循环码、卷积码及其python实现
摘要:本文介绍了循环码和卷积码两种编码方式,并且,作者给出了两种编码方式的编码译码的python实现
关键字:循环码,系统编码,卷积码,python,Viterbi算法
循环码的编码译码
设 \(C\) 是一个 \(q\) 元 \([n,n-r]\) 循环码,其生成多项式为\(g(x), \text{deg}(g(x))=r\)。显然,\(C\) 有 \(n-r\) 个信息位,\(r\) 个校验位。我们用 \(C\) 对信息源 \(V(n-r,q)\) 中的向量进行表示。
对任意信息源向量 \(a_0a_1\cdots a_{n-r-1}\in V(n-r,q)\),循环码有两种编码思路:
非系统的编码方法
构造信息多项式
\]
该信息源的多项式对应于循环码 \(C\) 的一个码字
\]
系统编码
构造信息多项式
\]
显然当 \(a_0,a_1,\cdots,a_{n-r-1}\) 不全为零时。\(r\lt\text{deg}(\bar{a}(x))=n-1\)。用 \(g(x)\) 去除 \(\bar{a}(x)\),得到
\]
其中 \(\text{deg}(r(x))\lt\text{deg}(g(x))=r\),信息源多项式被编码为C中的码字
\]
可以看到,\(\bar{a}(x)\) 和 \(r(x)\) ,没有相同的项,所以这种编码方式为系统编码。也即,如果将 \(c(x)\) 中的 \(x\) 的项按生降次排序,则码字前 \(n-r\) 位就是信息位,后 \(r\) 位是校验位。
例子:二元(7,4)循环码
已知 \(C\) 是一个二元 \((7,4)\) 循环码,生成多项式为 \(g(x)=x^3+x+1\)。
\(0101\in V(4,2)\) 是代编码的信息向量
非系统编码(升幂排序,信息向量为 \(x+x^3\))
c(x)&=a(x)g(x) \\
&=(x+x^3)(1+x+x^3) \\
&=x+x^2+x^3+x^6
\end{aligned}
\]
也即,\(0101\in V(4,2)\) 被编码为\(0111001\in V(7,2)\)
系统编码(降幂排序,信息向量为 \(x^5+x^3\))
&\bar{a}(x)=x^5+x^3=x^2(x^3+x+1)=x^2 \\
\end{aligned}
\]
c(x)&=\bar{a}(x)-r(x) \\
&=(x^5+x^3)-x^2 \\
&=x^5+x^3+x^2
\end{aligned}
\]
也就是,\(0101\in V(4,2)\) 被编码为\(0101100\in V(7,2)\)
一般而言,系统码解码速度相比非系统编码更快。接下来我们对上述例子进一步探索。
系统码的生成矩阵
考虑 \(F_2[x]/\langle x^7-1\rangle\) 中阶数大于3的基。
\]
也即,\(1000\in V(4,2)\) 被编码为\(1000101\in V(7,2)\)。
\]
也即,\(0100\in V(4,2)\) 被编码为\(0100111\in V(7,2)\)。
\]
也即,\(0010\in V(4,2)\) 被编码为\(0010110\in V(7,2)\)。
\]
