Pod原理
Pod 是 Kubernetes 集群中最基本的调度单元,我们平时在集群中部署的应用都是以 Pod 为单位的,而并不是我们熟知的容器,这样设计的目的是什么呢?为何不直接使用容器呢?
为什么需要 Pod
假设 Kubernetes 中调度的基本单元就是容器,对于一个非常简单的应用可以直接被调度直接使用,没有什么问题,但是往往还有很多应用程序是由多个进程组成的,有的同学可能会说把这些进程都打包到一个容器中去不就可以了吗?理论上是可以实现的,但是不要忘记了 Docker 管理的进程是 pid=1 的主进程,其他进程死掉了就会成为僵尸进程,没办法进行管理了,这种方式本身也不是容器推荐的运行方式,一个容器最好只干一件事情,所以在真实的环境中不会使用这种方式。
那么我们就把这个应用的进程进行拆分,拆分成一个一个的容器总可以了吧?但是不要忘记一个问题,拆分成一个一个的容器后,是不是就有可能出现一个应用下面的某个进程容器被调度到了不同的节点上呀?往往我们应用内部的进程与进程间通信(通过 IPC 或者共享本地文件之类)都是要求在本地进行的,也就是需要在同一个节点上运行。
所以我们需要一个更高级别的结构来将这些容器绑定在一起,并将他们作为一个基本的调度单元进行管理,这样就可以保证这些容器始终在同一个节点上面,这也就是 Pod 设计的初衷。
Pod 原理
在一个 Pod 下面运行几个关系非常密切的容器进程,这样一来这些进程本身既可以受到容器的管控,又具有几乎一致的运行环境,也就完美解决了上面提到的问题。
其实 Pod 也只是一个逻辑概念,真正起作用的还是 Linux 容器的 Namespace 和 Cgroup 这两个最基本的概念,Pod 被创建出来其实是一组共享了一些资源的容器而已。首先 Pod 里面的所有容器,都是共享的同一个 Network Namespace,但是涉及到文件系统的时候,默认情况下 Pod 里面的容器之间的文件系统是完全隔离的,但是我们可以通过声明来共享同一个 Volume。
对于共享同一个 Network Namespace 这个概念是不是比较熟悉,我们之前在 Docker 网络模式的章节中讲解了网络的 Container 模式,我们可以指定新创建的容器和一个已经存在的容器共享一个 Network Namespace,在运行容器的时候只需要指定 --net=container:目标容器名 这个参数就可以了,但是这种模式有一个明显的问题那就是容器的启动有先后顺序问题,那么 Pod 是怎么来处理这个问题的呢?那就是加入一个中间容器(没有什么架构是加一个中间件解决不了的?),这个容器叫做 Infra 容器,而且这个容器在 Pod 中永远都是第一个被创建的容器,这样是不是其他容器都加入到这个 Infra 容器就可以了,这样就完全实现了 Pod 中的所有容器都和 Infra 容器共享同一个 Network Namespace 了,如下图所示:
