Longformer详解——从Self-Attention说开去
1.Longformer的应用场景
为了理解Longformer的原理,我们最好首先从为何需要使用Longformer开始说起。(这里默认各位已经对Self Attention等基础知识有一定的了解)
我们以一个简单的场景为例:

在这个例子中,我们共有六个Token,每个Token的维度是768维,当我们对这几个Token进行处理,得到的Q/K/V如下所示:
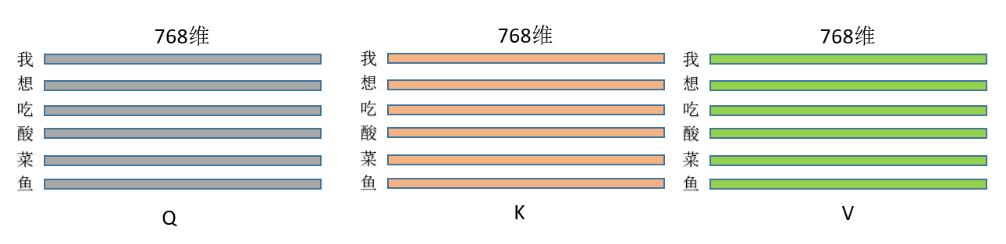
有了Q/K/V之后,下一步就可以计算每个Token对应的Attention:
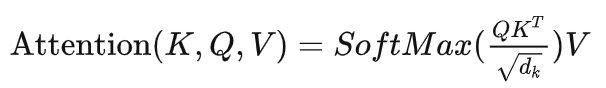
注意,Q乘以K的转置可以很形象地表示为下面这张图:
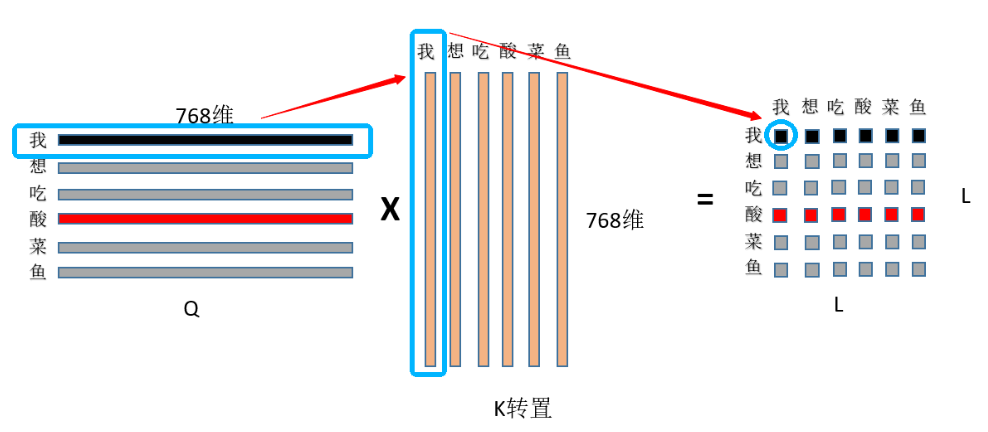
换言之,我们在Self Attention中,通过前面这一系列操作,得到的是一个(Token_size, Token_size)的矩阵。这里我们只有六个Token,一旦我们需要处理较长的文本,那么就会带来巨大的计算量。
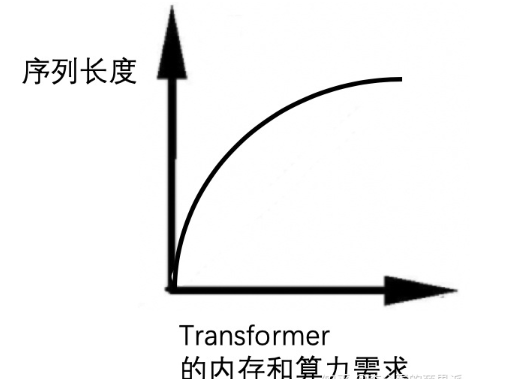
于是,为了解决这一困境,并使得Transformer能够用于较长的文本,Longformer的作者提出了下面这几种特殊的attention机制,这便是Longformer的核心内容。
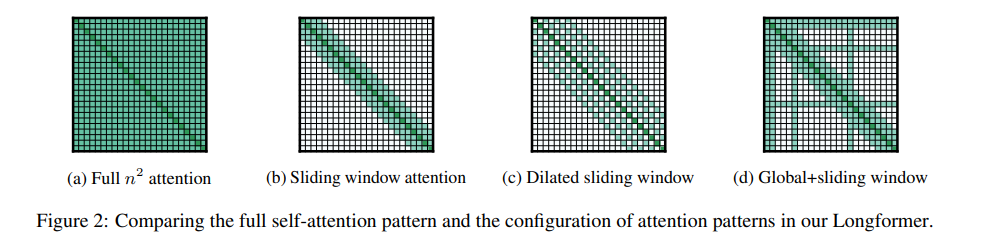
2.Longformer的核心内容
书接上文,Longformer的核心机制其实就是上面提到的三种attention窗口:
下面我们对这三种窗口进行一一介绍:
a.滑动窗口注意力
这种注意力机制不妨类比为卷积核,每一个卷积核的大小就是我们的感受野。总之,如果我们仔细观察的话,不难发现,这种方法的实质就是设定了一个固定大小的窗口\(ω\),它规定了序列中的每个Token都只能够看到\(ω\)个相邻的Token,其左右两侧各能看到\(\frac{1}{2}ω\)个Token(图中的例子,\(ω=6\)),这样一来,时间复杂度就由原来的\(O(n×n)\)变为了\(O(n×ω)\),当然,\(ω<<n\)。当然,我们无需担心这种设定无法建立整个序列的语义信息,因为transformer模型结构本身是层层叠加的结构,模型高层相比底层具有更宽广的感受野,自然能够能够看到更多的信息,因此它有能力去建模融合全部序列信息的全局表示,就行CNN那样。
