使用pandas处理数据和matplotlib生成可视化图表
一、缘由
上一篇输入关键词“口红”,将淘宝中的的相关商品信息全部爬取了下拉,并且以CSV的文件格式储存。我们拿到数据之后,那么就需要对数据进行处理。只是将爬取到的数据以更直观的方式——图表呈现出来。并且最后使用jieba、wordcloud来对商品名称进行词云的分析。
二、代码实现
话不多说,直接上代码:
#数据分析
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.ticker import FuncFormatter
import re
import jieba
from wordcloud import WordCloud,STOPWORDS
from PIL import Image
import datetime def data_analysis(goods):
###数据处理
#读取数据
df=pd.read_csv(r'C:/Users/sunshine/Desktop/课件/图片/爬取的数据/' + '淘宝' + goods+'.csv')
#降序排列
df1=df.sort_values('sum_body',ignore_index=True)
#删除重复值
df2=df1.drop_duplicates()
#重置索引
df2.index = range(len(df2))
#用平均值替换缺失值
df3=df2.fillna(df2.mean())
#用上下四分位数处理异常数据
#确定正常数据的范围 上四分位数加上1.5倍分位差 下四分位数减1.5倍分位差 分位差是上四分位数减下四分位数 mean1=df3['sum_body'].quantile(q=0.25)
mean2=df3['sum_body'].quantile(q=0.75)
mean3=mean2-mean1
topnum=mean2+1.5*mean3
lownum=mean1-1.5*mean3 #判断是否需要处理异常值
#范围
#print((lownum['prices'],topnum['prices']))
# print((lownum,topnum)) #判断价格是否在范围之内 结果为存在超出正常范围的价格
# print('判断是否存在超出正常范围的价格:',any(df3['prices']>topnum['prices']))
# print('判断是否存在低于正常范围的价格:',any(df3['prices']<lownum['prices'])) #判断购买人数是否在正常范围 结果为存在超出正常范围的价格
# print('判断是否存在超出正常范围的购买人数:',any(df3['sum_body']>topnum))
# print('判断是否存在超出正常范围的购买人数:',any(df3['sum_body']<lownum)) # plt.boxplot(x=df3['sum_body'])
# plt.show()
# df3['prices'][df3['prices']<topnum] #价格替换
replace_value_prices=df3['prices'][df3['prices']<topnum].max()