也即,\(0001\in V(4,2)\) 被编码为\(0001011\in V(7,2)\)。
所以生成多项式为 \(g(x)=x^3+x+1\) 的 \((7,4)\) 循环码C的生成矩阵为
\begin{bmatrix}
1 & 0 & 0 & 0 & \vdots &1&0&1 \\
0 & 1 & 0 & 0 & \vdots &1&1&1 \\
0 & 0 & 1 & 0 & \vdots &1&1&0 \\
0 & 0 & 0 & 1 & \vdots &0&1&1 \\
\end{bmatrix}
\]
循环码的译码
首先我们不加证明的引入循环矩阵的校验多项式核校验矩阵的知识。
定义 设 \(C\subset R_n\) 是一个 \(q\) 元 \([n,n-r]\) 循环码,其生成多项式为 \(g(x)\),校验多项式定义为
\]
定理 设 \(C\subset R_n\) 是一个 \(q\) 元 \([n,n-r]\) 循环码,其生成多项式为 \(g(x)\),校验多项式为 \(h(x)\),则对任意 \(c(x)\in R_n(x)\),\(c(x)\) 是 \(C\) 的一个码字当且仅当 \(c(x)h(x)=0\)。
定理 设\(C\subset R_n\) 是一个 \(q\) 元 \([n,n-r]\) 循环码,其生成多项式为 \(g(x)\),校验多项式记为
\]
且其校验矩阵为
\begin{pmatrix}
h_{n-r} & h_{n-r-1} & h_{n-r-2} & \cdots & h_0 & 0 & 0 & \cdots & 0 \\
0 & h_{n-r} & h_{n-r-1} & h_{n-r-2} & \cdots & h_0 & 0 & \cdots & 0 \\
0 & 0 & h_{n-r} & h_{n-r-1} & h_{n-r-2} & \cdots & h_0 & \cdots & 0 \\
\vdots & \vdots & \vdots & & \vdots & \vdots & \vdots & & \vdots \\
0 & 0 & 0 & \cdots & h_{n-r} & h_{n-r-1} & h_{n-r-2} & \cdots &h_0\\
\end{pmatrix}
\]
所以可得,对于已知 \(C\) 是一个二元 \((7,4)\) 循环码,生成多项式为 \(g(x)=x^3+x+1\),校验多项式为 \(h(x)=x^4+x^3+x^2+1\),校验矩阵为
\begin{pmatrix}
1 & 1 & 1 & 0 & 1 & 0 & 0 \\
0 & 1 & 1 & 1 & 0 & 1 & 0 \\
0 & 0 & 1 & 1 & 1 & 0 & 1 \\
\end{pmatrix}
\]
因为是系统编码,所以,如果将 \(c(x)\) 中的 \(x\) 的项按降幂次排序,则码字前 \(n-r\) 位就是信息位,后 \(r\) 位是校验位。也就是,如果不出错,则接受的的码字的前 4 个''字母''(信息比特)就是对方传输的信息。
但是考虑到一般情形,二元循环码解码流程如下
- 根据码字 \(C\) 及其生成多项式,构造校验多项式,进一步得到校验矩阵 \(H\)
