有一种算法叫做“Union-Find”?
前言:
不少搞IT的朋友听到“算法”时总是觉得它太难,太高大上了。今天,跟大伙儿分享一个比较俗气,但是却非常高效实用的算法,如标题所示Union-Find,是研究关于动态连通性的问题。不保证我能清晰的表述并解释这个算法,也不保证你可以领会这个算法的绝妙之处。但是,只要跟着思路一步一步来,相信你一定可以理解它,并像我一样享受它。
-----------------------------------------
为了便于引入算法,下面我们假设一个场景:
假设现在有A,B两人素不相识,但A通过熟人甲,甲通过熟人乙,乙通过熟人丙,丙通过熟人丁,而丁又刚好与B是熟人。就这样,A通过一层一层的人际关系最后认识了B。
基于以上介绍的“关系网”,现在给出一道思考题:13亿中国人当中一共有几个“关系网”呢?
------------------------------------------
1.Union-Find初探
是的,想到1,300,000,000这个数字,或许此刻你大脑已经懵了。那好,我们就先从小数据分析:
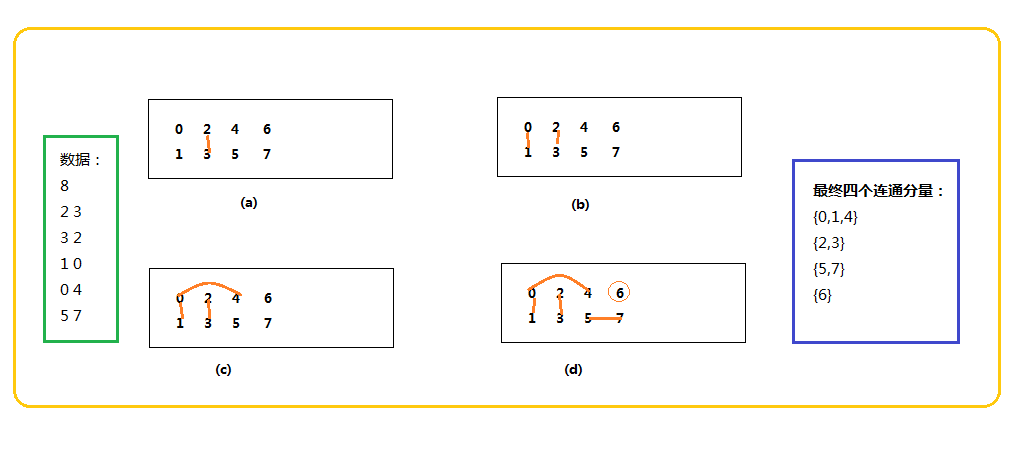
图1
从上图中,其实很好理解。初始每个人都是单独的一个“点”,用科学语言,我们把它描述为“连通分量”。随着一个一个关系的确立,即点与点之间的连接,每连接一次,总连通分量数即减1(理解算法的关键点之一)。最后的“关系网”几乎可以很轻易地数出来。所以,只要你把所有国人两两之间的联系给出,然后不断连线,连线,...,最后再统计一下不就完事儿了麽~
问题是:怎么存储点的信息?点与点怎么连,怎么判断该不该连?