df3.loc[df3['prices']>topnum,'prices']=replace_value_prices #购买人数替换
replace_value_sum_body=df3['sum_body'][df3['sum_body']<topnum].max()
df3.loc[df3['sum_body']>topnum,'sum_body']=replace_value_sum_body
# plt.boxplot(x=df3['sum_body'])
# plt.show() # 进行聚合分析
# 生成数据透视表 # 1、地域和价格
df3.groupby('loc')['prices'].mean() # 2、地区和店铺数量
df3['loc'].value_counts()
# 3、价格和销售额
# 4、店铺和销售额
# 5、价格和购买人数
df4=df3.groupby('shop_name').agg({'prices':np.mean,'sum_body':np.mean})
df4['sum_sales']=df4['prices']*df4['sum_body']
df5=pd.merge(df3,df4,how='left').fillna(method='ffill')
# print(df5)
# 6、地区和销量
df6=df5.groupby(['shop_name', 'loc']).agg({'prices': np.mean, 'sum_body': np.mean})
df7=df6.reset_index()
df8=df7.groupby('loc').sum().reset_index() '''
使用matplotlib画出饼状图、直方图频率分布图、散点图、柱状图、
'''
time=str(datetime.datetime.now().date()) #1、地区和销量的柱状图
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
plt.figure(figsize=(20,9))
x_data=df8['loc']
y_data=df8['sum_body']
plt.bar(x_data,y_data,color='b',width=1)
plt.xlabel('地区',fontsize=15)
plt.ylabel('销量',fontsize=15)
plt.title('不同地区的销量',fontdict={'fontsize':20})
plt.savefig(r'C:\Users\sunshine\Desktop\课件\图片\爬取的数据\数据分析\i'+time+'地区和销量柱状图.png')
plt.show()
plt.close()
#2、地区和店铺数量的直方图
plt.figure(figsize=(20,9))
df9=df3['loc'].value_counts().reset_index()
x_data=df9['index']
y_data=df9['loc']