- 接收到向量 \(y\),计算其伴随 \(S(y)=yH^{T}\)
- 若 \(S(y)\) 等于零,我们则认为传输过程没有发生错误,\(y\) 就是发送码字
- 若 \(S(y)\) 不等于零,则 \(S(y)\) 可表示为 \(b(H_i)^T\),其中 \(0\ne b\in GF(q),1\le i\le n\)。这时我们认为 \(y\) 中的第 \(i\) 个分量发生错误,\(y\) 被译为码字 \(y-\alpha_i\),其中 \(\alpha_i\) 中的第 \(i\) 个分量为 \(b\),其余分量为零。
对于上述码字,若接收到 \(y=0110010\),\(S(y)=yH^T=011=1*H_4\),所以发送码字为 \(0111010\),也即代表信息源 \(0111\)。
对于上述循环码,python程序实现如下
# (7,4)二元循环码
# 生成多项式 g(x)= x^3+x+1
import numpy as np
# 生成矩阵
G = np.array([
[1,0,0,0,1,0,1],
[0,1,0,0,1,1,1],
[0,0,1,0,1,1,0],
[0,0,0,1,0,1,1]
])
# 校验矩阵
H = np.array([
[1,1,1,0,1,0,0],
[0,1,1,1,0,1,0],
[0,0,1,1,1,0,1]
])
# 编码
def encode_cyclic(x):
if not len(x) == 4:
print("请输入4位信息比特")
return
y = np.dot(x,G)
print(x,"编码为:",y)
return y
# 译码,过程与汉明码一致
def decode_cyclic(y):
if not len(y) == 7:
print("请输入7位信息比特")
return
x_tmp = np.dot(y,H.T)%2
if (x_tmp!=0).any():
for i in range(H.shape[1]):
if (x_tmp==H[:,i]).all():
y[i] = (y[i]-1)%2
break
x = y[0:4]
print(y,"解码为:",x)
return x
# 测试
if __name__ == '__main__':
y = [1,0,0,0,1,0,1]
decode_cyclic(y)
x=[1,0,0,0]
encode_cyclic(x)
卷积码
卷积码是信道编码技术的一种,属于一种纠错码。最早由1955年Elias最早提出,目的是为了减少在信源消息在信道传输过程中产生的差错,增加接收端译码的准确性。
卷积码的生成方式是将待传输的信息序列通过线性有限状态移位寄存器,也就是在卷积码的编码过程中,需要输入消息源与编码器中的冲激响应做卷积。具体说来,在任意时段,编码器的 \(n\) 个输出不仅与此时段的 \(k\) 个输入有关,还与寄存器中前 \(m\) 个输入有关。卷积码的纠错能力随着 \(m\) 的增加而增大,同时差错率随着 \(m\) 的增加而成指数下降。
参数 \((n,k,m)\) 解释如下:
- \(m\) :约束长度,即位移寄存器的级数(个数),每级(每个)包含 \(k\) 个参数(\(k\) 个输入)。