通过这种设定Longformer能够在建模质量和效率之间进行一个比较好的折中。
b.膨胀滑动窗口注意力
这种注意力机制和上一种有什么区别呢?
答案很明显,它膨胀了。
好,我们来看下一个注意力机制(开玩笑的:D)
这种注意力窗口其实是为了弥补上一种窗口所造成的长度缺失,在不增加时间复杂度的前提下,我们会在两个Token之间设置一个大小为\(d\)的空隙。那么感受野的范围就可以扩展到\(d × ω\)。(以图中为例,\(d = 1, ω=6\))。
作者在文中提到,在进行Multi-Head Self-Attention时,在某些Head上不设置Dilated Sliding Window以让模型聚焦在局部上下文,在某些Head上设置Dilated Sliding Window以让模型聚焦在更长的上下文序列,这样能够提高模型表现。
c.全局注意力
这是重头戏。
首先,这是一个颇具迷惑性的名字,这里的全局只是部分的全局,我们在这里只设定某些特定的Token能够看到其余所有的Token,而对于另外一些不是太重要的Token,我们还是采取滑动窗口注意力。注意!这里“特定的Token” 会随着任务的不同而变化,打个比方,对于分类任务,带有全局视角的token就是“CLS”;而对于QA任务,那么带有全局视角的token就是Question中所包含的这些token。
之所以需要提出这种注意力机制,是因为这之前的两种变体无法完全适应task-specific的任务。
换言之,这种注意力机制的实质就是,将特殊位置的token“暴露”给其它的token。(等等,黑暗森林!?三体人狂喜)
Longformer的实际效果
a.Longformer在减少计算量这一方面的效果
Longformer的作者在论文中对三种Longformer的实现方式与Self-attention进行了对比:
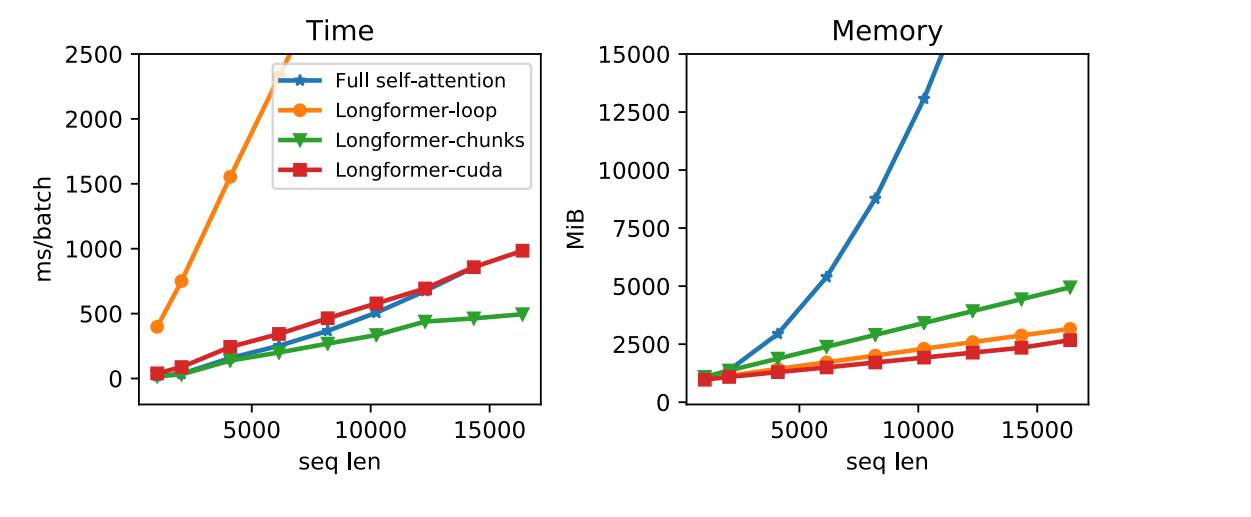
Longformer-loop是一种Pytorch实现,它支持膨胀滑动窗口
Longformer-chunks不支持膨胀滑动窗口,但计算速度很快