plt.bar(range(0,len(x_data)),y_data,tick_label=x_data)
plt.xlabel('地区',fontsize=15)
plt.ylabel('店铺数量',fontsize=15)
plt.title('地区和店铺数量的关系',fontdict={'fontsize':20})
plt.savefig(r'C:\Users\sunshine\Desktop\课件\图片\爬取的数据\数据分析\i'+time+'地区和店铺数量直方图.png')
plt.show()
plt.close()
#3、价格和销售量的散点图
plt.figure()
x_data=df4['prices']
y_data=df4['sum_body']
plt.scatter(x_data,y_data,color='pink')
plt.xlabel('价格')
plt.ylabel('销量')
plt.title('价格和销量之间的关系')
plt.grid()
plt.savefig(r'C:\Users\sunshine\Desktop\课件\图片\爬取的数据\数据分析\i'+time+'价格和销量散点图.png')
plt.show()
plt.close()
#4、价格和销售额的散点图
#价格和销售额之间的散点图
plt.figure()
np.set_printoptions(suppress=True, precision=10, threshold=2000, linewidth=150)
pd.set_option('display.float_format',lambda x : '%.2f' % x)
x_data=df4['prices']
y_data=df4['sum_sales']
plt.scatter(x_data,y_data,color='purple')
def formatnum(x,pos):
return float(x)
formatter = FuncFormatter(formatnum)
# 设置坐标轴格式
plt.gca().yaxis.set_major_formatter(formatter)
plt.yticks()
plt.xlabel('价格')
plt.ylabel('销量')
plt.title('价格和销量额之间的关系')
plt.grid()
plt.savefig(r'C:\Users\sunshine\Desktop\课件\图片\爬取的数据\数据分析\i'+time+'价格和销量额散点图.png')
plt.show()
plt.close() #5、地区和店铺数量分布的饼状图
plt.figure(figsize=(10,8),dpi=150)
x_data=df9['index']
y_data=df9['loc']
plt.pie(y_data,labels=x_data,radius=1.2,autopct='%1.1f%%',pctdistance=0.6,textprops={'fontsize':10})