- \(k\) :信息码位的数目,是卷积编码器的每级输入的比特数目
- \(n\) :k位信息码对应编码后的输出比特数,它与 \(mk\) 个输入比特相关
- 编码速率: \(R_c=k/n\)
由此看来,卷积码编码的结果与之前的输入有关,编码具有记忆性,是非分组码。而分组码的编码只于当前输入有关,编码不具有记忆性。
1967年Viterbi提出基于动态规划的最大似然Viterbi译码法。
卷积码编码
如下图为:(2,1,2)卷积码的编码示意图
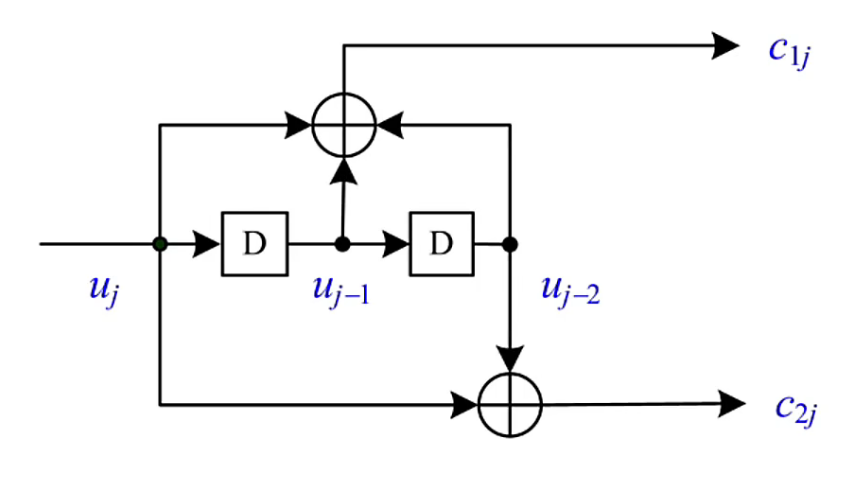
- 1位输入,2位输出,2个位移寄存器
- 两路生成多项式为 \(x^2+x+1, x^2+1\)(分别对应 \(c_{1j}\) 和 \(c_{2j}\) )
其中,\(j\) 表示时序,
c_{1j} &= u_j+D_1+D_2 = u_j+u_{j-1}+u_{j-2} \\
c_{2j} &= u_j + D_2 = u_j + u_{j-2}
\end{aligned}
\]
为了后续说明卷积码中重要的“状态”概念,现引入记号(仅以2个输出为例,\(n\) 个输出可以此类推):
- \(s_j=(u_j,u_{j-1})\) 表示为卷积码在 \(j\) 时刻的到达状态
- \(s_{j-1}=(u_{j-1},u_{j-2})\) 表示为卷积码在 \(j\) 时刻的出发状态
所以不难看出(2,1,2)卷积码由 4 种可能的状态,为 \((00),(01),(10),(11)\)。
对于状态我们有如下引理
引理
给定出发状态 \(s_{j-1}\) 和当前的输入 \(u_j\),可以确定出到达状态 \(s_j\) 以及当前输出 \(c_{1_j}c_{2j}\)
给定状态的变化序列 \(s_0s_1s_2\cdots\),将能确定出输入序列 \(u_0u_1u_2\cdots\) 以及输出序列\(c_{10}c{20}c_{11}c_{21}\cdots\)
注:我们默认初始状态\(s_{-1}=0\)
从上述描述中,不难看出,卷积码的全部信息都包含在状态变化序列中。
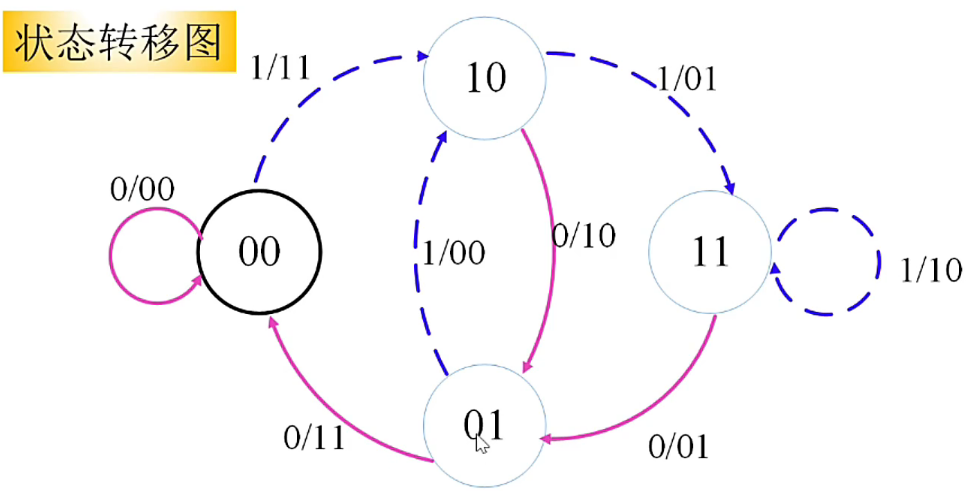
- 红线代表输入信息为0,蓝线表示输入信息为1。线旁的数字表示对应状态时候的机器的输出
- 从每个状态出发,可达到两个不同状态。每个到达状态都有两个出发状态
- 输入的信息比特一定等于到达状态的第1位
下图为“格图”,
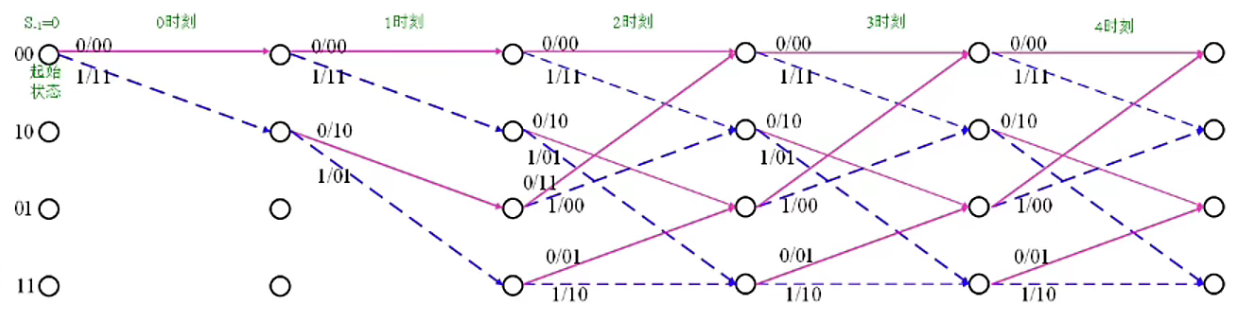
格图结构更加紧凑,代表着时间的移动,也即,信息比特在不断输入。
从上图中,我们可得出,若输入序列是 \(10110\),则输出序列为 \(11 10 00 01 01\)。
代码示例如下
# (2,1,2)卷积码
# 卷积编码
def encode_conv(x):
# 存储编码信息
y = []
# 两个寄存器u_1 u_2初始化为0
u_2 = 0
u_1 = 0
for j in x:
c_1 = (j + u_1 + u_2)%2
c_2 = (j+u_2)%2
y.append(c_1)
y.append(c_2)
# 更新寄存器
u_2 = u_1
u_1 = j
print(x,"编码为:",y)
