【项目实战】kaggle产品分类挑战
多分类特征的学习
这里还是b站刘二大人的视频课代码,视频链接:https://www.bilibili.com/video/BV1Y7411d7Ys?p=9
相关注释已经标明了(就当是笔记),因此在这里不多赘述,今天的主要目的还是Kaggle的题目
import torch
from torchvision import transforms # 图像处理工具
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307, ), (0.3081, ))
])
# 可以把传入的图像变成一个数值在0到1之间的张量,这里的均值和标准差都是算好的
train_dataset = datasets.MNIST(root='../dataset/mnist/',
train=True,
download=True,
transform=transform)
train_loader = DataLoader(train_dataset,
shuffle=True,
batch_size=batch_size)
text_dataset = datasets.MNIST(root='../dataset/mnist/',
train=False,
download=True,
transform=transform)
test_loader = DataLoader(text_dataset,
shuffle=False,
batch_size=batch_size)
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.l1 = torch.nn.Linear(784, 512)
self.l2 = torch.nn.Linear(512, 256)
self.l3 = torch.nn.Linear(256, 128)
self.l4 = torch.nn.Linear(128, 64)
self.l5 = torch.nn.Linear(64, 10)
def forward(self, x):
x = x.view(-1, 784)
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
return self.l5(x)
model = Net()
criterion = torch.nn.CrossEntropyLoss()
# 使用交叉熵损失他的作用是尽量保持当前梯度的变化方向。
# 没有动量的网络可以视为一个质量很轻的棉花团,风往哪里吹就往哪里走,一点风吹草动都影响他,四处跳
# 动不容易学习到更好的局部最优。没有动力来源的时候可能又不动了。加了动量就像是棉花变成了铁球,
# 咕噜咕噜的滚在参数空间里,很容易闯过鞍点,直到最低点。可以参照指数滑动平均。优化效果是梯度二阶
# 导数不会过大,优化更稳定,也可以看做效果接近二阶方法,但是计算容易的多。其实本质应该是对参数加了约束
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5) # 这里是一个冲量
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
optimizer.zero_grad()
# 前馈反馈和更新
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item() # 累积的loss拿入
if batch_idx % 300 == 299: # 每300轮输出一次
print('[%d, %5d] loss: %.3f' % (epoch+1, batch_idx+1, running_loss/300))
running_loss = 0.0
def test():
correct = 0 # 正确的数量
total = 0 # 总数
with torch.no_grad():
for data in test_loader: # 拿出每一行里面最大值的下标
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item() # 计算猜对的数量
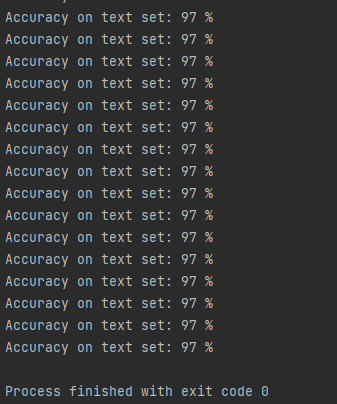
print('Accuracy on text set: %d %%' % (100*correct/total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()
# 到97就跑不上去了,毕竟这就是一个很简单的前馈网络
然后这里是结果
赛题及阅读
本题的kaggle网址在此:https://www.kaggle.com/competitions/otto-group-product-classification-challenge
然后数据集一个train一个text,train,这个挑战主要是给一堆商品数据,这些商品分为9类,每个商品有93个特征,需要你来进行一个模型学习,在测试集中完成分类
原文翻译如下:
在本次比赛中,我们为20多万种产品提供了一个包含93个功能的数据集。我们的目标是建立一个预测模型,能够区分我们的主要产品类别。获奖模型将是开源的。
数据处理
首先我们的数据长成这样


显然我们的target里面的就是我们要学习的标签值,但是他是一个string类型,这个我们可以进行转换
def class2num(brands):
brands_out = []
brand_in = ['class1', 'class2', 'class3', 'class4', 'class5', 'class6', 'class7', 'class8', 'class9']
for brand in brands: //循环的读传入的数据
brands_out.append(brand_in.index(brand)) ##获取当前值在brand_in的索引,巧妙的让他数字化
return brands_out
然后再定义处理数据的函数
class ProductData(Dataset):
def __init__(self, filepath):
xy = pd.read_csv(filepath)
brand = xy['target']
self.len = xy.shape[0]
self.x_data = torch.tensor(np.array(xy)[:, 1:-1].astype(float)) # 把xy转换成np的array数组然后读取里面的数据,并进行数据转换
self.y_data = class2num(brand)
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
再传入数据,定义小批量梯度下降的规模
train_data = ProductData('train.csv')
train_loader = DataLoader(dataset=train_data, batch_size=64, shuffle=True, num_workers=0)
模型设计
再开始设计模型,因为我们的最后分类是9,而特征有93个,所以需要把93降到9
这里是我们定义的模型