因此,我们需要维护2个变量,其中一个变量count表示实时的连通分量数,另一个变量可以用来存储具体每一个点所属的连通分量。因为不需要存储复杂的信息。这里我们选常用的数组 id[N] 存储即可。然后,我们需要2个函数find(int x)和union(int p,int q)。前者返回点“x”所属于的连通分量,后者将p,q两点进行连接。注意,所谓的连接,其实可以简单的将p的连通分量值赋予q或者将q的连通分量值赋予p,即:
id[p]=q 或者id[q]=p。
有了上面的分析,我们就可以牛刀小试了。且看Java代码实现第一版。
Code:
package com.gdufe.unionfind; import java.io.File;
import java.util.Scanner; public class UF { int count; //连通分量数
int[] id; //每个数所属的连通分量 public UF(int N) { //初始化时,N个点有N个分量
count = N;
id = new int[N];
for (int i = 0; i < N; i++)
id[i] = i;
}
//返回连通分量数
public int getCount(){
return count;
}
//查找x所属的连通分量
public int find(int x){
return id[x];
}
//连接p,q(将q的分量改为p所在的分量)
public void union(int p,int q){
int pID=find(p);
int qID=find(q);
for(int i=0;i<id.length;i++){
if(find(i)==pID){
id[i]=qID;
}
}
count--; //记得每进行一次连接,分量数减“1”
}
//判断p,q是否连接,即是否属于同一个分量
public boolean connected(int p,int q){
return find(p)==find(q);
} public static void main(String[] args) throws Exception { //数据从外部文件读入,“data.txt”放在项目的根目录下
Scanner input = new Scanner(new File("data.txt"));
int N=input.nextInt();
UF uf = new UF(N);
while(input.hasNext()){
int p=input.nextInt();
int q=input.nextInt();
if(uf.connected(p, q)) continue; //若p,q已属于同一连通分量不再连接,则故直接跳过
uf.union(p, q);
System.out.println(p+"-"+q); }
System.out.println("总连通分量数:"+uf.getCount());
} }
测试结果:
2-3
1-0
0-4
5-7
总连通分量数:4
分析:
find()操作的时间复杂度为:O(l),Union的时间复杂度为:O(N)。因为算法可以非常高效地实现find(),所以我们也把它称为“quick-find”算法。
--------------------
2.Union-find进阶:
仔细一想,我们上面再进行union()连接操作时,实际上就是一个进行暴力“标记”的过程,即把所有连通分量id跟点q相同的点找出来,然后全部换成p的id。算法本身没有错,但是这样的代价太高了,得想办法优化~
因此,这里引入了一个抽象的“树”结构,即初始时每个点都是一棵独立的树,所有的点构成了一个大森林。每一次连接,实际上就是两棵树的合并。通过,不断的合并,合并,再合并最后长成了一棵棵的大树。
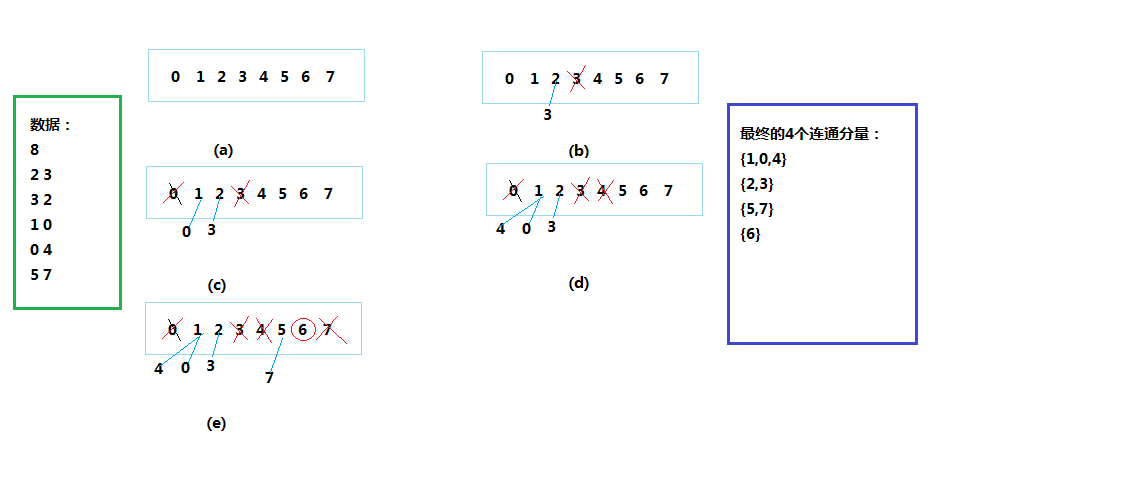