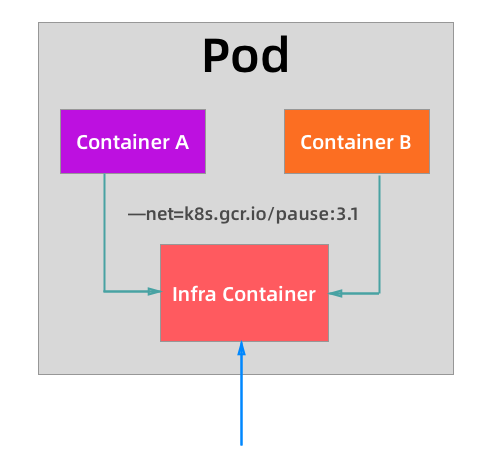
所以当我们部署完成 Kubernetes 集群的时候,首先需要保证在所有节点上可以拉取到默认的 Infra 镜像,默认情况下 Infra 镜像地址为 k8s.gcr.io/pause:3.1,这个容器占用的资源非常少,但是这个镜像默认是需要ke xue shang wang的,所以很多时候我们在部署应用的时候一直处于 Pending 状态,因为所有 Pod 最先启动的容器镜像都拉不下来,肯定启动不了,启动不了其他容器肯定也就不能启动了:
$ kubelet --help |grep infra
--pod-infra-container-image string The image whose network/ipc namespaces containers in each pod will use. This docker-specific flag only works when container-runtime is set to docker. (default "k8s.gcr.io/pause:3.1")
从上面图中我们可以看出普通的容器加入到了 Infra 容器的 Network Namespace 中,所以这个 Pod 下面的所有容器就是共享同一个 Network Namespace 了,普通容器不会创建自己的网卡,配置自己的 IP,而是和 Infra 容器共享 IP、端口范围等,而且容器之间的进程可以通过 lo 网卡设备进行通信:
- 也就是容器之间是可以直接使用 localhost 进行通信的;
- 看到的网络设备信息都是和 Infra 容器完全一样的;
- 也就意味着同一个 Pod 下面的容器运行的多个进程不能绑定相同的端口;
- 而且 Pod 的生命周期只跟 Infra 容器一致,而与容器 A 和 B 无关。
对于文件系统 Kubernetes 是怎么实现让一个 Pod 中的容器共享的呢?默认情况下容器的文件系统是互相隔离的,要实现共享只需要在 Pod 的顶层声明一个 Volume,然后在需要共享这个 Volume 的容器中声明挂载即可。
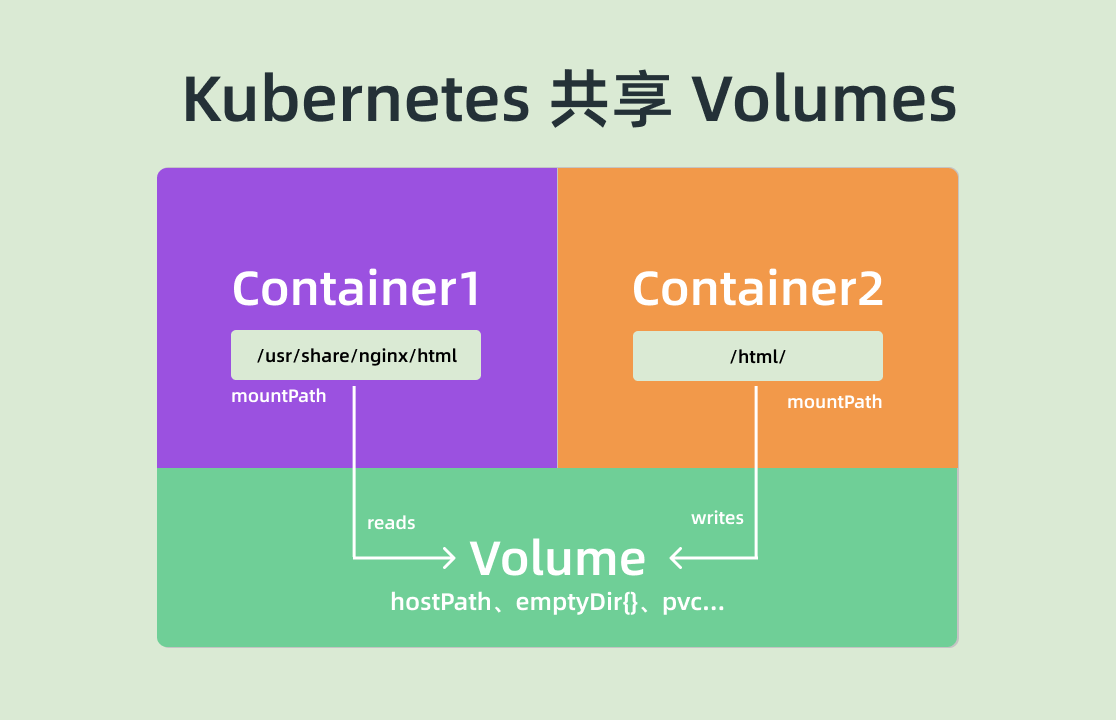
比如下面的示例:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
volumes:
- name: varlog
hostPath:
path: /var/log/counter
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log
