8. 使用Fluentd+MongoDB采集Apache日志
Fluentd+MongoDB,用以实时收集半结构化数据。
背景知识
日志接入Fluentd后,会以json的格式在Fluentd内部进行路由。这就决定了Fluentd处理日志的方式是非常灵活的,它将日志视为半结构化数据,可以方便地修改其结构。
相应地,日志的最终存储数据库也应该擅长处理这样的半结构或者非结构化数据。这样整个系统搭配起来才更协调和高效。
而MongoDB恰好也是以类json的方式来处理内部数据的,非常适合作为Fluentd的目标存储。实现机制
通常以下列架构来组合Fluentd+MongoDB这对CP。
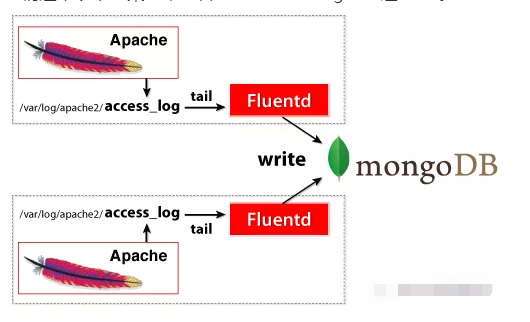
在这个组合中,Fluentd的职责为:
- 持续“tail”Apache访问日志
- 将Apache日志文本解析为有意义的字段(如ip、path等),并缓存之
- 定期将缓存的日志写入MongoDB
- 安装部署
3.1 安装Apache、MongoDB、Fluentd
3.2 在Fluentd中安装MongoDB插件(最新版Fluentd已内置)
fluent-gem install fluent-plugin-mongo
- 配置说明
4.1 配置输入端
<source>
@type tail
path /var/log/apache2/access_log
pos_file /var/log/td-agent/apache2.access_log.pos
<parse>
@type apache2
</parse>
tag mongo.apache.access
</source>
使用tail来追踪Apache的日志文件access_log,使用Fluentd内置的Apache日志解析器apache2来解析日志。日志事件tag为mongo.apache.access。
4.2 配置输出端
<match mongo.**>
# plugin type
@type mongo
# mongodb db + collection
database apache
collection access
# mongodb host + port
host localhost
port 27017
# interval
<buffer>
flush_interval 10s
</buffer>
# make sure to include the time key
<inject>
time_key time
</inject>
</match>
<match>匹配所有mongo开头的tag,使用out_mongo作为输出插件。依次配置日志存储在MongoDB中的数据库和集合、MongoDB地址和端口。设置flush间隔为10秒,每10秒将缓存的日志写入MongoDB。
- 测试验证
确保各服务正常运行。通过ping Apache来制造一些测试数据。
$ ab -n 100 -c 10 http://localhost/
然后,在MongoDB中就可以看到这些日志了。
$ mongo
> use apache
> db["access"].findOne();
{ "_id" : ObjectId("4ed1ed3a340765ce73000001"), "host" : "127.0.0.1", "user" : "-", "method" : "GET", "path" : "/", "code" : "200", "size" : "44", "time" : ISODate("2011-11-27T07:56:27Z") }
{ "_id" : ObjectId("4ed1ed3a340765ce73000002"), "host" : "127.0.0.1", "user" : "-", "method" : "GET", "path" : "/", "code" : "200", "size" : "44", "time" : ISODate("2011-11-27T07:56:34Z") }
{ "_id" : ObjectId("4ed1ed3a340765ce73000003"), "host" : "127.0.0.1", "user" : "-", "method" : "GET", "path" : "/", "code" : "200", "size" : "44", "time" : ISODate("2011-11-27T07:56:34Z") }
8. 使用Fluentd+MongoDB采集Apache日志的更多相关文章
- 使用Fluentd + MongoDB构建实时日志收集系统
Fluentd是一个日志收集系统,它的特点在于其各部分均是可定制化的,你可以通过简单的配置,将日志收集到不同的地方. 目前开源社区已经贡献了下面一些存储插件:MongoDB, Redis, Couch ...
- elk系列7之通过grok分析apache日志
preface 说道分析日志,我们知道的采集方式有2种: 通过grok在logstash的filter里面过滤匹配. logstash --> redis --> python(py脚本过 ...
- elk系列7之通过grok分析apache日志【转】
preface 说道分析日志,我们知道的采集方式有2种: 通过grok在logstash的filter里面过滤匹配. logstash --> redis --> python(py脚本过 ...