图2
Code:
package com.gdufe.unionfind; import java.io.File;
import java.util.Scanner; public class UF { int count; //连通分量数
int[] id; //每个数所属的连通分量 public UF(int N) { //初始化时,N个点有N个分量
count = N;
id = new int[N];
for (int i = 0; i < N; i++)
id[i] = i;
}
//返回连通分量数
public int getCount(){
return count;
} //查找x所属的连通分量
public int find(int x){
while(x!=id[x]) x = id[x]; //若找不到,则一直往根root回溯
return x;
}
//连接p,q(将q的分量改为p所在的分量)
public void union(int p,int q){
int pID=find(p);
int qID=find(q);
if(pID==qID) return ;
id[q]=pID;
count--;
}
/*
//查找x所属的连通分量
public int find(int x){
return id[x];
} //连接p,q(将q的分量改为p所在的分量)
public void union(int p,int q){
int pID=find(p);
int qID=find(q);
if(pID==qID) return ;
for(int i=0;i<id.length;i++){
if(find(i)==pID){
id[i]=qID;
}
}
count--; //记得每进行一次连接,分量数减“1”
}
*/
//判断p,q是否连接,即是否属于同一个分量
public boolean connected(int p,int q){
return find(p)==find(q);
} public static void main(String[] args) throws Exception { //数据从外部文件读入,“data.txt”放在项目的根目录下
Scanner input = new Scanner(new File("data.txt"));
int N=input.nextInt();
UF uf = new UF(N);
while(input.hasNext()){
int p=input.nextInt();
int q=input.nextInt();
if(uf.connected(p, q)) continue; //若p,q已属于同一连通分量不再连接,则故直接跳过
uf.union(p, q);
System.out.println(p+"-"+q); }
System.out.println("总连通分量数:"+uf.getCount());
} }
测试结果:
2-3
1-0
0-4
5-7
总连通分量数:4
分析:
利用树本身良好的连通性,我们算法仅需要O(l)时间代价进行union()操作,但此时find()操作的时间代价有所增加。结合本算法对quick-find()的优化,我们把它称为“quick-union”算法。
--------
3.Union-Find再进阶
等等,还没完!
表面上,上述引入“树”结构的算法时间复杂度由原来的O(N)改进为O(lgN)。但是,不要忽略了这样一种极端情况,即每连接一个点之后,树在不断往下生长,最后长成一棵“秃树”(没有任何树枝)。
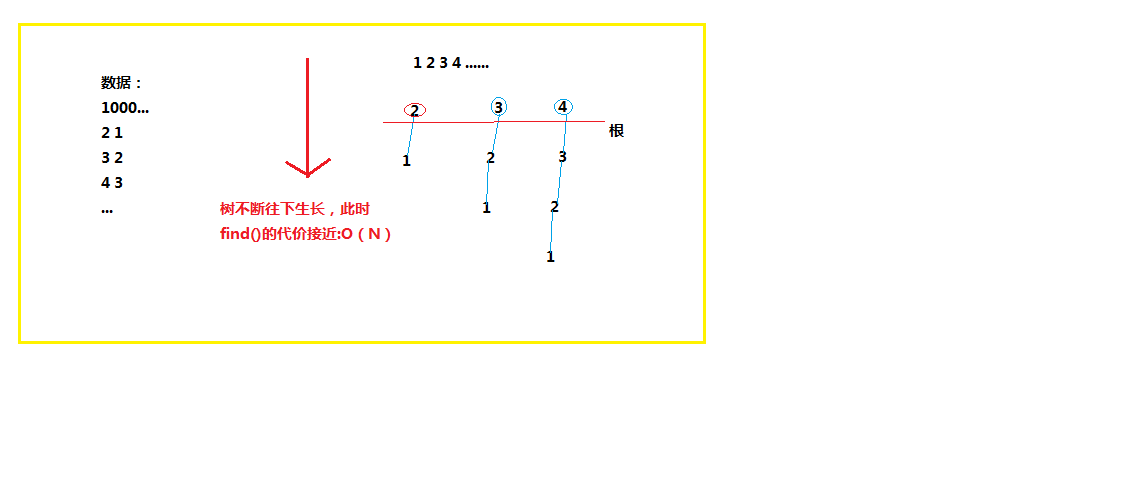 图3
图3
为了不让我们前面做的工作白费,必须得采取某些措施避免这种恶劣的情况给我们算法带来的巨大代价。所以...