image: busybox
args: [/bin/sh, -c, 'tail -n+1 -f /var/log/1.log']
volumeMounts:
- name: varlog
mountPath: /var/log
示例中我们在 Pod 的顶层声明了一个名为 varlog 的 Volume,而这个 Volume 的类型是 hostPath,也就意味这个宿主机的 /var/log/counter 目录将被这个 Pod 共享,共享给谁呢?在需要用到这个数据目录的容器上声明挂载即可,也就是通过 volumeMounts 声明挂载的部分,这样我们这个 Pod 就实现了共享容器的 /var/log 目录,而且数据被持久化到了宿主机目录上。
这个方式也是 Kubernetes 中一个非常重要的设计模式:sidecar 模式的常用方式。典型的场景就是容器日志收集,比如上面我们的这个应用,其中应用的日志是被输出到容器的 /var/log 目录上的,这个时候我们可以把 Pod 声明的 Volume 挂载到容器的 /var/log 目录上,然后在这个 Pod 里面同时运行一个 sidecar 容器,他也声明挂载相同的 Volume 到自己容器的 /var/log (或其他)目录上,这样我们这个 sidecar 容器就只需要从 /var/log 目录下面不断消费日志发送到 Elasticsearch 中存储起来就完成了最基本的应用日志的基本收集工作了。
除了这个应用场景之外使用更多的还是利用 Pod 中的所有容器共享同一个 Network Namespace 这个特性,这样我们就可以把 Pod 网络相关的配置和管理也可以交给一个 sidecar 容器来完成,完全不需要去干涉用户容器,这个特性在现在非常火热的 Service Mesh(服务网格)中应用非常广泛,典型的应用就是 Istio。
如何划分 Pod
举一个简单的示例,比如我们的 Wordpress 应用,是一个典型的前端服务器和后端数据服务的应用,那么你认为应该使用一个 Pod 还是两个 Pod 呢?
如果在同一个 Pod 中同时运行服务器程序和后端的数据库服务这两个容器,理论上肯定是可行的,但是不推荐这样使用,我们知道一个 Pod 中的所有容器都是同一个整体进行调度的,但是对于我们这个应用 Wordpress 和 MySQL 数据库一定需要运行在一起吗?当然不需要,我们甚至可以将 MySQL 部署到集群之外对吧?所以 Wordpress 和 MySQL 即使不运行在同一个节点上也是可行的,只要能够访问到即可。
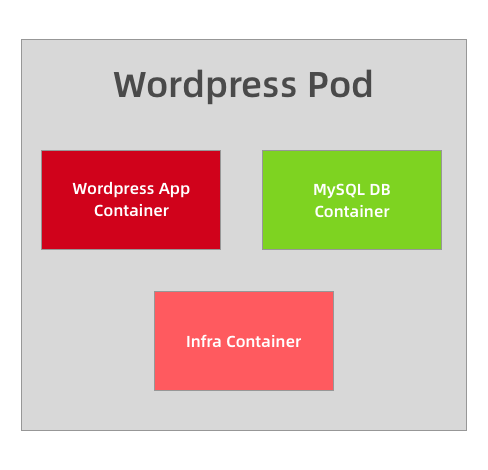