Longformer-cuda则是作者使用TVM实现的CUDA内核方法
左图是计算时间的对比,右图是计算所需要的内存量对比,本着男左女右,女士优先的原则,我们先看右边这幅图。可以看出,在序列长度较长的情况下,Longformer确实可以做到减少计算量的效果。但是,左图中的计算时间也可以看出,尽管Longformer减少了计算所需的内存,但计算时间并没有比一般的Self-Attention快多少,尤其是Longformer-loop,即使序列长度不长,但它还是给出了一个令人叹为观止的计算时间,这可太“酷”了。
b.Longformer在不同数据集上的实验结果
b.1.在text8与enwiki8两个字符级任务上的实验
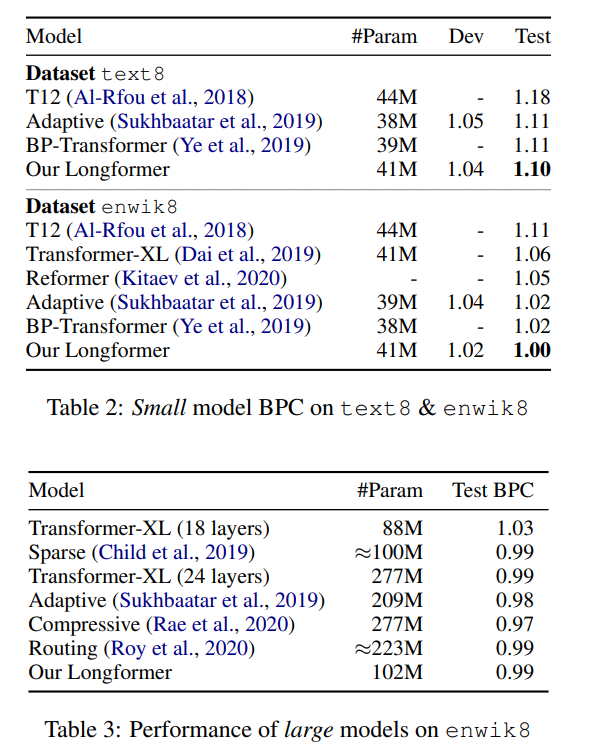
(这里的测试指标是BPC,BPC越小,就代表性能越好)
此外,在这个实验中,作者还使用了两种不同大小的模型:
small model:12 layers, 512 hidden size
large model:30 layers, 512 hidden size
在小的模型上,long former比其他模型都要好。这也证明了这个模型的有效性。
在大的模型上,比18层的transformerxl要好,跟第二个和第三个齐平,不如第四、五两个。但作者说明,这两个模型并不适用于pretrain-finetune的模式。
b.2.Pretraining and Finetuning
本文的预训练使用的同样是MLM,并且是在RoBERTa的checkpoint后继续训练。
在所有layer上使用512window size的滑动窗口attention,这么设置是为了与RoBERTa的seq len相匹配。
为了支持长文本,作者添加了额外的position embedding到4096的大小,此外,为了利用RoBERTa的权重,作者通过多次复制其512个位置嵌入来对其进行初始化。
下面这个表中展示了预训练使用的数据集。
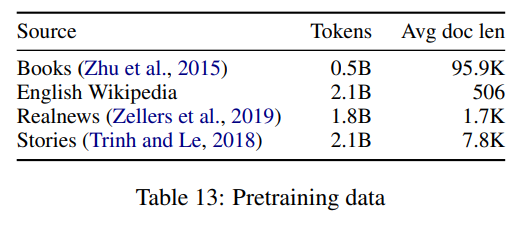
而下表是Longformer在具体的下游任务上的训练结果与RoBERTa的一个对比:

其中QA任务中,在问题和候选答案的位置使用全局attention。
共指消解任务上没有使用全局attention。
文本分类任务中,在[CLS]标签上用了全局attention。