plt.title('店铺地区分布',fontdict={'fontsize':10},y=1.0)
plt.legend(loc=(1.1,0.1),fontsize=10)
plt.savefig(r'C:\Users\sunshine\Desktop\课件\图片\爬取的数据\数据分析\i'+time+'地区和店铺数量分布饼状图.png')
plt.show()
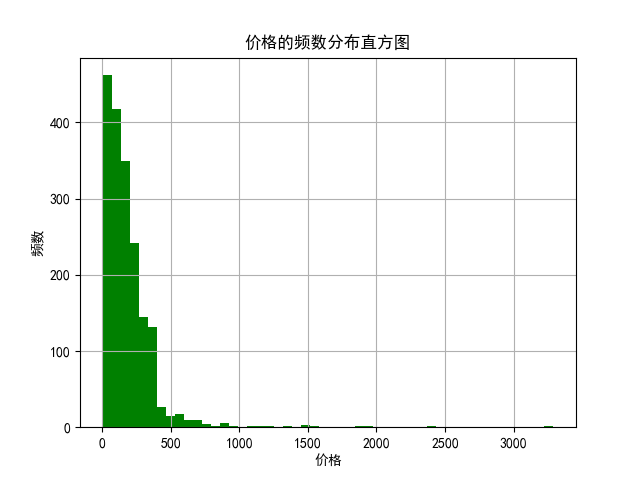
plt.close() #6、价格的频数分布直方图
plt.figure()
data=df3['prices']
plt.hist(data,bins=50,color='g')
plt.xlabel('价格')
plt.ylabel('频数')
plt.title('价格的频数分布直方图')
plt.grid()
plt.savefig(r'C:\Users\sunshine\Desktop\课件\图片\爬取的数据\数据分析\i'+time+'价格的频数分布直方图.png')
plt.show()
plt.close()
#7、关于店铺名称的词云
plt.figure(figsize=(8,8),dpi=100)
jieba.setLogLevel(jieba.logging.INFO)
#建立停用词
stop_words=set(STOPWORDS) with open(r"C:\Users\sunshine\Desktop\课件\图片\爬取的数据\stop_words.txt",'r',encoding='utf-8') as f:
stop_words.add(f.read())
#统计文件的读取成为字符串
data=df3['shop_name'].values
data="".join(data) #对统计文本进行分词处理
cut_list=jieba.lcut(data)
#对每一个分词进行处理
def fiter_word(words,stop_words):
num=re.search('\d+',words)
if num==None:
if words not in stop_words:
if len(words)>1:
return words
else:
pass
else:
pass
#对文本进行次数的统计
word_freq=dict()
for one in cut_list:
# print(list(one))
row=fiter_word(one,STOPWORDS)
if row:
word_freq[row]=word_freq.get(row,0)+1
# print(word_freq)
#使用图片背景
mask=np.array(Image.open(r'C:\Users\sunshine\Desktop\课件\图片\爬取的数据\背景.png'))
wc=WordCloud(font_path=r'C:\Windows\Fonts\simkai.ttf',background_color='white',
mask=mask,max_font_size=100,max_words=500,random_state=1,