但是如果你非要强行部署到同一个 Pod 中呢?从某个角度来说是错误的,比如现在我们的应用访问量非常大,一个 Pod 已经满足不了我们的需求了,怎么办呢?扩容对吧,但是扩容的目标也是 Pod,并不是容器,比如我们再添加一个 Pod,这个时候我们就有两个 Wordpress 的应用和两个 MySQL 数据库了,而且这两个 Pod 之间的数据是互相独立的,因为 MySQL 数据库并不是简单的增加副本就可以共享数据了,所以这个时候就得分开部署了,采用第二种方案,这个时候我们只需要单独扩容 Wordpress 的这个 Pod,后端的 MySQL 数据库并不会受到扩容的影响。
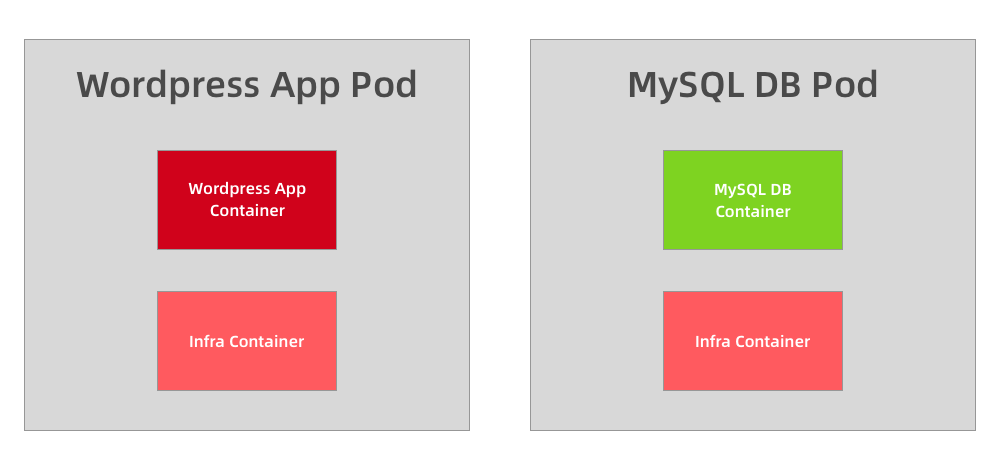
将多个容器部署到同一个 Pod 中的最主要参考就是应用可能由一个主进程和一个或多个的辅助进程组成,比如上面我们的日志收集的 Pod,需要其他的 sidecar 容器来支持日志的采集。所以当我们判断是否需要在 Pod 中使用多个容器的时候,我们可以按照如下的几个方式来判断:
- 这些容器是否一定需要一起运行,是否可以运行在不同的节点上
- 这些容器是一个整体还是独立的组件
- 这些容器一起进行扩缩容会影响应用吗
基本上我们能够回答上面的几个问题就能够判断是否需要在 Pod 中运行多个容器了。
Pod原理的更多相关文章
- K8S探针和SVC,POD原理
(6)容器是否健康: spec.container.livenessProbe.若不健康,则Pod有可能被重启(可配置策略) (7)容器是否可用: spec.container.readiness ...
- Kubernetes学习之原理
Kubernetes基本概念 一.Label selector在kubernetes中的应用场景 1.kube-controller-manager的replicaSet通过定义的label 来筛选要 ...
- Linux运维博客大全
系统 U盘安装Linux详细步骤_hanxh7的博客-CSDN博客_u盘安装linux 使用U盘安装linux系统 - lwenhao - OSCHINA 各厂商服务器存储默认管理口登录信息(默认IP ...
- 阳明-K8S训练营全部文档-2020年08月11日14:59:02更新
阳明-K8S训练营全部文档 Docker 基础 简介 安装 基本操作 Dockerfile Dockerfile最佳实践 Kubernetes 基础 简介 安装 资源清单 Pod 原理 Pod 生命周 ...
- Kubernetes ConfigMap热更新
ConfigMap是用来存储配置文件的kubernetes资源对象,所有的配置内容都存储在etcd中. 总结 更新 ConfigMap 后: 使用该 ConfigMap 挂载的 Env 不会同步更新 ...