可以看出,所有结果都是优于RoBERTa的。
当然,结果仅供参考,具体任务具体分析,实践才能出真知。
最后附上我本人使用的Longformer中文预训练模型地址
https://huggingface.co/ValkyriaLenneth/longformer_zh
Longformer详解——从Self-Attention说开去的更多相关文章
- Transform详解(超详细) Attention is all you need论文
一.背景 自从Attention机制在提出 之后,加入Attention的Seq2 Seq模型在各个任务上都有了提升,所以现在的seq2seq模型指的都是结合rnn和attention的模型.传统的基 ...
- Java面试题详解四:==和equals的去别
一,功能 1.对于== 作用于基本数据类型的变量,比较的存储的值是否相等, 作用于引用类型的变量,比较的是其所指向的对象的地址是否相同(即是否是同一个对象) 2.对于equals Object的equ ...
- Attention is all you need 论文详解(转)
一.背景 自从Attention机制在提出之后,加入Attention的Seq2Seq模型在各个任务上都有了提升,所以现在的seq2seq模型指的都是结合rnn和attention的模型.传统的基于R ...
- Android开发之InstanceState详解
Android开发之InstanceState详解 本文介绍Android中关于Activity的两个神秘方法:onSaveInstanceState() 和 onRestoreInstanceS ...
- Android开发之InstanceState详解(转)---利用其保存Activity状态
Android开发之InstanceState详解 本文介绍Android中关于Activity的两个神秘方法:onSaveInstanceState() 和 onRestoreInstanceS ...
- Android开发之MdiaPlayer详解
Android开发之MdiaPlayer详解 MediaPlayer类可用于控制音频/视频文件或流的播放,我曾在<Android开发之基于Service的音乐播放器>一文中介绍过它的使用. ...