return y
# 测试代码
if __name__ == '__main__':
encode_conv([1,0,1,1,0])
卷积码的译码
我们注意到
- 任何一个编码器输出序列,都对应着树图(格图)上唯一的一条路径
- 译码器要根据接收序列,找出这条路径
- 按照最大似然(Maximum Likelihood )译码原则,译码器应该在图的所有路径中找出这样一条,其编码输出序列与译码器接收的序列之间码距最小。
分支度量(以(2,1,2)卷积码为例)
设 \(j\) 时刻接受的比特是 \(y_{1j}y_{2j}\)
- 网格图在 \(j\ge2\) 时刻有8种不同的分支(相同分支:出发状态和到达状态相同),每个分支对应两个比特编码输出 \(c_{1j}c_{2j}\)
- 这两个比特编码输出与接收比特之间的汉明距离称为该分支的分支度量
例如从第 \(i\) 步到第 \((i+1)\) 步接收的比特位 \(01\)
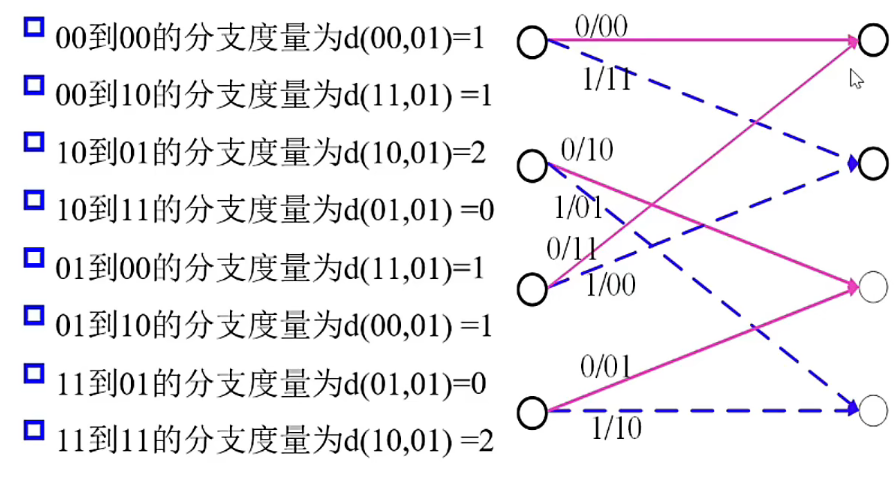
累计度量
- 从起始状态到 \(j\) 时刻的某个状态路径是由各个树枝连成的,这些树枝的分支度量之和称为该路径的累积度量
- 在上述定义下,某个路径的累积度量实际是该路径与接收序列的汉明距离
- 最大似然(Maximum Likelihood,ML)译码就是要寻找到 \(j\) 时刻累积度量最小的路径。
如下为输入比特:01 11 01 的格图。
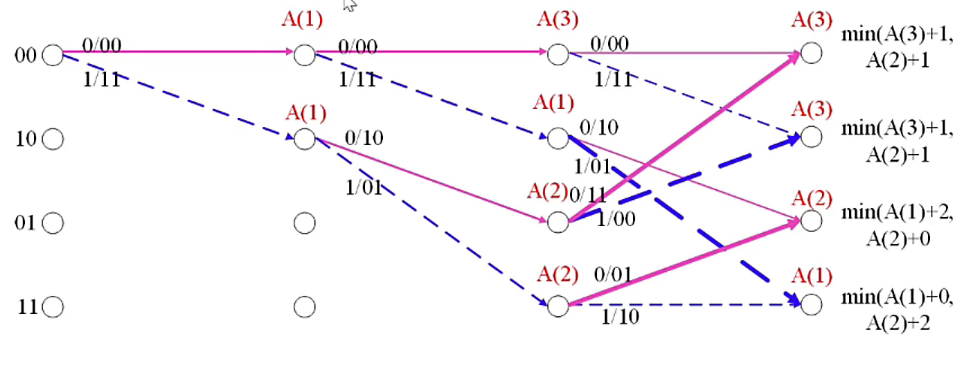
其中 \(A(i)\) 表示从开始时刻到当前时刻的累积度量为 \(i\)
Viterbi译码
- 最大似然序列译码要求序列有限,因此对于卷积码来说,要求能截尾。基于最大似然译码(ML译码)准则,寻找从起点到终点的极大似然路径,即从起点到终点累计度量最小的路径。
- 截尾:在信息序列输入完成以后,利用输入一些特定的比特,使 \(M\) 个状态的各残留路径可以到达某一已知状态(一般是全零状态)。这样就变成只有一条残留路径,这就是最大似然序列。
- Viterrbi译码核心思想:进行累加-比较-选择,基于计算,并产生新的幸存路径。
对于接收序列为:01 11 01 11 00
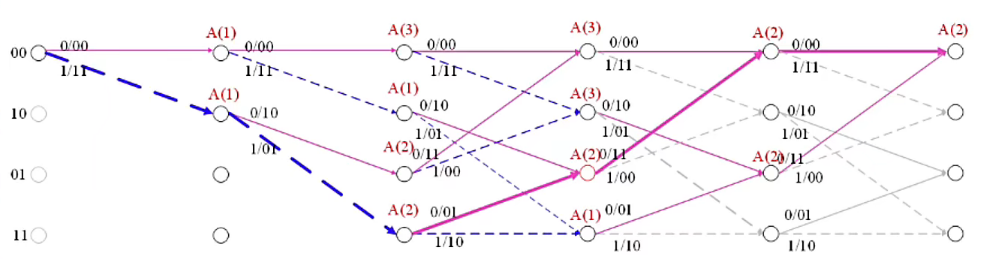
通过上述路径分析图可得,经过最大似然译码分析后,译码序列为:11000
Viterbi译码python实现如下:
def decode_conv(y):
# shape = (4,len(y)/2)
# 初始化
score_list = np.array([[ float('inf') for i in range(int(len(y)/2)+1)] for i in range(4)])
for i in range(4):
score_list[i][0]=0
# 记录回溯路径
trace_back_list = []
# 每个阶段的回溯块
trace_block = []
# 4种状态 0-3分别对应['00','01','10','11']
states = ['00','01','10','11']
# 根据不同 状态 和 输入 编码信息
def encode_with_state(x,state):