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.l1 = torch.nn.Linear(93, 72)
self.l2 = torch.nn.Linear(72, 36)
self.l3 = torch.nn.Linear(36, 18)
self.l4 = torch.nn.Linear(18, 9)
def forward(self, x):
x = x.view(-1, 93)
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
return self.l4(x)
同时在Net的下面我还决定按照昨天的代码编写思路,写上测试的函数
def test(self, x):
with torch.no_grad():
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
_, predict = torch.max(x, dim=1)
# 代码中一个独立的下划线,表示这个变量不重要一个独立的下划线,它也是一个变量名,只不过它比较特殊,当你使用下划线作为变量名时,就代表你告诉大家,这个变量不重要,仅仅占个位置,可以忽略,后面不会再使用它。
y = pd.get_dummies(predict) # 把predict转换成独热向量
return y
实例化模型,并确定损失函数和优化器
model = Net()
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
训练
if __name__ == '__main__':
for epoch in range(200):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0): //用batch_idx, data获取enumerate的值
inputs, target = data
inputs = inputs.float()
optimizer.zero_grad()
outputs = model(inputs) // 放进模型
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item() # 累积的loss拿入
if batch_idx % 300 == 299: # 每300轮输出一次
print('[%d, %5d] loss: %.3f' % (epoch+1, batch_idx+1, running_loss/300))
running_loss = 0.0
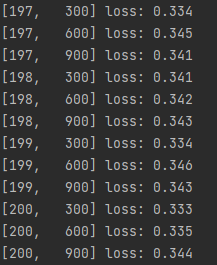
这就是小批量梯度下降的训练写法
训练结果如下
测试
按照要求来测试数据集并且输出一个csv
test_data = pd.read_csv('test.csv') # 读取测试集
test_inputs = torch.tensor(np.array(test_data)[:, 1:].astype(float)) # 读取特征
out = model.test(test_inputs.float()) # 传入模型并且用out来接受得到的值
lables=['Class_1', 'Class_2', 'Class_3', 'Class_4', 'Class_5', 'Class_6', 'Class_7', 'Class_8', 'Class_9']
out.columns = lables # 用lables作为标签
out.insert(0, 'id', test_data['id']) # 对应的标签插入值,insert() 函数用于将指定对象插入列表的指定位置
output = pd.DataFrame(out) # 输出成一个dataframe
output.to_csv('my_predict.csv', index=False) # 输出为csv文件
放进kaggle看看
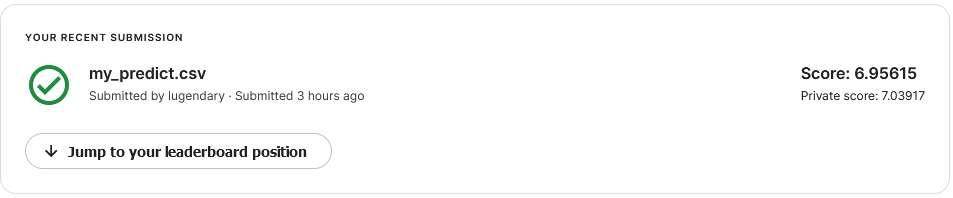
分数不太行嗷
改变一下动量看看(改成0.1)

稍微好一点
以下是完整代码
import numpy as np
import pandas as pd
from torch.utils.data import Dataset, DataLoader
import torch
import torch.nn.functional as F
import torch.optim as optim
def class2num(brands):
brands_out = []
brand_in = ['Class_1', 'Class_2', 'Class_3', 'Class_4', 'Class_5', 'Class_6', 'Class_7', 'Class_8', 'Class_9']
for brand in brands:
brands_out.append(brand_in.index(brand))
return brands_out
class ProductData(Dataset):
def __init__(self, filepath):
xy = pd.read_csv(filepath)
brand = xy['target']
self.len = xy.shape[0]
self.x_data = torch.tensor(np.array(xy)[:, 1:-1].astype(float)) # 把xy转换成np的array数组然后读取里面的数据,并进行数据转换
self.y_data = class2num(brand)
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
train_data = ProductData('train.csv')
train_loader = DataLoader(dataset=train_data, batch_size=64, shuffle=True, num_workers=0)
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.l1 = torch.nn.Linear(93, 72)
self.l2 = torch.nn.Linear(72, 36)
self.l3 = torch.nn.Linear(36, 18)
self.l4 = torch.nn.Linear(18, 9)
def forward(self, x):
x = x.view(-1, 93)
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
return self.l4(x)
def test(self, x):
with torch.no_grad():
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
_, predict = torch.max(x, dim=1)
# 代码中一个独立的下划线,表示这个变量不重要一个独立的下划线,它也是一个变量名,只不过它比较特殊,当你使用下划线作为变量名时,就代表你告诉大家,这个变量不重要,仅仅占个位置,可以忽略,后面不会再使用它。
y = pd.get_dummies(predict) # 把predict转换成独热向量