- 使用ansible kubectl插件连接kubernetes pod以及实现原理
ansible kubectl connection plugin ansible是目前业界非常火热的自动化运维工具.ansible可以通过ssh连接到目标机器上,从而完成指定的命令或者操作. 在ku ...
- kubernetes pod infra container网络原理
刚开始接触kubernetes时,对kubelet的--pod-infra-container-image参数非常不能理解,不理解为什么我的业务应用需要依赖一个第三方的容器: 上文入门级kuberne ...
- Pod和容器的LimitRange原理和实践总结
一.背景介绍 通常情况下,Pod中的容器可以无限制的使用节点上的CPU和内存资源,在共享资源和资源有限的情况下,若不加以限制,某个集群或命名空间的资源可能会消耗殆尽,导致其他节点上优先级低的Pod发生 ...
- iOS----CocoaPods的安装、使用和,原理+参考流程+常见问题
一.什么是CocoaPods CocoaPods是iOS项目的依赖管理工具,该项目源码在Github上管理.开发iOS项目不可避免地要使用第三方开源库,CocoaPods的出现使得我们可以节省设置和第 ...
随机推荐
- 《SVDNet for Pedestrian Retrieval》理解
<SVDNet for Pedestrian Retrieval>理解 Abstract: 这篇文章提出了一个用于检索问题的SVDNet,聚焦于在行人再识别上的应用.我们查看卷积神经网络中 ...
- SpringBoot自定义starter开发分布式任务调度实践
概述 需求 在前面的博客<Java定时器演进过程和生产级分布式任务调度ElasticJob代码实战>中,我们已经熟悉ElasticJob分布式任务的应用,其核心实现为elasticjob- ...
- 强化学习-学习笔记12 | Dueling Network
这是价值学习高级技巧第三篇,前两篇主要是针对 TD 算法的改进,而Dueling Network 对 DQN 的结构进行改进,能够大幅度改进DQN的效果. Dueling Network 的应用范围不 ...
- Java中运算符和方法的区别
1.多数情况下,运算符是程序语言里固有的.比如+,-,*,/.可以直接被编译为机器语言而无需再调用其它方法编译. 2.运算符在被定义时会被规定运算的优先级.如4+3*3,会得到13.而不是21. 3. ...
- mysql8.0二进制安装遇到的问题
公司新项目需要用CentOS8.0以上的系统和mysql8.0:于是在虚拟机上开始操作测试: 一实验环境 1.系统版本:CentOS8.32.数据库版本:mysql-8.0.233.数据库下载链接:h ...
- 使用OnPush和immutable.js来提升angular的性能
angular里面变化检测是非常频繁的发生的,如果你像下面这样写代码 <div> {{hello()}} </div> 则每次变化检测都会执行hello函数,如果hello函数 ...
- 总结-DSU ON TREE(树上启发式合并)
考试遇到一道题: 有一棵n个点的有根树,每个点有一个颜色,每次询问给定一个点\(u\)和一个数\(k\),询问\(u\)子是多少个不同颜色节点的\(k\)级祖先.n<=500000. 显然对每一 ...
- 除了Synchronized关键字还有什么可以保证线程安全?
除了Synchronized关键字还有什么可以保证线程安全? 日常使用Java开发时,多线程开发,一般就用Synchronized保证线程安全,防止并发出现的错误和异常,那么 除了Synchr ...
- 盘点Vue2和Vue3的10种组件通信方式(值得收藏)
Vue中组件通信方式有很多,其中Vue2和Vue3实现起来也会有很多差异:本文将通过选项式API 组合式API以及setup三种不同实现方式全面介绍Vue2和Vue3的组件通信方式.其中将要实现的通信 ...
- Web 前端模块出现的原因,以及 Node.js 中的模块
模块出现原因 简单概述 随着 Web 2.0 时代的到来,JavaScript 不再是以前的小脚本程序了,它在前端担任了更多的职责,也逐渐地被广泛运用在了更加复杂的应用开发的级别上. 但是 JavaS ...