- Centos7 搭建 Flume 采集 Nginx 日志
版本信息 CentOS: Linux localhost.localdomain 3.10.0-862.el7.x86_64 #1 SMP Fri Apr 20 16:44:24 UTC 2018 x ...
- logresolve - 解析Apache日志中的IP地址为主机名
logresolve是一个解析Apache访问日志中IP地址的后处理程序. 为了使对名称服务器的影响降到最低,logresolve拥有极为自主的内部散列表缓存, 使每个IP值仅仅在第一次从日志文件中读 ...
- Apache日志分析
Apache日志统计举例 加些来了解一下如何统计Apache的访问日志,一般可以用tail命令来实时查看日志文件变化,但是各种的应用系统中的日志会非常复杂,一堆长度超过你浏览极限的日志出现在你眼前时, ...
- 关于Apache日志的统计
统计apache日志文件里访问量前十的ip并按从多到少排列 五月 31, 2012 by FandLR Filed under Linux Leave a comment 解法1: cat acc ...
- Apache日志配置参数详细说明
Apache日志按时间分段记录 在apache的配置文件httpd.conf中找到ErrorLog logs/error_log及CustomLog logs/access_log common Li ...
- Apache日志配置详解(rotatelogs LogFormat)
logs/error_logCustomLog logs/access_log common--默认为以上部分 修改为如下: ErrorLog "|/usr/sbin/rotatelogs ...
随机推荐
- 抢先体验! 在浏览器里写 Flutter 是一种什么体验?
Invertase 是一间位于英国的开源软件制作公司.主要构建关于开发者工具.SDK 等应用程序,早在 Flutter 2.2 的时候,Invertase 团队就开始帮助构建和贡献 Firebase ...
- Linux系列之添加和删除软件命令
前言 在基于Debian的Linux发行版中,默认的软件管理器是Advanced Packaging Tool, 也就是apt.本文将简单介绍下面有关添加和删除软件的命令: apt-cache sea ...
- 推荐系统-协同过滤在Spark中的实现
作者:vivo 互联网服务器团队-Tang Shutao 现如今推荐无处不在,例如抖音.淘宝.京东App均能见到推荐系统的身影,其背后涉及许多的技术.本文以经典的协同过滤为切入点,重点介绍了被工业界广 ...
- USB转串口参数配置功能
当使用USB转串口芯片时,在部分场合下需要修改芯片内部的USB参数以满足其应用需要.常见如: 系统下使用多个USB转串口芯片,区分使用各芯片. 修改厂商ID.产品ID.厂商字符串,使用客户自有ID和信 ...
- 2022-07-25 第四组 java之抽象、接口
目录 一.抽象类 1.概念 2.抽象类以及抽象方法格式定义 3.抽象类总结规定 二.接口 1.什么是接口 2.接口的定义 3.接口特性 4.抽象类和接口的区别 5.继承抽象类和实现接口的异同 6.规则 ...
- python 执行需要管理员权限的命令(Windows)
由于Windows存在管理员权限限制,执行需管理员权限的命令时会出错, 有两种方案, 1.采用python调用vbs文件,vbs调用bat文件 2.采用提供弹出用户管理员权限方式让用户确认 1.采用p ...
- Windows环境中Hadoop配置
我们之前已经在Windows中安装好了Hadoop,并且配置了环境变量.如果要在本地上运行的,还需要这两个文件,可以去找一下,放到Hadoop的bin目录下面.这样我们写好的mr程序就可以直接在Win ...
- 如何构建 Apache DolphinScheduler 的 Docker 镜像
继昨日发布第一个 [官方 Docker 镜像] 后,有几位小伙伴私信想自己进行编译,这里也将 Docker 的主要贡献者文禾同学整理的文档进行分享.以下是全文内容: 您能够在类 Unix 系统和 Wi ...
- Apache DolphinScheduler 源码剖析之 Worker 容错处理流程
今天给大家带来的分享是 Apache DolphinScheduler 源码剖析之 Worker 容错处理流程 DolphinScheduler源码剖析之Worker容错处理流程 Worker容错流程 ...
- 60行自己动手写LockSupport是什么体验?
60行自己动手写LockSupport是什么体验? 前言 在JDK当中给我们提供的各种并发工具当中,比如ReentrantLock等等工具的内部实现,经常会使用到一个工具,这个工具就是LockSupp ...