scale=3,stopwords=stop_words)
wc.generate_from_frequencies(word_freq)
plt.imshow(wc,interpolation='bilinear')
plt.axis('off')
plt.savefig(r'C:\Users\sunshine\Desktop\课件\图片\爬取的数据\数据分析\i'+time+'店铺名称词云.png')
plt.show()
plt.close()
if __name__ == '__main__':
data_analysis(goods)
三、运行结果
1、地区和销量的柱状图
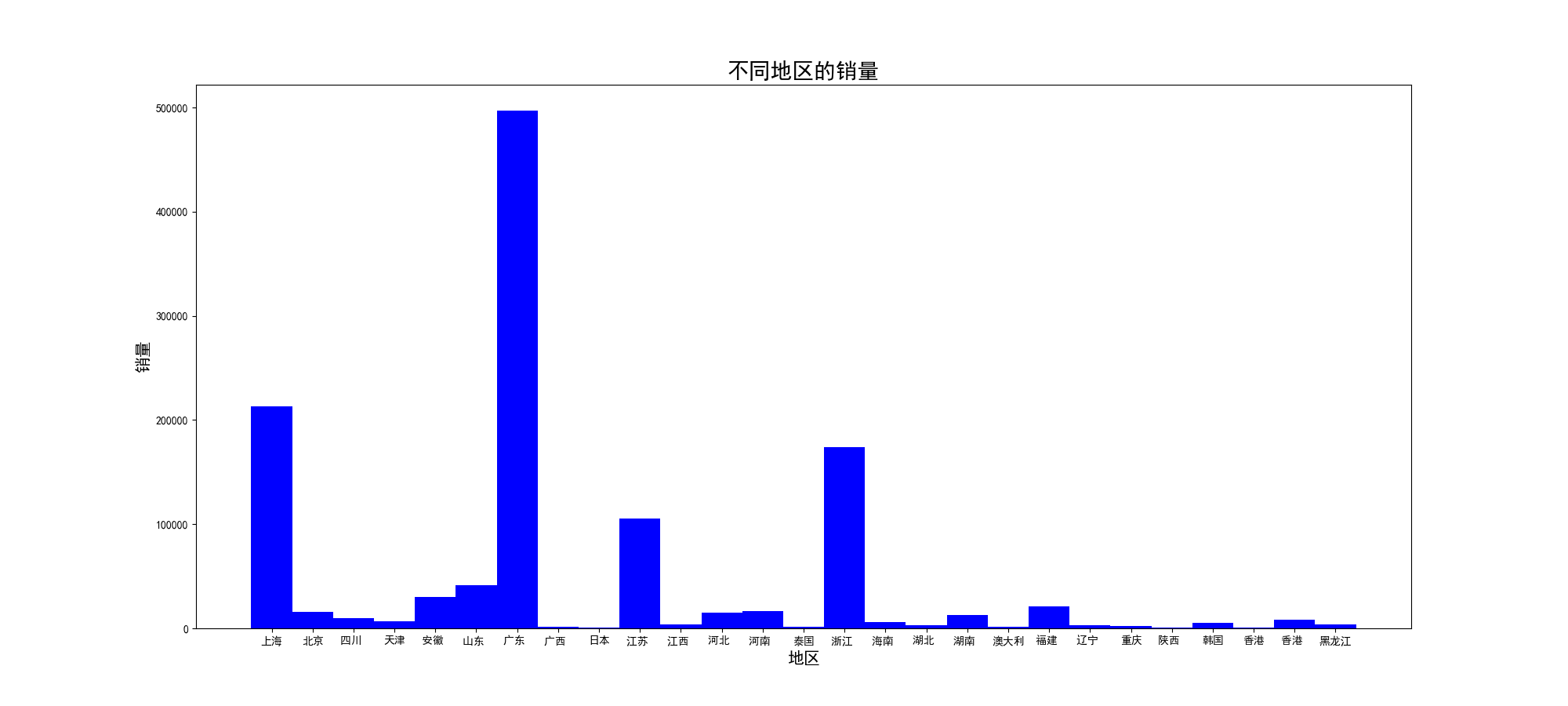
2、地区和店铺数量的直方图
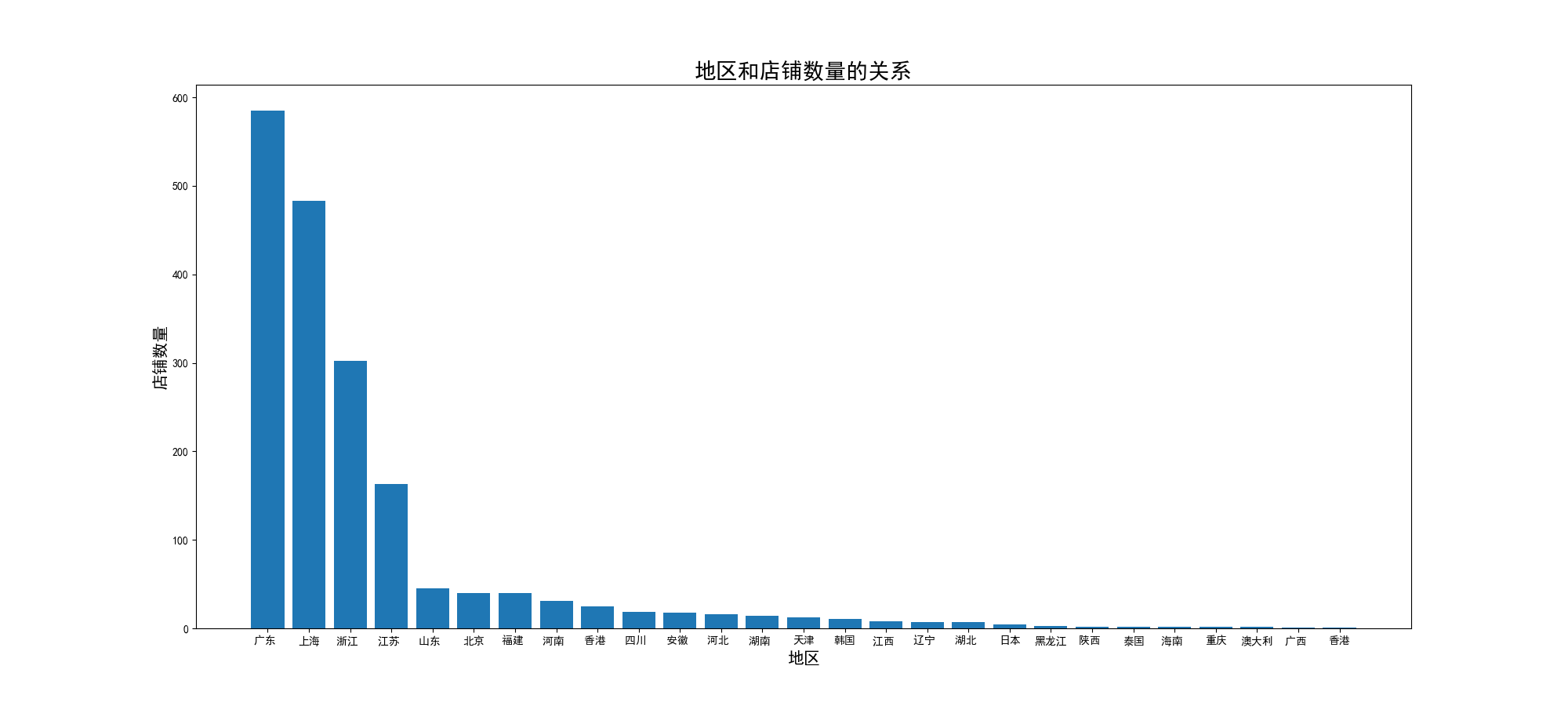
3、价格和销售量的散点图
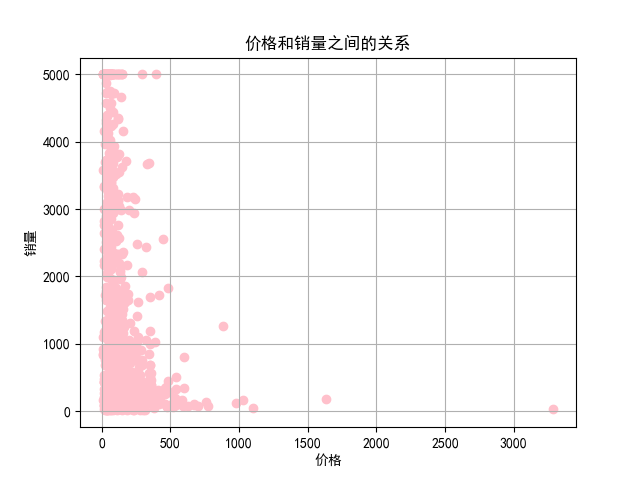
4、价格和销售额的散点图
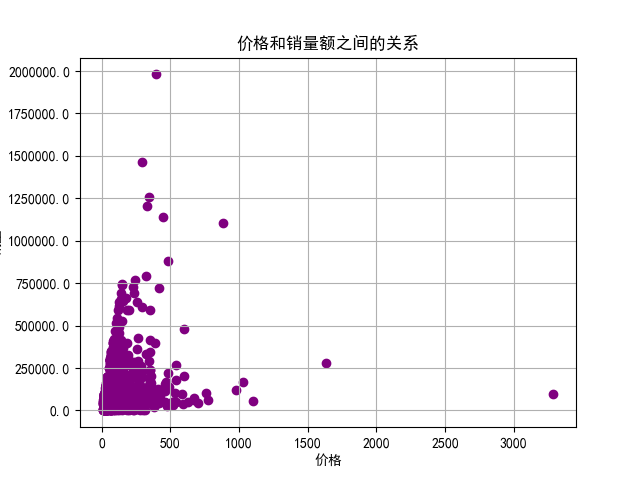
5、地区和店铺数量分布的饼状图

6、价格的频数分布直方图
7、关于店铺名称的词云

四、小结
当然这次是基于matplotlib实现的制作图表。但是却没有交互的功能。如果可以使用pygal库来进行的话,可以实现交互的功能,会更方便前端的展示。
使用pandas处理数据和matplotlib生成可视化图表的更多相关文章
- Python数据分析:手把手教你用Pandas生成可视化图表
大家都知道,Matplotlib 是众多 Python 可视化包的鼻祖,也是Python最常用的标准可视化库,其功能非常强大,同时也非常复杂,想要搞明白并非易事.但自从Python进入3.0时代以后, ...
- ELK之使用metricbeat收集系统数据及其他程序并生成可视化图表
将 Metricbeat 部署到您所有的 Linux.Windows 和 Mac 主机,并将它连接到 Elasticsearch 就大功告成啦:您可以获取系统级的 CPU 使用率.内存.文件系统.磁盘 ...
- ELK之使用filebeat收集系统数据及其他程序并生成可视化图表
当您要面对成百上千.甚至成千上万的服务器.虚拟机和容器生成的日志时,请告别 SSH 吧.Filebeat 将为您提供一种轻量型方法,用于转发和汇总日志与文件,让简单的事情不再繁杂. 1,安装fileb ...
- 使用可视化图表对 Webpack 2 的编译与打包进行统计分析
此文主要对使用可视化图表对 Webpack 2 的编译与打包进行统计分析进行了详细地讲解,供您更加直观地参考. 在之前更新的共十七章节中,我们陆续讲解了 Webpack 2 从配置到打包.压缩优化到调 ...
- JFreeChart与AJAX+JSON+ECharts两种处理方式生成热词统计可视化图表
本篇的思想:对HDFS获取的数据进行两种不同的可视化图表处理方式.第一种JFreeChar可视化处理生成图片文件查看.第二种AJAX+JSON+ECharts实现可视化图表,并呈现于浏览器上. 对 ...
