ela Sorting Books 分析:贪心,将字符串每一位都存在map里,从前往后尽量让每一个\(n / k\)的段\(mex\)值尽 ...
- Java程序员必会Synchronized底层原理剖析
synchronized作为Java程序员最常用同步工具,很多人却对它的用法和实现原理一知半解,以至于还有不少人认为synchronized是重量级锁,性能较差,尽量少用. 但不可否认的是synchr ...
- NLP之基于logistic回归的文本分类
数据集下载: 链接:https://pan.baidu.com/s/17EL37CQ-FtOXhtdZHQDPgw 提取码:0829 逻辑斯蒂回归 @ 目录 逻辑斯蒂回归 1.理论 1.1 多分类 1 ...
- 是什么让.NET7的Min和Max方法性能暴增了45倍?
简介 在之前的一篇文章.NET性能系列文章一:.NET7的性能改进中我们聊到Linq中的Min()和Max()方法.NET7比.NET6有高达45倍的性能提升,当时Benchmark代码和结果如下所示 ...