# 编码后的输出
y = []
u_1 = 0 if state<=1 else 1
u_2 = state%2
c_1 = (x + u_1 + u_2)%2
c_2 = (x + u_2)%2
y.append(c_1)
y.append(c_2)
return y
# 计算汉明距离
def hamming_dist(y1,y2):
dist = (y1[0]-y2[0])%2 + (y1[1]-y2[1])%2
return dist
# 根据当前状态now_state和输入信息比特input,算出下一个状态
def state_transfer(input,now_state):
u_1 = int(states[now_state][0])
next_state = f'{input}{u_1}'
return states.index(next_state)
# 根据不同初始时刻更新参数
# 也即指定状态为 state 时的参数更新
# y_block 为 y 的一部分, shape=(2,)
# pre_state 表示当前要处理的状态
# index 指定需要处理的时刻
def update_with_state(y_block,pre_state,index):
# 输入的是 0
encode_0 = encode_with_state(0,pre_state)
next_state_0 = state_transfer(0,pre_state)
score_0 = hamming_dist(y_block,encode_0)
# 输入为0,且需要更新
if score_list[pre_state][index]+score_0<score_list[next_state_0][index+1]:
score_list[next_state_0][index+1] = score_list[pre_state][index]+score_0
trace_block[next_state_0][0] = pre_state
trace_block[next_state_0][1] = 0
# 输入的是 1
encode_1 = encode_with_state(1,pre_state)
next_state_1 = state_transfer(1,pre_state)
score_1 = hamming_dist(y_block,encode_1)
# 输入为1,且需要更新
if score_list[pre_state][index]+score_1<score_list[next_state_1][index+1]:
score_list[next_state_1][index+1] = score_list[pre_state][index]+score_1
trace_block[next_state_1][0] = pre_state
trace_block[next_state_1][1] = 1
if pre_state==3 or index ==0:
trace_back_list.append(trace_block)