是的,或许你已经想到了,就是在两棵树进行连接之前做一个判断。每一次都优先选择将小树合并到大树下面,这样子树的高度不变,能避免树一直往下增长了!下图中,数据增加了“6-2”的一条连接,得知以“2”为根节点的树比“6”的树大,对比(f)和(g)两种连接方式,我们最优选择应该是(g),即把小树并到大树下。
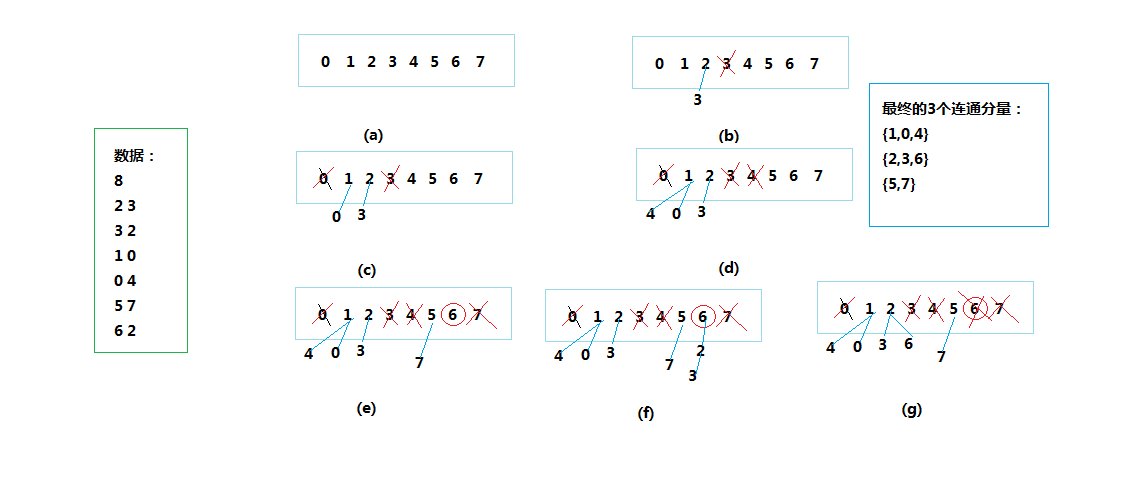 图4
图4
基于此,我们还得引入一个变量对以每个结点为根节点的树的大小进行维护,具体我们以sz[i]表示i结点代表的树(或子树)的结点数作为它的大小,初始sz[i]=1。因为现在的每一个结点都有了权重,所以我们也把这种树结构称为“加权树”,本算法称为“weightedUnionFind”。
Code:
package com.gdufe.unionfind; import java.io.File;
import java.util.Scanner; public class UF { int count; // 连通分量数
int[] id; // 每个数所属的连通分量
int[] sz; public UF(int N) { // 初始化时,N个点有N个分量
count = N;
sz = new int[N];
id = new int[N];
for (int i = 0; i < N; i++)
id[i] = i; for (int i = 0; i < N; i++)
sz[i] = 1; } // 返回连通分量数
public int getCount() {
return count;
} // 查找x所属的连通分量
public int find(int x) {
while (x != id[x])
x = id[x]; // 若找不到,则一直往根root回溯
return x;
} // 连接p,q(将q的分量改为p所在的分量)
public void union(int p, int q) {
int pID = find(p);
int qID = find(q);
if (pID == qID)
return; if (sz[p] < sz[q]) { //通过结点数量,判断树的大小并将小树并到大树下
id[p] = qID;
sz[q] += sz[p];
} else {
id[q] = pID;
sz[p] += sz[q];
}
count--;
} /*
* //查找x所属的连通分量 public int find(int x){ return id[x]; }
*
* //连接p,q(将q的分量改为p所在的分量) public void union(int p,int q){ int pID=find(p);
* int qID=find(q); if(pID==qID) return ; for(int i=0;i<id.length;i++){
* if(find(i)==pID){ id[i]=qID; } } count--; //记得每进行一次连接,分量数减“1” }
*/
// 判断p,q是否连接,即是否属于同一个分量
public boolean connected(int p, int q) {
return find(p) == find(q);
} public static void main(String[] args) throws Exception { // 数据从外部文件读入,“data.txt”放在项目的根目录下