return y
model = Net()
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.1)
if __name__ == '__main__':
for epoch in range(200):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
inputs = inputs.float()
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item() # 累积的loss拿入
if batch_idx % 300 == 299: # 每300轮输出一次
print('[%d, %5d] loss: %.3f' % (epoch+1, batch_idx+1, running_loss/300))
running_loss = 0.0
# 测试
test_data = pd.read_csv('test.csv')
test_inputs = torch.tensor(np.array(test_data)[:, 1:].astype(float))
out = model.test(test_inputs.float())
lables=['Class_1', 'Class_2', 'Class_3', 'Class_4', 'Class_5', 'Class_6', 'Class_7', 'Class_8', 'Class_9']
out.columns = lables
out.insert(0, 'id', test_data['id'])
output = pd.DataFrame(out)
output.to_csv('my_predict.csv', index=False)
全梯度
故技重施,搞一下直接梯度下降看看,训练5w遍
import numpy as np
import pandas as pd
import torch
import torch.nn.functional as F
import torch.optim as optim
def class2num(brands):
brands_out = []
brand_in = ['Class_1', 'Class_2', 'Class_3', 'Class_4', 'Class_5', 'Class_6', 'Class_7', 'Class_8', 'Class_9']
for brand in brands:
brands_out.append(brand_in.index(brand))
return brands_out
xy = pd.read_csv('train.csv')
brand = xy['target']
len = xy.shape[0]
x_data = torch.tensor(np.array(xy)[:, 1:-1].astype(float)) # 把xy转换成np的array数组然后读取里面的数据,并进行数据转换
y_data = torch.tensor(class2num(brand))
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.l1 = torch.nn.Linear(93, 72)
self.l2 = torch.nn.Linear(72, 36)
self.l3 = torch.nn.Linear(36, 18)
self.l4 = torch.nn.Linear(18, 9)
def forward(self, x):
x = x.view(-1, 93)
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
return self.l4(x)
def test(self, x):
with torch.no_grad():
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
_, predict = torch.max(x, dim=1)
# 代码中一个独立的下划线,表示这个变量不重要一个独立的下划线,它也是一个变量名,只不过它比较特殊,当你使用下划线作为变量名时,就代表你告诉大家,这个变量不重要,仅仅占个位置,可以忽略,后面不会再使用它。
y = pd.get_dummies(predict) # 把predict转换成独热向量
return y
model = Net()
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.1)
if __name__ == '__main__':
for epoch in range(50000):
x_data = x_data.float()
optimizer.zero_grad()
outputs = model(x_data)
loss = criterion(outputs, y_data)
print(epoch, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 测试
test_data = pd.read_csv('test.csv')
test_inputs = torch.tensor(np.array(test_data)[:, 1:].astype(float))
out = model.test(test_inputs.float())
lables=['Class_1', 'Class_2', 'Class_3', 'Class_4', 'Class_5', 'Class_6', 'Class_7', 'Class_8', 'Class_9']
out.columns = lables
out.insert(0, 'id', test_data['id'])
output = pd.DataFrame(out)
output.to_csv('my_predict.csv', index=False)
这次训练速度肉眼可见的慢,慢的一批
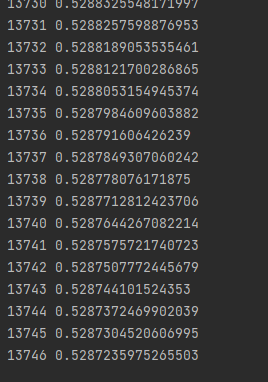
下降的也非常缓慢,基本可以判断是碰到局部最优了,毕竟刚刚那个200次就loss就0.3了
最后我们再用随机梯度下降试试,只需要把batchsize改成1即可
慢的就离谱。。。。
半天就跑这么点
那没事了
结束今天的学习!
【项目实战】kaggle产品分类挑战的更多相关文章
- Java高级项目实战之CRM系统01:CRM系统概念和分类、企业项目开发流程
1. CRM系统介绍 CRM系统即客户关系管理系统, 顾名思义就是管理公司与客户之间的关系. 是一种以"客户关系一对一理论"为基础,旨在改善企业与客户之间关系的新型管理机制.客户关 ...
- 《React后台管理系统实战 :四》产品分类管理页:添加产品分类、修改(更新)产品分类
一.静态页面 目录结构 F:\Test\react-demo\admin-client\src\pages\admin\category add-cate-form.jsx index.jsx ind ...