# 默认寄存器初始为 00。也即,开始时刻,默认状态为00
# 开始第一个 y_block 的更新
y_block = y[0:2]
trace_block = [[-1,-1] for i in range(4)]
update_with_state(y_block=y_block,pre_state=0,index=0)
# 开始之后的 y_block 更新
for index in range(2,int(len(y)),2):
y_block = y[index:index+2]
for state in range(len(states)):
if state == 0:
trace_block = [[-1,-1] for i in range(4)]
update_with_state(y_block=y_block,pre_state=state,index=int(index/2))
# 完成前向过程,开始回溯
# state_trace_index 表示 开始回溯的状态是啥
state_trace_index = np.argmin(score_list[:,-1])
# 记录原编码信息
x = []
for trace in range(len(trace_back_list)-1,-1,-1):
x.append(trace_back_list[trace][state_trace_index][1])
state_trace_index = trace_back_list[trace][state_trace_index][0]
x = list(reversed(x))
print(y,"解码为:",x)
return x
# 测试代码
if __name__ == '__main__':
# 对应 1 1 0 0 0
decode_conv([0,1,1,1,0,1,1,1,0,0])
参考
循环码、卷积码及其python实现的更多相关文章
- Python中的多进程与多线程(一)
一.背景 最近在Azkaban的测试工作中,需要在测试环境下模拟线上的调度场景进行稳定性测试.故而重操python旧业,通过python编写脚本来构造类似线上的调度场景.在脚本编写过程中,碰到这样一个 ...
- Python高手之路【六】python基础之字符串格式化
Python的字符串格式化有两种方式: 百分号方式.format方式 百分号的方式相对来说比较老,而format方式则是比较先进的方式,企图替换古老的方式,目前两者并存.[PEP-3101] This ...
- Python 小而美的函数
python提供了一些有趣且实用的函数,如any all zip,这些函数能够大幅简化我们得代码,可以更优雅的处理可迭代的对象,同时使用的时候也得注意一些情况 any any(iterable) ...
- JavaScript之父Brendan Eich,Clojure 创建者Rich Hickey,Python创建者Van Rossum等编程大牛对程序员的职业建议
软件开发是现时很火的职业.据美国劳动局发布的一项统计数据显示,从2014年至2024年,美国就业市场对开发人员的需求量将增长17%,而这个增长率比起所有职业的平均需求量高出了7%.很多人年轻人会选择编 ...