Scanner input = new Scanner(new File("data.txt"));
int N = input.nextInt();
UF uf = new UF(N);
while (input.hasNext()) {
int p = input.nextInt();
int q = input.nextInt();
if (uf.connected(p, q))
continue; // 若p,q已属于同一连通分量不再连接,则故直接跳过
uf.union(p, q);
System.out.println(p + "-" + q); }
System.out.println("总连通分量数:" + uf.getCount());
} }
测试结果:
2-3
1-0
0-4
5-7
6-2
总连通分量数:3
4.算法性能比较:
|
读入数据 |
find() |
union() |
总时间复杂度 |
|
|
quick-find |
O(M) |
O(l) |
O(N) |
O(M*N) |
|
quick-union |
O(M) |
O(lgN~N) |
O(l) |
O(M*N)极端 |
|
WeightedUF |
O(M) |
O(lgN) |
O(N) |
O(M*lgN) |
----------------------
结语:
读到了最后,有朋友可能觉得“不就是一个O(N)到O(lgN)的转变吗,有必要这么长篇大论麽”?对此,本人就只有无语了。有过算法复杂度分析的朋友应该知道算法由O(N)到O(lgN)所带来的增长效益是多么巨大。虽然,前文中13亿的数据,就算我们用最后的加权树算法一时半会儿也无法算出。但假如现在同样是100w的数据,那么我们最后的“加权树”因为整体的时间复杂度:O(M*lgN)可以在1秒左右跑完,而O(M*N)的算法可能得花费1千倍以上的时间,至少1小时内还没算出来(当然啦,也可能你机器的是高性能的~)。
最后的最后,罗列本人目前所知晓的本算法适用的几个领域:
l 网络通信(比如:是否需要在通信点p,q建立通信连接)
l 媒体社交(比如:向通一个社交圈的朋友推荐商品)
l 数学集合(比如:判断元素p,q之后选择是否进行集合合并)
有一种算法叫做“Union-Find”?的更多相关文章
- nignx 负载均衡的几种算法介绍
负载均衡,集群必须要掌握,下面介绍的负载均衡的几种算法. 1 .轮询,即所有的请求被一次分发的服务器上,每台服务器处理请求都相同,适合于计算机硬件相同. 2.加权轮询,高的服务器分发更多的请求 ...
- [BS-28] iOS中分页的几种算法
iOS中分页的几种算法 总记录数:totalRecord 每页最大记录数:maxResult 算法一: totalPage = totalRecord % maxResult == 0 ? total ...
- 从零开始学C++之STL(四):算法简介、7种算法分类
一.算法 算法是以函数模板的形式实现的.常用的算法涉及到比较.交换.查找.搜索.复制.修改.移除.反转.排序.合并等等. 算法并非容器类型的成员函数,而是一些全局函数,要与迭代器一起搭配使用. 算法的 ...
- BitSet: 有1千万个随机数,随机数的范围在1到1亿之间。现在要求写出一种算法,将1到1亿之间没有在随机数中的数求出来?
package common; import java.util.ArrayList; import java.util.BitSet; import java.util.List; import j ...