- 高效开发之SASS篇 灵异留白事件——图片下方无故留白 你会用::before、::after吗 link 与 @import之对比 学习前端前必知的——HTTP协议详解 深入了解——CSS3新增属性 菜鸟进阶——grunt $(#form :input)与$(#form input)的区别
高效开发之SASS篇 作为通往前端大神之路的普通的一只学鸟,最近接触了一样稍微高逼格一点的神器,特与大家分享~ 他是谁? 作为前端开发人员,你肯定对css很熟悉,但是你知道css可以自定义吗?大家 ...
- php开发面试题---php面向对象详解(对象的主要三个特性)
php开发面试题---php面向对象详解(对象的主要三个特性) 一.总结 一句话总结: 对象的行为:可以对 对象施加那些操作,开灯,关灯就是行为. 对象的形态:当施加那些方法是对象如何响应,颜色,尺寸 ...
- 开源项目SMSS发开指南(五)——SSL/TLS加密通信详解(下)
继上一篇介绍如何在多种语言之间使用SSL加密通信,今天我们关注Java端的证书创建以及支持SSL的NioSocket服务端开发.完整源码 一.创建keystore文件 网上大多数是通过jdk命令创建秘 ...
- Residual Attention Network for Image Classification(CVPR 2017)详解
一.Residual Attention Network 简介 这是CVPR2017的一篇paper,是商汤.清华.香港中文和北邮合作的文章.它在图像分类问题上,首次成功将极深卷积神经网络与人类视觉注 ...
随机推荐
- AJAX请求的基本操作
1 const { request, response } = require('express'); 2 //引入express 3 const express = require('express ...
- vue项目启动报错问题解决. Module build failed: Error: Node Sass does not yet support your current environment
导入vue项目后,启动报错,异常如下: 1 error in ./src/pages/home.vue 2 Module build failed: Error: Node Sass does not ...
- 1004.Django模板标签
一.常用标签 模板标签 标签在渲染的过程中提供任意的逻辑.这个定义是刻意模糊的.例如,一个标签可以输出内容,作为控制结构,例如 "if"语句或"for"循环从数 ...
- 记录一次使用locust压测的过程
1 脚本# encoding: utf-# @Time : 2021/6/21 1:28 下午 # @Author : Sail # @File : main.py # @Software: PyCh ...
- 微信小程序-顶部下拉菜单实现
最近写的小程序里面需要实现顶部下拉菜单的效果,做一个过滤操作,但是没有找到相关组件,所以动手写了一个. 先看一下这拙劣的效果叭~ 下面就直接看具体实现了嗷! index.wxml <view c ...
- sdut——4541:小志志和小峰峰的日常(取石子博弈模板题 4合1)
小志志和小峰峰的日常 Time Limit: 1000 ms Memory Limit: 65536 KiB Problem Description 小志志和小峰峰特别喜欢一起讨论一些很好玩的问题. ...
- 记一次winfrom 面板改变背景图片
this.panel1.BackgroundImage = Image.FromFile(@"D:\TestDemo\WindowsFormsApp2\WindowsFormsApp2\黑箭 ...
- ApplicationRunner 类说明
在开发中可能会有这样的情景.需要在容器启动的时候执行一些内容.比如读取配置文件,数据库连接之类的.SpringBoot给我们提供了两个接口来帮助我们实现这种需求.这两个接口分别为 CommandLin ...
- 机器学习(三):朴素贝叶斯+贝叶斯估计+BP人工神经网络习题手算|手工推导与习题计算
1.有 1000 个水果样例. 它们可能是香蕉,橙子或其它水果,已知每个水果的 3 种特性:是否偏长.是否甜.颜色是否是黄色 类型 长 不长 甜 不甜 黄色 非黄 Total 香蕉 400 100 3 ...
- vue cli3中配置生产环境、开发环境、测试环境
首先在packjson中配置 "scripts": { "serve": "vue-cli-service serve", //调用开发ap ...