- 可爱的豆子——使用Beans思想让Python代码更易维护
title: 可爱的豆子--使用Beans思想让Python代码更易维护 toc: false comments: true date: 2016-06-19 21:43:33 tags: [Pyth ...
- 使用Python保存屏幕截图(不使用PIL)
起因 在极客学院讲授<使用Python编写远程控制程序>的课程中,涉及到查看被控制电脑屏幕截图的功能. 如果使用PIL,这个需求只需要三行代码: from PIL import Image ...
- Python编码记录
字节流和字符串 当使用Python定义一个字符串时,实际会存储一个字节串: "abc"--[97][98][99] python2.x默认会把所有的字符串当做ASCII码来对待,但 ...
- Apache执行Python脚本
由于经常需要到服务器上执行些命令,有些命令懒得敲,就准备写点脚本直接浏览器调用就好了,比如这样: 因为线上有现成的Apache,就直接放它里面了,当然访问安全要设置,我似乎别的随笔里写了安全问题,这里 ...
- python开发编译器
引言 最近刚刚用python写完了一个解析protobuf文件的简单编译器,深感ply实现词法分析和语法分析的简洁方便.乘着余热未过,头脑清醒,记下一点总结和心得,方便各位pythoner参考使用. ...
随机推荐
- linux目录结构知识
1.系统目录结构介绍 1.目录结构特点 linux系统中的目录一切从根开始. Linux系统中的目录结构拥有层次. Linux系统中的目录需要挂载使用. 2.目录挂载初识 挂载的命令:mount mo ...
- python入门基础—安装
说明:0基础,那就先练习python语言基础知识,等基础知识牢固了,再对各开发平台分别进行介绍.这里只介绍两个简单而又容易搭建开发平台Anaconda和pycharm Anaconda是一个开源的Py ...
- Java学习day7
Java继承不同与c++,格式为: public class 子类名 extends 父类名{ 语句体; } 继承提高了代码的复用性与维护性 在子类方法中访问一个变量时,首先在子类局部范围查找,其次到 ...
- Nuxt 的介绍与安装
Nuxt.js(一.介绍与安装) 1.为什么使用Nuxt 渐进式Vue.js框架给前后端分离带来无限的乐趣,越来越多的程序员选择Vue.在我们使用Vue框架的过程中不免会出现以下的一些问题: 如何更好 ...
- client 系列
定义 : client翻译过来就是客户端,我们使用client系列的相关属性来获取元素可视区的相关信息.通过client系列的相关属性可以动态的得到该元素的边框大小.元素大小等.
- python基础练习题(题目 模仿静态变量的用法)
day27 --------------------------------------------------------------- 实例041:类的方法与变量 题目 模仿静态变量的用法. 程序 ...
- Nginx下载文件指定文件名称
配置 location ^~/TEMP/ { alias/share/files/; if ($request_uri ~* ^.*\/(.*)\.(txt|doc|pdf|rar|gz|zip|do ...
- spring boot的配置文件
1.SpringBootApplication是标志启动类,启动后可以把这个类所在的包资源发布到服务器,不用再启动tomcat 2.利用spring boot工程可以和以前一样直接在Controlll ...
- 4.26JMetre分离数据、响应断言、动态参数、响应管理
修改 查询 默认查询 断言: 1.JSON断言 2.响应断言 :实际返回的值是否包含期望的值 参数化 相同的测试步骤,不同的测试数据.比如针对测试平台,使用不同的用户登陆进去来验证产品管理的业务. 在 ...
- 超越OpenCV速度的MorphologyEx函数实现(特别是对于二值图,速度是CV的4倍左右)。
最近研究了一下opencv的 MorphologyEx这个函数的替代功能, 他主要的特点是支持任意形状的腐蚀膨胀,对于灰度图,速度基本和CV的一致,但是 CV没有针对二值图做特殊处理,因此,这个函数对 ...