- 浅析负载均衡的6种算法,Ngnix的5种算法。
浅析负载均衡的6种算法,Ngnix的5种算法.浮生偷闲百家号03-21 10:06关注内容导读其实际效果越来越接近于平均分配调用量到后端的每一台服务器,也就是轮询的结果.源地址哈希的思想是根据获取客 ...
- 算法入门:最大子序列和的四种算法(Java)
最近再学习算法和数据结构,推荐一本书:Data structures and Algorithm analysis in Java 3rd 以下的四种算法出自本书 四种最大子序列和的算法: 问题描述 ...
- 可以进行SHA-1,SHA-224,SHA-256,SHA-384,SHA-512五种算法签名的工具类,以及简单说明
import java.security.MessageDigest; public class SignatureSHA { public static String signSHA(String ...
- LeetCode 531----Lonely Pixel I----两种算法之间性能的比较
Lonely Pixel I 两种算法之间的性能比较 今天参加LeetCode Weekly Contest 22,第二题 "Lonely Pixel I" 问题描述如下: Giv ...
- 谈谈"求线段交点"的几种算法(js实现,完整版)
"求线段交点"是一种非常基础的几何计算, 在很多游戏中都会被使用到. 下面我就现学现卖的把最近才学会的一些"求线段交点"的算法总结一下, 希望对大家有所帮助. ...
- 背景建模技术(二):BgsLibrary的框架、背景建模的37种算法性能分析、背景建模技术的挑战
背景建模技术(二):BgsLibrary的框架.背景建模的37种算法性能分析.背景建模技术的挑战 1.基于MFC的BgsLibrary软件下载 下载地址:http://download.csdn.ne ...
随机推荐
- url编码base编码解码十六进制
0x25346425353425343525333525343325366125343525373725346425353125366625373825346425343425363725346225 ...
- NOIP2015 运输计划(bzoj4326)
4326: NOIP2015 运输计划 Time Limit: 30 Sec Memory Limit: 128 MBSubmit: 886 Solved: 574[Submit][Status] ...
- Android入门篇1-Hello World
一.android studio安装. 二.项目结构 三.运行流程 src->main->AndroidMainifest.xml注册HelloWorldActivity(intent-f ...
- MySQL Index详解
FROM:http://blog.csdn.net/tianmo2010/article/details/7930482 ①MySQL Index 一.SHOW INDEX会返回以下字段 1.Tabl ...
- 【点滴积累,厚积薄发】windows schedule task中.exe程序的路径问题等问题总结
1.在发布ReportMgmt的Job时遇到一个路径问题,代码如下: doc.Load(@"Configuration\Business\business.config"); ...
- TinyFrame升级之三:逻辑访问部分
在上一篇,我们打造了自己的数据访问部分,这篇,我们准备讲解如何打造逻辑访问部分. 在上一篇中,我们利用Repository模式构建了基于泛型的操作合集.由于这些操作的合集都是原子性的操作,也就是针对单 ...
- [MetaHook] GameUI hook
Hook GameUI function. #include <metahook.h> #include <IGameUI.h> IGameUI *g_pGameUI = ; ...
- lecture6-mini批量梯度训练及三个加速的方法
Hinton的第6课,这一课中最后的那个rmsprop,关于它的资料,相对较少,差不多除了Hinton提出,没论文的样子,各位大大可以在这上面研究研究啊. 一.mini-批量梯度下降概述 这部分将介绍 ...
- GitHub中国区前100名到底是什么样的人?
本文根据Github公开API,抓取了地址显示China的用户,根据粉丝关注做了一个排名,分析前一百名的用户属性,剖析这些活跃在技术社区的牛人到底是何许人也!后续会根据我的一些经验出品<技术人员 ...
- Android系统启动分析(Init->Zygote->SystemServer->Home activity)
整个Android系统的启动分为Linux Kernel的启动和Android系统的启动.Linux Kernel启动起来后,然后运行第一个用户程序,在Android中就是init程序. ------ ...