- 动态可视化 数据可视化之魅D3,Processing,pandas数据分析,科学计算包Numpy,可视化包Matplotlib,Matlab语言可视化的工作,Matlab没有指针和引用是个大问题
动态可视化 数据可视化之魅D3,Processing,pandas数据分析,科学计算包Numpy,可视化包Matplotlib,Matlab语言可视化的工作,Matlab没有指针和引用是个大问题 D3 ...
- python requests抓取NBA球员数据,pandas进行数据分析,echarts进行可视化 (前言)
python requests抓取NBA球员数据,pandas进行数据分析,echarts进行可视化 (前言) 感觉要总结总结了,希望这次能写个系列文章分享分享心得,和大神们交流交流,提升提升. 因为 ...
- Python数据可视化之Matplotlib实现各种图表
数据分析就是将数据以各种图表的形式展现给领导,供领导做决策用,因此熟练掌握饼图.柱状图.线图等图表制作是一个数据分析师必备的技能.Python有两个比较出色的图表制作框架,分别是Matplotlib和 ...
- Python调用matplotlib实现交互式数据可视化图表案例
交互式的数据可视化图表是 New IT 新技术的一个应用方向,在过去,用户要在网页上查看数据,基本的实现方式就是在页面上显示一个表格出来,的而且确,用表格的方式来展示数据,显示的数据量会比较大,但是, ...
- Pandas系列(十二)-可视化详解
目录 1. 折线图 2. 柱状图 3. 直方图 4. 箱线图 5. 区域图 6. 散点图 7. 饼图六边形容器图 数据分析的结果不仅仅只是你来看的,更多的时候是给需求方或者老板来看的,为了更直观地看出 ...
随机推荐
- 基于 Apache Hudi 极致查询优化的探索实践
摘要:本文主要介绍 Presto 如何更好的利用 Hudi 的数据布局.索引信息来加速点查性能. 本文分享自华为云社区<华为云基于 Apache Hudi 极致查询优化的探索实践!>,作者 ...
- sql查数据库表中的条数
select count(*) from <>表名 例 select count(*) from user_info
- docker搭建个人云盘可道云kodbox
1.拉取kodbox镜像 (文章最后有自己编写yml文件可直接搭建) docker pull tznb/kodbox:1.15 2. 创建并启动kodbox docker run -d -it --n ...
- Nginx代理和动静分离
Nginx代理 微服务项目可能需要 Nginx来实现反向代理,用户请求 Nginx,随后 Nginx将请求转发至 Gateway网关,再由网关转至具体的微服务 一.动态代理 1.1 网关配置 针对使用 ...
- 通过linux-PAM实现禁止root用户登陆的方法
前言 在linux系统中,root账户是有全部管理权限的,一旦root账户密码外泄,对于服务器而言将是致命的威胁:出于安全考虑,通常会限制root账户的登陆,改为配置普通用户登陆服务器后su切换到ro ...
- PHP开启debug模式
我用的是lnmp一键集成环境 所以我的php.ini在/usr/local/php/ 把这个值改成从 Off 改成On 即可
- js中通过正则表达式验证邮箱是否合法
文章目录 1.效果展示 2.问题描述 3.代码实现 1.效果展示 2.问题描述 当用户在输入框输入邮箱后.点击验证邮箱按钮.系统给出提示信息. 3.代码实现 <!DOCTYPE html> ...
- C++之值传递&指针传递&引用传递详解
C++之值传递&指针传递&引用传递详解 目录 C++之值传递&指针传递&引用传递详解 1.函数基础 2.值传递 3.指针传递 4.引用传递 1.函数基础 一个函数由以下 ...
- jmeter中获取token和cookie
## 登录获取token 1.添加请求 1.1 输入接口中需要携带的参数的值 2.正则表达式提取器提取出值 3.输入token数据 "token":"(.+?)" ...
- 【React】学习笔记(二)——组件的生命周期、React脚手架使用
原教程视频:ttps://www.bilibili.com/video/BV1wy4y1D7JT?p=2&spm_id_from=pageDriver 目录 一.组件的生命周期 1.1.生命周 ...