- 【腾讯Bugly干货分享】React Native项目实战总结
本文来自于腾讯bugly开发者社区,非经作者同意,请勿转载,原文地址:http://dev.qq.com/topic/577e16a7640ad7b4682c64a7 “8小时内拼工作,8小时外拼成长 ...
- 【无私分享:ASP.NET CORE 项目实战(第十三章)】Asp.net Core 使用MyCat分布式数据库,实现读写分离
目录索引 [无私分享:ASP.NET CORE 项目实战]目录索引 简介 MyCat2.0版本很快就发布了,关于MyCat的动态和一些问题,大家可以加一下MyCat的官方QQ群:106088787.我 ...
- angularJs项目实战!01:模块划分和目录组织
近日来我有幸主导了一个典型的web app开发.该项目从产品层次来说是个典型的CRUD应用,故而我毫不犹豫地采用了grunt + boilerplate + angularjs + bootstrap ...
- ASP.NET Core 系列视频完结,新项目实战课程发布。
今天把MVC的章节完成了,给大家从头到尾做了一个登录注册的示例,带前后端Model验证,算是完整的示例.同时借助于eShopOnContainers的示例也做了一个DBContextSeed的包装器来 ...
- 【.NET Core项目实战-统一认证平台】第十章 授权篇-客户端授权
[.NET Core项目实战-统一认证平台]开篇及目录索引 上篇文章介绍了如何使用Dapper持久化IdentityServer4(以下简称ids4)的信息,并实现了sqlserver和mysql两种 ...
- 机器学习_线性回归和逻辑回归_案例实战:Python实现逻辑回归与梯度下降策略_项目实战:使用逻辑回归判断信用卡欺诈检测
线性回归: 注:为偏置项,这一项的x的值假设为[1,1,1,1,1....] 注:为使似然函数越大,则需要最小二乘法函数越小越好 线性回归中为什么选用平方和作为误差函数?假设模型结果与测量值 误差满足 ...
- 项目实战8.1—tomcat企业级Web应用服务器配置与会话保持
分类: Linux架构篇 tomcat企业级Web应用服务器配置与实战 环境背景:公司业务经过长期发展,有了很大突破,已经实现盈利,现公司要求加强技术架构应用功能和安全性以及开始向企业应用.移动A ...
随机推荐
- 013(oulipo)
题目:http://ybt.ssoier.cn:8088/problem_show.php?pid=1455 题目描述:在母串里找子串出现的次数 题目思路:与字符串的搜索有关那就立刻找到哈希 从s[1 ...
- meet in the middle 复习笔记
前言 若干年前看过现在又忘了.这么简单都忘 所以今天来重新复习一下. 正题 考虑这样的问题: 给定 \(n\) 个物品的价格,你有 \(m\) 块钱,每件物品限买一次,求买东西的方案数. \(n\le ...
- springboot java -jar指定启动的jar外部配置文件
Limited Setting Effect 中文描述 Java 8 -Xbootclasspath:<path> Sets the search path for bootstrap c ...
- 请问为啥计算器16进制FFFFFFFFFFFF时10进制是-1?
请问为啥计算器16进制FFFFFFFFFFFF时10进制是-1?
- SpringBoot 如何集成 MyBatisPlus - SpringBoot 2.7.2实战基础
SpringBoot 2.7.2 学习系列,本节通过实战内容讲解如何集成 MyBatisPlus 本文在前文的基础上集成 MyBatisPlus,并创建数据库表,实现一个实体简单的 CRUD 接口. ...
- show create table底层流程跟踪
GreatSQL社区原创内容未经授权不得随意使用,转载请联系小编并注明来源. 导语 SHOW CREATE TABLE语句用于为指定表/视图显示创建的语句,本文将简要描述如何在MySQL源码里跟踪和学 ...
- Dolphin Scheduler 1.2.0 部署参数分析
本文章经授权转载 1 组件介绍 Apache Dolphin Scheduler是一个分布式易扩展的可视化DAG工作流任务调度系统.致力于解决数据处理流程中错综复杂的依赖关系,使调度系统在数据处理流程 ...
- Apache DolphinScheduler 如何从 1.2.1 升级到 1.3.4
关于 Apache DolphinScheduler Apache DolphinScheduler(incubator) 于 17 年在易观数科立项, 19 年 8 月进入 Apache 孵化器,已 ...
- LuoguP3690 【模板】Link Cut Tree (LCT)
勉强算是结了个大坑吧或者才开始 #include <cstdio> #include <iostream> #include <cstring> #include ...
- Centroids (换根DP)
题面 题解 删一条边.加一条边,相当于把一个子树折下来,然后嫁接在一个点上, 那么最优的情况肯定是接在根上,对吧,很好理解吧 那么这个拆下来的子树大小就不能超过n/2. 我们用son[]来表示每个点为 ...